
Key takeaways
- vivo faced some challenges when using Apache Kafka in performance, scalability, and data migration.
- After comparing different streaming and messaging tools, vivo began to learn Apache Pulsar and explored its features in scalability, fault tolerance, and load balancing.
- As vivo put Apache Pulsar into use, it summarized some useful practices in bundle and data management.
- vivo built its monitoring architecture based on Pulsar and created its customized Pulsar metrics for better observability.
Background
vivo provides internet services and products for over 400 million smartphone users worldwide. On the back of its messaging team, vivo seeks to build a strong message system featuring high throughput and low latency to support its real-time computing business, including data integration and message queueing services.
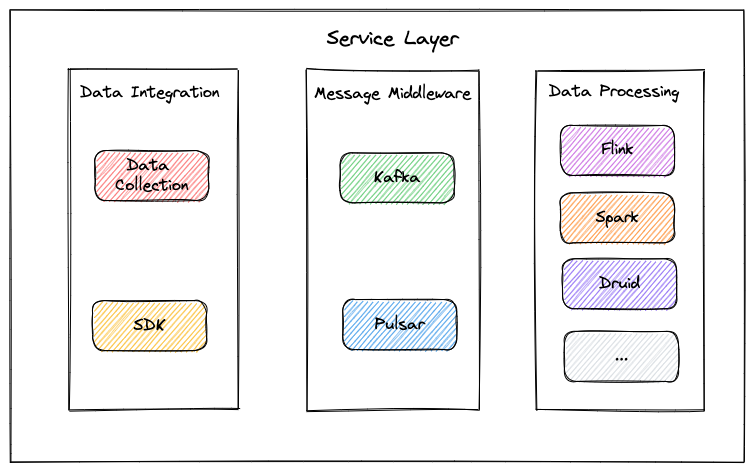
vivo’s existing business service layer consists of three parts - data integration, message middleware, and data processing. Currently, the team is using both Apache Kafka and Apache Pulsar as messaging solutions, with the latter handling over 100 billion messages per day.
Challenges
Over the past few years, vivo has used Kafka clusters to serve different business modules. As its business expands, the traffic that the Kafka clusters need to handle has grown exponentially. This results in the following challenges.
- Decreased performance. As existing clusters grow with more partitions on disks, sequential I/O turns to random I/O, affecting Kafka’s performance in reads and writes.
- Low resource utilization. The existing clusters serving the old business need to be split when they expand. However, the business itself cannot be dynamically scaled. As a result, some machines may not have their resources fully utilized or they cannot be allocated timely to serve new traffic.
- Scaling difficulty. When scaling a Kafka cluster, the team must migrate and rebalance traffic before they can put a new machine up and running in the cluster, which is extremely time-consuming. This might cause problems during traffic bursts.
- Increased metadata size. To increase the number of consumers, the team has to add more partitions, which means more metadata needs to be stored.
- Hardware failures. With various clusters containing a large number of machines, the team needs to deal with different disk issues, which account for two thirds of their total failures. This could directly affect the performance of clients.
“When you have so many clusters with massive traffic flows coming from a variety of business scenarios, you have to take into account a lot of things, such as cluster stability and overhead,” said Limin Quan, Big Data Engineer at vivo. “We need a more comprehensive message solution with better scalability that can be applied to more use cases.”
What Apache Pulsar has to offer for vivo
In 2022, the team began to learn Pulsar and tried to figure out how they could leverage Pulsar to solve the above-mentioned problems, especially through the following features.
