
Key takeaways
- iFLYTEK was looking for a flexible and scalable message queue system to support over 100 products and enhance SRE efficiency.
- Apache Pulsar stood out as iFLYTEK’s top choice due to its robust geo-replication, multi-tenancy, and user-friendly operation capabilities.
- iFLYTEK seamlessly integrated Pulsar into its SRE system to facilitate tasks such as resource allocation, traffic throttling, and monitoring and alerting.
- Leveraging Pulsar to support more than 100 product lines, iFLYTEK has amplified its traffic by four to five times while reducing maintenance costs by 30%.
Background
Founded in 1999, iFLYTEK is a well-known intelligent speech and artificial intelligence company in the Asia-Pacific region. Since its establishment, it has been focused on the research and development of speech and language technologies. As iFLYTEK works to benefit more people with artificial intelligence, it has achieved world leading positions in natural language understanding, machine learning, machine reasoning, adaptive learning, and many more.
Figure 1 shows iFLYTEK’s business structure. On the service layer, its PaaS team ingests data via web APIs or SDKs, and then sends it to message queues (for example, RocketMQ, RabbitMQ, and Pulsar) to rebalance traffic for upstream and downstream usage. The team hopes that these systems can provide high throughput and low latency services to over 100 products. Processed data are stored in databases like MySQL and Apache HBase.
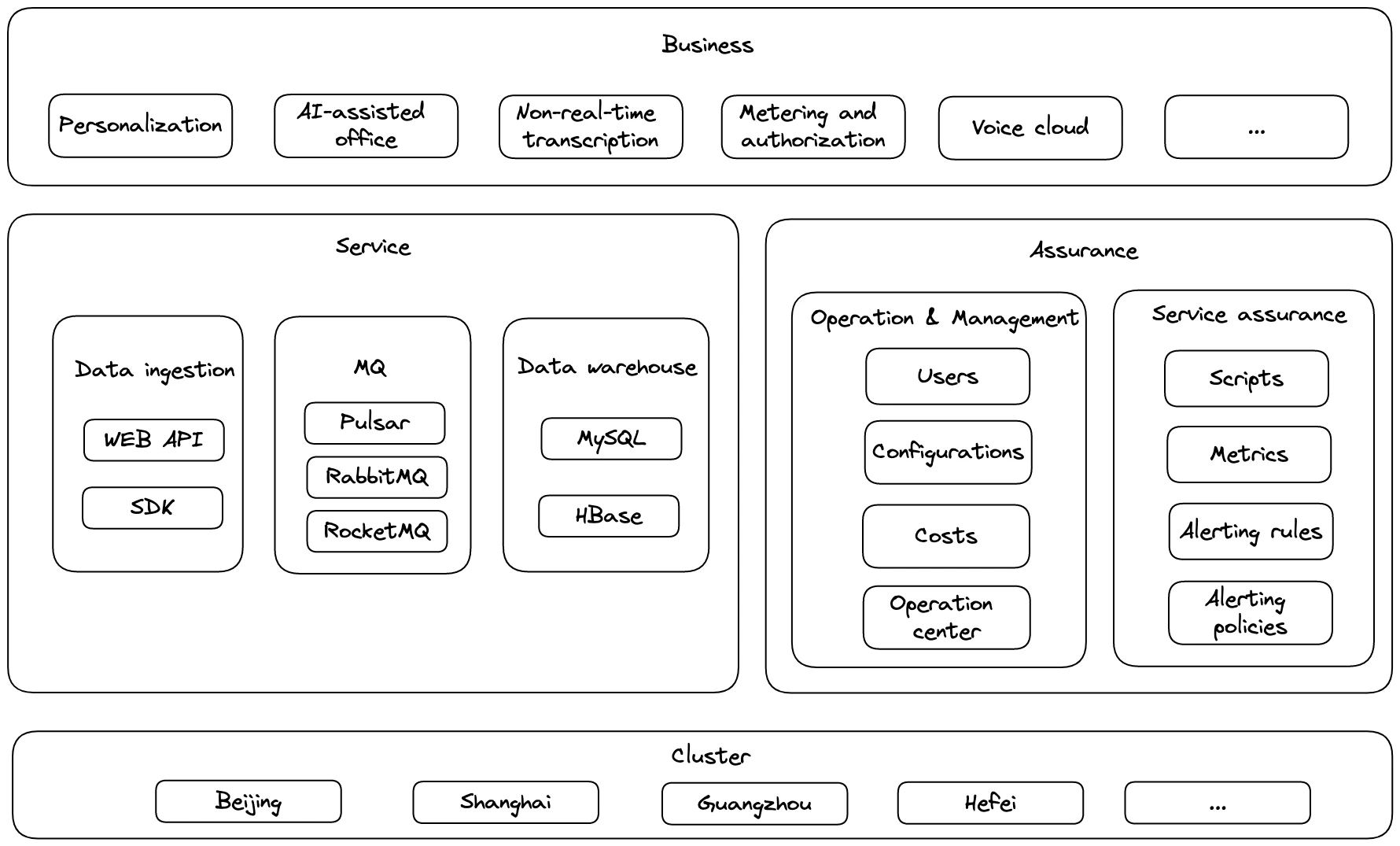
To support the service layer, iFLYTEK uses their own operation and management platform and service assurance platform for SRE (Site Reliability Engineering). The former is responsible for unified management of cluster services, and the latter handles scripts, metrics, alerting policies, and so on.
