
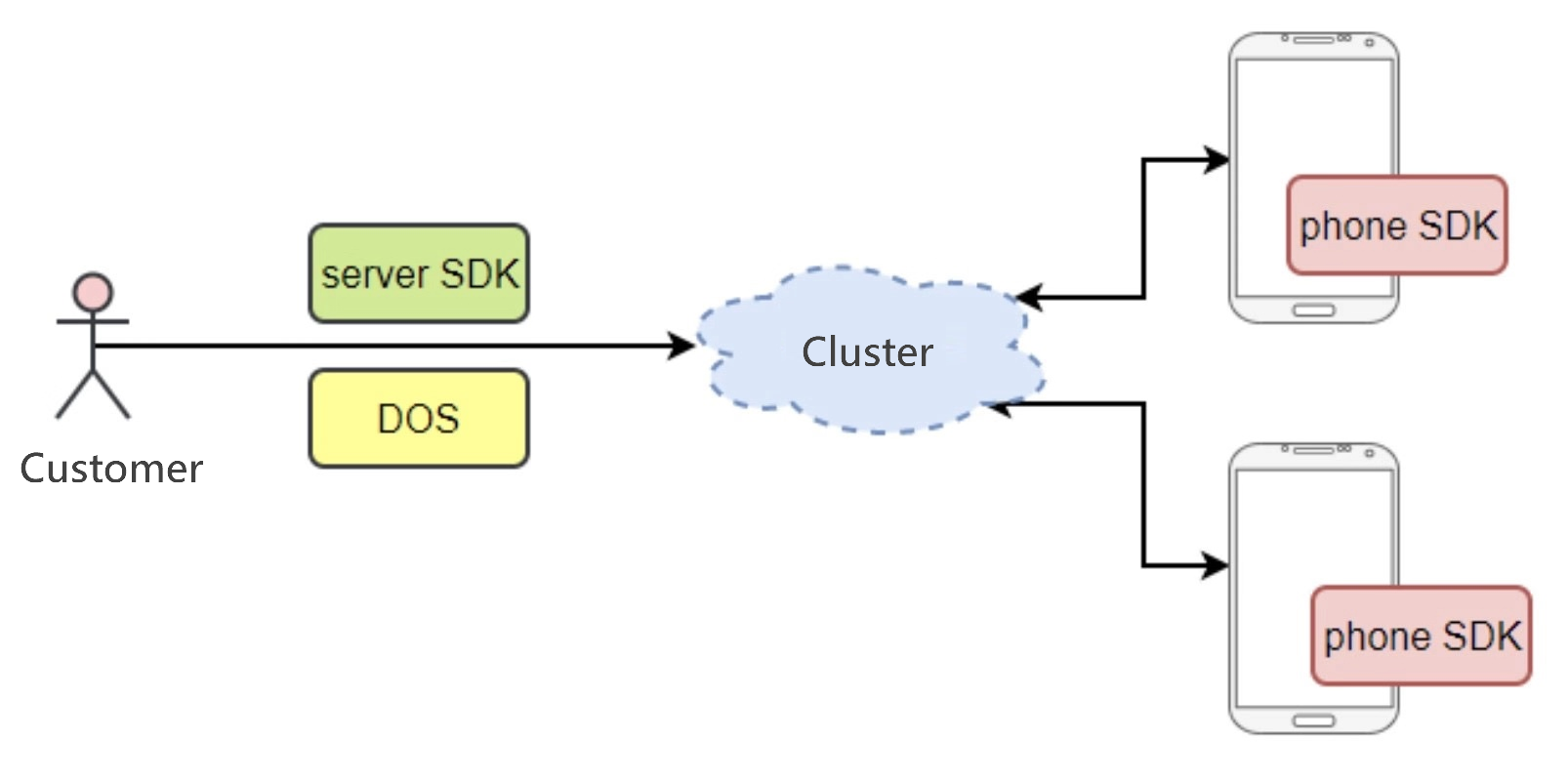
When a GeTui customer needs to send push notifications to its end users, it first sends messages to GeTui's push notification service. The push notifications are queued in the service based on their priorities.
However, resource contention increases when the number of push notifications waiting in message queues increases. It drives demands for a priority-based push notification design because we need to allocate more resources to customers with high priorities.