Scalability
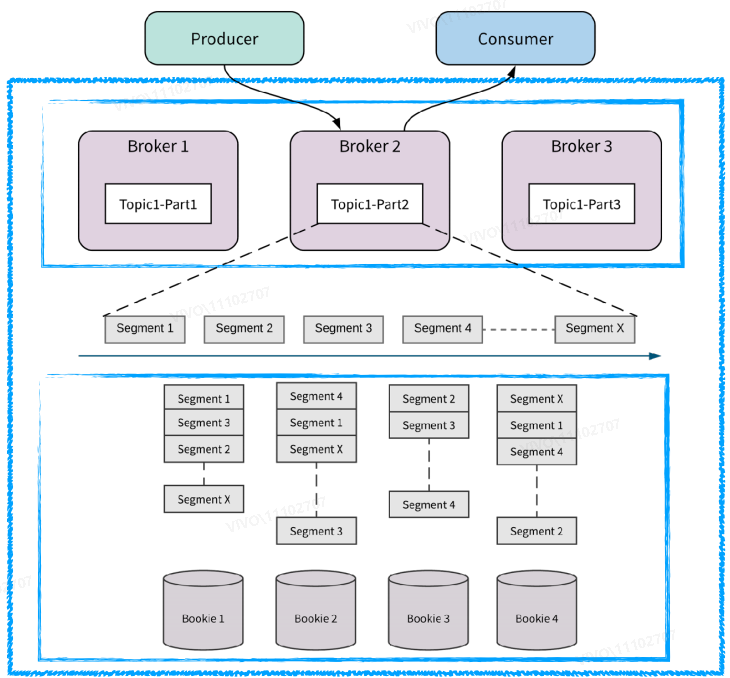
Different from Kafka, Pulsar separates computing from storage. “Apache Pulsar boasts a unique two-layer architecture. The benefit of the design is that we can scale nodes separately at either layer without impacting the other one,” Quan said. “At the computing layer, stateless brokers are equivalent to each other, which makes it possible for rapid scaling. As for storage, there is no leader or follower. All the nodes, namely bookies, are the same.”
Fault tolerance
Both brokers and bookies are lightweight nodes. Once a node goes down, the Pulsar cluster can quickly scale by adding or removing the node.
“The broker layer provides fault tolerance for bookies,” said Quan. “When a bookie goes down, Pulsar has this smooth fault tolerance mechanism that makes sure any node failure does not affect upstream business. Your client does not even need to know that. This could be extremely helpful to us as two thirds of our problems are related to disks.”
Load balancing
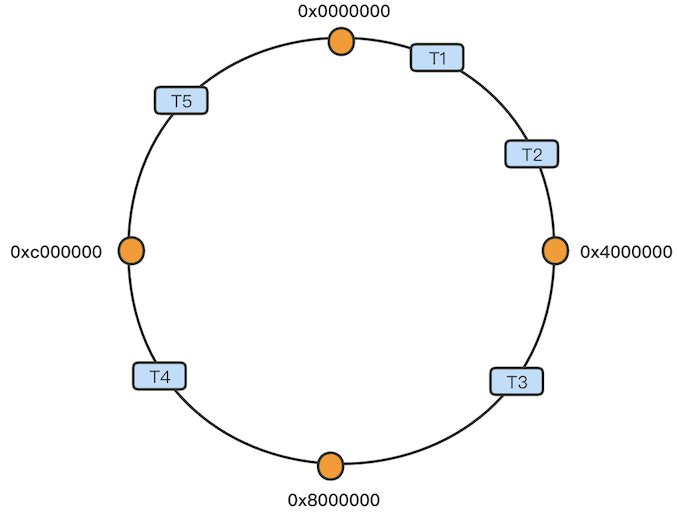
Pulsar frees users from spending hours migrating data when scaling a cluster as it features an automatic load balancing mechanism. Pulsar uses an abstraction called “bundles”. Topics are assigned to a specific bundle, which comprises a portion of the overall hash range of the namespace that has the topics. Each bundle is independent and is assigned to a broker. This ensures topics within a namespace are evenly distributed across brokers.
“At the storage layer, data are also distributed evenly. As we scale our cluster, messages can be written to bookies that have more available storage space,” said Quan. “In this way, traffic can be balanced in real time without manually migrating the data. This greatly improves our ability to cope with emergencies during traffic peak hours.”
“In bookies, data are flushed to disks asynchronously. During the process, messages are sorted first so that they can be read sequentially later,” Quan added. “In terms of sequentiality, Pulsar is an ideal solution to handling large clusters and emergencies during traffic bursts.”
In addition to the above features, the team also looked at other capabilities of Pulsar, such as tiered storage, traffic management and control, multi-tenancy, geo-replication, and containerized deployment. “With a comprehensive picture of Pulsar in mind, we know that it might be the answer to our problems,” Quan said.
Pulsar in practice: Bundle and data management
As the team worked to put Pulsar into use, they faced some challenges at the beginning in managing bundles and ledger data. However, they gradually worked out solutions and offered some insights based on their practices.
