
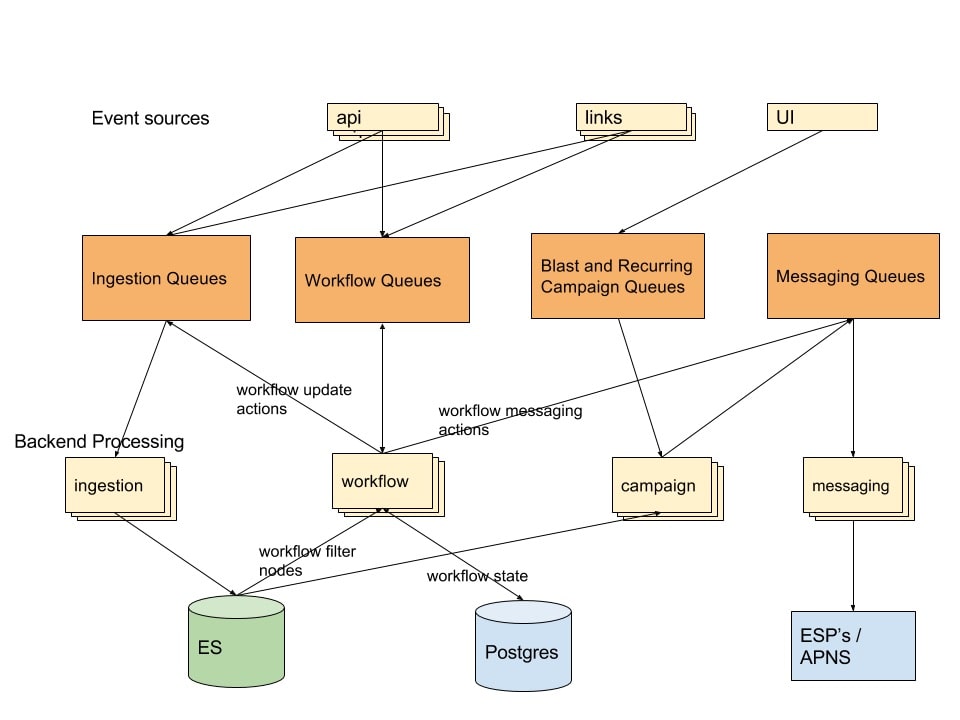
When we started evaluating Pulsar, all the queues mentioned above were on RabbitMQ, except for ingestion, which used Kafka. Kafka was a fit for ingestion, since it provided the necessary performance and ordering guarantees. Kafka was not a good fit for the other use cases, since it lacked the necessary work-queue semantics. The fact that we used many RabbitMQ-specific features like delays also made it more challenging to find an alternative.
As we scaled our system, RabbitMQ began to show the following limitations:
- At high loads, RabbitMQ frequently experienced flow control issues. Flow control is a mechanism that slows publishers when the message broker cannot keep up, usually because of memory and other resource limits. This impeded the ability of the producers to publish, which caused service delays and request failures in other areas. Specifically, we noticed that flow control occurred more often when large numbers of messages had TTLs that expired at the same time. In these cases, RabbitMQ attempted to deliver the expiring messages to their destination queue all at once. This overwhelmed the memory capacity of the RabbitMQ instance, which triggered the flow control mechanism for normal producers, blocking their attempts to publish.
- Debugging became more difficult because RabbitMQ's broker does not store messages after they are acknowledged. In other words, it is not possible to set a retention time for messages.
- Replication was difficult to achieve, as the replication component in RabbitMQ was not robust enough for our use cases, leading to RabbitMQ being a single point of failure for our message state.
- RabbitMQ had difficulty handling large numbers of queues. As we have many use cases that require dedicated queues, we often need more than 10,000 queues at a time. At this level, RabbitMQ experienced performance issues, which usually appeared first in the management interface and API.