Kafka solution
Overview
Our first priority-based push notification solution was implemented by using Apache Kafka.
Kafka is a high-performance distributed streaming platform developed by LinkedIn, which is also widely used within GeTui, from log aggregation to online and offline message distribution, and many other use cases.
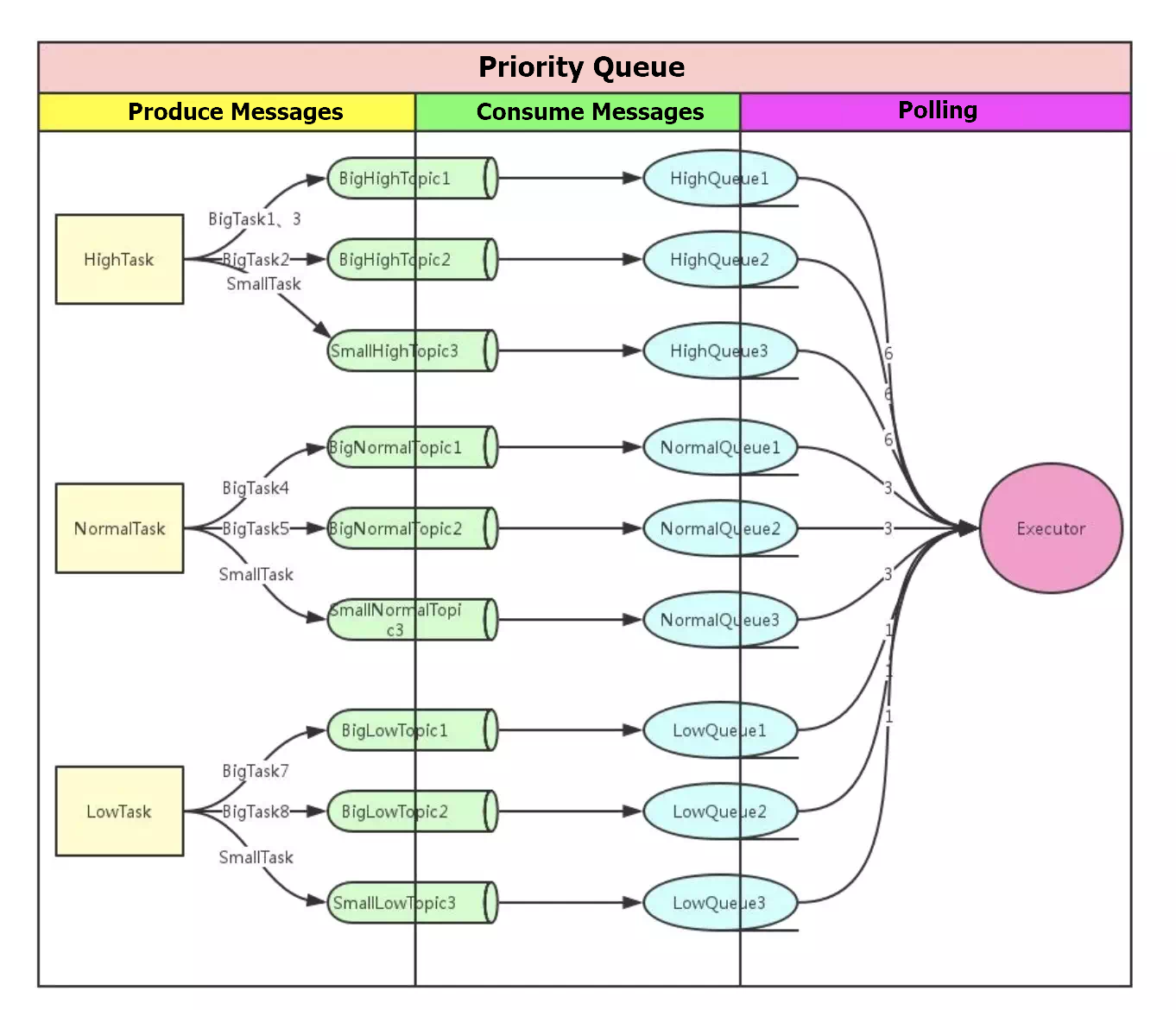
In this solution, we set the priority of messages into three levels: high, normal, and low. Messages of each priority are stored in a group of topics. The push notification tasks are sent to different topics based on their priorities. Downstream consumers receive messages based on their priorities. The push notification tasks with the same priority are polled in a round-robin way. It guarantees push notifications with higher priorities can be sent as early as possible, and push notifications with low priority can be eventually sent as well.