Bundle management
To control traffic in a cluster, Pulsar provides users with bundles to help establish the connection between topics and brokers. Initially, traffic might be spread as evenly as possible across brokers, while this could change over time. Besides, how to set the number of bundles might also be tricky for cluster maintainers. For these possible challenges, Quan proposed the following suggestions and tips.
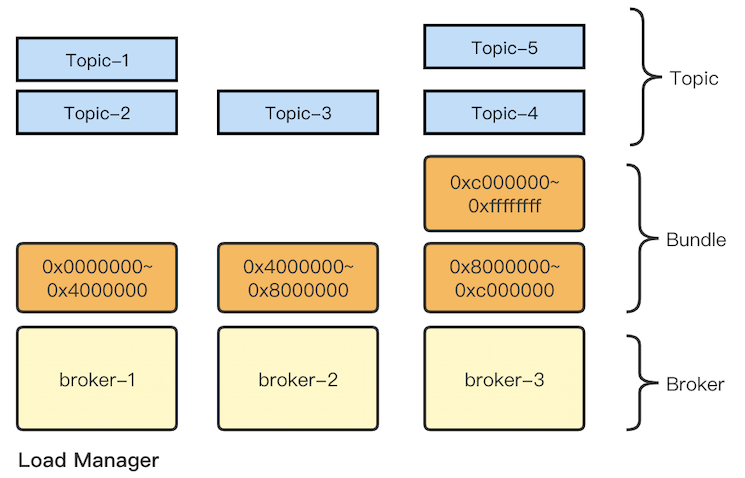
- Make a careful decision on the number of bundles. How many bundles exist in a cluster has a direct bearing on load balancing. Topics are assigned to a specific bundle according to the hash of the topic name. This means that topics may not be evenly distributed to bundles. “At vivo, we configure bundles based on the number of brokers corresponding to the namespace, and set a range to limit the number of bundles that are too large or small,” Quan said. “For example, we configure bundles with the number of brokers multiplied by 20, and limit them between 200 and 500.”
- Split bundles when necessary. Pulsar has a bundle split mechanism. In cases where a broker hosting several topics has heavy traffic while others are underutilized, bundles can be split by the broker. In this way, new smaller bundles can be reassigned to different brokers. The behavior can be customized by configuring defaultNamespaceBundleSplitAlgorithm in broker.conf. For more information, see Split namespace bundles.
- Unload bundles instead of the entire namespace. Pulsar allows users to unbind bundles from the broker and reassign these bundles, usually to nodes with lower loads. However, this is not recommended for namespaces. “If you unload a namespace, all the producers and consumers of all the bundles in the namespace will be disconnected. Hence, we should avoid unloading namespaces, especially during traffic peak hours.”
“Bundles are closely related to how traffic is distributed. Any operation on bundles may lead to traffic migration, which directly impacts your clients. If you have enormous bundles, you have to be extremely careful when unloading them.” Quan said. “I would suggest cluster maintainers run some tests on bundles first and then decide the number of bundles they need at the very beginning. Ideally, they should have a plan and take all factors into consideration, like the metadata of bundles, which are stored in ZooKeeper.”
Data management
Ledger rollovers
In Pulsar, users can configure related parameters in the broker.conf file to control ledger rollover behaviors. When a rollover happens, a ledger is closed with a new ledger created to store data. A ledger rollover is triggered after the minimum rollover time (managedLedgerMinLedgerRolloverTimeMinutes) is reached and one of the following conditions is met.
- The maximum rollover time has been reached (managedLedgerMaxLedgerRolloverTimeMinutes).
- The number of entries written to the ledger has reached the maximum value (managedLedgerMaxEntriesPerLedger)
- The entries written to the ledger have reached the maximum size value (managedLedgerMaxSizePerLedgerMbytes).
“I believe the reason for setting a threshold of the minimum rollover time is to prevent a ledger from being closed too fast,” Quan said. “The metadata of ledgers is stored in ZooKeeper. That means if we have too many ledgers, the metadata size will be extremely large. However, this might cause problems if we don’t have these parameters configured correctly.”