Evaluating Apache Pulsar
Overall, Apache Pulsar appeared to offer all the features we needed. While a lot of the publicity we had seen around Pulsar had compared it to Kafka for streaming workloads, we also discovered that Pulsar was a great fit for our queueing needs. Pulsar's shared subscription feature allows topics to be used as queues, potentially offering multiple virtual queues to different subscribers within the same topic. Pulsar also supports delayed and scheduled messages natively, though these features were very new at the time we started considering Pulsar.
In addition to providing a rich feature set, Pulsar's multi-layered architecture allows us to scale the number and size of topics more conveniently than other messaging systems.
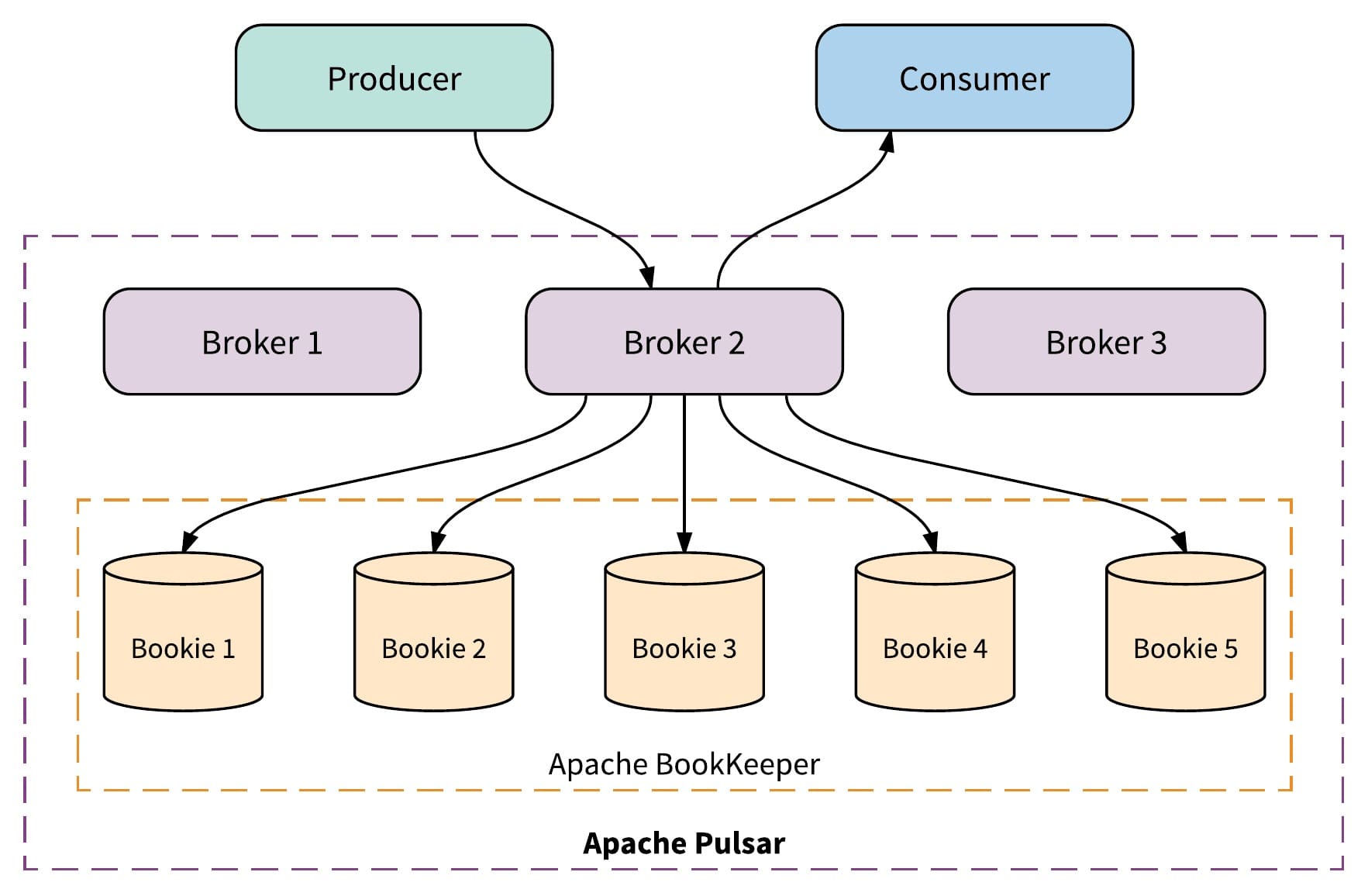
Pulsar's top layer consists of brokers, which accept messages from producers and send them to consumers, but do not store data. A single broker handles each topic partition, but the brokers can easily exchange topic ownership, as they do not store topic states. This makes it easy to add brokers to increase throughput and immediately take advantage of new brokers. This also enables Pulsar to handle broker failures.