Problems
When the business grows and the number of applications using our service increases, the Kafka solution ran into problems as below:
- For customers with the same priority levels, their notification tasks pushed at the same time becomes more and more. Later tasks (taskN in the image below) are delayed due to earlier tasks (task1, task2, task3 in the image below) are waiting to be processed. If task1 has a high volume of messages, then taskN will wait until task1 is finished.

- When the number of topics increases from 64 to 256, the throughput of Kafka degrades sharply. Since in Kafka, each topic and partition are stored as one or a few physical files, when the number of topics increases, random IO access introduces lots of IO contentions and consumes lots of I/O resources. Hence, we can not solve the first problem by just increasing the number of topics.
To solve the problems stated previously, we need to evaluate another messaging system that supports a large number of topics while maintaining as high throughput as Kafka. After doing some investigations, Apache Pulsar catches our attention.
Why Pulsar fits best
Apache Pulsar is a next-generation distributed messaging system developed at Yahoo, it was developed from the ground up to address several shortcomings of existing open-source messaging systems and has been running in Yahoo's production for three years, powering critical applications like Mail, Finance, Sports, Flickr, the Gemini Ads Platform, and Sherpa (Yahoo's distributed key-value store). Besides, Pulsar was open-sourced in 2016 and graduated from the Apache incubator as an Apache top-level project (TLP) in September 2018.
After working closely with the Pulsar community and diving deeper into Pulsar, we decided to adopt Pulsar for the new priority-based push notification solution for the following reasons:
- Pulsar can scale to millions of topics with high performance, and its segment-based architecture delivers better scalability.
- Pulsar provides a simple and flexible messaging model that unifies queuing and streaming, so it can be used for both work queue and pub-sub messaging use cases.
- Pulsar has a segment-centric design, that separates message serving from message storage, allowing independent scalability of each. Such a layered architecture offers better resiliency and avoids complex data rebalancing when machines crash or a cluster expands.
- Pulsar provides an excellent I/O isolation, which is suitable for both messaging and streaming workloads.
Pulsar solution
After extensive discussions, we settled down a new solution using Apache Pulsar.
The Pulsar solution is close to the Kafka solution, but it solves the problems we encountered in Kafka by leveraging Pulsar's advantages.
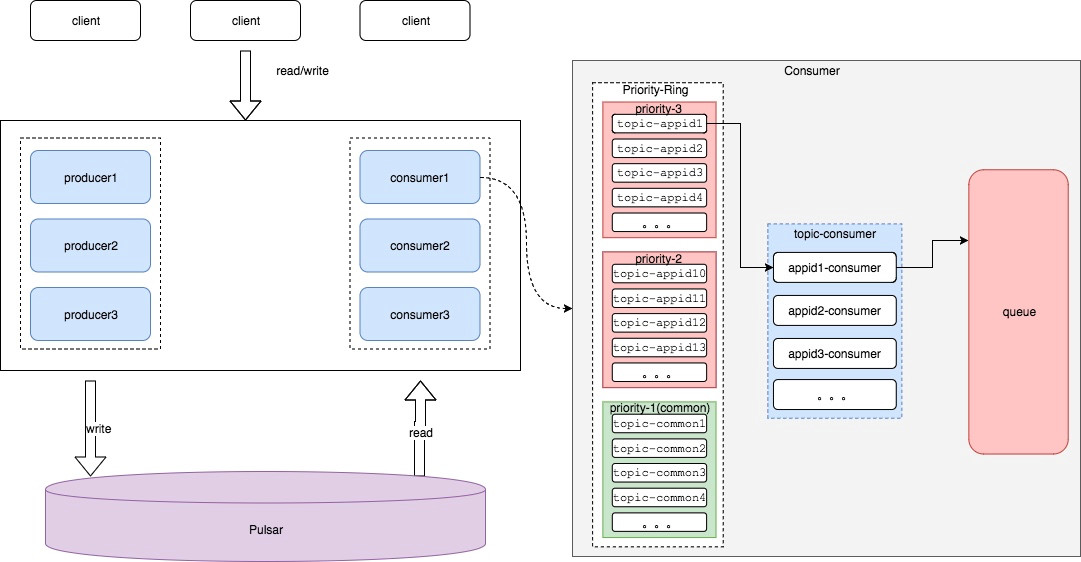
- In Pulsar solution, we create topics dynamically based on tasks. It guarantees later tasks do not wait due to other tasks are waiting to be processed in a queue.
