
In addition to its unique design, Pulsar also features multi-tenancy, persistent storage, geo-replication, strong consistency, high throughput, and many more built-in abilities. Specifically, Wu’s team explored the following capabilities of Apache Pulsar:
- Great scalability. A Pulsar cluster can be seamlessly scaled out to include thousands of nodes.
- High throughput. Supports millions of messages (Pub/Sub) per second.
- Low latency. Provides low latency of less than 5 ms even during traffic bursts.
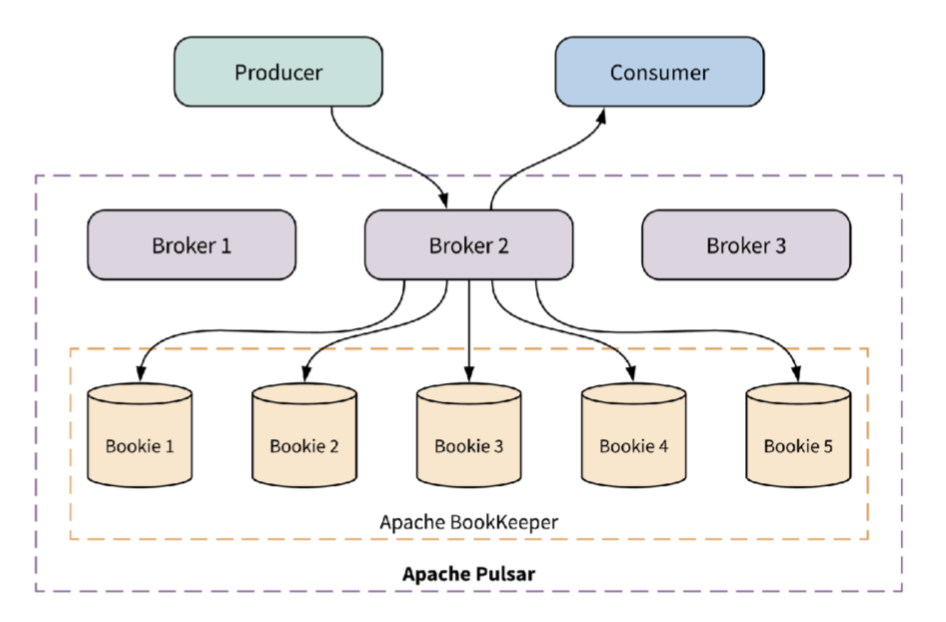
- Data persistency. Provides durable storage based on Apache BookKeeper, which allows users to customize their replica writing strategy.
- Read-write separation. In BookKeeper, reads and writes are separated, which gives full play to sequential I/O. This is more friendly to HDDs. Furthermore, there is no limitation on the number of topics that a bookie can support.
After the team saw first hand the power and reliability of Apache Pulsar, they commenced further exploring Pulsar by running a series of tests in December 2019. “We were using HDDs at that time and no SSDs. At the beginning, we had some performance issues in these tests,” Wu said. “Fortunately, with the help of StreamNative, we brought the performance and stability of brokers and BookKeeper to another level.” Founded by the original creators of Apache Pulsar and Apache BookKeeper, StreamNative builds a cloud-native event streaming platform that enables enterprises to easily access data as real-time event streams.
“After 3 to 4 months of testing and optimization, we were fully confident that Pulsar could help us make a visible difference in the places where Kafka fell short. Therefore, we put Pulsar into production in May 2020,” Wu added.
Apache Pulsar at BIGO: Pub/Sub model
BIGO uses Pulsar mainly for the pub/sub model. At the front end, the team leverages Baina (a data collection service implemented through C++), Kafka Mirror Maker, Flink, as well as other clients written in different languages (for example, Java and Python) to produce messages on Pulsar topics. At the back end, Flink, Flink SQL, and other clients serve as consumers.
