
We are excited to share that the Snowflake Sink Connector for Apache Pulsar is now generally available. This connector enables you to utilize Pulsar to preprocess data from a variety of sources and seamlessly offload the processed data into Snowflake in real-time. The Snowflake sink connector allows you to leverage Pulsar and Snowflake to develop high-performance data applications and perform advanced analytics.
What is the Snowflake Sink Connector for Apache Pulsar?
The Snowflake sink connector for Apache Pulsar is a tool that pulls data from Pulsar topics and securely stores it in Snowflake. This connector provides a seamless and efficient way to persist data to Snowflake.
Why Snowflake + Apache Pulsar?
Snowflake is a global cloud data warehouse that provides organizations with the tools to transform their data into valuable, real-time, and predictive insights. By uniting isolated data silos, Snowflake enables users to build data applications, models, and pipelines directly where the data is stored. Snowflake can handle a wide range of workloads, of varying types and scales, and can operate efficiently across multiple clouds. However, to fully leverage the capabilities of Snowflake, it is critical to ingest data in real-time.
Apache Pulsar is a real-time data platform designed to simplify the complexities of messaging and streaming workloads, making it easier to build end-to-end data pipelines. With its extensive range of connectors and serverless functions, Pulsar is ideal for integrating many different data sources and loading the data into Snowflake.
StreamNative, a company that provides a cloud-native data streaming platform powered by Apache Pulsar, developed the Snowflake Sink Connector for Apache Pulsar. This connector makes it simple for Snowflake users to utilize the full capabilities of Pulsar, enabling them to streamline data integration and ingestion into Snowflake. With this connector, Snowflake users can easily leverage Pulsar’s rich set of features to build high-performance data applications and perform advanced analytics.
What are the benefits of using the Snowflake connector?
The Snowflake sink connector provides several key benefits:
- Simplicity: Easily load data from Pulsar to Snowflake in real-time without the need to write user code.
- Efficiency: Reduce your time in configuring the data layer. This means you have more time to discover the maximum business value from real-time data in an effective manner.
- Flexible configuration: Configure the connector using a JSON or YAML file when running connectors in a cluster with Pulsar Function Worker. For those running connectors with Function Mesh, CustomResourceDefinitions (CRD) can be created to create a Snowflake sink connector.
What are the features of the Snowflake connector?
The Snowflake sink connector offers a rich set of features:
- Delivery guarantees: The connector supports the at-least-once delivery guarantees to ensure zero message loss.
- Auto table creation: Configure the connector such that tables are automatically created when they do not exist. Mapping relationships between topics and tables can also be specified.
- Metadata fields mapping: The connector allows you to map the metadata of a Pulsar message. Metadata fields including message_id, partition, topic, and event_time are automatically created. Other supported fields include schema_version, event_time, publish_time, sequence_id, and producer_name.
- Schema conversion: The connector supports Pulsar schema conversions for JSON, AVRO, and PRIMITIVE.
- Batch sending: Configure the buffer size and latency for the Snowflake connector to increase write throughput and enable batch sending.
How to get started with the Snowflake connector?
In this section, we walk through how to deploy the Snowflake connector depending on where you run it. In self-managed open-source Pulsar, function workers must be used to set up the connector. In StreamNative Cloud, you can leverage our built-in, cloud-native Kubernetes operator – Function Mesh – to deploy the connector.
Start the connector in open-source Pulsar using Functions Workers
Prerequisites
You should have an Apache Pulsar cluster and a Snowflake service set up:
- If you are using the self-managed open-source version, you can run Pulsar in standalone mode on your machine. Refer to the documentation for information on how to set this up.
- Ensure that your Snowflake service is properly configured. Refer to the Snowflake Quickstarts for detailed instructions. It is important to note that security settings must be configured to access Snowflake.
Get the connector
If you plan to run the Snowflake sink connector in a cluster using Pulsar Function Worker, you can obtain it using one of the following methods.
- Download the NAR package.
- Build it from the source code.
To build the Snowflake sink connector from the source code, follow these steps.
