
The explosive growth of connected remote devices is posing challenges for the centralized computing paradigm. Due to network and infrastructure limitations, organizations find it increasingly difficult to move and process all the device-generated data in data centers or the cloud without latency or performance issues. As a result, edge applications are on the rise. By Gartner’s estimation, 75% of enterprise data will be created and processed outside data centers or the cloud by 2025.
So what are edge applications? Edge applications run on or near the sources of data, such as IoT devices and local edge servers, and edge execution. Edge computing enables computation, storage, cache, management, alerting, machine learning, and routing to happen beyond data centers and the cloud. Organizations across industries, such as retail, farming, manufacturing, transportation, healthcare, and telecommunications, are adopting edge applications to achieve lower latency, better bandwidth availability, lower infrastructure costs, and faster decision-making.
In this article, you will learn some of the challenges of developing edge applications and why Apache Pulsar is the solution. You will also learn how to build edge applications using Pulsar with a step-by-step example.
1. Key Challenges
While the decentralized nature of edge computing offers a multitude of benefits, it also poses challenges. Some of the key challenges include:
- Edge applications often need to support a variety of devices, protocols, languages, and data formats.
- Communication from edge applications needs to be asynchronous with a stream of events from sensors, logs, and applications at a rapid but uneven pace.
- By design, edge producers of data require diverse messaging cluster deployments.
- By design, edge applications are geographically distributed and heterogeneous.
2. The Solution
To overcome the key challenges of building edge applications, you need an adaptable, hybrid, geo-replicated, extensible, and open-source solution. A widely-adopted open-source project provides the support of an engaged community and a rich ecosystem of adapters, connectors, and extensions needed for edge applications. After working with different technologies and open-source projects for the past two decades, I believe Apache Pulsar solves the needs for edge applications.
Apache Pulsar is an open-source, cloud-native, distributed messaging and streaming platform. Since Pulsar became a top-level Apache Software Foundation project in 2018, its community engagement, ecosystem growth, and global adoption have skyrocketed. Pulsar is equipped to solve the many challenges of edge computing because:
- Apache Pulsar supports fast messaging, metadata, and many data formats with support for various schemas.
- Pulsar supports a rich set of client libraries in Go, C++, Java, Node.js, Websockets, and Python. Additionally, there are community-released open-source clients for Haskell, Scala, Rust, and .Net as well as stream processing libraries for Apache Flink and Apache Spark.
- Pulsar supports multiple messaging protocols, including MQTT, Kafka, AMQP, and JMS.
- Pulsar’s geo-replication feature solves the issues with distributed device locations.
- Pulsar is cloud-native and can run in any cloud, on-premises, or Kubernetes environment. It can also be scaled down to run on edge gateways and powerful devices like the NVIDIA Jetson Xavier NX.
In today’s examples, we build out edge applications on an NVIDIA Jetson Xavier NX, which provides us enough power to run an edge Apache Pulsar standalone broker, multiple web cameras, and deep learning edge applications with horsepower to spare. My edge device contains 384 NVIDIA CUDA® cores and 48 Tensor cores, six 64-bit ARM cores, and 8 GB of 128-bit LPDDR4x RAM. In my upcoming blogs, I will show you that running Pulsar on more restrained devices like Raspberry PI 4s and NVIDIA Jetson Nanos is still adequate for fast edge event streams.