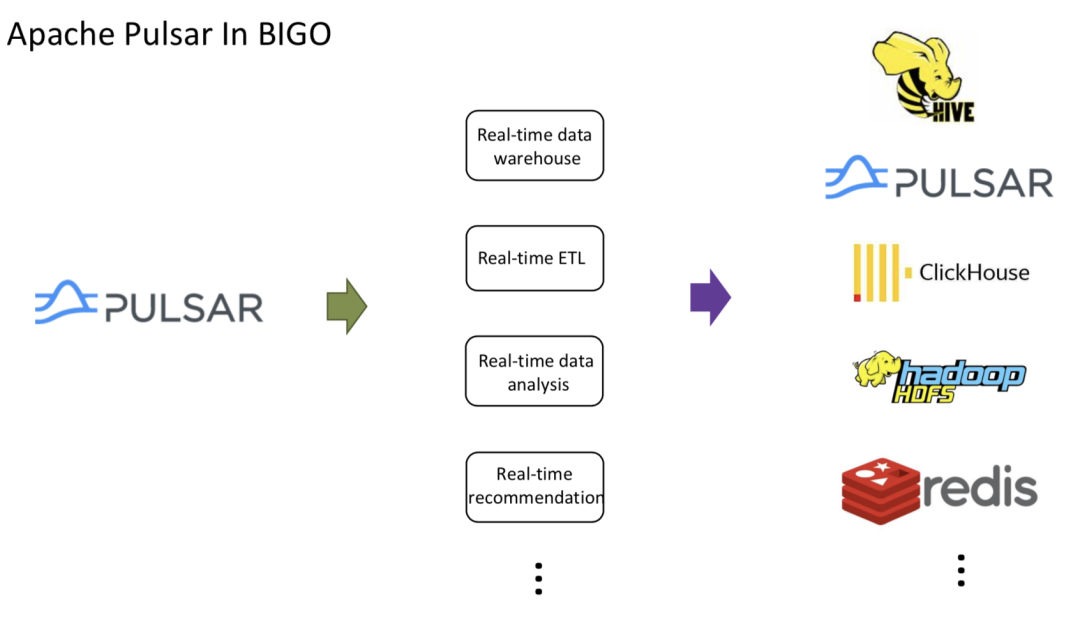
Downstream business modules include real-time warehouse, ETL, data analysis, and recommendations. Most of them depend on Flink consuming data from Pulsar topics, and then they process the data based on their own business logic. Finally, the data are written to third-party storage services, such as Hive, ClickHouse, and Redis.
Real-time Messaging Architecture for ETL
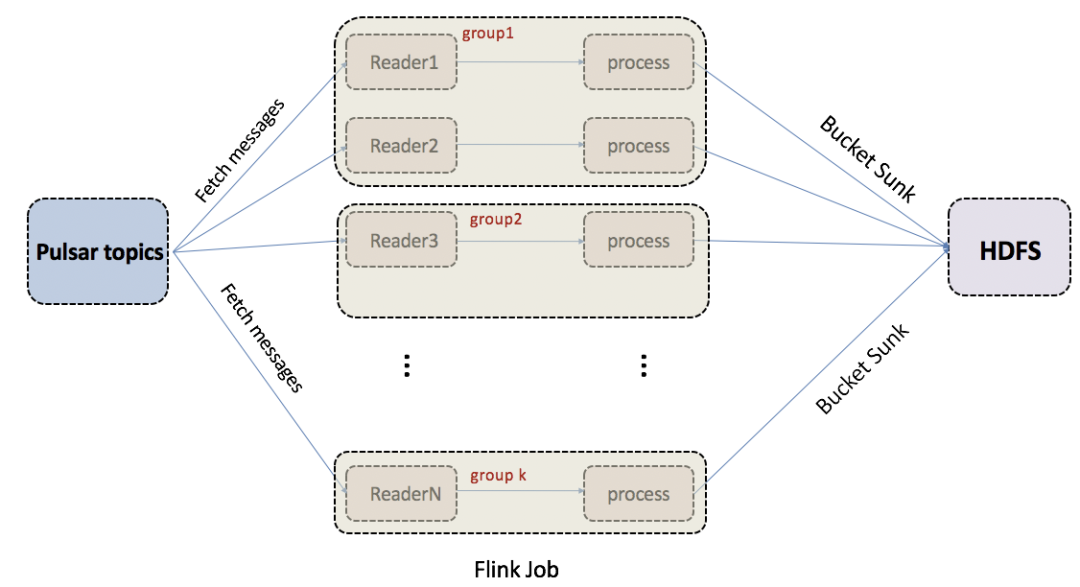
The team has built a real-time messaging architecture based on Pulsar and Flink to support a key ETL use case at BIGO. This scenario contains up to thousands of Pulsar topics, with each one having its independent schema. Each topic has a table in HDFS, and each table may have different fields. Data in these topics need to be processed for field conversion and eventually written to HDFS.
