Handling 100K Consumers with One Pulsar Topic

Background
Nippon Telegraph and Telephone Corporation (NTT) is one of the world's leading telecommunications carriers. NTT Software Innovation Center creates innovative platform technologies to support the ICT service for prosperous future as a professional group on IT. It works to create innovative software platforms and computing platform technologies to support the evolution of the IoT/AI service as a professional group on IT. It will not only proactively contribute to the open source community but also promote research and development through open innovation. It will also contribute to the reduction of CAPEX/OPEX for IT or strategic utilization of IT, using the accumulated technologies and know-how regarding software development and operation.
Before I introduce how we use Apache Pulsar to handle 100K consumers, let me first explain our use case and the challenges facing us.
In our smart city scenario, we need to collect data from a large number of devices, such as cars, sensors, and cameras, and further analyze the data for different purposes. For example, if a camera detects any road damage, we need to immediately broadcast the information to the cars nearby, thus avoiding traffic congestion. More specifically, we provide a topic for each area and all the vehicles in that area are connected to the topic. For a huge city, we expect that there are about 100K vehicles publishing data to a single topic. In addition to the large data volume, we also need to work with different protocols used by these devices, like MQTT, REST, and RTSP.

Data persistence is another challenge in this scenario. For essential data, like key scenes from cameras or key events from IoT devices, we need to securely store them for further analysis, perhaps for a long period of time. We also have to prepare proper storage solutions in the system.
With massive devices, various protocols, and different storage systems, our data pipeline becomes extremely complicated. It is almost impossible to maintain such a huge system.
Why did we choose Apache Pulsar
As we worked on solutions, we were thinking about introducing a unified data hub, like a large, centralized message broker that is able to support various protocols. This way, all the devices only need to communicate with a single endpoint.
Nowadays, many brokers provide their own storage solutions or even support tiered storage, which guarantees persistence for any data processed by the brokers. This also means that we only need to work with brokers and their topics, which allows us to have an easier and cleaner system.
Ultimately, we chose to build our system with Apache Pulsar as the basic framework. Pulsar is a cloud-native streaming and messaging system with the following key features.
- A loosely-coupled architecture. Pulsar uses Apache BookKeeper as its storage engine. This allows us to independently scale out the storage cluster without changing the number of brokers if we need to store more data.
- A pluggable protocol handler. Pulsar’s protocol handler enables us to work with multiple protocols with just one broadcaster. It supports MQTT, Kafka, and many other brokers. This makes it very convenient to ingest data from various sources into a centralized Pulsar cluster.
- High performance and low latency. Pulsar shows excellent performance as we tested it using different benchmarks. We will talk about this in more detail later.
So, does Pulsar meet the performance requirements of our use case? Let’s take a look at the breakdown of our requirements.
- A large number of consumers. Brokers should be able to manage messages and broadcast them to up to 100K vehicles.
- Low latency. We have tons of notifications generated against the data in real time, which need to be broadcast at an end-to-end (E2E) latency of less than 1 second. In our case, the end-to-end latency refers to the duration between the time a message is produced by cloud services and the time it is received by the vehicle. Technically, it contains two phases - producing and consuming.
- Large messages. Brokers should be able to handle large messages from cameras (for example, video streams) without performance issues. Most brokers focus on handling small messages, such as event data from microservices on the cloud, which are usually about several hundred kilobytes at most. When messages become larger, these brokers may have performance problems.
In this blog, we will focus on the first 2 requirements, namely how to broadcast messages for 100K consumers with an end-to-end latency of less than 1 second.
Benchmark testing
To understand how Pulsar fits into our use case, we performed some benchmark tests on Pulsar and I will introduce some of them in this section.
Figure 2 shows the general structure of our benchmark tests.

- Broadcast task: Only 1 publisher sending messages to 1 persistent topic with a single Pulsar broker
- Consumers: 20K-100K consumers (shared subscription)
- Message size: 10 KB
- Message dispatch rate: 1 msg/s
- Pulsar version: 2.10
- Benchmark: OpenMessaging Benchmark Framework (OMB)
Figure 3 shows our client and cluster configurations.

We performed the benchmark tests on Amazon Web Services (AWS), with both the broker and bookies using the same machine type (i3.4xlarge). We provided sufficient network (10 Gbit) and storage (2 SSDs) resources for each node to avoid hardware bottlenecks. This allowed us to focus on the performance of Pulsar itself. As we had too many consumers, we put them onto several servers, or clients in Figure 3.
Overall benchmark results
Table 1 displays our benchmark results. We can see that Pulsar worked well with 20K consumers, recording a P99 latency of 0.68 seconds and a connection time of about 4 minutes. Both of them are acceptable in real-world usage.

