
Key takeaways
- Huawei Device sought a message queue solution capable of meeting the diverse service requirements of HMS.
- Leveraging Apache Pulsar, Huawei Device developed a middleware platform that includes a unified SDK interface, a dynamic topic discovery mechanism, and consolidated authentication and authorization.
- After evaluating various disaster recovery models using Kafka and Pulsar, HMS concluded that Pulsar’s model better satisfied its need for high reliability, low latency, and cost-efficiency.
- To improve resource utilization, HMS implemented a shared storage pool to support Pulsar deployments on Kubernetes.
About HUAWEI Mobile Services
Huawei is a leading global provider of information and communications technology (ICT) infrastructure and smart devices. As a part of Huawei, Huawei Device provides key products for Huawei users, like smartphones, personal computers, wearable devices, and HUAWEI Mobile Services (HMS). Huawei Device aims to leverage HMS to enrich users’ lives with advanced content and services, catering to a wide array of needs in various fields such as smart homes, health and fitness, mobile offices, apps, smart travel, and entertainment. Notable services running on HMS include HUAWEI Health, AppGallery, HUAWEI Video, and HUAWEI Mobile Cloud.
Challenges
Huawei Device faced several challenges when selecting a messaging and streaming system for HMS.
Maintenance complexity
“HMS provides consumers with a diversified portfolio of services such as Smart Office, Fitness and Health, Easy Travel, and Entertainment,” said Lin Lin, SDE Expert at Huawei Device. “To support these services, we need to maintain different types of clusters for various scenarios. However, there is hardly an all-in-one message queue solution that can cover all the use cases and meet our requirements.”
The ideal messaging solution for Huawei Device should possess advanced capabilities as follows.
- Delay queues: Messages can be delivered at any time.
- Dead-letter queues: Messages can be automatically sent to dead-letter topics after a certain number of failed delivery attempts, preventing congestion in the current queue.
- Massive partitions: A single cluster should support a large number of partitions without affecting performance. This is particularly important in IoT scenarios where the cluster needs to serve numerous clients.
Cloud-native compatibility
“In a cloud-native era, organizations aim for high efficiency and low costs,” Lin explained. “Against this backdrop, our messaging system should feature excellent scalability so that it is compatible with cloud-native environments.”
The ideal solution should guarantee the following for HMS:
- Scaling should be complete within seconds.
- Scaling should not impact any ongoing business.
- Data replication during scaling doesn’t occur, or if it does, it doesn’t affect cluster availability.
Disaster recovery
Most disaster recovery solutions fall into two types:
- A single cluster across multiple availability zones, which can result in higher network latency and reduced overall performance when synchronizing data.
- Multiple clusters in separate availability zones, where users deploy identical active and backup clusters in separate availability zones. In case of a disaster, the standby cluster can take over. However, this deployment method for better redundancy has higher overhead.
“Redundancy is very important for disaster recovery scenarios. Unfortunately, it is not always easy to control your costs,” Lin added.
Resource utilization
A single cluster cannot support an unlimited number of topics or partitions. When traffic surges, clusters are unable to handle requests from multiple services. “To support different services, we choose to deploy a dedicated message queue cluster for each service,” Lin said. “As they are physically isolated, we can use more partitions and topics for a single cluster and avoid resource contention.”
Although using dedicated clusters solves the problem in some cases, it necessitates reserving resources, such as CPU and memory, potentially leading to low resource utilization. “Traffic peaks only occur on certain dates and you can utilize your resources to the maximum during that time. On the flip side, it also means a waste of resources when you have a low traffic volume,” Lin noted.
As an alternative, Huawei Device considered adopting a multi-tenant messaging system capable of supporting numerous topics and partitions within a single cluster. “We hope the new system allows us to isolate resources and is easy for operations and monitoring,” Lin said.
To overcome these challenges, Huawei Device ultimately opted for Apache Pulsar and created respective solutions with the messaging system.
A unified middle platform based on Apache Pulsar
To support HMS, message queues are now widely applied to various internal services and production systems, addressing common business scenarios such as asynchronous service decoupling, MQTT devices with high resource requirements, big data log streaming and analysis, and data exposure to external parties.
“To address the diverse requirements of different business scenarios, we looked to build a single architecture that can cover most use cases and reduce our development and operations workloads,” said Xiaotong Wang, Senior Software Engineer at Huawei Device. “Therefore, we created a unified middle platform based on Pulsar, which supports multiple client connections with a single cluster. For example, we are using Kafka-on-Pulsar (KoP) to support Kafka client connections.”
