
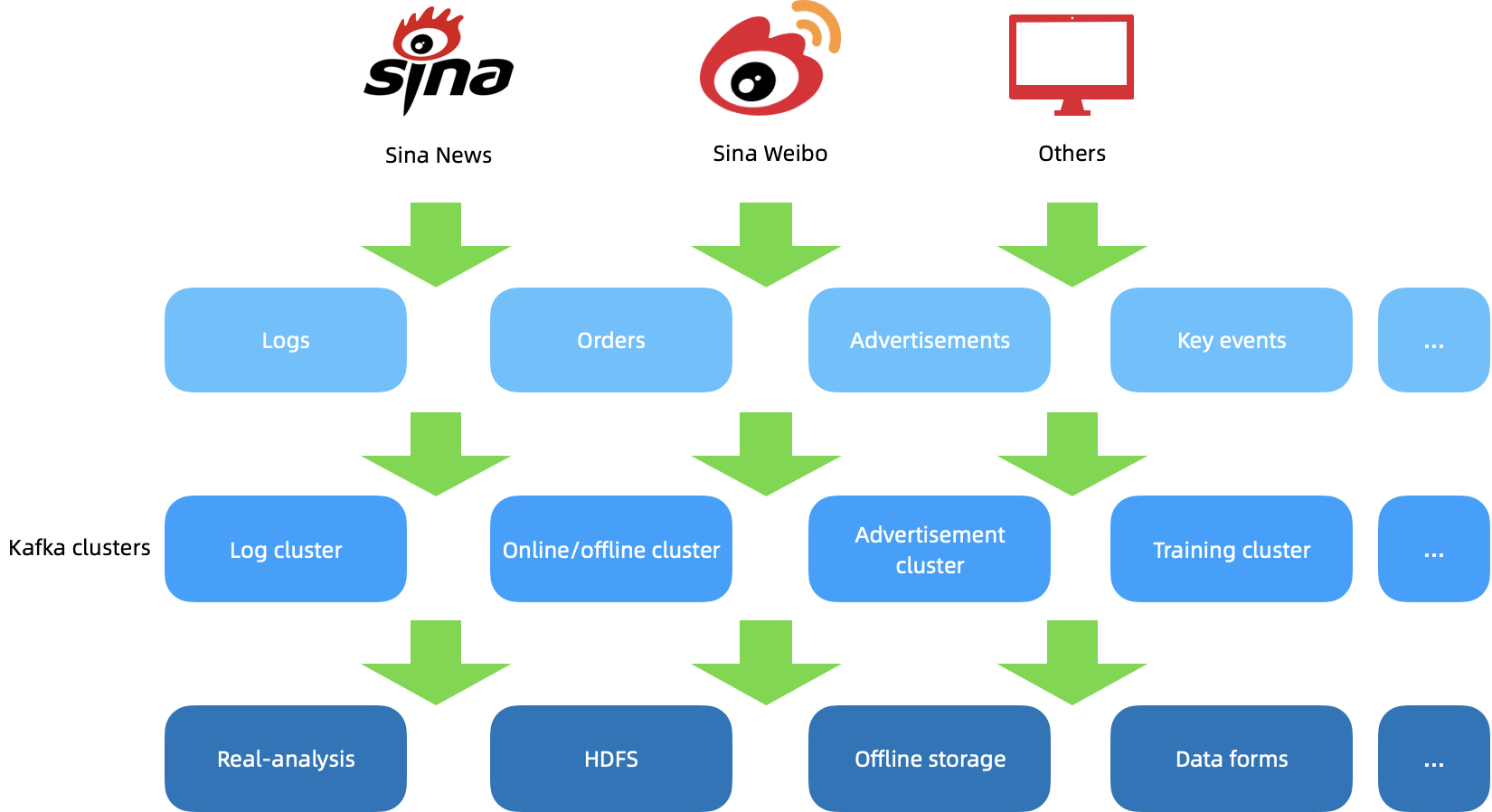
Previously, Sina was using Kafka clusters to handle data from Sina Weibo, Sina News, and other platforms. Data from logs (monitoring, services, characteristics, etc.), orders, advertisements, and key events were first processed by different Kafka clusters. After that, they might be used for different purposes, such as real-time analysis and monitoring, data form creation, HDFS, training, and offline storage. As Sina worked to use and maintain its Kafka clusters, the Sina Weibo messaging team was faced with a series of challenges, particularly during traffic peak hours:
- Maintenance difficulties. When traffic soars, Kafka clusters are not capable of automatic scaling for load balancing. Even if more nodes were added to scale the cluster, new brokers could not serve the load automatically. This means the team must manually balance the traffic, which is extremely complicated and time-consuming.