Challenges
Previously, the iFLYTEK PaaS team had the following challenges in service assurance.
- Service clusters might become unstable when traffic grew drastically (by over 10 times).
- The loads on old and new brokers were unbalanced during cluster scaling, which might impact upstream and downstream business.
- It was difficult to achieve great idempotency and low latency for data synchronization across availability zones.
- Maintaining multiple clusters and troubleshooting tickets was costly and time-consuming.
Apart from addressing the challenges, they also looked to improve the efficiency of their SRE system regarding the following aspects.
- Introduce a tiered service assurance solution for 100+ products powered by the messaging system.
- Lower the latency for end-to-end data writes and synchronization.
- Standardize the process to integrate business with message queues.
- Enhance SRE sustainability.
- Reduce costs and increase efficiency.
“As we have over 1 billion messages to process per day, our system unavoidably needs an efficient middleware solution for guaranteeing high throughput and low latency,” said Kan Liu, Software Engineer at iFLYTEK, focusing on SRE and service assurance. “Our cross-regional system also requires accurate data synchronization across various availability zones.”
Why Apache Pulsar
“To address these challenges and improve our SRE system, we compared several popular message queues and selected Apache Pulsar,” Liu added. “Pulsar is a cloud-native, next-generation messaging and streaming system with many useful features for our use case, like multi-tenancy and geo-replication.” Specifically, Pulsar won the most votes within the organization with the following capabilities.
- Traffic aggregation: Route traffic of multiple small clusters all to Pulsar.
- Simple operations and maintenance: Improve productivity and inform data-driven decisions for business.
- Storage-compute separation: Easy to scale brokers and bookies separately.
- Multi-tenancy: Isolate different products with better resource utilization.
- Geo-replication: Efficient synchronous and asynchronous replication across regions.
- Multi-language SDKs: Support Go, Java, and Python with an active community contributing to these languages.
High-efficient SRE integrated Apache Pulsar
iFLYTEK started its exploration of Pulsar in July 2021 regarding its features, feasibility, and implementation and found it a promising candidate. Two months later, iFLYTEK developers ran stress tests on Pulsar to understand whether the messaging system can meet their needs for production traffic. This way, they could adjust the overall architecture and optimize related configurations to avoid potential problems. In February 2022, they fine-tuned Pulsar, and their Pulsar-integrated system finally went live one month later.

This section introduces the details of how iFLYTEK explored and implemented Pulsar, how Pulsar was integrated with its SRE system, as well as iFLYTEK’s experience in fine-tuning Pulsar for production.
Tiered service assurance
For better reliability and availability of Pulsar, iFLYTEK introduced a tiered service assurance system. Table 1 gives an overview of the availability requirements for different products.
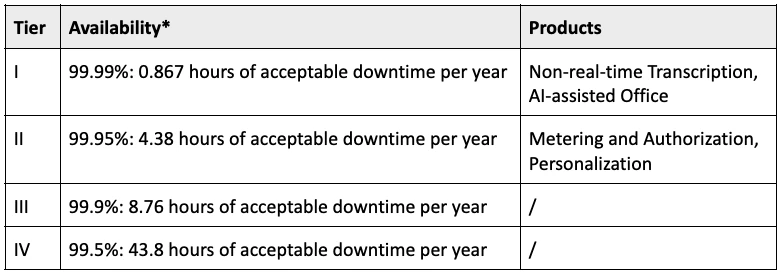
*Availability = (Total Service Time - Accumulative Downtime) / Total Service Time
Implementing Pulsar for SRE
SRE is a set of practices and principles that help organizations ensure high availability, low latency, and stability internally. SRE tasks require employees at different levels to cooperate with each other.
