
Introduction
In this blog, we talk about the importance of load balancing in distributed computing systems and provide a deep dive on how Pulsar handles broker load balancing. First, we’ll cover Pulsar’s topic-bundle grouping, bundle-broker ownership, and load data models. Then, we'll walk through Pulsar’s load balancing logic with sequence diagrams that demonstrate bundle assignment, split, and shedding. By the end of this blog, you’ll understand how Pulsar dynamically balances brokers.
Before we dive into the details of Pulsar’s broker load balancing, we'll briefly discuss the challenges of distributed computing, and specifically, systems with monolithic architectures.
The challenges of load balancing in distributed streaming
A key challenge of distributed computing is load balancing. Distributed systems need to evenly distribute message loads among servers to avoid overloaded servers that can malfunction and harm the performance of the cluster. Topics are naturally a good choice to partition messages because messages under the same topic (or topic partition) can be grouped and served by a single logical server. In most distributed streaming systems, including Pulsar, topics or groups of topics are considered a load-balance entity, where the systems need to evenly distribute the message load among the servers.
Topic load balancing can be challenging when topic loads are unpredictable. When there is a load increase in certain topics, these topics must offload directly or repartition to redistribute the load to other machines. Alternatively, when machines receive low traffic or become idle, the cluster needs to rebalance to avoid wasting server resources.
Dynamic rebalancing can be difficult in monolithic architectures, where messages are both served and persisted in the same stateful server. In monolithic streaming systems, rebalancing often involves copying messages from one server to another. Admins must carefully compute the initial topic distribution to avoid future rebalancing as much as possible. In many cases, they need careful orchestration to execute topic rebalancing.
An overview of load balancing in Pulsar
By contrast, Apache Pulsar is equipped with automatic broker load balancing that requires no admin intervention. Pulsar’s architecture separates storage and compute, making the broker-topic assignment more flexible. Pulsar brokers persist messages in the storage servers, which removes the need for Pulsar to copy messages from one broker to another when rebalancing topics among brokers. In this scenario, the new broker simply looks up the metadata store to point to the correct storage servers where the topic messages are located.
Let's briefly talk about the Pulsar storage architecture to have the complete Pulsar's scaling context here. On the storage side, topic messages are segmented into Ledgers, and these Ledgers are distributed to multiple BookKeeper servers, known as bookies. Pulsar horizontally scales its bookies to distribute as many Ledger (Segment) entities as possible. For a high write load, if all bookies are full, you could add more bookies, and the new message entries (new ledgers) will be placed on the new bookies. With this segmentation, during the storage scaling, Pulsar does not involve recopying old messages from bookies. For a high read load, because Pulsar caches messages in the brokers' memory, the read load on the bookies significantly offloads to the brokers, which are load-balanced. You can read more about Pulsar Storage architecture and scaling information in the blog post Comparing Pulsar and Kafka.
Topics are assigned to brokers at the bundle level
From the client perspective, Pulsar topics are the basic units in which clients publish and consume messages. On the broker side, a single broker will serve all the messages for a topic from all clients. A topic can be partitioned, and partitions will be distributed to multiple brokers. You could regard a topic partition as a topic and a partitioned topic as a group of topics.
Because it would be inefficient for each broker to serve only one topic, brokers need to serve multiple topics simultaneously. For this multi-topic ownership, the concept of a bundle was introduced in Pulsar to represent a middle-layer group.
Related topics are logically grouped into a namespace, which is the administrative unit. For instance, you can set configuration policies that apply to all the topics in a namespace. Internally, a namespace is divided into shards, aka the bundles. Each of these bundles becomes an assignment unit.
Pulsar uses bundles to shard topics, which will help reduce the amount of information to track. For example, Pulsar LoadManger aggregates topic load statistics, such as message rates at the bundle layer, which helps reduce the number of load samples to monitor. Also, Pulsar needs to track which broker currently serves a particular topic. With bundles, Pulsar can reduce the space needed for this ownership mapping.