A unified SDK interface
For some internal clients, HMS provides a unified SDK that encapsulates standard messaging queue pub-sub interfaces. This way, the clients don’t need to know the actual protocol that the server is using.
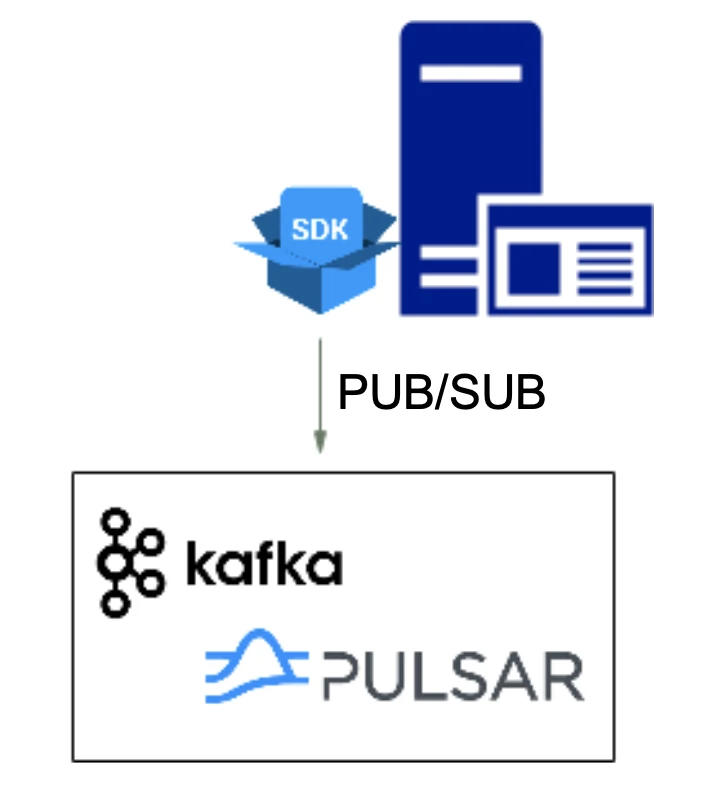
“One of the primary benefits is that if we change the protocols or authentication and authorization modes on the server side, we don’t need to make any changes to our clients,” Wang explained. “They only need to focus on the data that they send and the topics that they access.”
Dynamic topic discovery
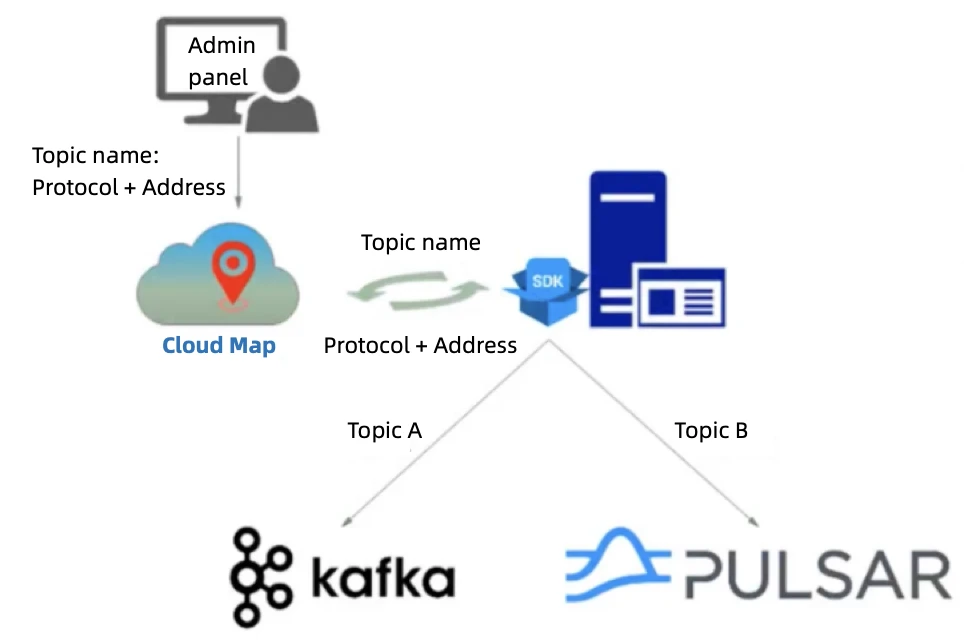
When a service needs to access multiple topics across different clusters, the conventional approach may require configuring multiple cluster addresses for the topics on local files, which can be redundant and difficult to manage. “It is unacceptable to make changes to clients when something like cluster migration, scaling, or node failure happens on the server side,” Wang emphasized.