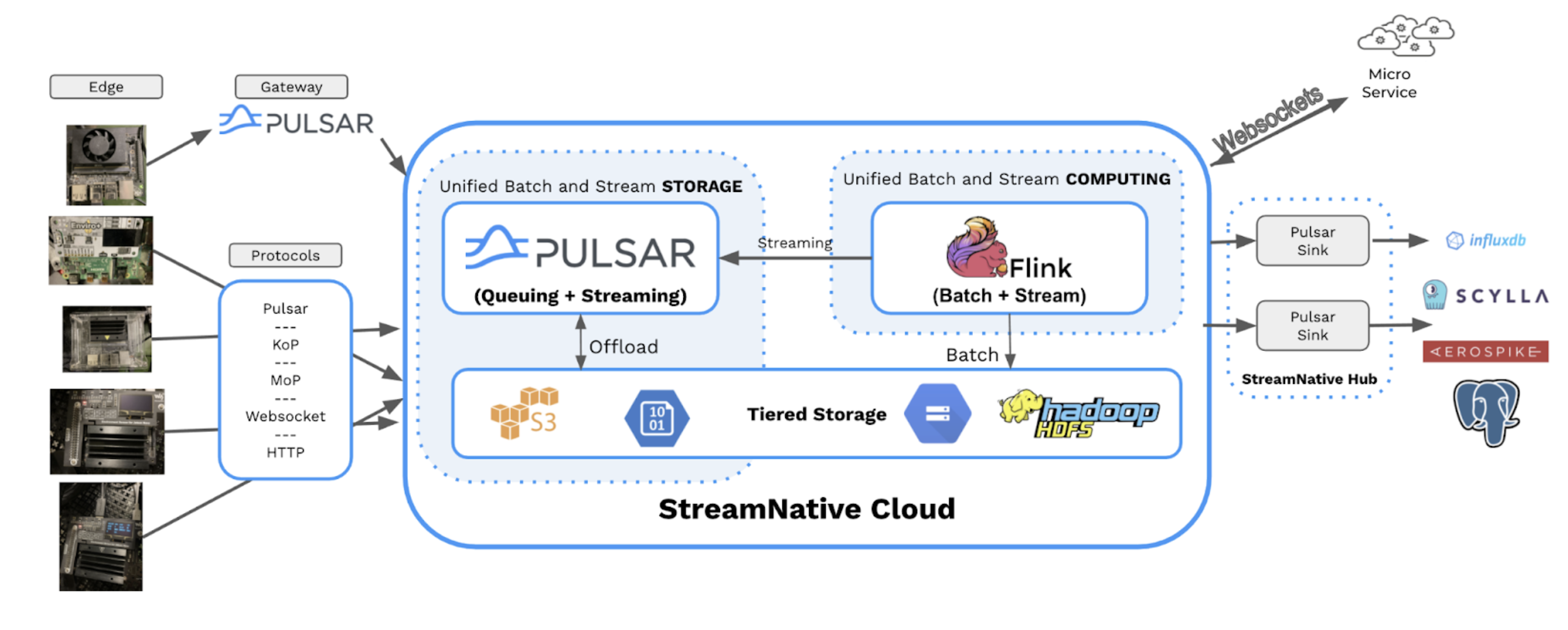
3. Architecture
Now that we have covered the physical architecture of our solution, let’s focus on how we want to logically structure incoming data. For those of you unfamiliar with Pulsar, each topic belongs to both a tenant and a namespace as shown in the diagram below.
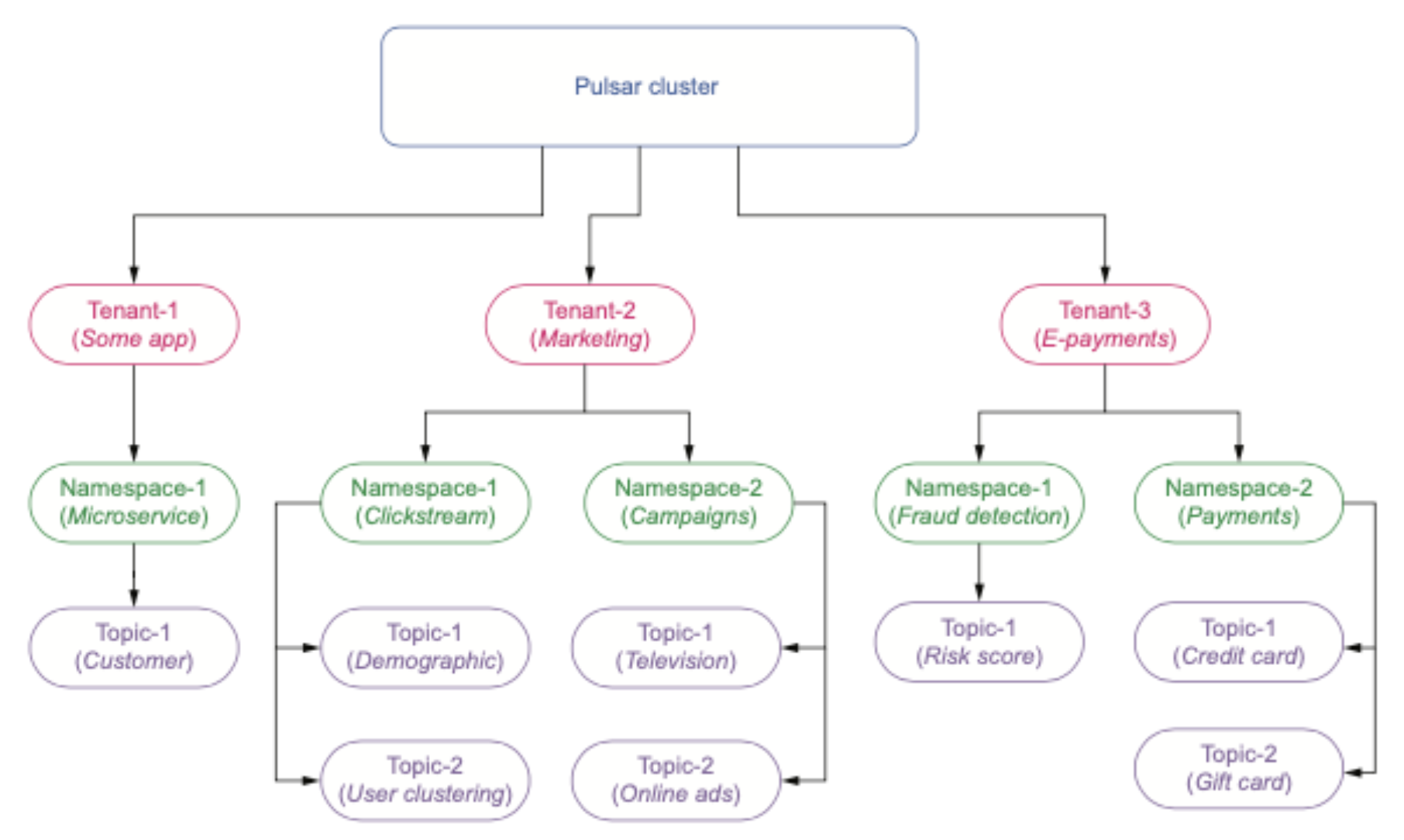
These logical constructs allow us to group data together based on various criteria such as the original source of the data and different business. Once we have decided on our tenant, namespaces, and topics, we need to determine what fields we will need to collect additional data required for analytics.
Next, we need to determine the format of our data. It can be the same as the original format or we can transform it to meet transport, processing, or storage requirements. We need to ask ourselves a number of architectural questions. Plus in many cases, our devices, equipment, sensors, operating system, or transport force us to choose a specific data format.
For today’s application we are going to use JSON, which is ubiquitous for practically any language and human readable. . Apache Avro, a binary format, is also a good option, but for these blogs we will keep it simple.
Now that data format is chosen, we may need to enrich the raw data with extra fields beyond what is produced by the sensors, machine learning classification, logs, or other sources. I like to add IP address, mac address, host name, a creation timestamp, execution time, and some fields about the device health like disk space, memory, and CPU. You can add more or remove some if you don’t see a need for it or if your device already broadcasts device health. At a minimum these fields can help with debugging especially when you get thousands of devices. Therefore I always like to include them unless strict bandwidth restrictions make that impossible.