The SRE system of iFLYTEK contains two important parts, MTBF (Mean Time Before Failure) and MTTR (Mean Time To Repair). MTBF represents the duration between failures for devices that require reparation. The SRE team further separates it into Pre-MTBF and Post-MTBF for failure prevention and improvements respectively. MTTR measures the time period to repair the failed devices and it contains MTTI (Mean Time To Identify), MTTK (Mean Time To Know), MTTF (Mean Time To Fix) and MTTV (Mean Time To Verify); it is where failure recovery happens. See Figure 3 for details.
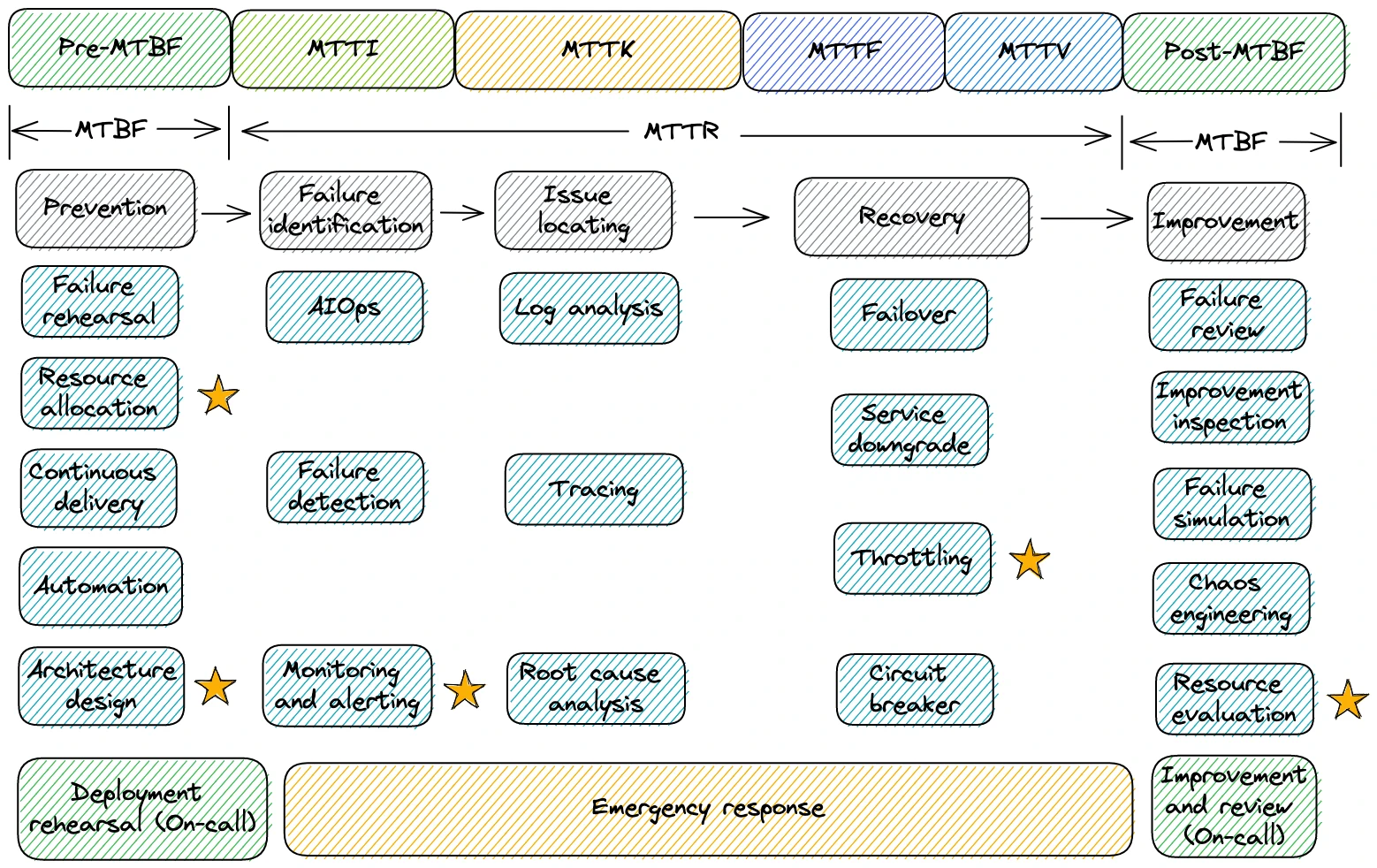
Each stage is aimed at dealing with specific SRE tasks. The following sections detail some important modules (marked by a star in Figure 3) to ensure Pulsar’s high availability and stability.