To address this issue, Huawei Device uses a Cloud Map-based topic registration and discovery mechanism. All topic-related operations such as creation, partition scaling, and migration, are managed through a centralized administration panel. “We register the basic information of topics to a configuration center in Cloud Map and it is dynamically updated,” Wang said. “This way, clients can dynamically connect to the appropriate IP address without impacting themselves.”
Unified authentication and authorization
The message queues powering HMS have varied implementations for authentication and authorization for a wide range of scenarios, such as SSO Kerberos for big data services. The Pulsar-based platform supports common authentication and authorization models for different data sources. To ensure consistent authentication across the platform, Huawei Device extended Pulsar’s support for SCRAM-SHA-256 authentication when integrating it.
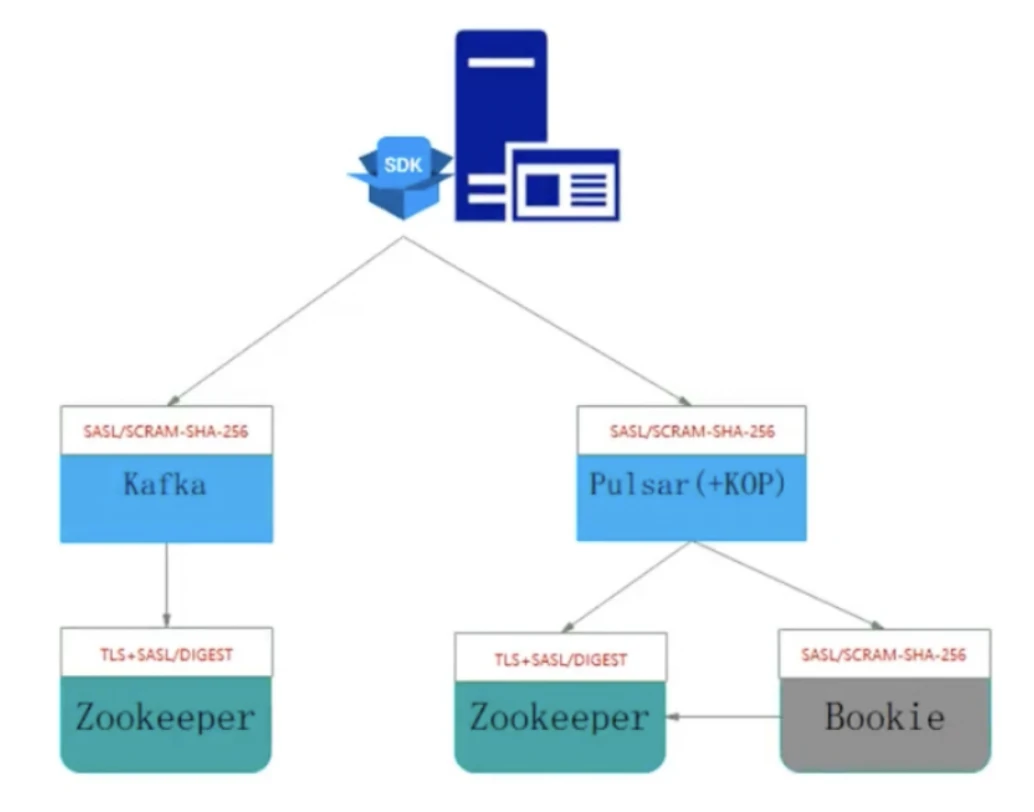
“As Pulsar doesn’t support SCRAM-SHA-256 authentication by default, we added the support internally for both brokers and bookies,” Wang said. For interactions between brokers/bookies and ZooKeeper, Huawei Device adopts SASL authentication with TLS encryption to safeguard against credential exposure.
Choosing Pulsar over Kafka: Scalability and load balancing
Previously, Huawei Device used Kafka to power its message queues. By default, Kafka does not automatically migrate traffic during horizontal scaling. “Newly-added nodes in Kafka can’t handle requests immediately and require operators to manually rebalance partitions,” Wang explained. “For data migration, we need to set a rate limit. The challenging part is determining the appropriate threshold. If it is too large, our clients may experience performance issues for reads and writes; if it is too small, the entire migration process may be too long and it requires human intervention.”