* Connection time: the time between the start of the connections to all consumers and the end of all the connections.
As the number of consumers increased, we noticed a decline in performance. When we had 30K consumers, the P99 latency exceeded 1 second. When 40K consumers were involved, the P99 latency even topped 4 seconds, with a connection time of nearly 20 minutes, which is too long for our use case. For 100K consumers, they even failed to establish the connections since they took too much time.
A polynomial curve: The connection time and the number of consumers
To understand how the connection time is related to consumers, we conducted further research and made a polynomial curve for the approximations of the collection time as the number of consumers increases.

Based on the curve, we expected the connection time to reach 8,000 seconds (about 2.2 hours) at 100K consumers, which is unacceptable for our case.
Connection time distribution: The long tail problem
In addition, for the case with 20K consumers, we measured the connection time of each consumer and created a histogram to see the time distribution across them, as depicted in Figure 5.
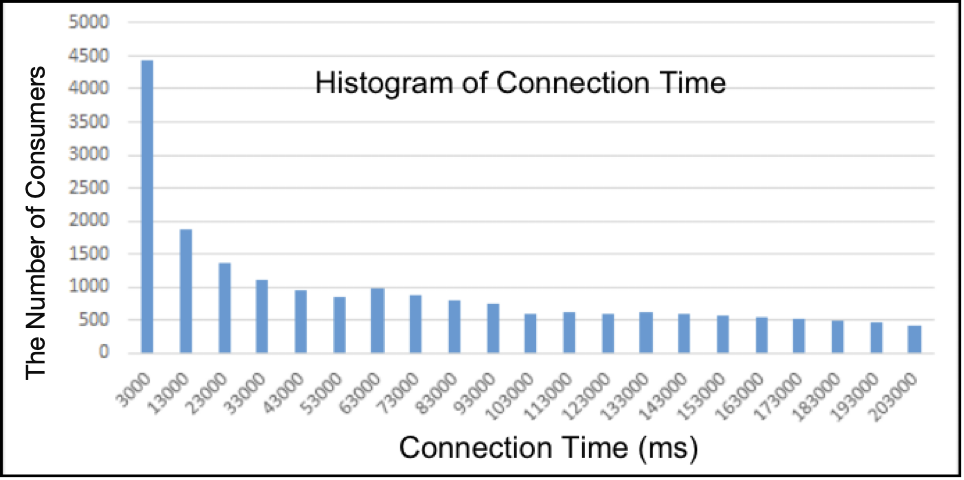
The Y-axis represents the number of consumers that finished their connections within the time range on the X-axis. As shown in Figure 5, about 20% of connections finished in about 3 seconds, and more than half of the connections finished within one minute. The problem lay with the long tail. Some consumers even spent more than 200 seconds, which greatly affected the overall connection time.
A breakdown of P99 latency
For the P99 latency, we split it into six stages and measured their respective processing time in the 40K-consumer case.
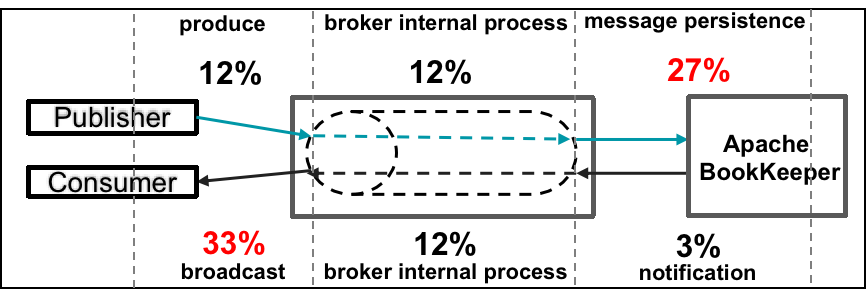
- Producing: Includes message production by the publisher, network communications, and protocol processing.
- Broker internal process: Includes message deduplication, transformation, and other processes.
- Message persistence: The communication between the broker and BookKeeper.
- Notification: The broker receives an update notification from BookKeeper.
- Broker internal process: The broker prepares the message for consumption.
- Broadcasting: All the messages are broadcast to all the consumers.
Our results show that message persistence took up about 27% of the total latency while broadcasting accounted for about 33%. These two stages combined were responsible for most of the delay time, so we needed to focus on reducing the latency for them specifically.
Before I continue to explain how we worked out a solution, let’s review the conclusion of our benchmark results.
- Pulsar is already good enough for scenarios where there are no more than 20K consumers with a P99 latency requirement of less than 0.7s. The consumer connection time is also acceptable.
- As the number of consumers increases, it takes more time for connections to finish. For 100K consumers, Pulsar still needs to be improved in terms of latency and connection time. For latency, the persistence (connections with BookKeeper) and broadcasting (connections with consumers & acks) stages take too much time.
Approaches to 100K consumers
There are typically two ways to improve performance: scale-up and scale-out. In our case, we can understand them in the following ways.
- Scale-up: Improve the performance of a single broker.
- Scale-out: Let multiple brokers handle one topic at the same time. One of the possible scale-out solutions is called “Shadow Topic”, proposed by a Pulsar PMC member. It allows us to distribute subscriptions across multiple brokers by creating "copies" of the original topic. See PIP-180 for more details.
This blog will focus on the first approach. More specifically, we created a broadcast-specific model for better performance and resolved the task congestion issue when there are too many connections.
Four subscription types in Pulsar
First, let’s explore Pulsar’s subscription model. In fact, many brokers share similar models. In Pulsar, a topic must have at least one subscription to dispatch messages and each consumer must be linked to one subscription to receive messages. A subscription is responsible for transferring messages from topics. There are four types of subscriptions in Pulsar.