We need to find a primary key or unique identifier for our event record. Often IoT data does not have a natural one. We can synthesize one with a UUID generator at the creation of the record.
Now that we have a list of fields, we need to fit a schema to our data and determine field names, types, defaults, and nullability. Once we have a schema defined, which we can do with JSON Schema or build a class with the fields, we can then use Pulsar SQL to query data from our topics. We can also leverage that schema to run continuous SQL with Apache Flink SQL.

For IoT applications you often want to use a time-series-capable primary data store for these events. I recommend Aerospike, InfluxDB, or ScyllaDB. We can handle this via Pulsar IO sinks or other mechanisms based on use cases and needs. We can use the Spark connector, Flink Connector, or NiFi connector if needed.
Our final event will look like the JSON in the following example.
{"uuid": "xav_uuid_video0_lmj_20211027011044", "camera": "/dev/video0", "ipaddress": "192.168.1.70", "networktime": 4.284832000732422, "top1pct": 47.265625, "top1": "spotlight, spot", "cputemp": "29.0", "gputemp": "28.5", "gputempf": "83", "cputempf": "84", "runtime": "4", "host": "nvidia-desktop", "filename": "/home/nvidia/nvme/images/out_video0_tje_20211027011044.jpg", "imageinput": "/home/nvidia/nvme/images/img_video0_eqi_20211027011044.jpg", "host_name": "nvidia-desktop", "macaddress": "70:66:55:15:b4:a5", "te": "4.1648781299591064", "systemtime": "10/26/2021 21:10:48", "cpu": 11.7, "diskusage": "32367.5 MB", "memory": 82.1}
4. Edge Producers
Let’s test out a few libraries, languages, and clients on our NVIDIA Jetson Xavier NX to see which is best for our use case. After prototyping a number of libraries that ran on Ubuntu with NVIDIA Jetson Xavier NX’s version of ARM, I have found a number of options that produce messages in line with what I need for my application. These are not the only but very good options for this edge platform.