Pulsar uses a hash to map topics to bundles. Here’s an example of two bundles in a namespace.
Bundle_Key_Partitions : [0x00000000, 0x80000000, 0xFFFFFFFF]
Bundle1_Key_Range: [0x00000000, 0x80000000)
Bundle2_Key_Range: [0x80000000, 0xFFFFFFFF]
Pulsar computes the hashcode given topic name by Long hashcode = hash(topicName). Let’s say hash(“my-topic”) = 0x0000000F. Then Pulsar could do a binary search by NamespaceBundle getBundle(hashCode) to which bundle the topic belongs given the bundle key ranges. In this example, “Bundle1” is the one to which “my-topic” belongs.
Brokers dynamically own bundles on demand
One of the advantages of Pulsar’s compute (brokers) and storage (bookies) separation is that Pulsar brokers can be stateless and horizontally scalable with dynamic bundle ownership. When brokers are overloaded, more brokers can be easily added to a cluster and redistribute bundle ownerships.
To discover the current bundle-broker ownership in a given topic, Pulsar uses a server-side discovery mechanism that redirects clients to the owner brokers’ URLs. This discovery logic requires:
- Bundle key ranges for a given namespace, in order to map a topic to a bundle.
- Bundle-Broker ownership mapping to direct the client to the current owner or to trigger a new ownership acquisition in case there is no broker assigned.
Pulsar stores bundle ranges and ownership mapping in the metadata store, such as ZooKeeper or etcd, and the information is also cached by each broker.
Load data model
Collecting up-to-date load information from brokers is crucial to load balancing decisions. Pulsar constantly updates the following load data in the memory cache and metadata store and replicates it to the leader broker. Based on this load data, the leader broker runs topic-broker assignment, bundle split, and unload logic:
- Bundle Load Data contains bundle-specific load information, such as bundle-specific msg in/out rates.
- Broker Load Data contains broker-specific load information, such as CPU, memory, and network throughput in/out rates.
Load balance sequence
In this section, we’ll walk through load balancing logic with sequence diagrams:
- Assigning topics to brokers dynamically (Read the complete documentation.)
- Splitting overloaded bundles (Read the complete documentation.)
