
With a user base of over 100+ million users, and a database of 200+ million resumes, Zhaopin is one of the largest online recruiting and career platforms in China. As a bilingual job board, it provides one of the largest selections of real-time job vacancies in China.
A key part of the software supporting Zhaopin is our event center system. This system, which is responsible for all of the intra-service messaging within Zhaopin, supports mission-critical services such as resume submission and job search. The event center system needs to handle more than 1 billion messages per day under normal conditions, scaling to multiple billion messages per day during the peak recruiting season.
Our previous technology to support the pub-sub messaging and message queuing needs for our event center consisted of two separate systems. Our work queue use cases were implemented with RabbitMQ, while our pub-sub messaging and streaming for use cases used Apache Kafka.
We use work queues throughout our microservices architecture as an intermediate layer to decouple front-end services and backend systems, allowing our systems to run reliably even in the event of traffic spikes. At Zhaopin, our typical work-queue use cases have the following characteristics:
- Each message is consumed by multiple independent services.
- Each service must consume a full replica of all messages.
- Each service has multiple consumers consuming messages concurrently.
- Each message should be guaranteed to be delivered at-least-once.
A tracing mechanism is required for tracing the lifecycle of messages for mission-critical services. For instance, when a user submits a résumé, the service handling resume submission will first enqueue a message into the messaging system. All the other services (such as database updates, sending notifications, and recommendations) will then consume the messages from the messaging system and process them.

Our Challenges
Although we did have technology in place to support our event center system, we saw that we faced a number of growing challenges and limitations with that technology as we grew.
Cost & Complexity
One of our primary problems with our previous approach was the hardware cost and administrative burden of deploying and managing multiple messaging technologies side by side just for the sake of serving different use cases. Several additional problems arose from having to publish the same event data into dual data pipelines as well. First, the same data needed to be stored in two separate systems, which doubled our storage requirements. Second, it was very difficult to keep the copies consistent across the two different systems. Lastly, having two different technologies introduced additional complexity because our developers and DevOps team had to be familiar with both messaging platforms.
Missing Important Capabilities
In addition to the operational overhead of running two messaging systems, there were architectural shortcomings within each of our previous technologies, making the decision to switch even more compelling. While RabbitMQ supports work queue use-cases very well, it does not integrate well with popular computing frameworks. It also has several limitations such as scalability, throughput, persistence and message replay. We attempted to overcome by implementing our own distributed message queue service based on Apache Zookeeper and RabbitMQ. However, we found this decision also came with a large, ongoing maintenance burden that we felt was unsustainable.
Inadequate Performance and Durability
During our peak usage periods, we were unable to meet our service level SLA without increasing the number of consumers on some of our Kafka topics. However, we found that the ability to parallelize consumption in Kafka is tightly coupled with the number partitions on a given topic. Therefore, in order to increase the number of consumers on a particular topic required us to increase the number of partitions, which was not an acceptable approach for us for these reasons: The newly created partitions did not contain any data, resulting in no real increase in consumption throughput. In order to remedy this, we had to also force partition reassignment on the topic to distribute the backlogged data onto these new partitions.
Both of these steps were not easy to automate, forcing us to monitor the topics for backlog, and manually correct the issues. Although we had deployed Kafka for our pub-sub messaging use cases, Kafka does not provide the data durability guarantees that were increasingly a must-have requirement for our mission-critical business services. For these reasons, in early 2018 we decided to simplify our entire messaging technology stack by selecting a technology that would support both our work queue and streaming use cases, thereby eliminating all of the cost and complexity of hosting separate systems.
Requirements
With this in mind, we compiled the following list of capabilities that we required from our messaging platform:
- Fault Tolerance and Strong Consistency: Events stored within our messaging system are used for mission-critical online services, therefore the data must be stored reliably and in a consistent fashion. Events cannot be lost under any circumstances, and it must be possible to guarantee at-least-once delivery.
- Single Topic Consumer Scalability: We must be able to easily scale the throughput of a single topic by increasing the number of consumers of the topic on-the-fly as the traffic pattern changes.
- Individual and Cumulative Message Acknowledgement: The messaging system should support BOTH acknowledgement of individual messages, which is often used for work queue use cases, and cumulative acknowledgement of messages, which is required for most streaming use cases.
- Message Retention and Rewind: We need to be able to configure different topics with different retention policies, either time-based or size-based. Consumers should be able to rewind their consumption back to a certain time. Based on these requirements, we started investigating the open source technologies available in the market. During our initial research, we were unable to find any open source messaging products that satisfied all of our requirements, particularly when it came to no data loss and strong consistency.
Unable to find a better solution among the technologies we knew about, our initial plan was to build our own platform on top of the strongly-consistent distributed log storage platform Apache BookKeeper, which offers an excellent log storage API and has been deployed at internet scale by Twitter, Yahoo, and Salesforce. However, after getting touch with the BookKeeper community, they pointed us to Apache Pulsar — the next generation pub-sub messaging system built on BookKeeper.
Why Apache Pulsar?
After working closely with the Pulsar community and diving deeper into Pulsar, we decided to adopt Pulsar as the basis for Zhaopin’s event center system for following reasons:
- By using BookKeeper for its storage layer, it offers strong durability and consistency, guaranteeing zero data loss.
- It provides a very flexible replication scheme, allowing users to choose different replication settings per topic to suit their requirements for throughput, latency, and data availability.