“During peak hours, you may have some topics serving massive traffic flows. In this case, the entries written to a ledger might already have exceeded the allowed maximum size before the minimum rollover time threshold is reached. This results in the ledger being unnecessarily large,” Quan talked about the potential problem in a ledger rollover. “When this large ledger is written to bookies, the data cannot be distributed evenly on the disk. Besides, some operations on the ledger may be affected, like data offloading.”
“In reality, we should carefully configure the parameters related to ledger rollovers based on business needs. To avoid excessively large ledgers, we can try to increase the number of topic partitions and reduce the traffic in a single partition,” Quan explained.
Data expiry
Pulsar uses retention policies and TTL (Time to live) to control message expiry behaviors. Retention policies are used to keep messages for a period of time before deletion, while TTL defines the amount of time a message is allowed to remain unacknowledged. When the TTL value is reached for a message, Pulsar automatically marks the message acknowledged. Specifically, messages go through the following steps before they are deleted.
- Unacknowledged messages remain in a backlog. These messages will not be deleted.
- Messages are acknowledged. They can be acknowledged and thus removed from the backlog in either of the following ways.
- Consumers send back acknowledgments to the broker, which acknowledges them in the subscription.
- When the TTL expires, Pulsar automatically marks the messages acknowledged with the cursor moved.