- Exclusive. Only one consumer is allowed to be associated with the subscription. This means if the consumer crashes or disconnects, the messages in this subscription will not be processed anymore.
- Failover. Supports multiple consumers, but only one of the consumers can receive messages. When the working consumer crashes or disconnects, Pulsar can switch to another consumer to make sure messages keep being processed.
- Shared. Distributes messages across multiple consumers. Each consumer will only receive parts of the messages, and the number of messages will be well-balanced across every consumer.
- Key_Shared. Similar to Shared subscriptions, Key_Shared subscriptions allow multiple consumers to be attached to the same subscription. Messages are delivered across consumers and the messages with the same key or same ordering key are sent to only one consumer.
A problem with the subscription types is that there is no model designed for sending the same messages to multiple consumers. This means in our broadcasting case, we must create a subscription for each consumer. As shown in Figure 8, for example, we used 4 exclusive subscriptions, and each of them had a connected consumer, allowing us to broadcast messages to all of them.

Using multiple subscriptions for broadcasting messages
However, creating multiple subscriptions can increase latency, especially when you have too many consumers. To understand the reason, let’s take a look at how a subscription works. Figure 9 displays the general design of a subscription, which is comprised of three components:
- The subscription itself.
- Cursor. You use a cursor to track the position of consumers. You can consider it as a message ID, or the position on the message stream. This information will also be synchronized with the metadata store, which means you can resume consumption from this position even after the broker restarts.
- Dispatcher. It is the only functional part of the subscription, which communicates with BookKeeper and checks if there are any new messages written to BookKeeper. If there are new messages, it will pull them out and send them to consumers.

As the dispatcher communicates with BookKeeper, each dispatch has its own connection to BookKeeper. This comes with a problem when you have too many consumers. In our case, 100K consumers were attached to 100K subscriptions, requiring 100K connections to BookKeeper. This huge number of connections was clearly a performance bottleneck.
In fact, these connections were redundant and unnecessary. This is because for this broadcasting task, all the consumers used their respective subscriptions just to retrieve the same messages from the same topic. Even for the cursor, as we sent the same data at the same time, we did not expect too many differences between these cursors. Theoretically, one cursor should be enough.
Broadcast Subscription with virtual cursors
To improve performance, we redesigned the subscription model specifically for handling large volumes of consumers (see Figure 10). The new structure guarantees the message order for each consumer. It shares many functions with the existing subscription model, such as cumulative acknowledgment.
In the new model, only one subscription exists to serve multiple consumers, which means there is only one dispatcher. As only a single connection to BookKeeper is allowed, this method can greatly reduce the load on BookKeeper and lower the latency. Additionally, since the subscription only has one cursor, there is no metadata duplication.

In Pulsar, when consumers fail to receive or acknowledge messages, we need to resend the messages. To achieve this for one subscription and multiple consumers, we introduced a lightweight “virtual cursor” for each consumer to record the incremental position of the main cursor. The virtual cursor has a lightweight design; it does not contain any other information other than the incremental position. It allowed us to identify unread messages by comparing the virtual cursors and the data stored on BookKeeper. This way, we could keep unprocessed messages and delete any acknowledged ones.
Evaluating the performance of the new subscription model
With this new subscription model, we evaluated its performance using 30K, 40K, and 100K consumers. The baseline is the shared subscription, which had the best result among all four original subscription models.