- Uneven data distribution. After the topics that serve heavy traffic are removed, the brokers that hosted these topics can have more storage space with incoming traffic decreasing. This is not a problem itself but if similar situations happen repeatedly, neither partition traffic nor disk data can be distributed evenly. To rebalance the traffic, manual intervention is required.
- Extra data flows during traffic bursts. When Kafka rebalances traffic, partitions need to be moved with data moved together. This results in additional network flows, which could cause unexpected problems during traffic jumps. In these cases, because the entire cluster is already under great pressure (high resource usage, especially disks), the extra data transmission could lead to more serious consequences.
- Migration concerns. There are over 1 trillion messages created per day on Sina Weibo, which come from various business systems written in different languages. This makes it extremely difficult for the team to migrate to another message queue solution. In addition, there are some important business modules that have been running for over 5 years whose source code is missing. Without the original programmers, it poses great challenges to the team to migrate them to alternatives for a redesign.
“Our team is looking for a message queue technology that could help solve these issues in Kafka without complex configuration changes to our business system,” said Wenbing Shen, Data Platform Engineer at Sina Weibo. “Our expectation is that this solution allows us to only change the broker list of Kafka and we can all be set.”
Solution: Why Apache Pulsar and KoP
Against this backdrop, the team began seeking a solution with the auto-scaling capability for additional workloads and peak traffic conditions, so that the performance impact was minimized for users. Ultimately, Apache Pulsar, a cloud-native streaming and message system featuring a flexible architecture with storage separated from computing, came to their attention.
“In Pulsar, brokers and bookies are separated. Bookies can be automatically scaled to handle new traffic and brokers only need to carry out some metadata computing work. As such, it helps us solve the problem of automatic scaling,” Shen added. “When it comes to topic rebalancing, Pulsar is also extremely fast. This is different from Kafka, which has to move the data for rebalancing.”
As the team continued to learn and understand Pulsar, they were made aware of the open-source project KoP (Kafka on Pulsar). KoP brings the native Kafka protocol support to Pulsar by introducing a Kafka protocol handler on Pulsar brokers. By adding the KoP protocol handler to the existing Pulsar cluster, users can easily migrate existing Kafka applications and services to Pulsar without changing their code.
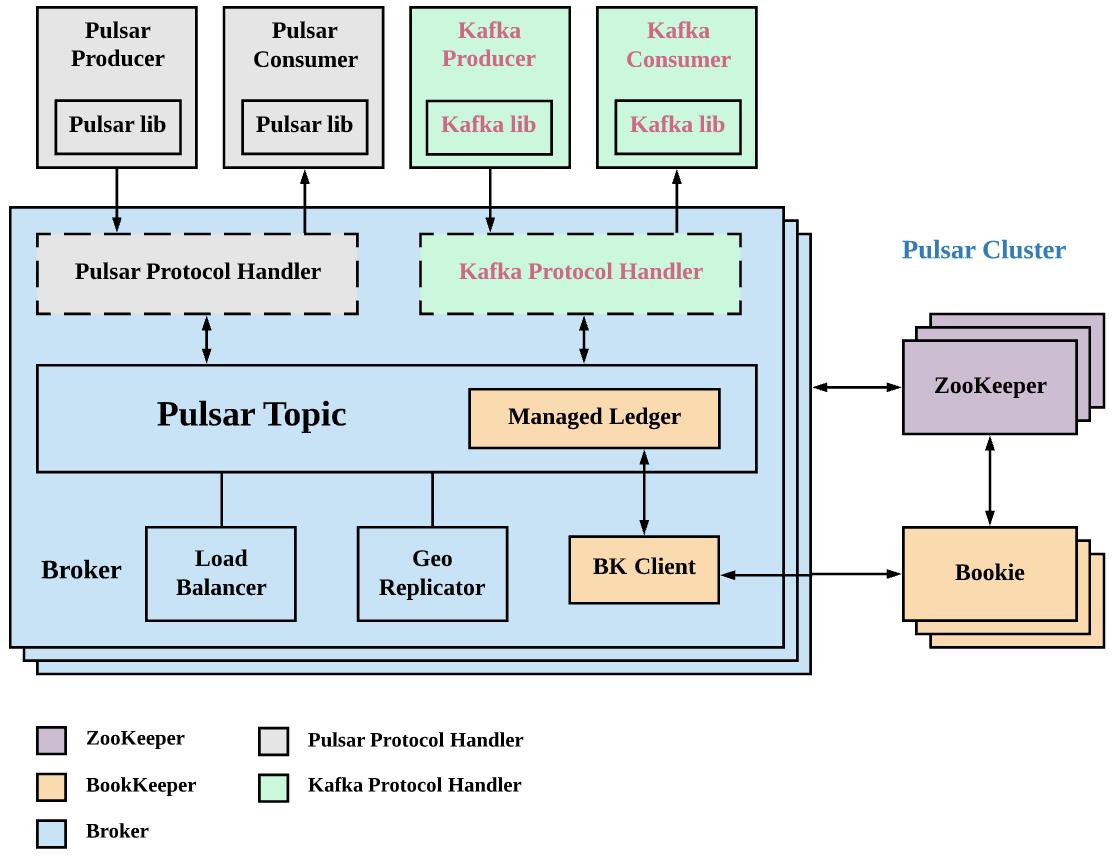
“Pulsar producers send data to Pulsar topics based on the Pulsar protocol handler. Likewise, Kafka producers send data to the Pulsar cluster through the Kafka protocol handler,” Shen noted. “KoP leverages Pulsar’s existing features and components, such as the topic lookup mechanism and ManagedLedger. And with BookKeeper clients, the data sent by Kafka producers can be stored securely on bookies.”
The following two key distinct features of Apache Pulsar and KoP let the team make their final decision to integrate them into their system.