- Go Lang Pulsar Producer
- Python 3.x Websocket Producer
- Python 3.x MQTT Producer
- Java 8 Pulsar Producer
Go Lang Pulsar Producer
package main
import (
"context"
"fmt"
"log"
"github.com/apache/pulsar-client-go/pulsar"
"github.com/streamnative/pulsar-examples/cloud/go/ccloud"
"github.com/hpcloud/tail"
)
func main() {
client := ccloud.CreateClient()
producer, err := client.CreateProducer(pulsar.ProducerOptions{
Topic: "jetson-iot",
})
if err != nil {
log.Fatal(err)
}
defer producer.Close()
t, err := tail.TailFile("demo1.log", tail.Config{Follow:true})
for line := range t.Lines {
if msgId, err := producer.Send(context.Background(),
&pulsar.ProducerMessage{
Payload: []byte(line.Text),
}); err != nil {
log.Fatal(err)
} else {
fmt.Printf("jetson:Published message: %v-%s \n",
msgId,line.Text)
}
}
}
Python 3 Websocket Producer
import requests, uuid, websocket, base64, json
uuid2 = uuid.uuid4()
row = {}
row['host'] = 'nvidia-desktop'
ws = websocket.create_connection( 'ws://server:8080/ws/v2/producer/persistent/public/default/energy')
message = str(json.dumps(row) )
message_bytes = message.encode('ascii')
base64_bytes = base64.b64encode(message_bytes)
base64_message = base64_bytes.decode('ascii')
ws.send(json.dumps({ 'payload' : base64_message, 'properties': { 'device' : 'jetson2gb', 'protocol' : 'websockets' },'key': str(uuid2), 'context' : 5 }))
response = json.loads(ws.recv())
if response['result'] == 'ok':
print ('Message published successfully')
else:
print ('Failed to publish message:', response)
ws.close()
Java Pulsar Producer with Schema
public static void main(String[] args) throws Exception {
JCommanderPulsar jct = new JCommanderPulsar();
JCommander jCommander = new JCommander(jct, args);
if (jct.help) {
jCommander.usage();
return;
}
PulsarClient client = null;
if ( jct.issuerUrl != null && jct.issuerUrl.trim().length() >
0 ) {
try {
client = PulsarClient.builder()
.serviceUrl(jct.serviceUrl.toString())
.authentication(
AuthenticationFactoryOAuth2.clientCredentials(new URL(jct.issuerUrl.toString()),new URL(jct.credentialsUrl.toString()), jct.audience.toString())).build();
} catch (PulsarClientException e) {
e.printStackTrace();
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
else {
try {
client = PulsarClient.builder().serviceUrl(jct.serviceUrl.toString()).build();
} catch (PulsarClientException e) {
e.printStackTrace();
}
}
UUID uuidKey = UUID.randomUUID();
String pulsarKey = uuidKey.toString();
String OS = System.getProperty("os.name").toLowerCase();
String message = "" + jct.message;
IoTMessage iotMessage = parseMessage("" + jct.message);
String topic = DEFAULT_TOPIC;
if ( jct.topic != null && jct.topic.trim().length()>0) {
topic = jct.topic.trim();
}
ProducerBuilder producerBuilder = client.newProducer(JSONSchema.of(IoTMessage.class))
.topic(topic)
.producerName("jetson").
sendTimeout(5, TimeUnit.SECONDS);
Producer producer = producerBuilder.create();
MessageId msgID = producer.newMessage()
.key(iotMessage.getUuid())
.value(iotMessage)
.property("device", OS)
.property("uuid2", pulsarKey)
.send();
producer.close();
client.close();
producer = null;
client = null;
}
private static IoTMessage parseMessage(String message) {
IoTMessage iotMessage = null;
try {
if ( message != null && message.trim().length() > 0) {
ObjectMapper mapper = new ObjectMapper();
iotMessage = mapper.readValue(message, IoTMessage.class);
mapper = null;
}
}
catch(Throwable t) {
t.printStackTrace();
}
if (iotMessage == null) {
iotMessage = new IoTMessage();
}
return iotMessage;
}
java -jar target/IoTProducer-1.0-jar-with-dependencies.jar --serviceUrl pulsar://nvidia-desktop:6650 --topic 'iotjetsonjson' --message "...JSON…"
You can find all the source code here.
