
As a cloud-native distributed messaging and streaming platform, Apache Pulsar has a variety of features that differentiate it from other tools. One of the capabilities that got me to “fall in love” with it was individual message acknowledgment. When I was working with Apache Kafka, I noticed that one of the key features missing was the ability to signal which messages have been successfully processed. In this post, I will give a high-level explanation of how individual message acknowledgments work in a simple and elegant way in Pulsar.
Individual message acknowledgment: Why other systems fall short
The classic use case for individual message acknowledgment is task execution where the message describes the task, such as triggering an alert or sending an email. If some of the tasks fail, you may want to retry them, but you don’t want to reprocess those that have already succeeded. In Kafka, the only native option you have is to signal success for the entire bulk of messages that your application has read. The naive way of implementing retries for failed individual messages is stopping to read messages, and retrying the failed ones. However, the retries may have delays between them, resulting in a “traffic jam” in the execution pipeline. A more sophisticated workaround is to write the failed messages to a retry topic and store in a different data store when each message should be retried. Nevertheless, this requires a lot of writing, wiring, and DevOps work.
As that feature is not natively baked into Apache Kafka, you search for alternatives. The popular options are Apache ActiveMQ and RabbitMQ, but neither was designed to handle the scale of data as opposed to Kafka. This means they are not horizontally scalable, fault-tolerant, or highly available like Kafka. When you search for a distributed system with the ability to acknowledge individual messages, one tool that may appear in the results is Apache Pulsar.
Apache Pulsar provides the individual acknowledgment capability by design. It boasts a client supporting retries, with exponential back-off delays between messages (delay increasing in duration exponentially: 2, 4, 8, 16, 32 seconds) without any additional code on the user side.
Reading and writing in Pulsar
As shown in Figure 1, the Pulsar clients (comprising a Producer and two Consumers) communicate with the Pulsar cluster, which consists of multiple Brokers. The producer writes messages to a topic. Reading messages from a topic, on the other hand, requires a subscription. It’s the actual entity stored in the broker that keeps the position of readers. It tells you which messages have been read and which remains to be read. Each subscription can have one or multiple consumers, allowing them to share the load of reading and processing the messages across multiple machines, each running its own consumer.
Different subscriptions allow you to read the same messages on the topic for different purposes, each having its own consumption position tracked by its respective cursor. For example, one subscription can slowly upload the messages to S3, while another can quickly compute in-memory aggregations and flush them to an analytics database.
For a given subscription, consumers have the following API:
- consume() → Messages (each containing a MessageID)
- acknowledge(messageID)
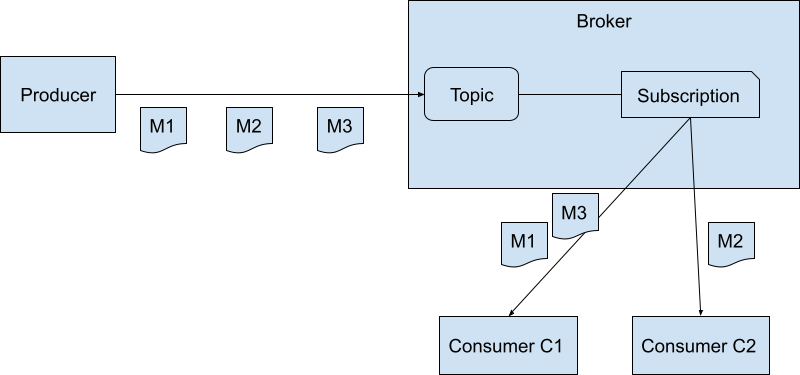
For efficiency reasons, the consumer buffers the individual acknowledgment commands and sends them in bulk to the broker. This behavior can be tuned by setting the maximum time to buffer before sending, or the maximum number of acknowledgments to hold before sending. The trade-off is that if the consumer machine goes down, these acknowledgments will not be persisted. As a result, messages will be redelivered to the consumers for that subscription. Since Pulsar guarantees at-least-once delivery, this does not break that contract. It’s a trade-off many high-scale systems make.
For avid Kafka users, note that Pulsar has two types of topics: Topics (as described above) and Partitioned Topics. A single partitioned topic is composed of several partitions, each implemented as an internal topic. In short, a Kafka Topic is equivalent to a Pulsar Partitioned Topic, and a Kafka Topic Partition is effectively an internal Pulsar Topic.
Before we dive into individual message acknowledgments, we need to understand how storage works in Pulsar (how messages are stored) as it is essential to knowing other key concepts.
How do messages persist on Pulsar brokers?