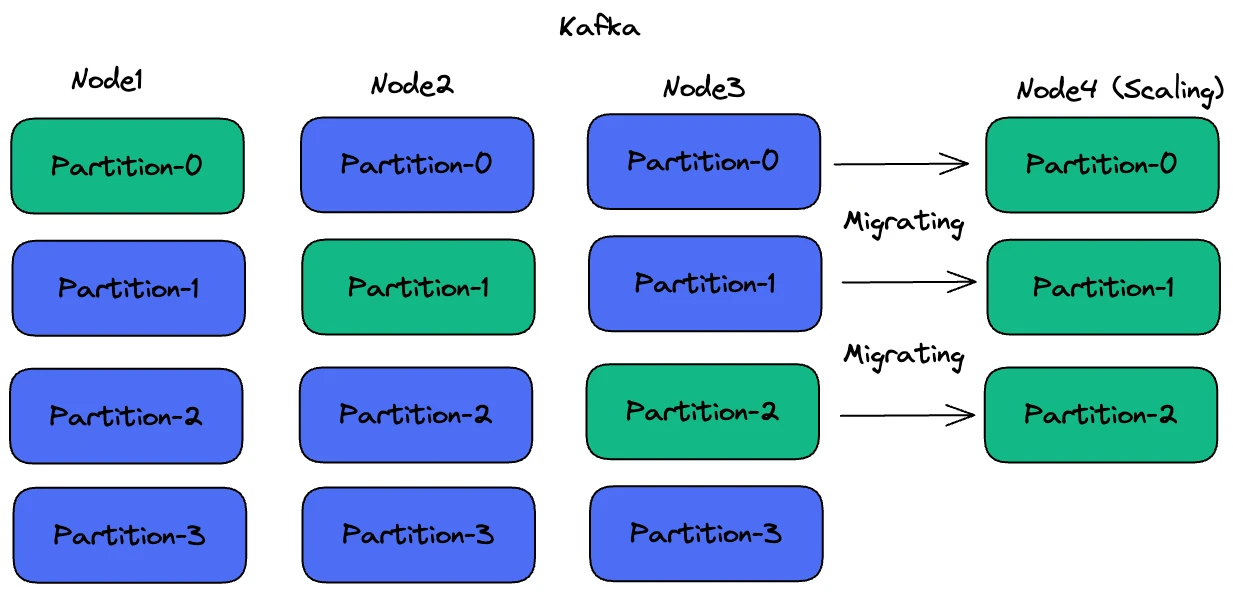
Due to these scaling difficulties, Wang’s team opted to scale up Kafka clusters by adding more CPU or disk resources, rather than scaling out. If this wasn’t feasible, Wang admitted that they had to create a new cluster. “Creating another cluster for data migration leads to extra operational costs. It also means that we may need to maintain multiple clusters for a single business module as it grows,” Wang added.
In contrast to Kafka, Pulsar separates computing from storage, which is powered by another open-source project, Apache BookKeeper. When a new node (bookie) joins the cluster, it is immediately available to serve writes. Messages are evenly stored across bookies and historical data is smoothly removed according to the configured retention and expiry policy.
“Scaling out a Kafka cluster might require a few hours. Even if we decide to create a new cluster and migrate topics to it, the process can still take tens of minutes,” Wang said. “By contrast, BookKeeper only takes a couple of minutes to finish scaling.”
Pulsar also distinguishes itself from Kafka in terms of load balancing. In Kafka, topic partitions are essentially bound to brokers, meaning human intervention may be necessary for load balancing. In the event of node failures, operators must manually migrate impacted partitions to another node. When traffic is not evenly distributed across Kafka brokers, operators may need to rebalance partitions themselves.
“To solve the load balancing pain points when using Kafka, our operators attempted to place topics for different services on separate machines, thereby physically isolating them,” Wang added. “However, this approach could result in additional maintenance overhead.”
Pulsar achieves load balancing with an automatic load-shedding mechanism. Users can set a threshold and an overloaded broker will unload the excess traffic to other nodes. Pulsar supports three types of strategies - ThresholdShedder, OverloadShedder, and UniformLoadShedder.