Architecture design
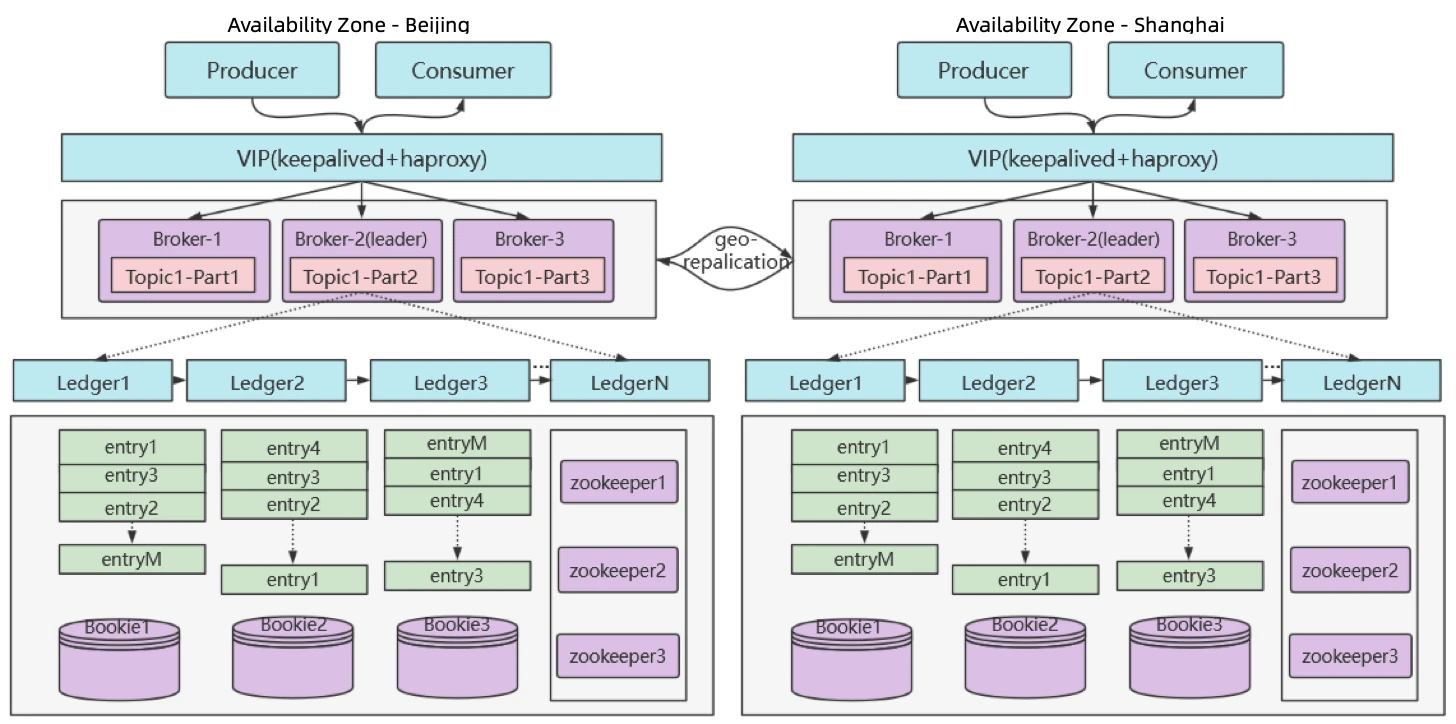
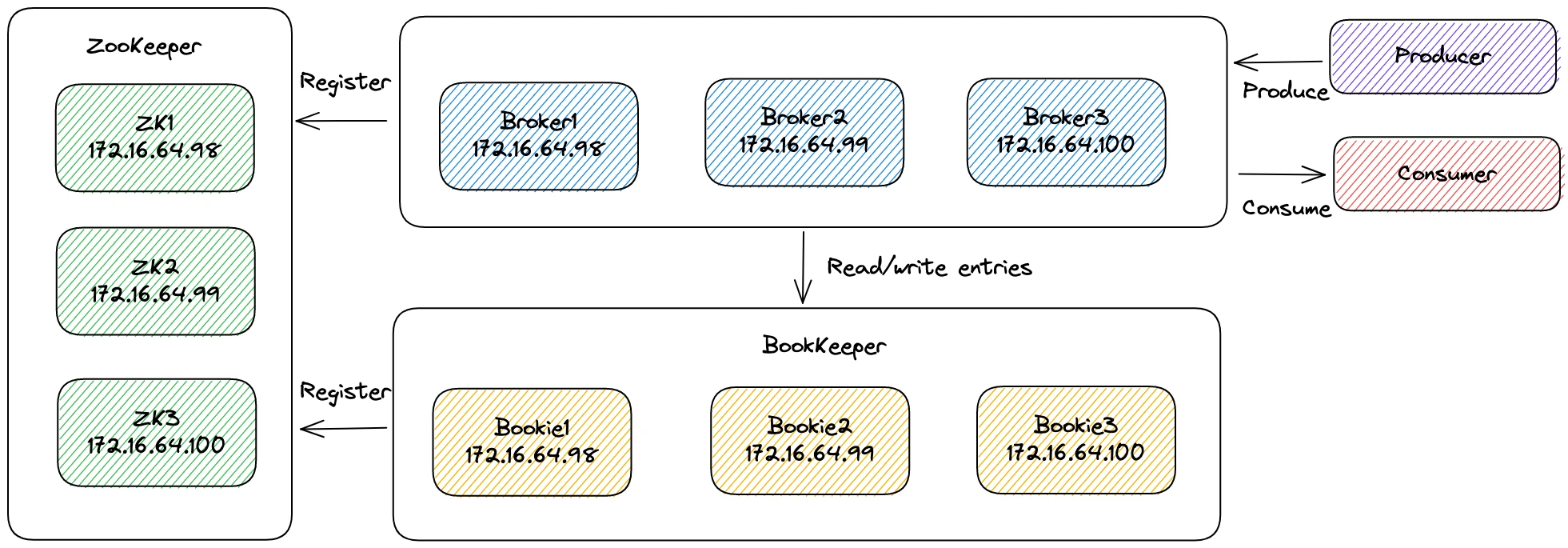
At iFLYTEK, Pulsar is deployed in multiple availability zones. The client communicates with the cluster through virtual IP addresses (VIP). On the broker layer, the node that owns the target topic handles the request. The broker replies to the client with the information of the connection established. BookKeeper powers Pulsar’s storage layer, which contains a number of storage nodes, or bookies. The cluster’s metadata is stored in ZooKeeper.
“We use Pulsar’s geo-replication feature to synchronize data across multiple availability zones,” Liu explained. “Our architecture adopts a hybrid deployment where brokers, bookies, and ZooKeeper run on the same machines, ensuring low latency for reads and writes when these components interact with each other.”
Traffic evaluation and resource allocation
When integrating a new product line with the existing Pulsar cluster, it is crucial to evaluate whether the cluster is capable of serving the traffic without affecting the overall performance. Therefore, developers at iFLYTEK evaluated cluster performance, mainly focusing on read and write rates, message size, traffic peaks, data replication, and backlogs. Table 2 shows some of the evaluation results.
“At iFLYTEK, we have many products with different requirements for traffic. We were wondering if Pulsar could meet these needs especially when our traffic grows. Therefore, we ran some tests to monitor key metrics like read/write rate and message size,” Liu said. “Additionally, we designed a model to simulate specific scenarios and obtained some useful results. With these statistics, we look to make informed resource allocation decisions.”
Figure 5 depicts the model that iFLYTEK designed to test messaging production and consumption. It used three identical physical machines, with brokers, bookies, and ZooKeeper all deployed on the same nodes.
- Operating system: Linux version 3.10.0-957.el7.x86_64
- CPU: 48 Intel(R) Xeon(R) CPU E5-2650 v4@ 2.20GHz
- Memory: 188 GB
- Disk: 6*960 GB SSD
- Network: 10 Gigabit network card
Using this model, iFLYTEK developers carried out tests in two scenarios where messages were only produced but not consumed with a duration of 30 minutes. Journals and ledgers were stored in individual disks. The difference between the two scenarios was the flush type - asynchronous and synchronous. Table 3 and Table 4 list their respective results.