“In this use case, the tricky part is that we have too many topics. We cannot afford the maintenance costs if we run a Flink job for each topic,” said Wu. “In the end, we choose to use readers to subscribe to all topics and write data to HDFS after schema processing.”
At first, the traffic sent to different topics was not balanced. Some task managers might need to handle high volumes of data while others received only a small portion of the traffic. For a high-volume topic, the task manager responsible for the reader process of the topic could be overwhelmed. As a result, tasks might get stuck on some machines, slowing down Flink streams. “To solve this problem, we group topics according to their traffic,” said Wu. “For example, we put low-traffic topics into the same group. By contrast, a topic that serves a high traffic volume is in its own group. This makes sure resources are separated with traffic balanced for task managers. By now, we have been running this ETL flow stably for nearly 2 years.”
What Pulsar Has Brought to BIGO
At BIGO, Pulsar has been running stably for over 2 years since its production adoption. With Pulsar’s distinctive features, including high throughput, low latency, and strong reliability, BIGO has seen a tremendous boost in its ability to process data at a low cost.
Here are some of the key results:
- Pulsar processes tens of billions of messages daily with a traffic flow of 2 to 3 GB per second.
- Pulsar has reduced the hardware cost by nearly 50%.
- Hundreds of Pulsar broker and bookie processes are deployed on tens of physical machines (the bookie and broker are deployed on the same node).
- The ETL business has over 10,000 topics, with 3 partitions per topic and 3 replicas for ledger storage.
“We have migrated our ETL business from Kafka to Pulsar and will be gradually doing the same for other modules that consume data from Kafka clusters, such as Flink and ClickHouse,” said Wu. “The tiered storage design of Pulsar makes it possible to support millions of topics, which are essential to our ETL use case.”
Deeper Integration with Pulsar
Over the past few years, BIGO has been working to optimize Pulsar and BookKeeper for the better. This has laid the groundwork to further integrate Pulsar within BIGO and promote it in the community. “We have done a lot of work on both Pulsar and BookKeeper,” said Wu. “Broker load balancing and monitoring, read and write performance, disk IO performance, and Pulsar’s integration with Flink and Flink SQL are all very important to us.”
As BIGO looks to put Pulsar in more scenarios within the organization, it is poised to help the community improve Pulsar and reap further benefits from Pulsar in the following ways.
- Continue to be an active contributor to the Pulsar community by developing more features for Pulsar (for example, topic policy support) and optimizing both Pulsar and BookKeeper (for example, BookKeeper IO protocol stack).
- Migrate more traffic to Pulsar. This contains two major tasks - migrating existing business modules that are using Kafka to Pulsar and running new business directly with Pulsar.
- Adopt Kafka on Pulsar (KoP) to ensure a smooth migration experience. “We still have some Flink-based jobs that consume data from existing Kafka clusters. We hope to integrate KoP with them to streamline the migration process,” said Wu.
More on Apache Pulsar
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community that continues to drive innovation and improvements to the project.
- Start your free, on-demand Pulsar training today with StreamNative Academy.
- Spin up a Pulsar cluster with StreamNative Cloud. StreamNative Cloud provides a simple, fast, and cost-effective way to run Pulsar in the public cloud.


