
In this blog post, I will provide an in-depth review of the internal details of Apache Pulsar producers and consumers. Next, I will outline the common pitfalls that application developers encounter when working with Pulsar. Finally, I will introduce best practices you can use when developing streaming/messaging applications.
Pulsar Terminology
Apache Pulsar is a cloud-native, distributed messaging and event streaming platform that supports both pub/sub and event streaming use cases. Let’s start by introducing some key Pulsar terminology.
.webp)
Demystifying the Consuming Side
The consuming side is where you are most likely to encounter potentially confusing behavior, so let’s start there. We will also cover best practices you might want to use as a checklist when you create your applications.
How Consumers Work
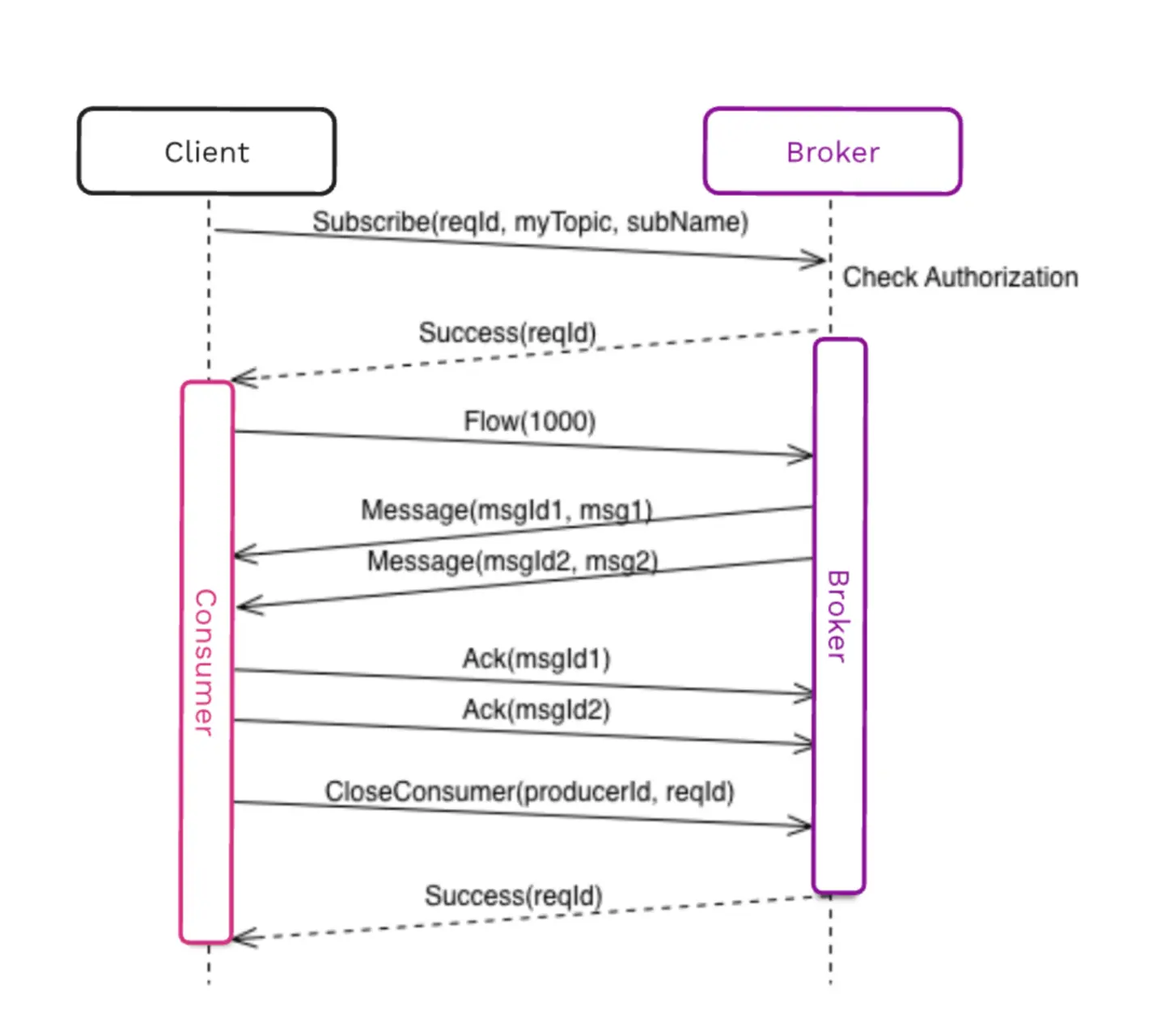 When a consumer comes up, it sends a “Flow” command to request messages from the broker, and then the broker sends messages up to the number of availablePermits. The max availablePermits is equal to the receiverQueue size which, by default is 1000 messages; therefore, it is as though the consumer says to the broker - “I have 1000 spots in my queue, so you can go ahead and send me up to 1000 messages.”
