

Why Zhaopin Chooses Pulsar SQL for Search Log Analysis
As one of the largest online recruiting and career platforms in China, Zhaopin has 140 million active users and 4 million cooperative companies. Zhaopin provides a high-quality user experience in which job search services play a critical role. Zhaopin’s job search services support a large number of user search requests every day and generate large-scale search logs. These logs are extremely valuable and can be used for troubleshooting or Big Data analysis.
In an effort to improve their job search service and user experience, Zhaopin added Pulsar SQL to their existing Pulsar implementation. Pulsar SQL gives Zhaopin the ability to refine queries by using certain parameters that limit the amount of data that needs to be searched. Pulsar SQL also provides various reports that the company uses to analyze and aggregate data. This article covers some typical usage scenarios at Zhaopin and explains how Pulsar SQL enables the company to query streaming data more efficiently.
Zhaopin is constantly exploring new ways to use their search logs effectively and Pulsar continues to provide inspiration for the company’s efforts.
Requirements
Below are some of the scenarios Zhaopin wanted to address:
- When the search results do not meet expectations—such as when top-ranking positions are not displayed at the top or when there is an error in the search service—use trace ID to obtain the original parameters associated with a job search, including the keyword, city, salary, and so on, as well as other parameters, such as the last time a résumé was updated. Then, use the relevant parameters to identify and analyze problems.
- Analyze the search criteria associated with a position that a job seeker applied for, such as when the position was first exposed to that user, in order to improve the search service.
- Analyze search logs from different perspectives and generate charts that summarize data in different ways, such as by city, vocation, or keyword ranking. In this way, the search service can be improved by making it more specific.
Why Pulsar SQL?
Other products are capable of generating similar data for the above-mentioned scenarios, as well. So, why did Zhaopin ultimately choose Pulsar SQL? There were three main reasons:
- As Zhaopin was the first company to adopt Pulsar in China, they already had a mature Pulsar messaging system. This made it easy to integrate Pulsar SQL’s log messages.
- Pulsar SQL allows queries using SQL syntax provided that the messages are sent to Pulsar.
- Pulsar SQL can save a large amount of data and is easy to scale up.
Message Processing Flow
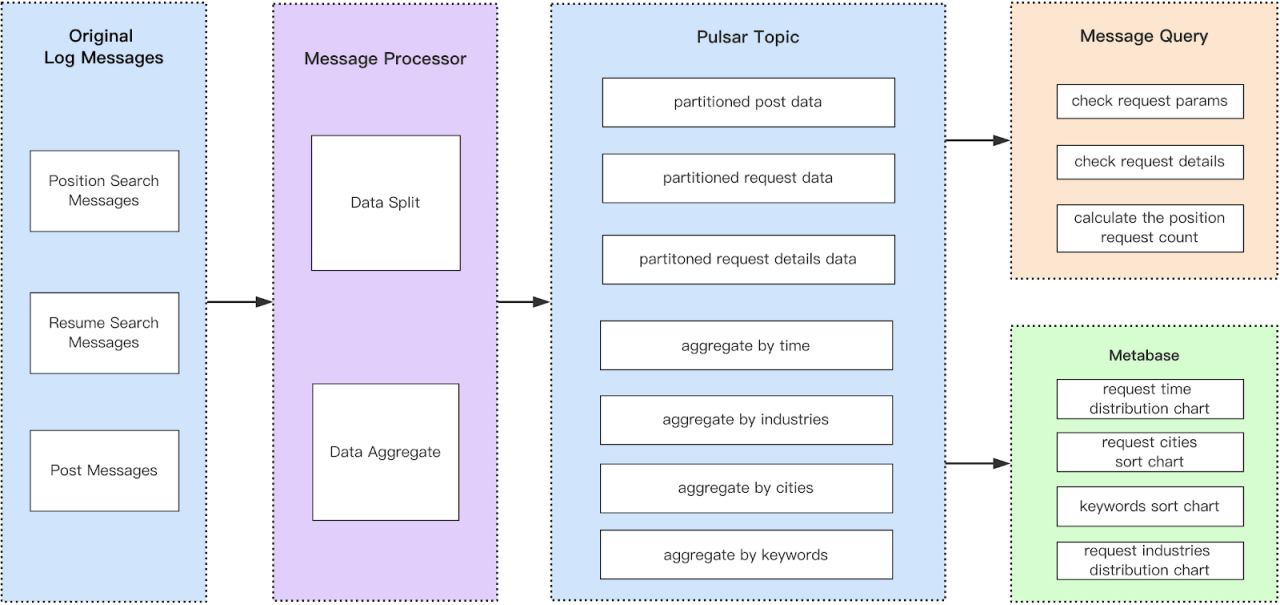
At Zhaopin, message processing flows are as shown in Figure 1. As you can see, two different methods are used to process the original search log messages: data splitting and data aggregation. Data splitting involves distributing job search requests and response data among different topics, and then splitting that data among different partitions based on the user ID or the position ID. Data aggregation aims to generate charts by category to improve search efficiency. For example, you can aggregate data by vocation once per minute and then focus on the searches that were done during that minute. If there were 10 million original search logs, then the aggregated data might number only several thousand search logs.
## Pulsar SQL Usage Scenarios
Job Exposure Queries
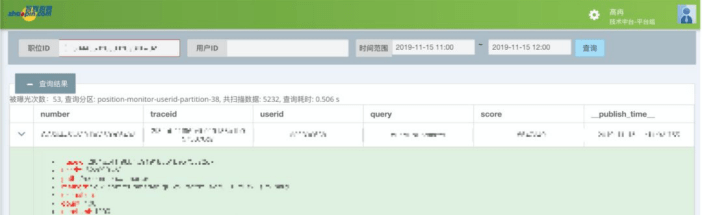
Zhaopin routinely performs queries to check the exposure of a position over a given period of time. Figure 2 illustrates an example of a typical job exposure query. A score is assigned to each exposure. The light green portion of the screenshot shows the query parameters for each exposure, such as keywords, returned values, and so on. The details associated with a search can be used to perform further analysis and optimization later.
The query page generates the query parameters, as necessary. For example, when the user chooses a publish time, the parameters are changed automatically.
Report Analysis
Four different types of reports can be generated using Pulsar SQL after the data has been aggregated by the message system. Figure 3 provides examples of each. These reports enable Zhaopin to compare data by category, such as time, vocation, and so on.
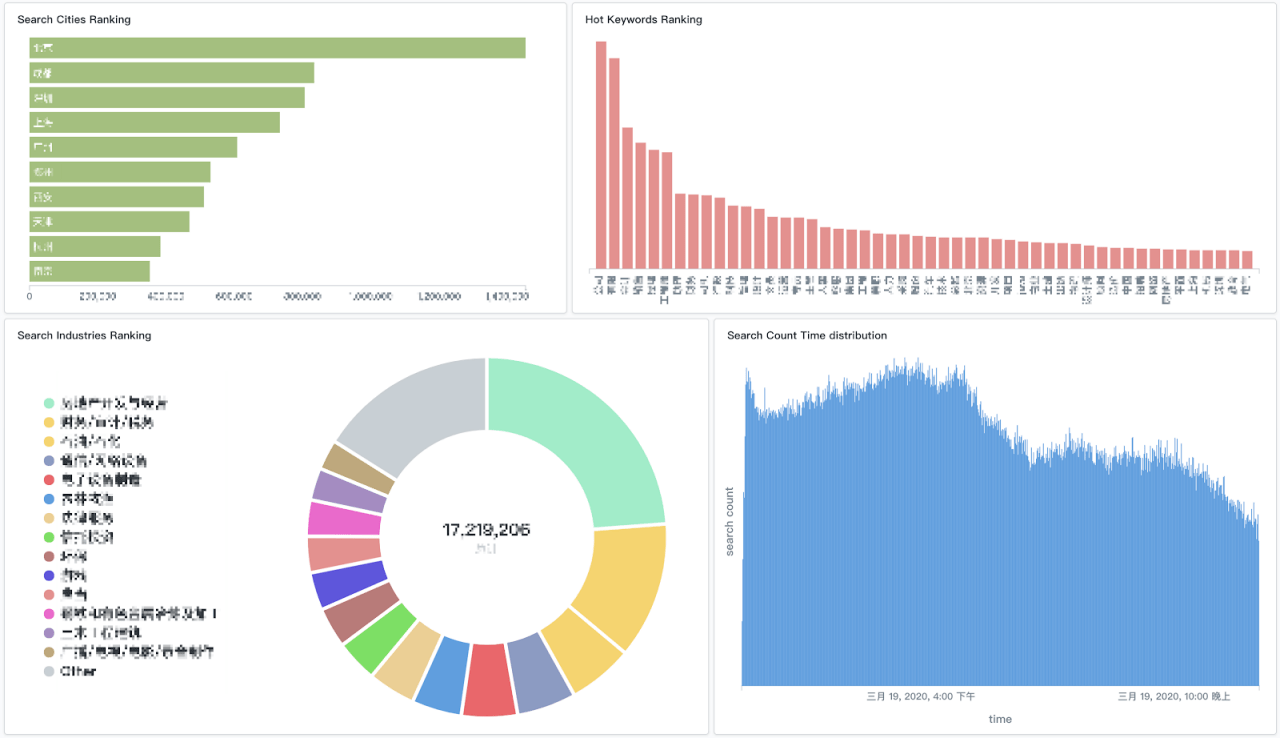
This image appears pixelated to protect the company’s confidentiality.
How Zhaopin Uses Pulsar SQL to Query Streaming Data
Pulsar SQL simplifies streaming data queries by leveraging Presto™ to retrieve data from the Pulsar storage layer. The advantage is that you can write data using the messaging API directly, and query data using Pulsar SQL, without moving data to another database. (For details about the concepts and architectures associated with Pulsar SQL, visit here.)