“In Pulsar, if a broker goes down, the partition previously owned by the broker will be automatically transferred to another broker,” Wang said. “To balance traffic, we can choose different strategies based on various algorithms or factors, such as resource usage averages.”
When using Pulsar’s load-balancing strategies, Wang found it difficult to set an appropriate traffic threshold. For instance, using a low threshold value might lead to frequent traffic rebalancing. To address this issue, Wang’s team redesigned Pulsar’s rebalancing algorithms, which reduced the load difference between brokers to less than 10% and increased the overall resource utilization by approximately 30%. Currently, they are working on a proposal and look to submit it to the Pulsar community.
Building a disaster recovery strategy: Kafka vs. Pulsar
To address challenges in disaster recovery, Wang’s team looked to design a strategy featuring high reliability, low latency, and low costs. The messaging system must remain available during a single AZ failure with three replicas.
High reliability
“When using Kafka with acks=all, the ISR (in-sync replica) algorithm requires all broker nodes in the ISR list to complete synchronization before responding to the client,” Wang said. “Consequently, network fluctuations across AZs can impact Kafka’s write performance and latency. However, this approach offers high reliability, tolerating single AZ failures without making the message queue unavailable.”
For Pulsar, Wang’s team created a policy with similar reliability while it was less affected by network instability. In this setting (Figure 5), bookies are assigned AZ labels and they are selected as follows:
- Randomly select a bookie from the available nodes, such as Bookie1 from AZ1.
- For the second replica (exclude Bookie1), randomly select one from AZ2 and AZ3, such as Bookie3.
- For the third replica (exclude all bookies in AZ1 and AZ2), select Bookie5 from AZ3.
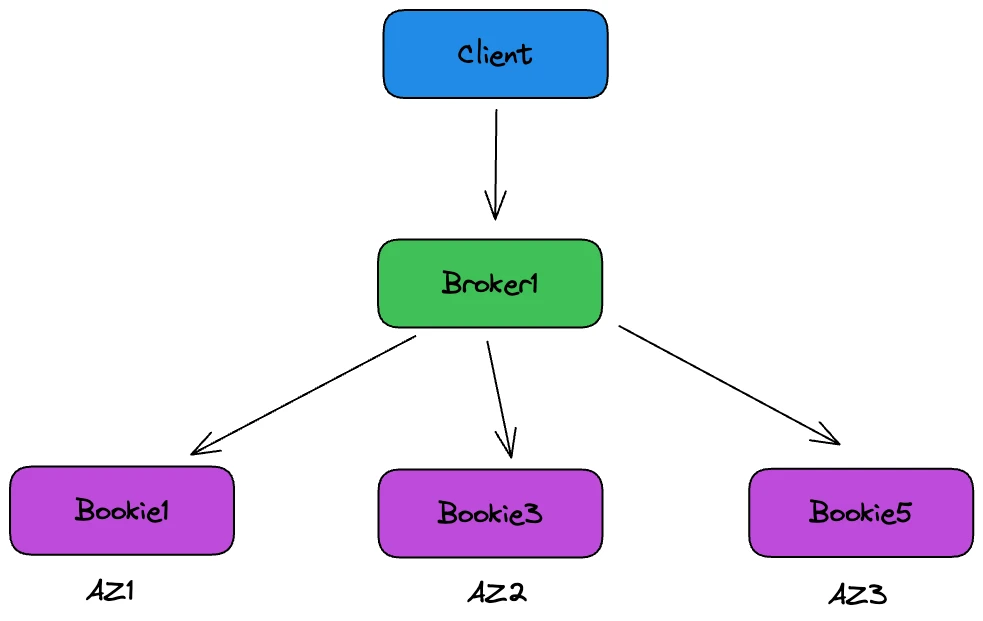
For an ack quorum of 2, this setup ensures that the client receives a successful message write response once any two AZs have completed writing. “One advantage Pulsar offers over Kafka is that it requires only two AZs to succeed in writing data before responding as successful, whereas Kafka’s ISR mechanism necessitates all three AZs in the list to complete the write. Thus, writes to Pulsar are less affected by inter-AZ network fluctuations compared to Kafka,” Wang added.