- Clone the source code to your machine.
git clone https://github.com/streamnative/pulsar-io-snowflake
- Build the connector in the pulsar-io-snowflake directory.
mvn clean install -DskipTests
- After the connector is successfully built, a NAR package is generated under the target directory.
ls target
Pulsar-io-snowflake-{{connector:version}}.nar
Configure the connector
You can create a configuration file (JSON or YAML) to set the properties if you use Pulsar Function Worker to run connectors in a cluster.
Here is an example of how to set the properties in JSON and YAML formats.
JSON
{
"tenant": "public",
"namespace": "default",
"name": "snowflake-sink",
"archive": "connectors/pulsar-io-snowflake-{{connector:version}}.nar",
"inputs": [
"test-snowflake-pulsar"
],
"parallelism": 1,
"retainOrdering": true,
"processingGuarantees": "ATLEAST_ONCE",
"sourceSubscriptionName": "sf_sink_sub",
"configs": {
"user": "TEST",
"host": "ry77682.us-central1.gcp.snowflakecomputing.com:443",
"schema": "DEMO",
"warehouse": "SNDEV",
"database": "TESTDB",
"privateKey": "SECRETS"
}
}
YAML
tenant: public
namespace: default
name: snowflake-sink
parallelism: 1
inputs:
- test-snowflake-pulsar
archive: connectors/pulsar-io-snowflake-{{connector:version}}.nar
sourceSubscriptionName: sf_sink_sub
retainOrdering: true
processingGuarantees: ATLEAST_ONCE
configs:
user: TEST
host: ry77682.us-central1.gcp.snowflakecomputing.com:443
schema: DEMO
warehouse: SNDEV
database: TESTDB
privateKey: SECRETS
Start the connector in StreamNative Cloud using Function Mesh
Prerequisites
- Deploy one Pulsar cluster in StreamNative Cloud. For instructions, see create clusters through StreamNative Cloud Console.
- Log in to the StreamNative Cloud Console or snctl CLI tool.
Get the connector
You can pull the Snowflake sink connector Docker image from the Docker Hub if you use Function Mesh to run the connector.
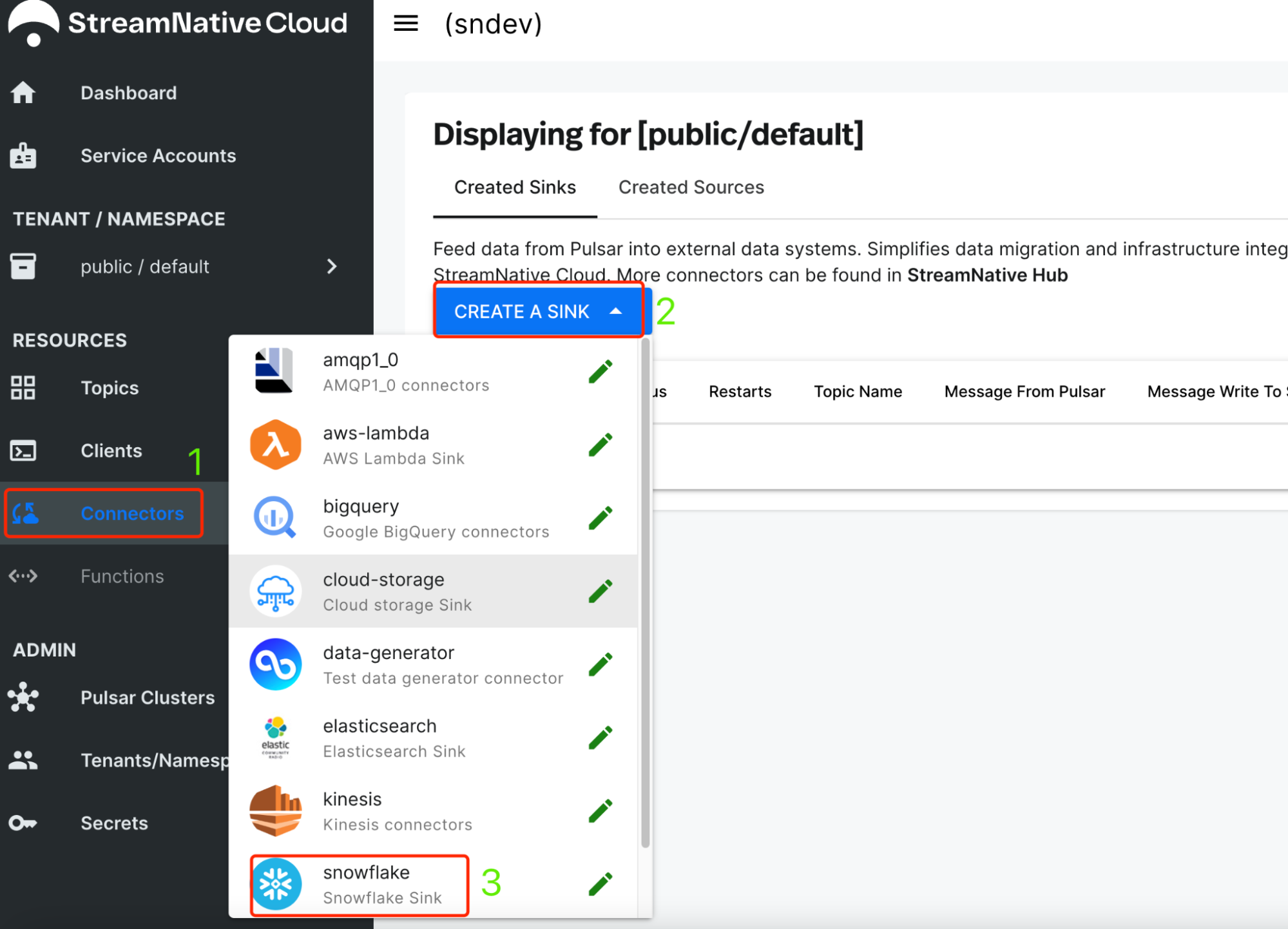