Pulsar SQL can map Pulsar schema to table schema well. Therefore, when data is written using a struct schema, Pulsar SQL can filter or aggregate data according to the attributes defined in the struct schema. This is the most common way in which Zhaopin uses Pulsar SQL.
The following section explains how to store search behavior data into a Pulsar topic and then query it using Pulsar SQL.
Writing Data Into a Topic Using Pulsar Struct Schemas
When users conduct a job search on www.zhaopin.com, they typically specify certain keywords to confine the search to relevant positions. Recording and analyzing users’ search behavior is critical when it comes to improving the user experience. That’s why Zhaopin stores search behavior data in topics using the Pulsar schema registry.
Here’s how you write job search request data and job search response data to a topic:
- In Terminal, create separate topics for storing job search request data and job search response data. For this example, we created two topics named "persistent://search/job/requests" and "persistent://search/job/responses."
- Define a schema for a Pulsar topic. To keep the following examples simple, we used only basic data attributes.
Note that there are several ways to define a Pulsar schema. At Zhaopin, we usually use JavaBean, but you can find more options at here.
Here are the two JavaBean objects we defined:
- Now, create the producers that will write data to the topics:
Querying Data in Pulsar Topics
Once we have written some data into the "job search request" and "job search response" topics, we can query that data using Pulsar SQL. The steps for querying data using the Pulsar SQL command-line tool are shown below.
- First, start the Pulsar SQL command-line tool:
- Now, write SQL language to query the data as shown in the following examples.
Example #1: To display the top ten keywords in today's job search requests, enter
- Now, create the producers that will write data to the topics:
Querying Data in Pulsar Topics
Once we have written some data into the "job search request" and "job search response" topics, we can query that data using Pulsar SQL. The steps for querying data using the Pulsar SQL command-line tool are shown below.