When a consumer comes up, it sends a “Flow” command to request messages from the broker, and then the broker sends messages up to the number of availablePermits. The max availablePermits is equal to the receiverQueue size which, by default is 1000 messages; therefore, it is as though the consumer says to the broker - “I have 1000 spots in my queue, so you can go ahead and send me up to 1000 messages.”
The broker receives this message that says this consumer has 1000 availablePermits and promptly dispatches the data while keeping track of every instance of activity. For example, if there are 10 messages to send, it dispatches those 10 and will continue to send 990 more. Only when that number reaches 0 will it stop sending data.
The consumer receives these messages in the receiverQueue. As long as you keep calling the receive() method, you pop those messages out of the queue. Later, when those 1000 messages are about halfway processed, it will send more (for example, it might send 500 more) permits to the broker.
The goal with message consumption is to keep it flowing. You always want to have messages available in the consumer queue size so that the application continually has messages to read and process.
Message Acknowledgement
An important mechanism in the flow described above is message acknowledgement. For the consuming side to be able to increase the number of availablePermits and request more messages, it needs to acknowledge the message back to the broker, validating that a specific message or group of messages was successfully consumed. In case an exception occurs, it can provide a negative acknowledgement (manually or automatically if an ackTimeout is provided - consumer.receive(500, TimeUnit.MILLISECONDS)), in which case it will redeliver the message. Pulsar supports two types of acknowledgements: individual and cumulative.
As its name suggests, individual acknowledgement sends an acknowledgment back to the broker after each message has been successfully processed. Cumulative acknowledgment, on the other hand, sends an acknowledgment for a batch of messages, which means that all the messages up to the specific offset will be acknowledged.
Note: Cumulative acknowledgment is not supported on the Shared Subscription mode.
What Is a Backlog?
A backlog (or consumer lag in the context of Kafka) describes how far behind a consumer is from the producing side. A backlog is the number of unacknowledged messages within a subscription.
For example, let’s say our producer has just sent successful message 1000 to the broker and our consumer has just successfully acknowledged processing message 800. This means that our backlog (or consumer lag) is 200, i.e. a subscription contains 200 messages that haven’t been acknowledged yet. In the upcoming Pulsar 2.10 release there will be built-in functionality for retrieving this metric directly with the Pulsar admin CLI by running pulsar-admin topics stats –etb true. The metric shows the timestamp from the publish time of the earliest message in the backlog to the current time and can be fetched.
Typical Pitfalls for the Consumers Not Processing Messages
Depending on the workload and the design of your application, you might encounter situations where your broker doesn’t send messages to the consumer or your consumer isn’t processing messages. In this section, I will outline some common pitfalls of such behavior and walk you through potential solutions.
As stated in the previous sections, a successful consuming flow is about having availablePermits to request messages from the broker, combined with the consumer’s receiverQueue, successful processing of the message, and making sure an acknowledgement is sent back to the broker. So… what could go wrong?
Scenario 1: The broker doesn’t dispatch messages and I see a growing backlog.
As mentioned, the first health check is to ensure your application acknowledges the messages after processing.
With that out of our way, we can see that this behavior might be due to the fact that your consuming application is not able to process messages fast enough. Going back to our consumer flow, by default the consumers ask for 1000 messages to hold in the receiverQueue. Depending on your processing logic, this could lead to a situation where your client requests more messages than are available to process, and this would lead to messages buffered in the queue eventually timing out and the backlog size growing. Therefore, it’s a good idea to lower this value so it is more meaningful.
In this scenario, typically you should see the availablePermits equal to 0 and unackedMessages that indicate that Pulsar has dispatched messages to the consumer, without the consumer having acked back to the broker.
Note: If the unacked messages exceed a threshold (which should be around 50,000 messages) then the consumer gets blocked, as described by setting blockedConsumerOnUnackedMsgs to true. You can use the pulsar-admin stats command to retrieve the metrics described here.