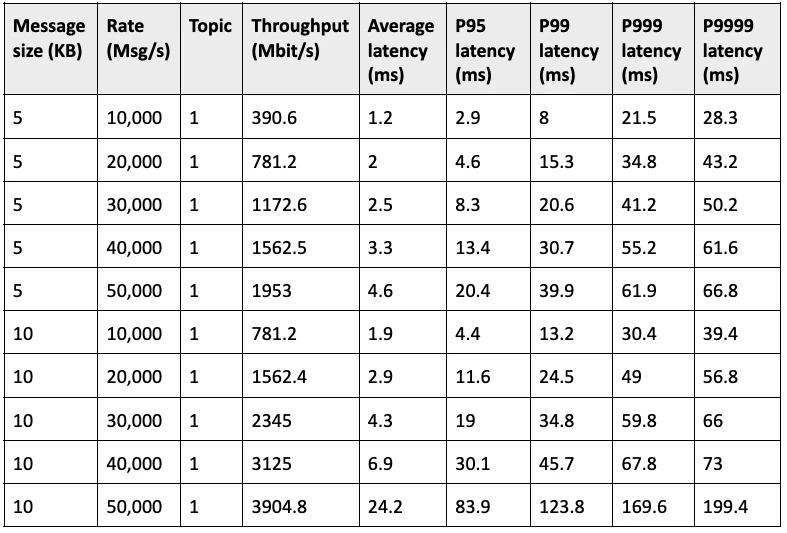
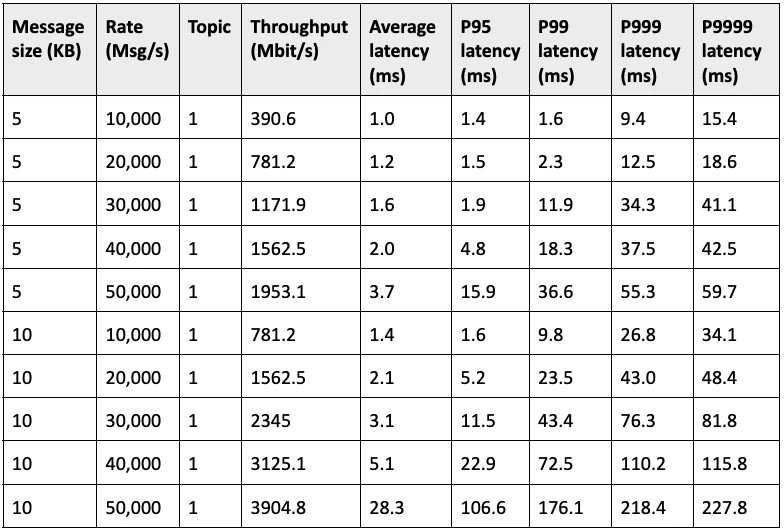
“The results show that as more messages were produced, the latency increased accordingly,” Liu said. “Based on the results, we disabled asynchronous flushes in our production environment. The important thing is that no matter which one you choose, you need to test the performance first for your own scenario.” With a basic understanding of Pulsar’s performance, Liu’s team proposed the following hardware configurations for their production use case.
- Physical machine configuration: 48-core CPU, 256 GB of memory, and 10 Gigabit network card. Each machine has 6 SSDs attached and uses separate disks for ZooKeeper, journals and ledgers.
- A separate SSD for ZooKeeper’s log and datalogs to ensure low read and write latency.
- Two separate SSDs for BookKeeper’s journalDirectories for better redundancy and concurrency during traffic peaks.
- Three separate SSDs for BookKeeper’s ledgerDirectories to reduce latency during ledger rollovers.
Monitoring and alerting
At iFLYTEK, monitoring and alerting represents an important part at its MTTI stage. The monitoring and alerting system is built on the back of modularized microservices, with each module only handling its respective tasks. This system is composed of different components, including PaaS-Agent for monitoring, PaaS-Collector for data collection and processing, PaaS-Probe for cluster availability metrics collection, PaaS-Alert for altering, and PaaS-Report for reporting. Figure 6 depicts the schematic architecture of the system.