Low latency and costs
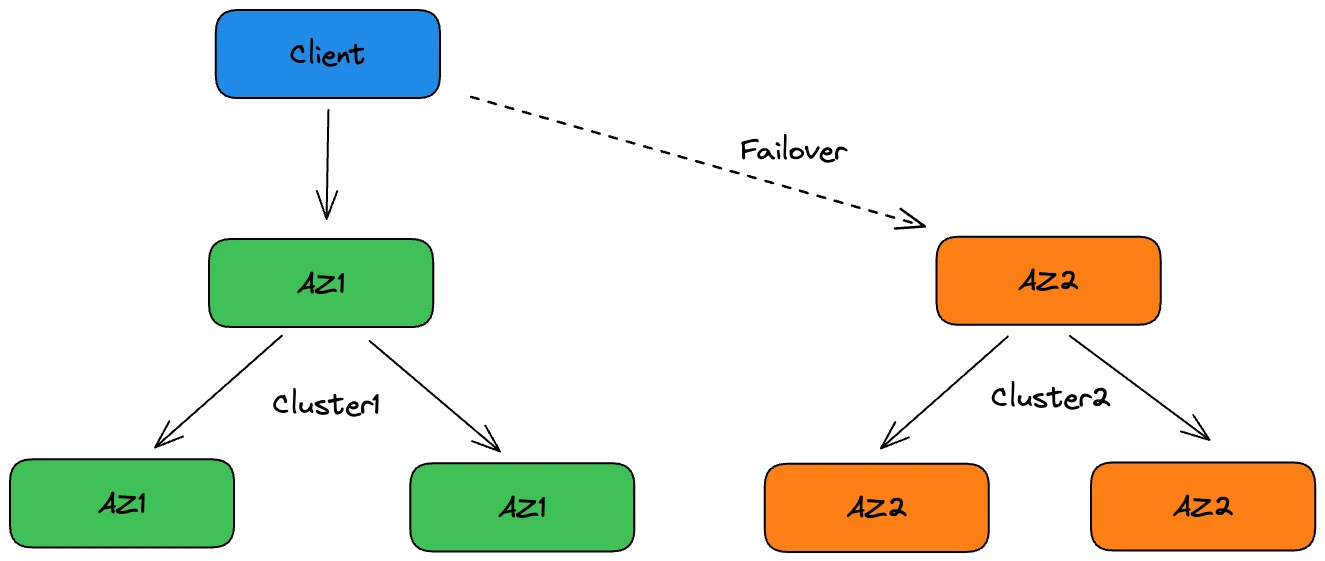
Some HMS services may require low latency and can tolerate slight data inconsistencies during a single AZ failure while message queue availability must be guaranteed. For this use case, Wang’s team designed different settings for both Kafka and Pulsar.
For Kafka, inter-AZ network fluctuations can lead to unstable writing latency for a multi-AZ cluster. Therefore, Huawei Device deployed independent Kafka clusters within each AZ, without any data synchronization between them. One of them served as a backup, such as Cluster2 in AZ2 in Figure 6, ensuring service availability during AZ1 failures. However, this solution results in resource waste and difficulty in maintaining data consistency during cluster switches.
For Pulsar, Wang’s team created a two-AZ deployment configuration that meets low-latency requirements while allowing for slight data inconsistencies during a single AZ failure (see Figure 7 for details). “We optimized Pulsar by supporting AZ labels for brokers and adjusting the bookie selection process,” Wang explained.