- Pulsar has a segment-centric design, that separates message serving from message storage, allowing independent scalability of each. Such a layered architecture offers better resiliency and avoids complex data rebalancing when machines crash or a cluster expands.
- Pulsar provides very good I/O isolation, which is suitable for both messaging and streaming workloads.
- It provides a simple flexible messaging model that unifies queuing and streaming. So it can be used for both work queue and pub-sub messaging use cases, thereby allowing us to eliminate the need for dual messaging systems and all the associated issues.
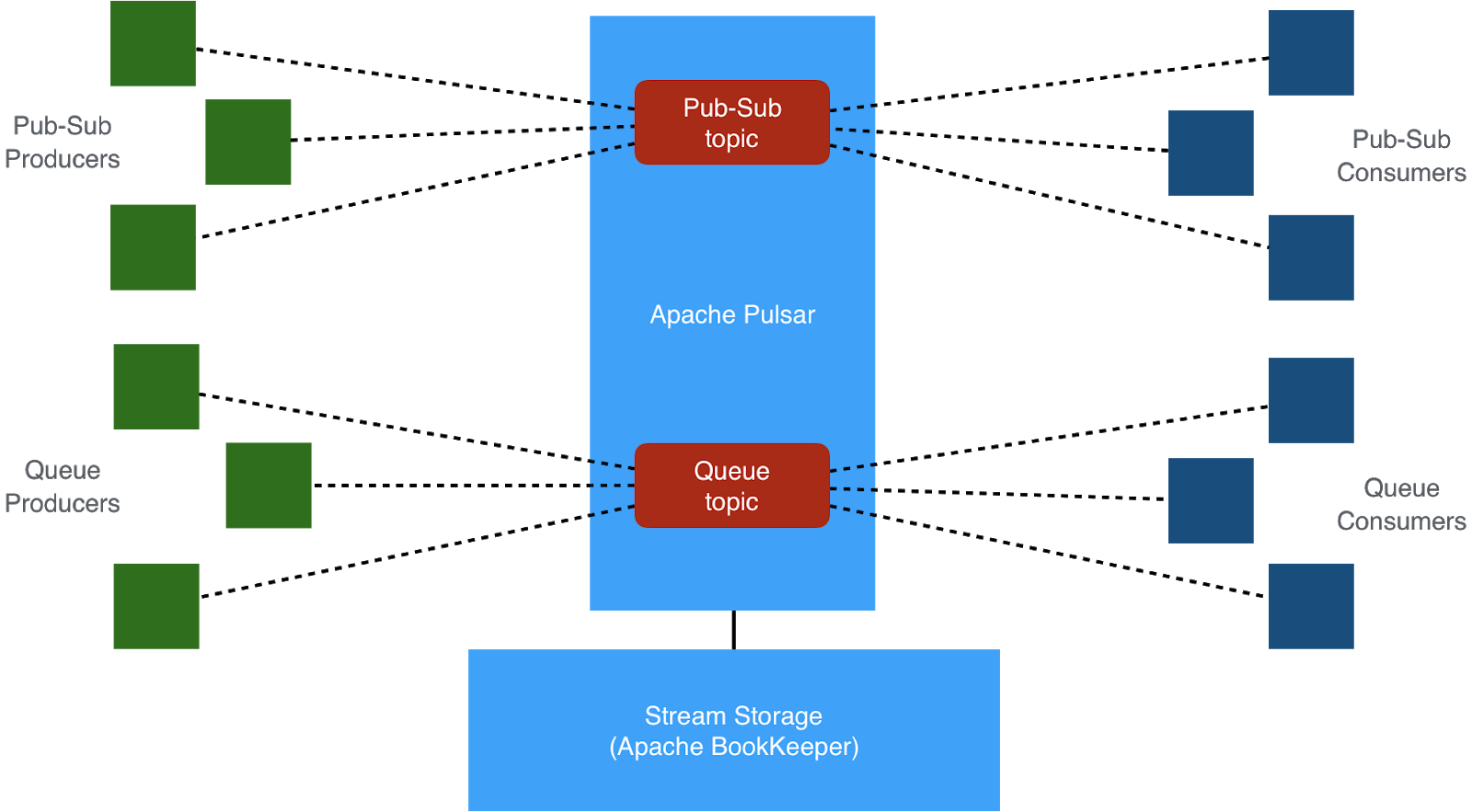
In addition to these key architectural features, Apache Pulsar also offers many different enterprise-grade features that are critical for supporting our business critical applications, such as multi-tenancy, geo-replication, built-in schema support and tiered storage. Recently added features such as serverless compute with Pulsar Functions and Pulsar SQL are essential for building event-driven microservices here at Zhaopin.com
Summary
We are very happy with our choice of Pulsar and the performance and reliability it provides, and are committed to contributing many great features back to the Apache Pulsar community, such as a Dead Letter Topic, Client Interceptors, and Delayed Messages just to name a few.
If you are running multiple messaging platforms just for the sake of serving different use cases, you should consider replacing them with Apache Pulsar to consolidate your messaging infrastructure into a single system capable of supporting both queuing and pub-/sub messaging.
We are very pleased to be hosting the next Apache Pulsar meetup on 12/15 at our offices in Shanghai. Please stop by to hear from our engineers at @Zhaopin_com on their experiences and best practices for running Pulsar in production and using Pulsar + @ApacheFlink to power their recommendation system. More info: buff.ly/2BFYrBy
We would like to especially thank all the committers to the Apache Pulsar project, as well as the technical support we received from members of its large and growing community.