- Great scalability. Pulsar’s unique design makes it more convenient for cluster maintenance even during traffic bursts. The load can be automatically balanced across nodes (both bookies and brokers).
- Native support for Kafka clients. The KoP protocol handlers (Pulsar protocol handler and Kafka protocol handler) help reduce the barriers for the team to adopt Pulsar without code change for Kafka applications. By integrating two popular event streaming platforms, KoP unlocks new use cases.
Using KoP: How the team solved compatibility issues
As the team worked to put KoP into use, the major challenge they had was to take on version compatibility.
Problem one: Authentication problems due to old Kafka versions
“We are using different Kafka versions for our business, ranging from 0.10 to 2.4,” Shen said. “Some of our clusters running mission-critical tasks are still using old versions like 0.10. Therefore, their corresponding clients are also using old versions for compatibility reasons. However, KoP only supports Kafka 1.0 or higher. This is where we need to work things out.”
Specifically, Shen’s team has been using an authentication mechanism where clients must be authenticated before they can communicate with servers. For Kafka versions prior to 1.0, the authentication is performed through SaslHandshakeRequest V0, with a series of SASL client and server tokens sent as opaque packets without Kafka request headers. To make sure the authentication is successful, the team must manually handle these packets to parse the tokens.
For detailed information, see this pull request submitted by Shen to the KoP GitHub repository.
Problem two: Protocol differences between Kafka and Pulsar
Both Kafka and Pulsar have their own message protocols. For example, Kafka has different message format versions (V0, V1, V2), and each version has its respective fields (for example, timestamp, magic, and offset). Hence, there may be compatibility issues if producers and consumers are developed in varied Kafka versions.
Similarly, messages may fail to be consumed if Kafka/Pulsar producers and Pulsar/Kafka consumers are mixed together without the correct configuration. In other words, consumers cannot parse producers’ messages. To ensure messages can be successfully consumed, there has to be a message conversion mechanism in the middle.
“In KoP, when a Kafka client sends a producer’s request, the handler thread in KoP uses ReplicaManager and PartitionLog to append Kafka records,” Shen explained the logic of the message conversion mechanism in KoP. “When PartitionLog appends Kafka records, it uses EntryFormatter to encode messages, which can then be published through the component PersistentTopic at the broker level. In this way, ManagerLedger can write messages to bookies.”
The value of entryFormat decides how messages are converted to map different fields between Pulsar and Kafka protocols, such as the number of messages and timestamp. Allowed values are kafka, mixed_kafka, and pulsar. KoP supports interaction between Pulsar and Kafka clients by default. If topics are used either by the Pulsar client or by the Kafka client, it is recommended to set entryFormat to kafka for better performance. For more information, see detailed explanations about entryFormat.
“To solve compatibility issues, we must pay special attention to the value of entryFormat,” Shen added. “Depending on the versions of producers and consumers, there may be performance deficiencies when messages are converted. In this connection, using a consumer written in a higher version may be a good idea.”