- Pulsar checks whether acknowledged messages should be kept based on the retention time and size in the retention policy.
- Acknowledged messages that exceed the retention limit on time or size will be deleted.
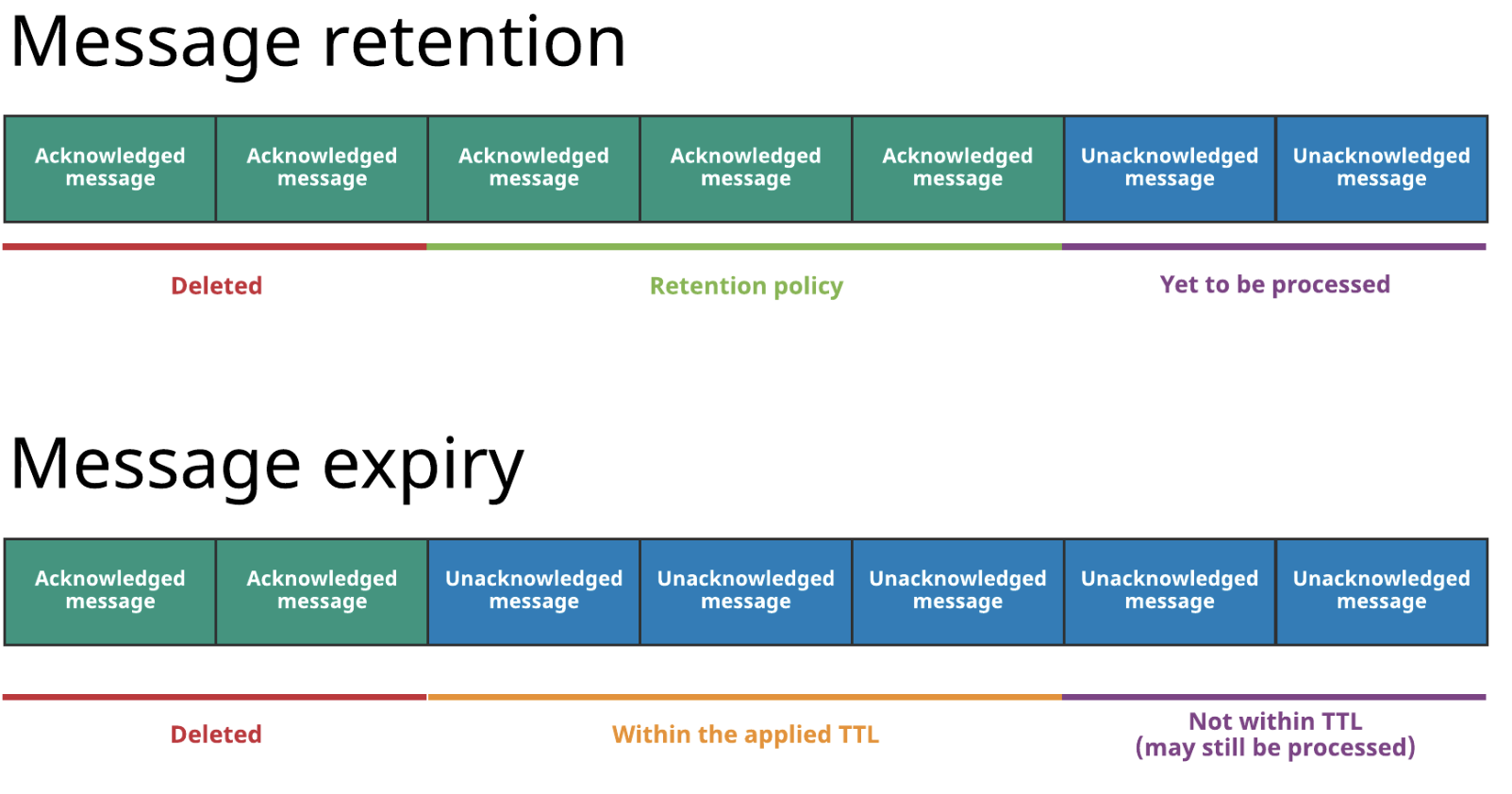
“TTL and retention policies provide cluster maintainers with great flexibility when they make their data expiry strategies. That said, it may be a little bit complicated for some,” Quan said. “I would suggest cluster maintainers keep it simple and have a unified rule to control how messages are retained. For example, simply making TTL equal to the retention period could be a good idea.”
Data deletion
When storing entries, BookKeeper sorts and flushes them to entry log files with index information stored in RocksDB. A single entry log file may contain entries that belong to different ledgers. “When a topic expires or is deleted, all related ledger data need to be deleted,” Quan said. “However, within the same period of time, as different ledger entries are written to the same entry log file, the entry log cannot be simply deleted. BookKeeper will start a GC (GarbageCollector) thread for checking and physical deletion.”
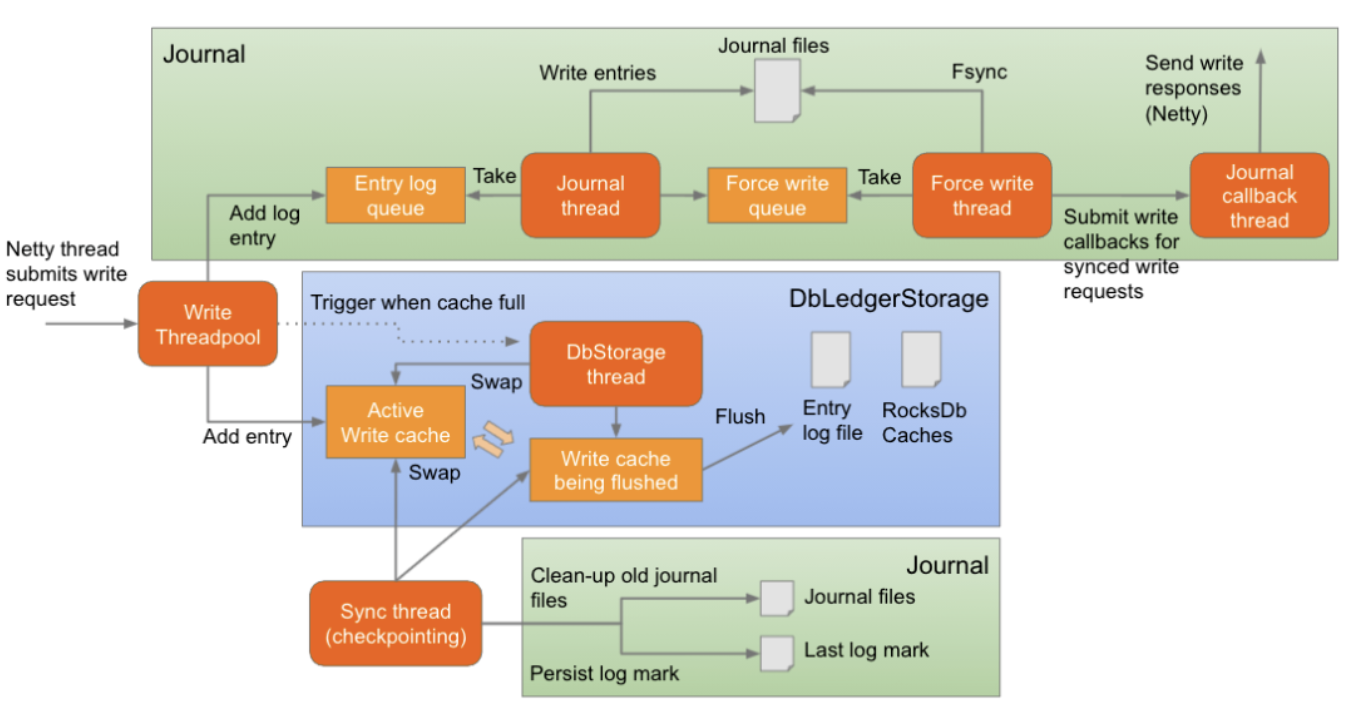
The entry log maintains metadata information (EntryLogMetadata), which records the ledger list, size, and remaining valid data ratio. The GC clean-up thread performs the following two steps at each gcWaitTime interval:
- Scan the metadata information of the entry log, and delete the entry log that has no valid data.