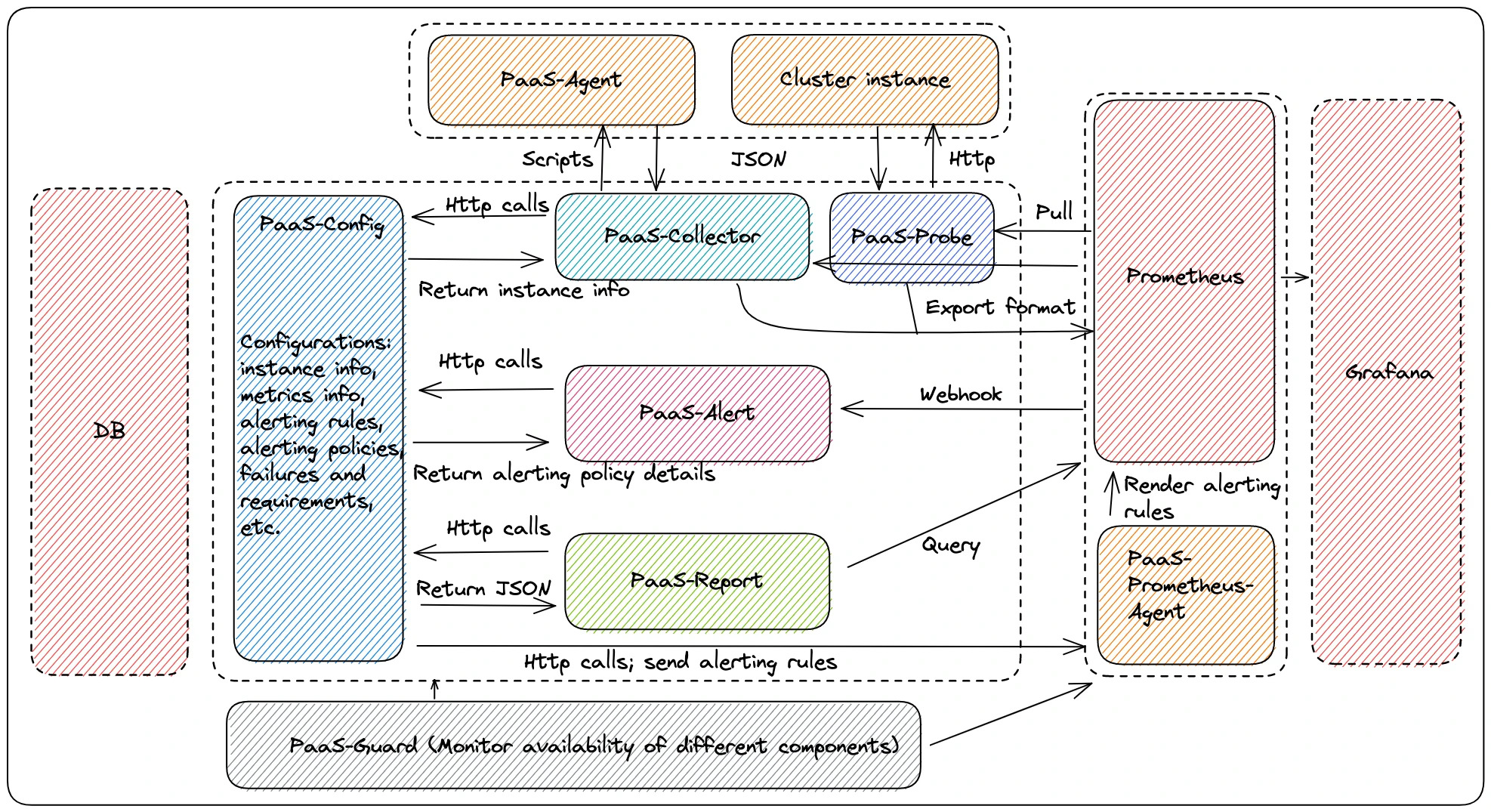
Data flows in from servers to PaaS-Agent, and is collected first by PaaS-Collector and then Prometheus. When it arrives at PaaS-Alert, the system checks whether the current status reaches the threshold based on alerting rules and policies in PaaS-Config.
“We built a comprehensive system for better observability of our Pulsar cluster,” Liu noted. “Our system supports alerts at different severity levels, like critical and intermediate. When certain thresholds are reached, we know exactly what happened and can take action accordingly if necessary.” The monitoring and alerting system has the following features.
- Support monitoring across multiple availability zones where Pulsar is deployed
- Cluster information is synchronized automatically
- Alerting policies can be added and implemented automatically
- Support custom alerting rules
- Support different alert channels like SMS, email, and WeChat messages
- Support daily, weekly and monthly reports
- Second-level latency
To improve troubleshooting efficiency, Liu’s team focuses on the following metrics about brokers, bookies and ZooKeeper. The most important ones to them are marked with an asterisk (*).
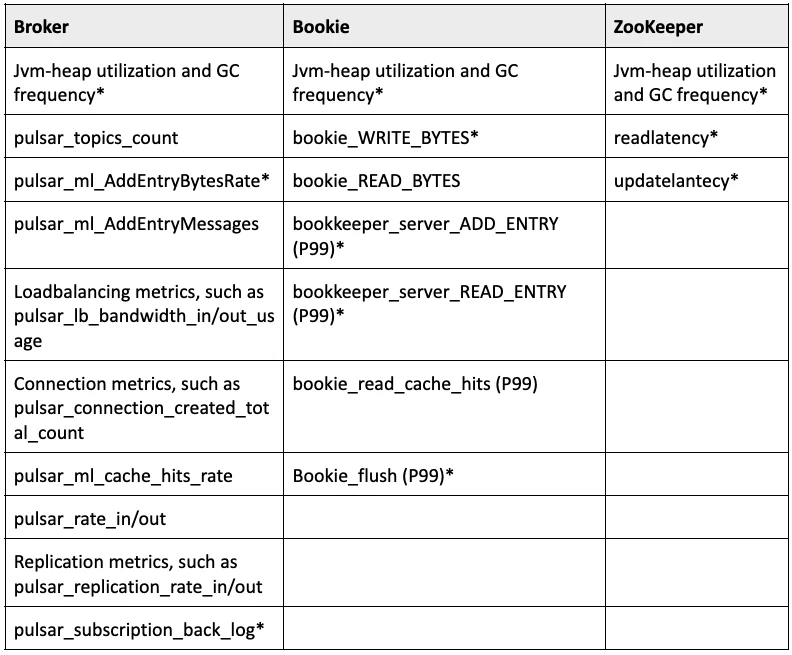
For detailed information about each metric, see the Pulsar documentation.