As shown in Table 2, when we had 40K consumers, the P99 latency of the Broadcast Subscription was almost 6 times faster than the original Shared Subscription. The connection time also saw a significant decrease as we only had one subscription. Even with 100K consumers, all the connections finished in just about 77.3 seconds. Although the results were extremely impressive, we still wanted a better P99 latency of less than 1 second.
Optimizing OrderedExecutor
In our benchmark evaluation, we found another factor that could lead to high latency: OrderedExecutor.
Let’s first explore how OrderedExecutor works. BookKeeper provides OrderedExecutor in org.apache.bookkeeper.common.util. It guarantees that tasks with the same key are executed in the same thread. As we can see from the code snippet below, if we provide the same ordering key, we will always return the same thread with chooseThread. It helps us keep the order of tasks. When sending messages, Pulsar can run sustaining jobs with the same key, ensuring messages are sent in the expected order. This is widely used in Pulsar.
We found two problems caused by OrderedExecutor according to our test results.
First, when we split 100K consumers into different Broadcast Subscriptions, the latency did not change too much. For example, we created four Broadcast Subscriptions with 25K consumers attached to each of them and hoped this approach would further reduce latency given its parallelization. In addition, dividing consumers into different groups should also help the broker have better communication with BookKeeper. However, we found that it had no noticeable effect on our benchmark results.
The reason is that Pulsar uses the topic name as the ordering key. This means that all the messages of the same tasks are sequentialized at the topic level. However, we know that subscriptions are independent of each other. It is unnecessary to guarantee the order across all the subscriptions. We just need to keep the message order within one subscription. A natural solution is to change the key to the subscription name.
The second one is more interesting. In terms of message acknowledgments, we noticed a very high long-tail latency. On average, acknowledgments finished in 0.5 seconds, but the slowest one took up to 7 seconds, which greatly affected the overall P99 latency. We carried out further research but did not find any problems in the network or consumers. This high latency issue could always be reproduced in every benchmark test.
Finally, we found that this issue was caused by the way Pulsar handles acknowledgments. Pulsar uses two individual tasks to complete the message-sending process - one for sending the message and the other for the ACK. For each message sent by the consumer, Pulsar generates these two tasks and pushes them to OrderedExecutor.

To guarantee the order of messages, Pulsar always adds them to the same thread, which is suitable for many use cases. However, things are slightly different when you have 100K consumers. As shown in Figure 12, Pulsar generates 200K tasks, all of which are inserted into a single thread. This means other tasks might also exist between a pair of SEND and ACK tasks. In these cases, Pulsar first runs the in-between tasks before the ACK task can be processed, leading to a longer latency. In a worst-case scenario, there might be 10,000 in-between tasks.

For our case, we only need to send messages in order while their ACK tasks can be placed anywhere. Therefore, to solve this problem, we used a random thread for ACK tasks instead of the same thread. As shown in Table 3, our final test with the updated logic of OrderExecutor shows some promising results.

Compared with the previous test using the original OrderedExecutor logic, the P99 latency in this test for 100K consumers was about 4 times shorter and the connection time was reduced by half. The latest design also worked well for 30K consumers, the connection time of which was about 2.5 times faster.
Conclusion
Pulsar has a flexible design and its performance is already good enough for many use cases. However, when you need to handle special cases where a large number of consumers exist, it may be a good idea to implement your own subscription model. This will help improve Pulsar’s performance dramatically.
Additionally, using OrderedExecutor in the right way is also important to the overall performance. When you have a large number of SEND and ACK tasks that need to be processed in a short time, you may want to optimize the original logic given the additional in-between tasks.
More on Apache Pulsar
- Make an inquiry: Interested in a fully-managed Pulsar offering built by the original creators of Pulsar? Contact us now.
- Pulsar Summit Europe 2023 is taking place virtually on May 23rd. Engage with the community by submitting a CFP or becoming a community sponsor (no fee required).
- Learn the Pulsar Fundamentals: Sign up for StreamNative Academy, developed by the original creators of Pulsar, and learn at your own pace with on-demand courses and hands-on labs.
- Read the 2022 Pulsar vs. Kafka Benchmark Report for the latest performance comparison on maximum throughput, publish latency, and historical read rate.

Newsletter
Our strategies and tactics delivered right to your inbox