- Shedding bundles from overloaded brokers (Read the complete documentation.)
Assigning topics to brokers dynamically
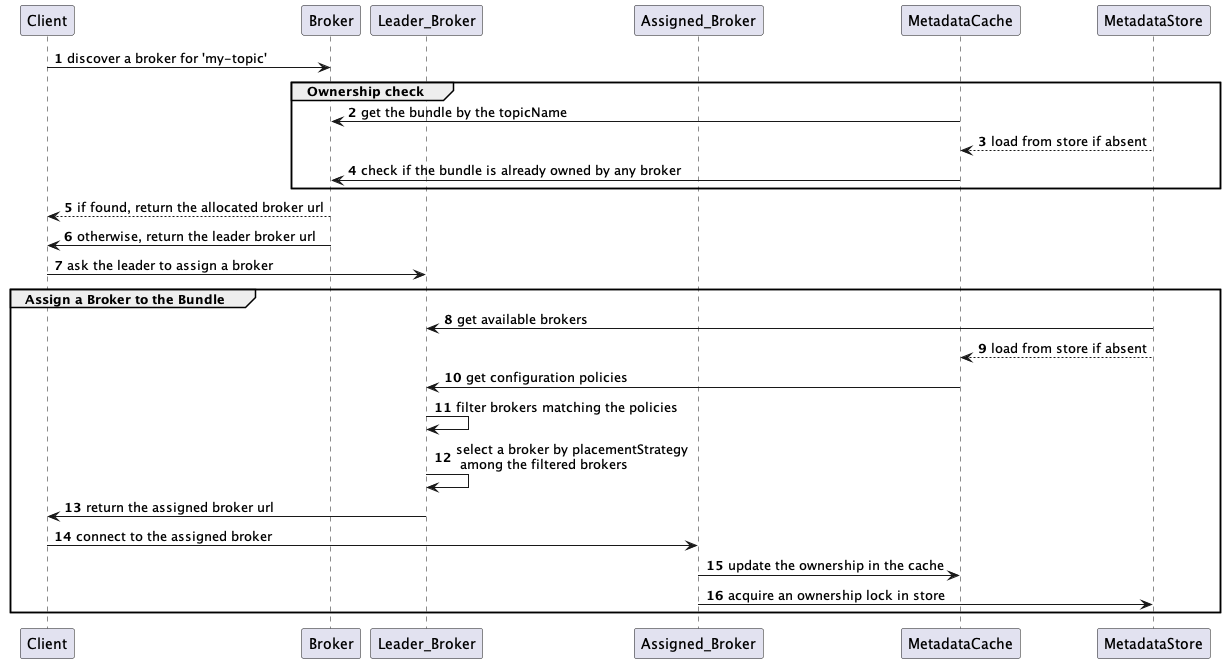
Imagine a client trying to connect to a broker for a topic. The client connects to a random broker, and the broker first searches the matching bundle by the hash of the topic and its namespace bundle ranges. Then the broker checks if any broker already owns the bundle in the metadata store. If already owned, the broker redirects the client to the owner URL. Otherwise, the broker redirects the client to the leader for a broker assignment. For the assignment, the leader first filters out available brokers by the configured rules and then randomly selects one of the least loaded brokers to the bundle, as shown in Section 1 below, and returns its URL. The leader redirects the client to the returned URL, and the client connects to the assigned broker. This new broker-bundle ownership creates an ephemeral lock in the metadata store, and the lock is automatically released if the owner becomes unavailable.
Section 1: Selecting a broker
This step selects a broker from the filtered broker list. As a tie-breaker strategy, it uses ModularLoadManagerStrategy (LeastLongTermMessageRate by default). LeastLongTermMessageRate computes brokers’ load scores and randomly selects one among the minimal scores by the following logic:
- If the maximum local usage of CPU, memory, and network is bigger than the LoadBalancerBrokerOverloadedThresholdPercentage (default 85%), then score=INF.
- Otherwise, score = longTermMsgIn rate and longTermMsgOut rate.
Splitting overloaded bundles
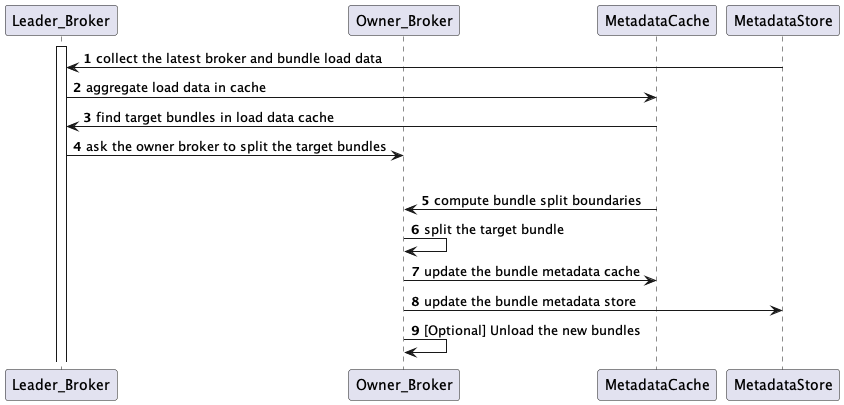 With the bundle load data, the leader broker identifies which bundles are overloaded beyond the threshold as shown in Section 2 below and asks the owner broker to split them. For the split, the owner broker first computes split positions, as shown in Section 3 below, and repartition the target bundles at them, as shown in Section 4 below. After the split, the owner broker updates the bundle ownerships and ranges in the metadata store. The newly split bundles can be automatically unloaded from the owner broker, configurable by the LoadBalancerAutoUnloadSplitBundlesEnabled flag.