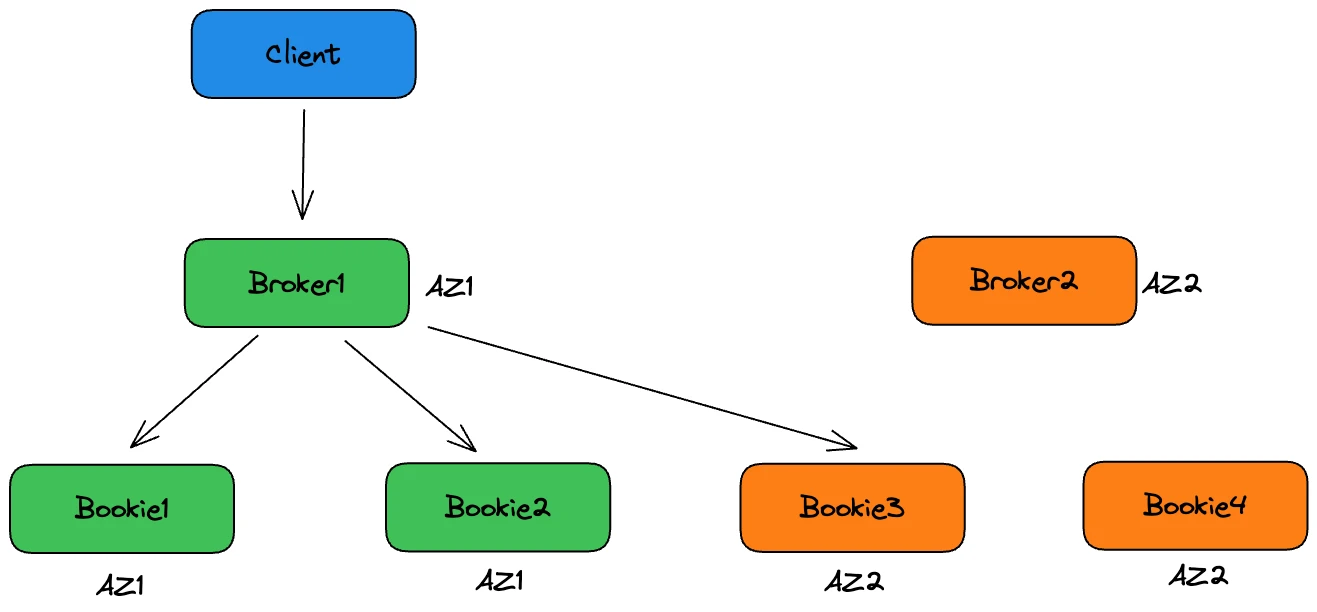
With the updated logic, bookies are selected in the following way.
- Randomly select a bookie from the available nodes, such as Bookie1 from AZ1.
- For the second replica (exclude Bookie1), randomly select one from AZ2, such as Bookie3.
- For the third replica, although there is no bookie to select from other AZs, the updated logic allows Pulsar to check the label of brokers (for example, AZ1 of Broker1) and write the last copy to another available bookie in AZ1, like Bookie2.
With an ack quorum of 2, writes are still considered successful even if data is replicated within the same AZ (Bookie1 and Bookie2), providing low write latency with minor data inconsistencies. “The benefit of using Pulsar with this setting is that the cluster remains available when an AZ fails and you don’t need to create a backup cluster,” Wang said. “Unlike Kafka, Pulsar allows better use of cluster resources.”
However, using a single Pulsar cluster across multiple AZs does not guarantee zero downtime. In a few cases, a shared backup cluster is still needed, but it is only used in specific scenarios as follows:
- Unexpected bugs
- Slow cluster automatic recovery
- Simultaneous failures in multiple AZs
- Untimely bookie scaling
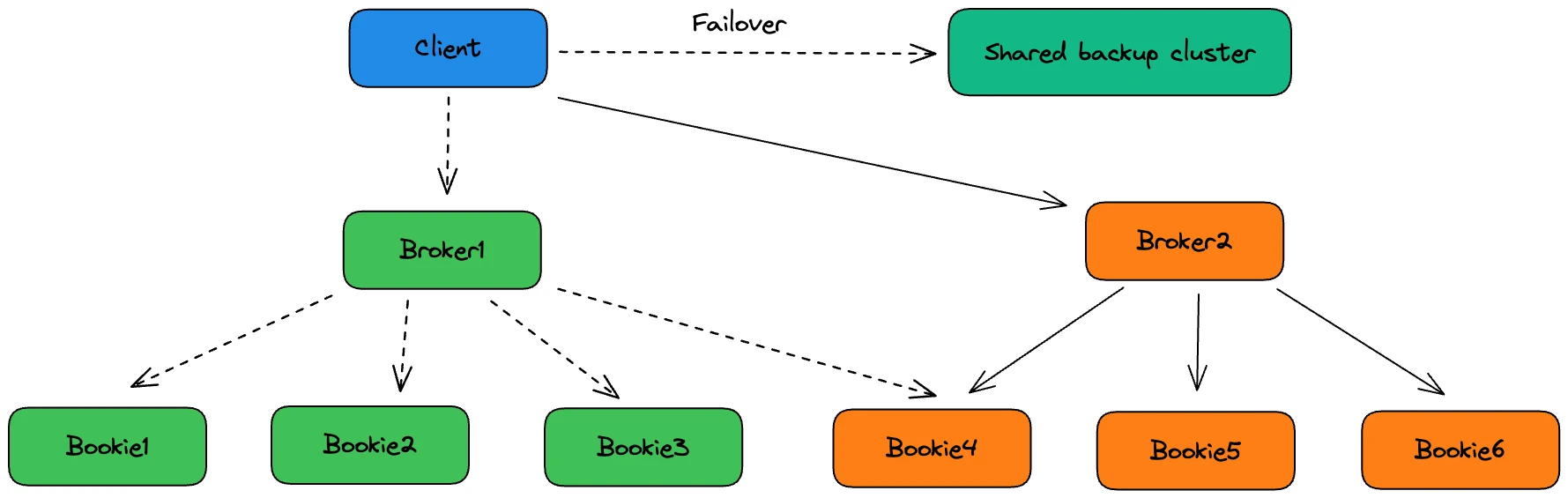
“Using the Pulsar-based disaster recovery strategy, we have increased CPU utilization from 20% to 40%,” Wang noted. “Unlike Kafka, the Pulsar backup cluster is shared so that we can significantly reduce resource waste.”