Introducing a new component: Metadata Event Handler
When using KoP, Shen’s team also noticed there may be some metadata inconsistency issues in the following scenarios. Therefore, they worked to develop a new component Metadata Event Handler for automatic metadata synchronization across all KoP brokers.
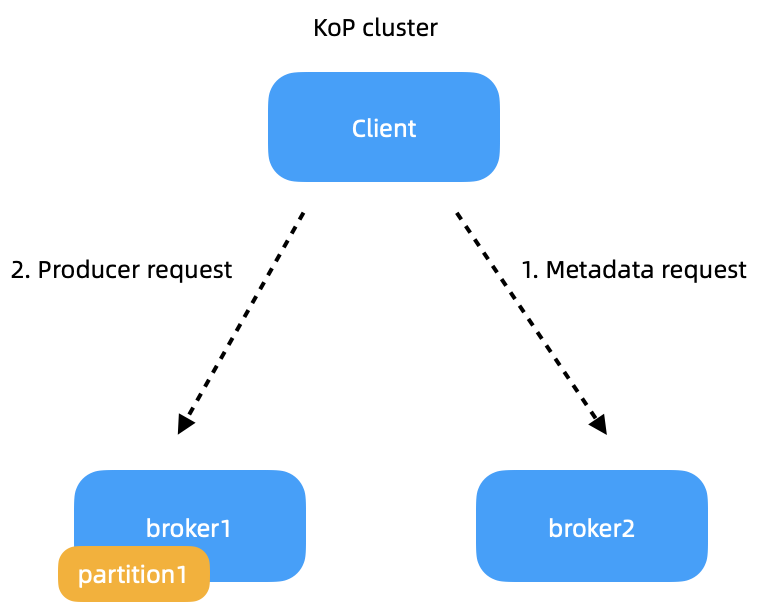
- Metadata inconsistency and request timeouts. As shown in the image below, this is a two-broker KoP cluster and the client needs to send messages to partition test0 hosted on broker1. When the client sends a metadata request to broker2, it responds with the information of broker1 and partition1, while excluding its own metadata. The client then sends producer requests to broker1. The process itself does not contain any problems. But if broker1 goes down, partition1 will be failed over to broker2 as its owner broker. In this case, the requests sent by the client cannot reach broker1. Nor can they be routed to broker2, resulting in metadata request timeouts.
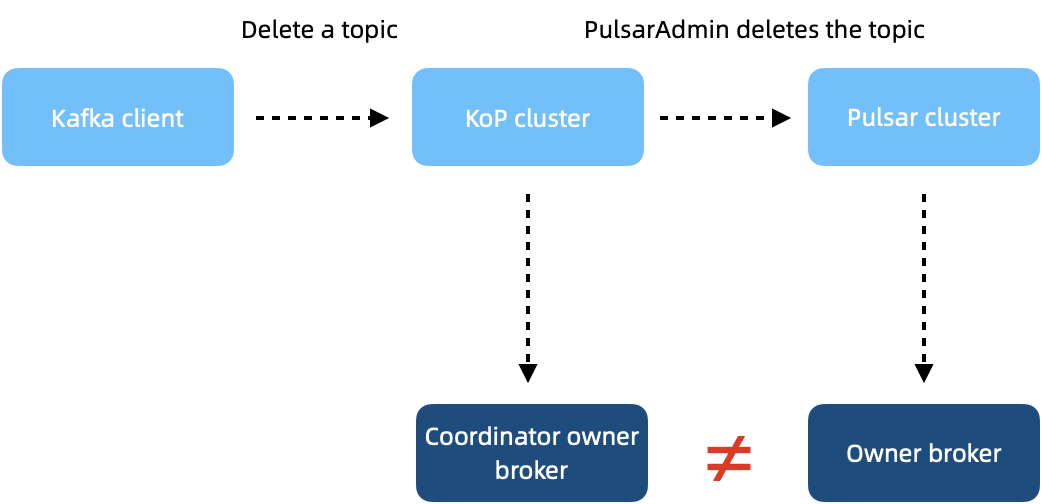
- The metadata remains in the coordinator after a topic is deleted. As messages are consumed from a topic, the metadata information of a consumer group is recorded in the coordinator. After the topic is deleted, there will be a timeout error when using the --describe option to obtain the group information. As shown in the following image, when the Kafka client sends the topic deletion request to the KoP cluster. The request is forwarded to all owner brokers of topic partitions, which then remove the topic. As the coordinator owner broker may not be the topic owner broker and the group metadata is stored in the coordinator, it is possible that the topic is deleted while the metadata remains.