Scenario 2: I do see availablePermits > 0, but a slow or zero delivery rate.
If there are availablePermits, but the delivery rate is slow, then the bottleneck is either on the brokers or the bookies. This means that the application processes messages faster than we can send them.
If the delivery rate is zero, there is typically an issue with the broker. This could indicate that there is a high workload on your broker. For example, the broker might process too many topics with some high workloads and thus dispatch messages slowly.
Try to split the bundles and unload the topics to achieve better load distribution. For more information, read the documentation about unloading topics and bundles.
Scenario 3: I use KeyShared Subscription, I add new consumers but I don’t see them processing any messages.
KeyShared subscription aims to guarantee ordering (per key). If you spin up a new consumer, while you have old messages unacked, you have to wait until the old consumer has processed all the data up to the current point before the new consumer can get the new spread keys. When you are in situations where you create a new consumer and then are confused when it doesn’t process any messages, keep in mind that this might be a potential cause.
Scenario 4: I use KeyShared Subscription and add a new consumer, but I don’t see it processing any messages even though there are no unacked messages.
This scenario typically has to do with key imbalance. When you design your application, think in terms of your key space as having all your keys spread out as evenly as possible among your consumers (probably also the volume of messages per key). Otherwise, you might end up in situations where some consumers pick up too much work, while others stay idle.
Let’s illustrate what we’re learning with an example. Imagine you have just two keys - key1 and key2 - and start with just one consumer. Then, you spin up a second consumer, but the way the keys are distributed does not ensure that the new consumer will receive any of those keys - thus you will very likely end up with an idle consumer.
On the other hand, imagine you have key1 assigned to consumer1 and key2 assigned to consumer2. Now, let’s assume that key1 is a userId and that user is 24/7 with the system and key2 is another userId for a user who only comes online once per week. As you might have guessed, you will see consumer1 processing too many messages. You might think that consumer2 is idle; in reality, it doesn’t have any messages to process for that key until a particular day of the week. This is why it is important to provide a key that will result in more equal message distribution.
At this point, we have covered quite a lot for the consuming side. One highlight here that applies to all of the applications is you should always ensure you close your client resources. Producers and consumers/readers are long-lived resources you typically create once and then keep as long as you like. However, there are situations that might require that you create a producer or consumer/reader (probably on demand) to perform functionality and exit. In both situations, you need to make sure that all the resources are closed before your application exits to avoid resource leaks.
Imagine a scenario where you spin up a consumer on demand to perform just one task and then exit, but you do not actually close it. By default, the consumers have a receiverQueue size of 1000. This means that when your consumer comes up, it will pre-fetch 1000 messages, perform some computation, and exit. If you don’t close the resources, messages will sit in the buffer and there will always be a backlog of 1000 messages because this “leaked” consumer holds those messages without consuming them.
Important Note: After you process each message, acknowledge that back to the broker. Otherwise, you will see backlogs increasing, using one of the available methods. For consumers it is recommended to use the same consumer instance to ACK messages. If you don’t (for whatever reason), you can create a consumer with a receiver queue size equal to 1. This will mimic the number of messages that this consumer needs to pre-fetch.
Demystifying the Producing Side
On the producing side, you have some kind of data source that generates data you want to send to Pulsar. Typical sources include ingesting data from files, connecting with some IoT messaging protocol like MQTT, receiving updates from Change Data Capture systems and more. When each message arrives you create a new Pulsar Message using the payload and use a Pulsar Producer to send that message over to the brokers. In order to use a producer first you need to have one in place. In the producer creation process there are a few things you might want to consider.
First, you need to decide on the schema of the message you want to use. By default everything is sent as bytes, but all the primitive data types are supported and more complex data formats like Json, Avro and Protobufs. For more information about schema, see Understand schema.
Second, you want to properly configure your producer:
- Batching: In order to send a message to the broker you can use either the send() method, which sends the message and waits until an acknowledgement is received or sendAsync() methods that sends the message without waiting for the acknowledgment. The sendAsync() method is used in order to increase the throughput of your application and uses batching in order to create batches of messages and send them altogether instead of sending each message and waiting for a response. By default batching is enabled in Pulsar. You can tune the maximum number of messages the buffer can hold as well as the byte size and a batch is considered “full” and ready to be sent to Pulsar when either one of these two thresholds is met. In case you have large messages and you want to create batches of 1000 messages for example, you might wanna increase the batchingMaxBytes limit (default is 128kb). Also when you use the sendAsync() method, because of the asynchronous nature your producer might be overwhelmed with ack message response, in which case there is another configuration option you will need to enable blockIfQueueFull(true), which applies backpressure when the producer is overwhelmed - i.e signals to the broker to “slow down”. Here is an example producer that uses batching, applies backpressure and tunes the batching buffer.