With the bundle load data, the leader broker identifies which bundles are overloaded beyond the threshold as shown in Section 2 below and asks the owner broker to split them. For the split, the owner broker first computes split positions, as shown in Section 3 below, and repartition the target bundles at them, as shown in Section 4 below. After the split, the owner broker updates the bundle ownerships and ranges in the metadata store. The newly split bundles can be automatically unloaded from the owner broker, configurable by the LoadBalancerAutoUnloadSplitBundlesEnabled flag.
Section 2: Finding target bundles
If the auto bundle split is enabled by loadBalancerAutoBundleSplitEnabled (default true) configuration, the leader broker checks if any bundle’s load is beyond LoadBalancerNamespaceBundle* thresholds.
Defaults
LoadBalancerNamespaceBundleMaxTopics = 1000
LoadBalancerNamespaceBundleMaxSessions = 1000
LoadBalancerNamespaceBundleMaxMsgRate = 30000
LoadBalancerNamespaceBundleMaxBandwidthMbytes = 100
LoadBalancerNamespaceMaximumBundles = 128
If the number of bundles in the namespace is already larger than or equal to MaximumBundles, it skips the split logic.
Section 3: Computing bundle split boundaries
Split operations compute the target bundle’s range boundaries to split. The bundle split boundary algorithm is configurable by supportedNamespaceBundleSplitAlgorithms.
If we have two bundle ranges in a namespace with range partitions (0x0000, 0X8000, 0xFFFF), and we are currently targeting the first bundle range (0x0000, 0x8000) to split:
RANGE_EQUALLY_DIVIDE_NAME (default): This algorithm divides the bundle into two parts with the same hash range size, for example ttarget bundle to split=(0x0000, 0x8000) => bundle split boundary=0x4000.
TOPIC_COUNT_EQUALLY_DIVIDE: It divides the bundle into two parts with the same topic count. Let’s say there are 6 topics in the target bundle [0x0000, 0x8000):
hash(topic1) = 0x0000
hash(topic2) = 0x0005
hash(topic3) = 0x0010
hash(topic4) = 0x0015
hash(topic5) = 0x0020
hash(topic6) = 0x0025
Here we want to split at 0x0012 to make the left and right sides of the number of topics the same. E.g. target bundle to split [0x0000, 0x8000) => bundle split boundary=0x0012.
Section 4: Splitting bundles by boundaries
Example:
Given bundle partitions 0x0000, 0x8000, 0xFFFF, splitBoundaries: 0x4000
Bundle partitions after split = 0x0000, 0x4000, 0x8000, 0xFFFF
Bundles ranges after split = [[0x0000, 0x4000),0x4000, 0x8000), 0x8000, 0xFFFF
Shedding (unloading) bundles from overloaded brokers
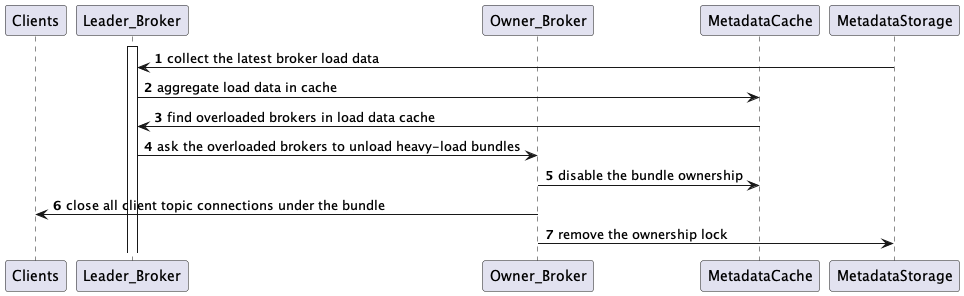 With the broker load information collected from all brokers, the leader broker identifies which brokers are overloaded and triggers bundle unload operations, with the objective of rebalancing the traffic throughout the cluster.