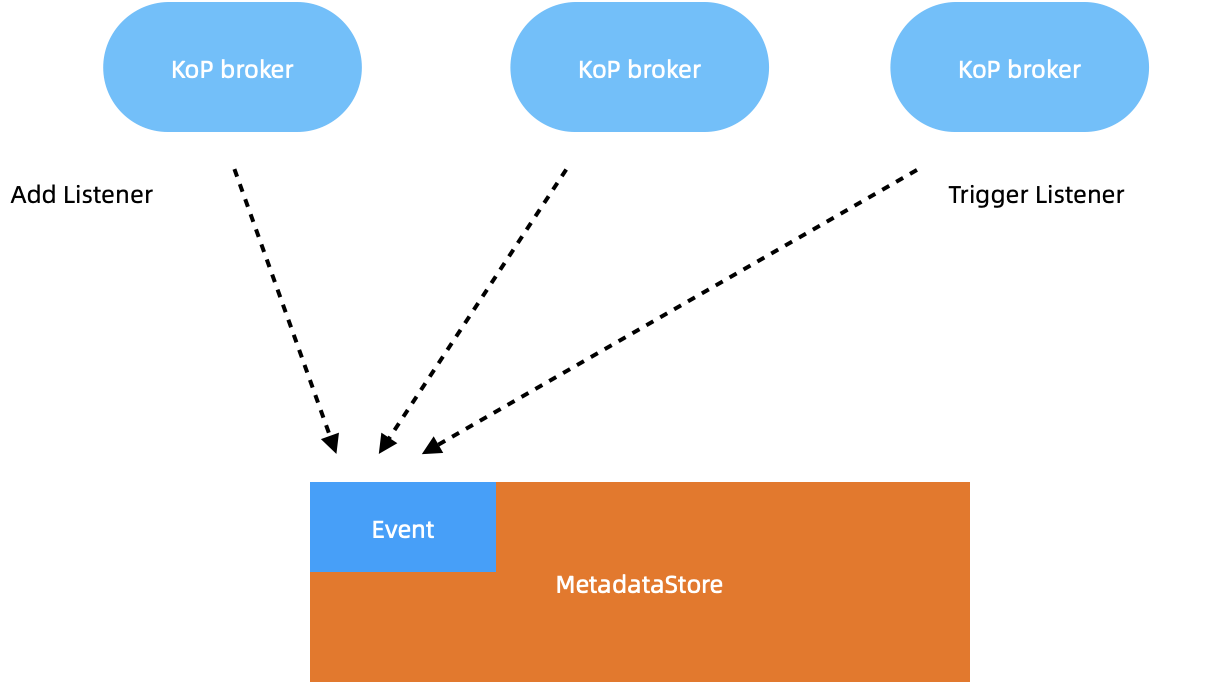
“KoP itself doesn’t have any controller to synchronize metadata across brokers. Therefore, the key to solving the above problems is achieving better metadata consistency,” Shen said. “We developed a metadata event handler based on MetadataStore. When new brokers are added to the cluster, it triggers the listener event, which can be known by other KoP brokers. In this way, they are able to update the metadata accordingly. This means once a topic is deleted, the coordinator can remove the metadata as well.”
Looking ahead
As Shen’s team works to solve these problems with more lessons learned from KoP and Pulsar, their entire system has been functioning securely and stably since September 2021.
To date, Shen has submitted a total of 43 pull requests to KoP, with 36 of them already merged. “KoP has become more mature as part of Pulsar’s ecosystem. Most of Kafka’s features are already available in it,” Shen said. “Personally, I will continue to contribute to the development and maintenance of KoP. As a member of the KoP community, I also welcome involvement from new participants. After all, this is what open source is all about.”
More on Apache Pulsar
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community that continues to drive innovation and improvements to the project.
- Start your on-demand Pulsar training today with StreamNative Academy.
- Spin up a Pulsar cluster in minutes with StreamNative Cloud. StreamNative Cloud provides a simple, fast, and cost-effective way to run Pulsar in the public cloud.
- Pulsar Summit Asia 2022 will be hosted virtually on November 19th and 20th, 2022. The CFP is open now! Submit a proposal to share your Pulsar story!
- Read more related blogs and documentation:
- Blog Offset Implementation in Kafka-on-Pulsar
- Blog Introducing StreamNative Cloud for Kafka
- Doc Kafka on Pulsar (KoP)