Pulsar's bottom layer, BookKeeper, stores topic data in segments, which are distributed across the cluster. If additional storage is needed, we can easily add BookKeeper nodes (bookies) to the cluster and use them to store new topic segments. Brokers coordinate with bookies to update the state of each topic as it changes. Pulsar's use of BookKeeper for topic data also helps it to support a very large number of topics, which is critical for many of Iterable's current use cases.
After evaluating several messaging systems, we decided that Pulsar provided the right balance of scalability, reliability, and features to replace RabbitMQ at Iterable and, ultimately, to replace other messaging systems like Kafka and Amazon SQS.
First Pulsar Use Case: Message Sends
One of the most important functions of Iterable's platform is to schedule and send marketing emails on behalf of Iterable's customers. To do this, we publish messages to customer-specific queues, then have another service that handles the final rendering and sending of the message. These queues were the first thing we decided to migrate from RabbitMQ to Pulsar.
We chose marketing message sends as our first Pulsar use case for two reasons. First, because sending incorporated some of our more complex RabbitMQ use cases. And second, because it represented a very large portion of our RabbitMQ usage. This was not the lowest risk use case; however, after extensive performance and scalability testing, we felt it was where Pulsar could add the most value.
Here are three common types of campaigns created on the Iterable platform:
- Blast campaigns that send a marketing message to all recipients at the same time. Suppose a customer wants to send an email newsletter to users who have been active in the past month. In this case, we can query ElasticSearch for the list of users at the time the campaign is scheduled and publish them to that customer's Pulsar topic.
- Blast campaigns that specify a custom send time for each recipient. The send time can be either fixed — for example, "9AM in the recipient's local time zone" — or computed by our send-time optimization feature. In each case, we want to delay the processing of the queued message until the designated time.
- User-triggered campaigns. These can be triggered by a custom workflow or by a user-initiated transaction, such as an online purchase. User-triggered marketing sends are done individually on demand.
In each of the above scenarios the number of sends being performed at any given time can vary widely, so we also need to be able to scale consumers up and down to account for the changing load.
Migrating to Apache Pulsar
Although Pulsar had performed well in load tests, we were unsure if it would be able to sustain high load levels in production. This was a special concern because we planned to take advantage of several of Pulsar's new features, including negative acknowledgements and scheduled message delivery.
To build our confidence, we implemented a parallel pipeline in which we published messages to both RabbitMQ and Pulsar; in this case, we set up the consumers on these topics to acknowledge queued messages without actually processing them. We also simulated consumption delays. This helped us understand Pulsar's behavior in our particular production environment. We used customer-level feature flags for both test topics and actual production topics, so we could migrate customers one-by-one for testing and, ultimately, for production usage.
During testing, we uncovered a few bugs in Pulsar. For example, we found a race condition associated with delayed messages, which Pulsar developers helped to identify and fix. This was the most serious issue we found, as it caused consumers to get stuck, creating a backlog of unconsumed messages.