If you use SN Console UI to create the Snowflake connector, you can follow the steps in the screenshot: 1. Connectors > 2. Create a Sink > 3. Select Snowflake
Configure the connector
To create a Snowflake sink connector using Function Mesh, you can define a CustomResourceDefinitions (CRD) file (YAML) with the desired properties. This approach enables seamless integration with the Kubernetes ecosystem. For more information on Pulsar sink CRD configurations, check out our resource documentation.
Here is an example of how to set the properties in the CRD file (YAML).
apiVersion: compute.functionmesh.io/v1alpha1
kind: Sink
metadata:
name: snowflake-sink-sample
spec:
image: streamnative/pulsar-io-snowflake:{{connector:version}}
replicas: 1
maxReplicas: 1
retainOrdering: true
input:
topics:
- persistent://public/default/test-snowflake-pulsar
sinkConfig:
user: TEST
host: ry77682.us-central1.gcp.snowflakecomputing.com:443
schema: DEMO
warehouse: SNDEV
database: TESTDB
privateKey: SECRETS
pulsar:
pulsarConfig: "test-pulsar-sink-config"
resources:
limits:
cpu: "0.2"
memory: 1.1G
requests:
cpu: "0.1"
memory: 1G
java:
jar: connectors/pulsar-io-snowflake-{{connector:version}}.nar
clusterName: test-pulsar
autoAck: false
More resources
- Learn about the Snowflake Sink Connector for Apache Pulsar by exploring the documentation and video tutorial.
- Pulsar also offers connectors for other data warehouse and lakehouse technologies: Google Cloud BigQuery Sink Connector, Delta Lake Sink Connector, Hudi Sink Connector, and Iceberg Sink Connector.
- Pulsar Summit Europe 2023 is taking place virtually on May 23rd. Register today or become a community sponsor (no fee required).
- Make an inquiry: Interested in a fully-managed Pulsar offering built by the original creators of Pulsar? Contact us now.
- Learn the Pulsar Fundamentals: Sign up for StreamNative Academy, developed by the original creators of Pulsar, and learn at your own pace with on-demand courses and hands-on labs.