With the broker load information collected from all brokers, the leader broker identifies which brokers are overloaded and triggers bundle unload operations, with the objective of rebalancing the traffic throughout the cluster.
Using the default ThresholdShedder strategy, the leader broker computes the average of the maximal resource usage among CPU, memory, and network IO. After that, the leader finds brokers whose load is higher than the average-based threshold, as shown in Section 5 below. If identified, the leader asks the overloaded brokers to unload some bundles of topics, starting from the high throughput ones, enough to bring the broker load to below the critical threshold.
For the unloading request, the owner broker removes the target bundles’ ownerships in the metadata store and closes the client topic connections. Then the clients reinitiate the broker discovery mechanism. Eventually, the leader assigns less-loaded brokers to the unloaded bundles and the clients connect to them.
Section 5: ThresholdShedder: finding overloaded brokers
It first computes the average resource usage of all brokers using the following formula.
For each broker:
usage =
max (
%cpu * cpuWeight
%memory * memoryWeight,
%bandwidthIn * bandwidthInWeight,
%bandwidthOut * bandwidthOutWeight) / 100;
usage = x * prevUsage + (1 - x) * usage
avgUsage = sum(usage) / numBrokers
If any broker’s usage is bigger than avgUsage + y, it is considered an overloaded broker.
- The resource usage “Weight” is by default 1.0 and configurable by
loadBalancerResourceWeightconfigurations. - The historical usage multiplier x is configurable by loadBalancerHistoryResourcePercentage. By default, it is 0.9, which weighs the previous usage more than the latest.
- The avgUsage buffer y is configurable by loadBalancerBrokerThresholdShedderPercentage, which is 10% by default.
Takeaways
In this blog, we reviewed the Pulsar broker load balance logic focusing on its sequence. Here are the broker load balance behaviors that I found important in this review.
- Pulsar groups topics into bundles for easier tracking, and it dynamically assigns and balances the bundles among brokers. If specific bundles are overloaded, they get automatically split to maintain the assignment units to a reasonable level of traffic.
- Pulsar collects the global broker (cpu, memory, network usage) and bundle load data (msg in/out rate) to the leader broker in order to run the algorithmic load balance logic: bundle-broker assignment, bundle splitting, and unloading (shedding).
- The bundle-broker assignment logic randomly selects the least loaded brokers and redirects clients to the assigned brokers’ URLs. The broker-bundle ownerships create ephemeral locks in the metadata store, which are automatically released if the owners become unavailable (lose ownership).
- The bundle-split logic finds target bundles based on the LoadBalancerNamespaceBundle* configuration thresholds, and by default, the bundle ranges are split evenly. After splits, by default, the owner automatically unloads the newly split bundles.
- The auto bundle-unload logic uses the default LoadSheddingStrategy, which finds overloaded brokers based on the average of the max resource usage among CPU, Memory, and Network IO. Then, the leader asks the overloaded brokers to unload some high loaded bundles of topics. Clients’ topic connections under the unloading bundles experience connection close and re-initiate the bundle-broker assignment.
More Resources
Stay tuned for more operational content around Pulsar load balance, such as Admin APIs, metrics, logs, and troubleshooting tips. Meanwhile, check out more Pulsar resources:
- Take Apache Pulsar Training: Take the self-paced Pulsar courses or instructor-led Pulsar training developed by the original creators of Pulsar. This will get you started with Pulsar and help accelerate your learning.
- Spin up a Pulsar Cluster in Minutes: If you want to try building microservices without having to set up a Pulsar cluster yourself, sign up for StreamNative Cloud today. StreamNative Cloud is the simple, fast, and cost-effective way to run Pulsar in the public cloud.