We also noticed some interesting issues related to Pulsar's batching of messages, which is enabled by default in Pulsar producers. For example, we noticed that Pulsar's backlog metrics report the number of batches rather than the actual number of messages, which makes it more challenging to set alert thresholds for message backlogs. Later we discovered a more serious bug in the interaction between negative acknowledgements and batching, which has recently been fixed. Ultimately we decided batching was not worth the trouble. Fortunately it's easy to disable batching in Pulsar producers, and the performance without batching was more than sufficient for our needs. These issues are also likely to be fixed in upcoming releases.
Delays and negative acknowledgements were relatively new features at the time, so we anticipated we might find some issues. This is why we chose to migrate to Pulsar slowly over many months, initially publishing to only test topics then gradually migrating real sends. This approach enabled us to identify issues before they could become problems for our customers. Although it took around six months to develop complete confidence that Pulsar was working as intended, the outcome was worth the time.
We migrated our entire marketing sends operation to Pulsar over the course of about six months. When migration was complete, we found that Pulsar reduced our operational costs by nearly half, with room to grow as we add new customers. The cost reduction was significant, in part, because our RabbitMQ instances had been overprovisioned to compensate for performance issues. To date, our Pulsar cluster has been running smoothly for over six months with no issues.
Implementation and Tooling
Iterable primarily uses Scala on the backend, so having good Scala tooling for Pulsar was important to us. We've used the excellent pulsar4s library and have made numerous contributions that support new features, such as delayed messages. We also contributed an Akka Streams-based connector for consuming messages as a source, with individual acknowledgement support.
For example, we can consume all the topics in a namespace like this:
// Create a consumer on all topics in this namespace
val createConsumer = () => client.consumer(ConsumerConfig(
topicPattern = "persistent://email/project-123/.*".r,
subscription = Subscription("email-service")
))
// Create an Akka streams `Source` stage for this consumer
val pulsarSource = committableSource(createConsumer, Some(MessageId.earliest))
// Materialize the source and get back a `control` to shut it down later.
val control = pulsarSource.mapAsync(parallelism)(handleMessage).to(Sink.ignore).run()
We like using regular expression subscriptions for consumers. They make it easy to automatically subscribe to new topics as they're created and make it so consumers don't have to be aware of a specific topic partitioning strategy. At the same time, we're also taking advantage of Pulsar's ability to support a large number of topics. Since Pulsar automatically creates new topics on publish, it's simple to create new topics for new message types or even for individual campaigns. This also makes it easier to implement rate limits for different customers and types of messages.
What We Learned
As Pulsar is a rapidly evolving open-source project, we had some challenges—mainly in getting up to speed and learning its quirks—that we might not have seen with other more mature technologies. The documentation was not always complete, and we often needed to lean on the community for help. That said, the community has been quite welcoming and helpful, and we were happy to get more involved with Pulsar's development and participate in discussions around new features.
Pulsar is unique in that it supports both streaming and queueing use cases, while also supporting a wide feature set that makes it a viable alternative to many other distributed messaging technologies currently being used in our architecture. Pulsar covers all of our use cases for Kafka, RabbitMQ, and SQS. This lets us focus on building expertise and tooling around a single unified system.
We have been encouraged by the progress in Pulsar's development since we started working with it in early 2019, particularly in the barriers to entry for beginners. The tooling has improved substantially: for example, Pulsar Manager now provides a very convenient GUI for managing the cluster. We also see many companies offering hosted and managed Pulsar services, which makes it easier for startups and small teams to start using Pulsar.
Overall, Iterable's transition to Pulsar has been interesting and sometimes challenging, but quite successful so far. In many ways, our use cases represented a new path that had not been widely pursued. We expected to encounter some problems, but our testing process helped minimize their impact on our customers. We now feel confident using Pulsar, and are continuing to expand our use of Pulsar for other existing and new components in Iterable's platform.