- Determine whether the compaction condition is met. If it is, the GC thread will read each entry to determine whether it has expired. Once it expires, it will be discarded. Otherwise, the data will be written to a new entry log.
Compaction is divided into minorCompaction and majorCompaction. The difference between the two is the threshold. By default, the minorCompaction clean-up interval is 1 hour with a threshold of 0.2; the majorCompaction clean-up interval is 24 hours with a threshold of 0.8. The threshold is the percentage of remaining valid data in the entry log file.
“You need to adjust interval and threshold values for minor and major compactions based on the actual situations, especially when your disk size is small. Otherwise, your data cannot be deleted in time,” Quan said. “To ensure cluster stability when data are being deleted, maintainers should take compaction settings and throttling policies all into account.”
Building a monitoring architecture with Pulsar and creating customized metrics
The team built its monitoring architecture based on Pulsar metrics. As shown in the image below, Prometheus first obtains these metrics from brokers, bookies, and ZooKeeper, and then sends formatted metrics to Kafka. Apache Druid consumes data from Kafka to provide the data source to create various Grafana dashboards.
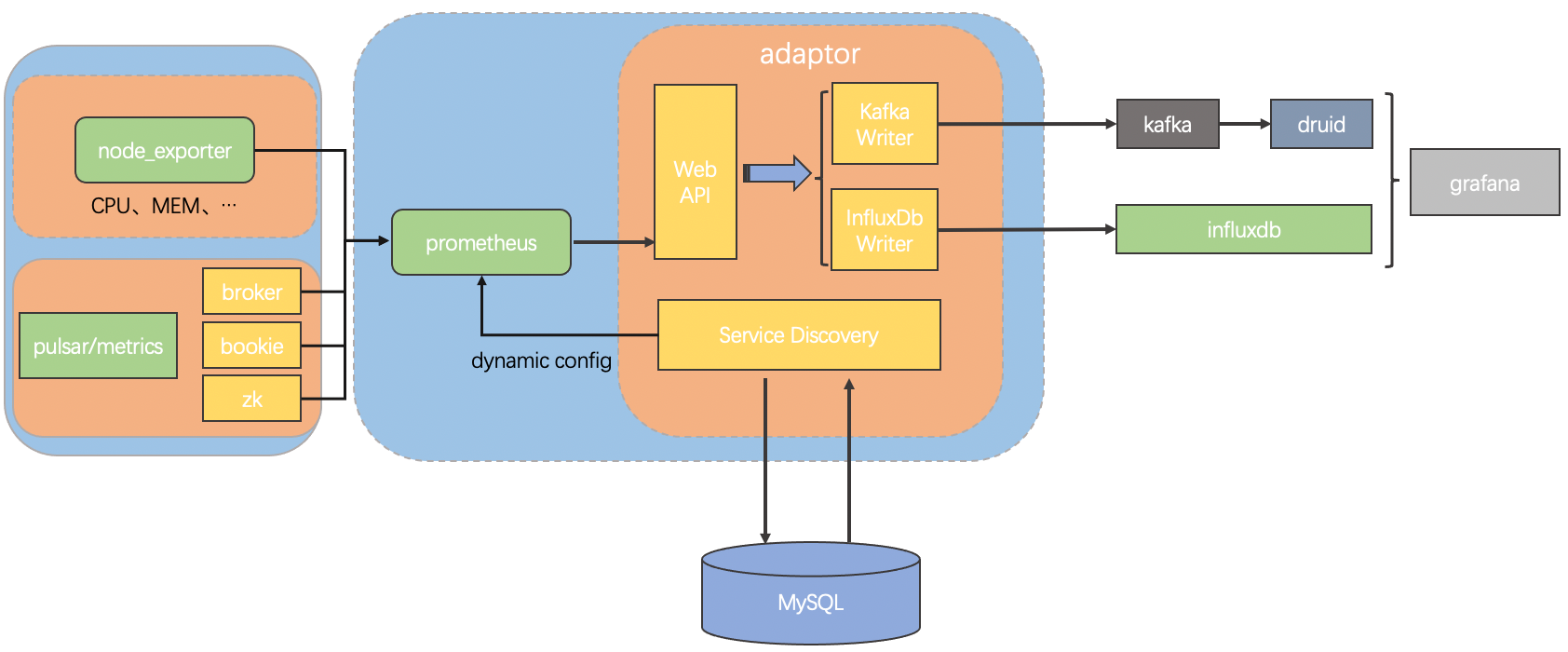
“In Grafana dashboards, we mainly focus on metrics from clients, brokers, and bookies,” said Jianbo Chen, Big Data Engineer at vivo. Specifically, the team is using these three major metrics for different purposes.
- Client metrics. Check exceptions on the client side.
- Broker metrics. Monitor topic traffic so that the team can make necessary adjustments to control traffic across brokers.
- Bookies metrics. Troubleshoot potential issues such as high latency in reading and writing.
“For each of them, we have further divided it into different subtypes. On bookies, for example, we have basic metrics like the number of entries and ledgers, and more advanced ones related to journal and queues,” Chen said.
Apart from these default metrics, Chen’s team also created customized metrics. “We have our own bundle metric that tells us how partitions are distributed in bundles. We also want to keep a close eye on latency and traffic on brokers, so we customized metrics related to P95 and P99 latency of reads and writes,” Chen added.