Containerization for better resource utilization
In order to optimize resource utilization, Huawei Device decided to containerize the messaging system for HMS. Pulsar’s stateless brokers make it much easier to migrate workloads onto Kubernetes. “Thanks to its decoupled architecture, Pulsar enables us to dynamically scale the number of brokers and adjust CPU or memory resources as required, thereby maximizing resource utilization,” Wang explained.
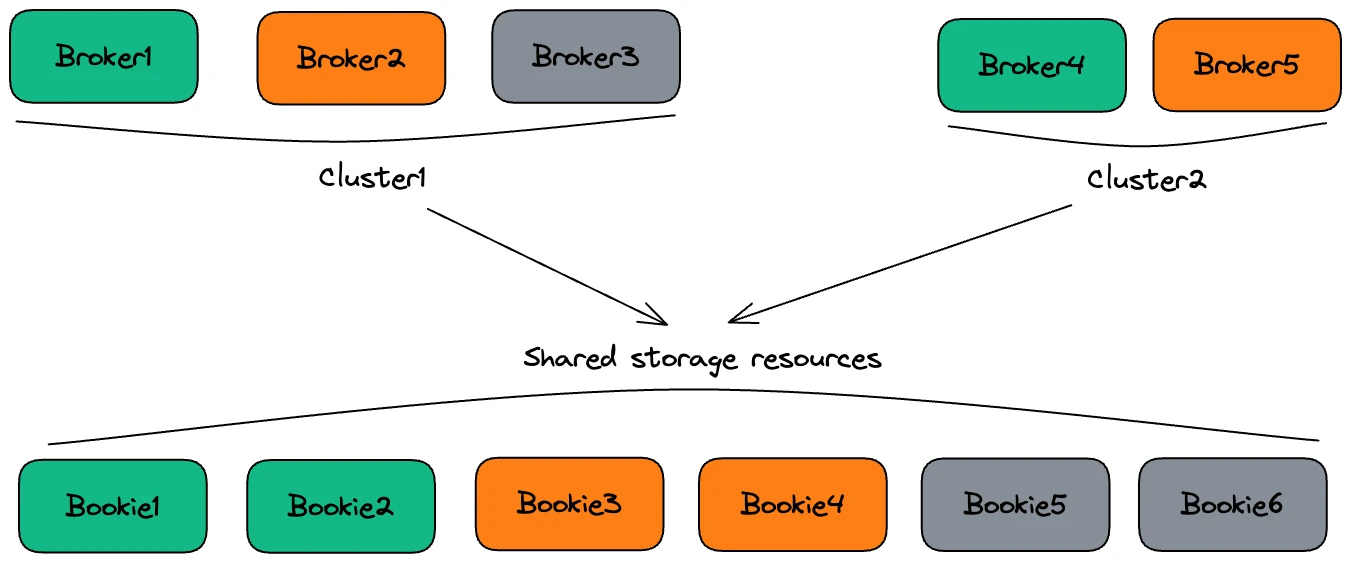
Furthermore, Huawei Device has created a unified bookie node pool to support multiple broker clusters. “With a shared bookie pool, we can effectively utilize cluster storage resources and enhance our capacity to handle unexpected traffic spikes,” Wang noted.
Conclusion
Huawei Device has successfully adopted Pulsar as the unified middle platform powering HMS, leveraging its unique capabilities to address its challenges and requirements. With Pulsar, Huawei Device has improved operation efficiency, achieved better scalability, established an effective disaster recovery strategy, and optimized resource utilization.