Pulsar, different from many messaging systems, doesn’t store its messages on broker’s disks. It stores them in a separate system called Apache BookKeeper. This two-layer architecture design powers many unique features.
In Apache BookKeeper, ledgers are the basic unit of storage. You can consider them as virtual files. An entry written to a ledger is appended to the end of it. An entry is simply a container for any data you keep and the data itself is just a byte array. Pulsar converts the message produced to it into a byte array and persists it as an entry in BookKeeper.
You can open a ledger, append entries to it, and eventually close it so that it becomes immutable (read-only). A ledger can only be written by a single writer, namely a single machine.
In Pulsar, a topic is actually a list of ledger IDs. Pulsar opens a ledger and appends any message it receives for the topic to the currently active ledger for that topic. After a size or time threshold is reached, the ledger is closed with a new one opened.
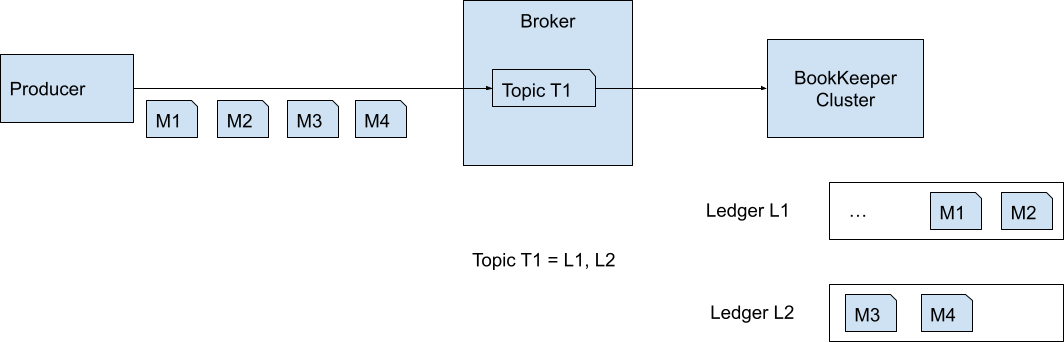
Apache BookKeeper by itself is a distributed system, which is horizontally scalable, fault-tolerant to its data, and highly available. It offloads many responsibilities from Pulsar, and it deserves its own blog post, so we won’t dive into more details.
Acknowledgment of messages
The subscription is a data structure, holding information about which messages have been acknowledged and which have not. It’s composed of the following fields:
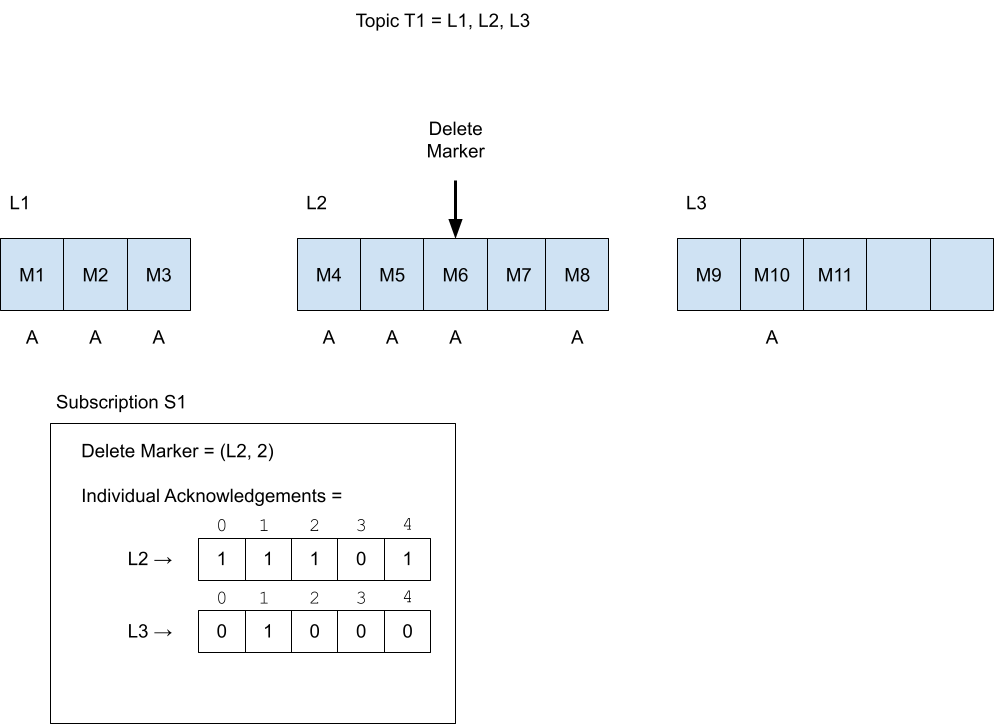
- Delete Marker (a.k.a. markDeletePosition): The position of a message in a topic. All messages before it (inclusive) have been acknowledged. In Pulsar, the default behavior is to delete acknowledged messages, so it is named this way.