Producer producer = pulsarClient.newProducer(Schema.STRING)
.topic(topic)
.producerName("test-producer")
.enableBatching(true)
.blockIfQueueFull(true)
.batchingMaxMessages(10000)
.batchingMaxBytes(10000000)
.create();
- Chunking: There are situations where your messages are too large and you want to send them as chunks to the broker. In order to enable chunking you need to disable batching and also you might wanna tune the sendTimeout option, depending how large your message is and your network latency. Here is an example of a chunking producer with an increased timeout.
Producer producer = pulsarClient.newProducer(Schema.STRING)
.topic(topic)
.producerName("test-producer")
.enableBatching(false)
.enableChunking(true)
.sendTimeout(120, TimeUnit.SECONDS)
.create();
- Routing: Your topics can be either non-partitioned or partitioned topics. In case of a partitioned-topic you might wanna have control on how messages are routed over to these partitions, in which case you need to tune your messageRoutingMode and also specify a messageRouter. Here is a producer example that specifies the routing mode as well how the messages should be routed - here we calculate some hash based on the message key. Also note that we specify the Murmur3_32Hash algorithm.
Producer producer = pulsarClient.newProducer(Schema.STRING)
.topic(topic)
.producerName("test-producer")
.blockIfQueueFull(true)
.messageRoutingMode(MessageRoutingMode.CustomPartition)
.hashingScheme(HashingScheme.Murmur3_32Hash)
.messageRouter(new MessageRouter() {
@Override
public int choosePartition(Message msg, TopicMetadata metadata) {
String key = msg.getKey();
return Integer.parseInt(key) % metadata.numPartitions();
}
})
.create();
As you can see the producing side is more straightforward with not many hidden caveats. It’s mostly fine-tuning to meet your application requirements. One thing though that is important to highlight is the number of producers you might create within your application. For example you might want to ingest multiple files (hundreds or thousands) from a directory or, for example, you have a web app and you want to spin up a producer for each user login. Producers are long-living processes, so creating hundreds or thousands of producers is something you should avoid. Instead what you can do is create a ProducerCache with a fixed number of producers that you can reuse across your application.
Client Application Checklist
- Name your producers, consumers, and readers.
- On the producing side, you typically want to use the sendAsync() method in order to achieve better throughput. Be sure to set the blockIfQueue option to true on your producer to ensure that backpressure gets applied. Due to the async nature, we might receive too many ack messages that the producer queue can't process fast enough. With this option, we can signal to wait before sending more.
- When you use a KeyShared subscription, make sure that your producing side uses a BatchBuilder.KeyShared. This ensures that messages with the same keys end up in the same batches.
- When you use partitioned topics, think in terms of how you distribute the workload to ensure you don’t have topics with large numbers of messages, while others are too small (this can impact both brokers and consumers as we saw in Scenarios 3 and 4).
- The same applies for key shared subscriptions: You typically want to think of your key space and see how you can better distribute the workload among consumers. This avoids the risk of one consumer picking up most of the work, while others sit mostly idle.
- For producers, you should avoid creating a producer for each message. For situations that require producers on demand, you might use a Map or a LRU cache and grab a producer from within that cache.
- Use the same consumer to acknowledge a message.
- On the producing side, make sure you check your batchMaxMessages size, which defaults to 1000. For example, if you have messages that are 1MB in size, this default might be too big for your application, and you will have 1GB sitting on your direct memory.
- On the consuming side, make sure you tune your receiverQueueSize, which defaults to 1000. For example, if you have messages that are 1MB in size, this default might be too big for your application, and you will have 1GB sitting on your direct memory, especially if your consumer does some heavy work.
- Use partitioned topics, even if you define just one partition. By doing so, if your traffic increases later, you can easily add more partitions to meet the demand. If you use a non-partitioned topic you will have to create a new partitioned-topic and migrate the data to the new topic in order to scale.
- Malformed messages will fail to be acknowledged. In this case, you might want to fine tune your consumers with the ackTimeout setting, and maybe introduce dead letter topics to recover from such cases and further investigate your messages. For more information, read the documentation about dead letter topics.