These customized metrics helped the team in making key decisions. “In one of our use cases, we had a topic with 30 partitions and 180 bundles. Based on the results, we could see that the traffic volumes that each node had to serve were quite different over time. Our customized bundle metric showed that some bundles had much more partitions than others,” Chen said. “To solve this problem, we increased the number of partitions to 120. After that, as expected, partitions were distributed more evenly with traffic balanced.”
Looking ahead
As Quan and Chen look back over their team’s journey of using Apache Pulsar, they still think they have a long way to go in the following aspects.
- End-to-end monitoring. “The existing metrics on the server side are not sufficient for analysis,” Chen said. “We hope we can have a more comprehensive monitoring tool to provide end-to-end observability so that we can quickly locate and troubleshoot issues.”
- Integration with other tools. “Pulsar is born for big data users and this offers us more possibilities in terms of data integration,” Chen said. Currently, Chen’s team is working on how they can combine Pulsar with other core components such as Spark and Flink, while necessary tests may still take some time before implementation.
- Kafka-on-Pulsar (KoP). KoP brings the native Kafka protocol support to Pulsar by introducing a Kafka protocol handler on Pulsar brokers. By adding the KoP protocol handler to the existing Pulsar cluster, users can easily migrate existing Kafka applications and services to Pulsar without modifying the code. “We still have plenty of Kafka clusters. To migrate our traffic and reduce our costs, we would like to try KoP going forward,” Chen said.
- Using Pulsar on Kubernetes. Pulsar represents a first-class citizen in the ecosystem of Kubernetes featuring native integration with containerized environments. As such, the message team will further extend the potential of Pulsar as a cloud-native messaging and streaming platform.
About the authors
Two vivo engineers contributed this case study.
- Limin Quan, Big Data Engineer at vivo, responsible for the development of distributed messaging middleware at vivo.
- Jianbo Chen, Big Data Engineer at vivo, responsible for the development of distributed messaging middleware at vivo. He was a microservices application architect before.