- Since a topic is a list of ledgers, a position is a specific Ledger ID contained in that list, and an entry ID (the position of the entry within the ledger, the first one being 0).
- Individual Acknowledgments: The messages that have been acknowledged, which are positioned after the Delete Marker. The data structure for it is a map between a Ledger ID to a bit set. A bit set at position 10 means the 11th message in that ledger has been acknowledged.
As I mentioned earlier, Pulsar contains a cluster of brokers. Every broker has a set of topics it is responsible for, which means all reads and writes for those topics go through that broker. Hence, the broker keeps that subscription data structure in memory for all subscriptions of those topics. The resiliency to broker failures comes in the form of persisting the subscription data structure: it is written to BookKeeper at a certain frequency, and in some cases to ZooKeeper.
Each subscription has a separate designated ledger which the subscription state is persisted to. The in-memory data structure is converted into a more compact data structure called “Position Info” and then serialized into a byte array through Protocol Buffers encoding, and appended as entry to the designated subscription ledger.
Position Info contains the following fields:
- Delete Marker Ledger ID
- Delete Marker Entry ID
- Array of Ranges, where each Range is a:
- Range Start Ledger ID
- Range Start Entry ID
- Range End Ledger ID
- Range End Entry ID
If we take Figure 3 as an example, we can convert it into Position Info as follows:
Delete Marker Ledger ID = L2
Delete Marker Entry ID = 2
Ranges[] =
Range 0: (L2, 0) —> (L2, 2)
Range 1: (L2, 4) —> (L2, 4)
Range 2: (L3, 1) —> (L3, 1)
The subscription has two event types triggering the persistence of the subscription in-memory state to the ledger:
- The consumer acknowledges a message. Since this happens at a rather high frequency, there’s a rate limiter, limiting it to 1 persistence action per second by default.
- Timeout. If the state is “dirty” and hasn’t been changed for X seconds, it’s persisted to BookKeeper.
In a worst-case scenario, there may be a large number (e.g. millions) of acknowledged messages that are fragmented. In that case, Position Info will be extremely large (tens of megabytes). The current workaround for that is increasing the rate limiting frequency so that it is higher than the default value (1 persistence action per second). This trades off the number of acknowledged messages you lose when the broker terminates ungracefully between persistence actions.
Currently, some community members are actively working on some solutions:
- Compress Position Info.
- Splitting Position Info into multiple BookKeeper entries as explained in PIP-81.
In case of a broker failure, you can lose acknowledgments for the subscriptions handled by that broker, depending on your configuration. By default you can lose up to 1 second worth of acknowledgments, as long as the subscription is active and messages are constantly acknowledged (triggering the persistence of it). If the subscription suddenly stops consuming messages, you will lose a time-out (as you configured) worth of acknowledged messages.
The subscription ledger (where the subscription state is persisted to) ID is persisted in ZooKeeper. When a broker crashes, another broker will take ownership of the topic it serves. That broker obtains the subscription ledger ID from ZooKeeper and then reads the last subscription state from that ledger (last entry) into memory.
There is a corner case optimization: if the number of unacknowledged message ranges in the converted Position Info is less than 1000 (by default), then the subscription state will be persisted directly in ZooKeeper. This only happens when the subscription ledger is closed (rolled over due to size/time) or a topic is moved from one broker to another (due to shutdown).
Summary
This blog explained the individual message acknowledgment feature of Apache Pulsar. It also covered the read and write logic, as well as message storage, to give a broader context for understanding it. I hope this post can be helpful for you to understand part of the “magic” behind Pulsar. Future posts will dive into other unique features of Pulsar.
More on Apache Pulsar
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community that continues to drive innovation and improvements to the project.
- Start your on-demand Pulsar training today with StreamNative Academy.
- Spin up a Pulsar cluster in minutes with StreamNative Cloud. StreamNative Cloud provides a simple, fast, and cost-effective way to run Pulsar in the public cloud.
- Pulsar Summit Asia 2022 will take place on November 19th and 20th, 2022. The CFP is open now! Submit a proposal to share your Pulsar story!