- We create a Pulsar topic for each task with normal-level and high-level priorities and create a fixed number of topics for tasks with low-level priority.
- Tasks with the same priorities are polling the topic to read messages, when the quotas are filled up, tasks with the next same priorities move to read messages in the next priority level.
- Tasks with the same priority can modify quota, which guarantees they can receive more messages.
- Consumers can be added and deleted dynamically using Pulsar's shared subscription without the need to increase and rebalance partitions.
- BookKeeper provides the flexibility of adding storage resources online and without rebalancing the old partitions.
Best practice of Pulsar
Pulsar has been successfully running on production for months serving the new priority-based push notification system. During the whole process of adopting and running Pulsar on production, we have collected some best practices on how to make Pulsar work smoothly and efficiently on our production.
- Different subscriptions are relatively independent. If you want to consume some messages of a topic repeatedly, you need to use different subscriptionName to subscribe. Monitor your backlog when adding new subscriptions. Pulsar uses a subscription-based retention mechanism. If you have an unused subscription, please remove it; otherwise, your backlog will keep growing.
- If a topic is not subscribed, messages sent to the topic are dropped by default. Consequently, if producers send messages to topics first, and then consumers receive the messages later, you need to make sure the subscription has been created before producers sending messages to topics; otherwise some messages will not be consumed.
- If no producers send messages to a topic, or no consumers subscribe to a topic, then the topic is deleted after a period. You can disable this behavior by setting brokerDeleteInactiveTopicsEnabled to false.
- TTL and other policies are applied to a whole namespace rather than a topic.
- By default, Pulsar stores metadata under root znode of ZooKeeper. It is recommended to configure the Pulsar cluster with a prefix zookeeper path.
- Pulsar's Java API is different from Kafka's, that is, messages need to be explicitly acknowledged in Pulsar.
- The storage size displayed in Pulsar dashboard is different from the storage size shown in Prometheus. The storage size shown in Prometheus is the total physical storage size, including all replicas.
- Increase dbStorage_rocksDB_blockCacheSize to prevent slow-down in reading large volume of backlog.
- More partitions lead to higher throughputs.
- Use stats and stats-internal to retrieve topic statistics when troubleshooting a problem in your production cluster.
- The default backlogQuotaDefaultLimitGB in Pulsar is 10 GB. If you are using Pulsar to store messages for multiple days, it is recommended to increase the amount or set a large quota for your namespaces. Choose a proper backlogQuotaDefaultRetentionPolicy for your use case because the default policy is producer_request_hold, which rejects produce requests when you exhaust the quota.
- Set the backlog quota based on your use case.
- Since Pulsar reads and dispatches messages in the broker's cache directly, the read time metrics of BookKeeper in Prometheus can be null at most of the time.
- Pulsar writes messages to journal files and writes cache synchronously, and the write cache is flushed back to log files and RocksDB asynchronously. It is recommended to use SSD for storing journal files.
Summary
We have successfully run the new Pulsar based solution on production for some use cases for a few months. Pulsar has shown great stability. We keep watching the news, updates, and activities in the Pulsar community and leverage the new features for our use cases.
Graduated from the ASF incubator as a top-level project in 2018, Pulsar has plenty of attractive features and advantages over competitors, such as geo-replication, multi-tenancy, seamless cluster expansion, read-write separation, and so on.
The Pulsar community is still young, but there is already a fast-growing tendency of adopting Pulsar for replacing many legacy messaging systems.
During the process of adopting and running Pulsar, we run into a few problems, and a huge thank you goes to Jia Zhai and Sijie Guo from StreamNative for providing quality support.