Traffic throttling
Traffic throttling strategies are used to prevent the cluster from crashing when traffic soars. “At iFLYTEK, we evaluate flow peaks based on the specific requirements of products and then adjust our throttling strategy to a manageable range for producers,” Liu said. “This helps us better utilize cluster resources, such as disks and bandwidth, and ensure cluster stability.”
For example, Liu’s team imposes flow limits on Pulsar namespaces. As shown in the code snippet below, the maximum traffic volume set for all the topics in the namespace is 50 MB. This means any incoming message will be refused once the threshold is reached.
"autoSubscriptionCreationOverride" : {
"allowAutoSubscriptionCreation" : true
},
"publishMaxMessageRate" : {
"dx" : {
"publishThrottlingRateInMsg" : -1,
"publishThrottlingRateInByte" : 52428800
}
},
"latency_stats_sample_rate" : { },
"subscription_expiration_time_minutes" : 0,
"deleted" : false,
"encryption_required" : false,
"subscription_auth_mode" : "None",
"max_subscriptions_per_topic" : 1,
Problems and fine-tuning
Not every step in iFLYTEK’s adoption of Pulsar was simple and smooth. During this process, Liu’s team encountered problems but found the optimal solution to their use cases. Here are some of their fine-tuning practices of Pulsar in production.
Problem 1: Bookies become read-only when a single large message is written to Pulsar.
Analysis: Brokers and bookies have different configurations to limit the message size. The messages sent by the client can be consumed by the broker but may be refused by the bookie, thus triggering the retry on the broker side.
Solution: Adjust dispatcherMaxReadSizeBytes and nettyMaxFrameSizeBytes. For more information about these two parameters, see Pulsar configuration.
Problem 2: When a disk is allocated to ZooKeeper for data and datalog directories, as well as bookie’s journals and ledgers, the read and write performance declines.
Analysis: In some cases, the I/O of journals and ledgers of will see an upsurge, causing a higher read and write latency in ZooKeeper.
Solution: Use separate disks for ZooKeeper and bookies.
Problem 3: Unbalanced loads on brokers.
Analysis: Pulsar brokers support three types of load shedding strategies - OverloadShedder, ThresholdShedder, and UniformLoadShedder. In Pulsar 2.10.0 and earlier versions, OverloadShedder is the default behavior. It sheds exactly one bundle on overloaded brokers whose maximum resource usage exceeds loadBalancerBrokerOverloadedThresholdPercentage (it defaults to 85%). When multiple brokers nearly reach the threshold, bundles may be offloaded repeatedly across these brokers.
Solution: Use ThresholdShedder as the load shedding strategy. It takes into account a series of factors such as bandwidth, CPU, and memory. When the usage of these resources exceeds a certain threshold, extra bundles will be shed in a more evenly way. For more information, see Shed load automatically.
Problem 4: In high-throughput scenarios, the broker direct memory may be OOM.
Analysis: Bookies have a low write rate. Consequently, a large number of messages stay in the broker’s off-heap memory until OOM.
Solution: In production, low write latency in bookies cannot always be guaranteed. Therefore, users can set a traffic throttling strategy for specific namespaces or topics on the broker side (as mentioned in “Traffic throttling”).
Problem 5: Is it possible to use one single IP address for all clients?
Analysis: The serviceUrl configuration list is long. When brokers are scaled out, the configuration needs to be updated.
Solution: Build a highly-available architecture with tools like Keepalived and HAProxy. There are many proven virtual IP solutions in the industry.
Looking ahead
Apache Pulsar has proved itself an ideal match for the SRE system at iFLYTEK as the team has seen the first fruits of it. “Since we adopted Pulsar, we have integrated multiple product lines with it. Our traffic has increased by 4 - 5 times with the maintenance cost cut by 30%,” Liu said. “In terms of data replication across availability zones, we have greatly reduced our cost with Pulsar’s geo-replication.”
After learning some lessons in Pulsar adoption, the company will continue its exploration and integration of Pulsar mainly on the following aspects.
- Authorization and authentication configuration on Pulsar. Further improve the safety of the system.
- One city, two data centers. Connect more business to Pulsar and enhance the stability and efficiency of the system.
- Ecosystem integration. Integrate Pulsar with more big data tools such as Apache Flink and Apache Spark.
- Pulsar on Kubernetes. Currently, Pulsar is deployed on Docker at iFLYTEK. To simplify the deployment and provide better scheduling, iFLYTEK will explore Pulsar’s usage on Kubernetes.