- First, start the Pulsar SQL command-line tool:
- Now, write SQL language to query the data as shown in the following examples.
Example #1: To display the top ten keywords in today's job search requests, enter
Example #2: To display the job search requests that yielded no jobs, enter
As you can see, the process is straightforward. Also, many data analysis tools, such as Metabase®, Apache Superset, and Tableau®, can integrate with Pulsar SQL using the Presto data source. Data analysis becomes more convenient and versatile with the help of these tools. At Zhaopin, we use Metabase.
In addition, REST API provides an alternative method of querying data. Whereas the command-line query tool shows data in Terminal, REST API shows the same data in an application, such as back-end services or a web application. These methods can be applied in different scenarios. REST API uses the interface provided by Pulsar SQL. For more information on how to use REST API, visit here.
Improving Query Efficiency
Queries that involve scanning large amounts of data can be extremely time-consuming and inefficient. Pulsar SQL offers two ways to improve the efficiency of a query. Users can increase the number of partitions or narrow down the selected range of dates. Both of these methods are described in detail below.
Method #1: Increase the Number of Partitions
As of version 2.5.0, Pulsar supports the ability to partition an internal column, thereby providing a way to perform an internal data query on different partitions. Thus, a partitioning strategy can be used to improve query performance exponentially. For example, you can partition job data by job ID when sending a Pulsar message, as shown below.
When Zhaopin first began using Pulsar, they could only perform queries using real topic names. However, in Pulsar, logic topic names are not considered real topic names. Now that the community has added source attributes, partition can be used as a search field and placed in search conditions when performing a query.
The first line of code shows how to query the data in partition 1 by real topic names. The second line shows how to query the same data by logic topic names. The last line shows how to query data in multiple partitions by logic topic names; this type of query cannot be done using real topic names.
Method #2: Limit the _publish_time_ Range
Narrowing down the selected range of publish times can also improve query performance significantly because it reduces the volume of data to be scanned. Specify the field _publish_time_ in the source data immediately following the where condition, as shown below. This example illustrates how to query 100 messages at a time on partition 1 for which the publish time was after 2019-11-15 09:00:00.
Note that the query page generates the query parameters accordingly.
Optimizing Performance When Making Entries in BookKeeper
Pulsar 2.5.0 offers more ways to configure the managed ledger and the BookKeeper client in pulsar.config. The most important change for Zhaopin was the addition of the bookkeeper-throttle-value parameter, which enables users to optimize performance when making entries in BookKeeper. For more details, visit here.
Conclusion
Zhaopin is now using Pulsar SQL to perform data searches and aggregation analysis for troubleshooting. Pulsar SQL improves efficiency when searching for user usage scenarios at both ends of the recruitment business. For example, public log search tools of a company are needed in log searching and there are complicated steps to search the original search parameters. However, Pulsar SQL offers tools that help make searches simpler and more specific. With the addition of Pulsar SQL, Zhaopin has improved the efficiency of its large-scale search business and solved some problems in daily search scenarios, such as saving a larger amount of data and becoming more efficient at queries.
Zhaopin has successfully demonstrated that Pulsar SQL’s simple approach makes it a cost-effective solution for businesses and industries that rely heavily on searches.
Future Outlook
Zhaopin is looking forward to implementing more business support functions and richer usage scenarios in the future. Specifically, Zhaopin would like to be able to do the following:
- Use Pulsar SQL to query a message by a specific Message ID.
- Combine Pulsar SQL with Pulsar Functions to improve the efficiency of data processing and aggregation. (For information on how to use Pulsar Functions to create complex processing logic, visit here.)
- Implement more usage scenarios, such as the ability to view hot jobs, hot résumés, hot search terms, and so on, thereby improving the user experience for both job posters and job seekers.
Recommended resources
Read more success stories.


Newsletter
Our strategies and tactics delivered right to your inbox