Now we determine how to execute our applications on the devices. It can be using a scheduler that comes with the system such as cron or some add-on. I often use cron, MiNiFi agents, a shell script, or run the application continuously as a service. You will have to investigate your device and sensor for optimal scheduling.
5. Validate Data and Monitor
Now that we have a continuous stream of events streaming into our Pulsar cluster, we can validate the data and monitor our progress. The easiest option is to use StreamNative Cloud Manager for a fresh web interface to our unified messaging data, as shown in the diagram below. We also have the option to view the Pulsar metrics endpoint as documented here.
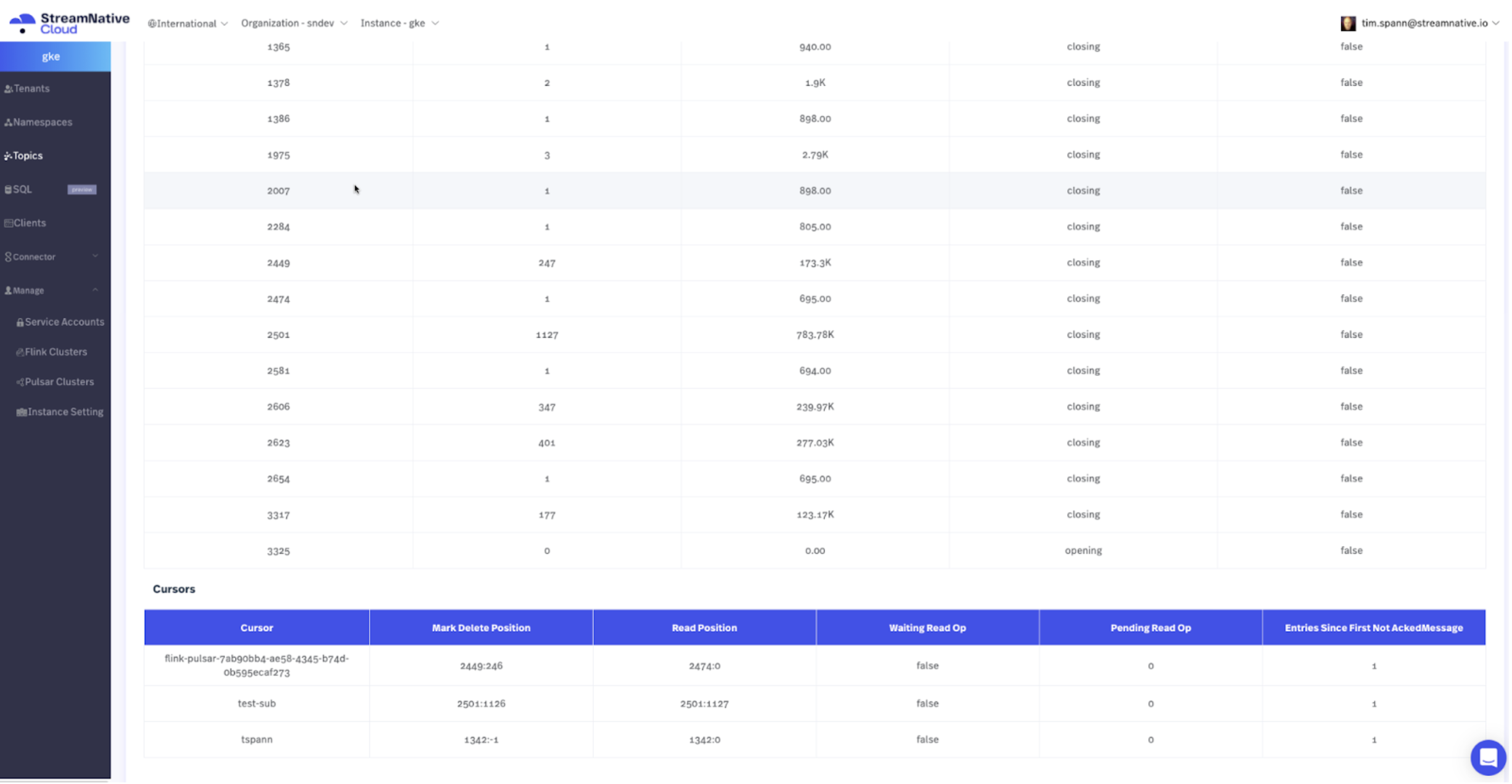
Check Stats via REST
http://:8080/admin/v2/persistent/public/default/mqtt-2/stats http://:8080/admin/v2/persistent/public/default/mqtt-2/internalStats
Check Stats via Admin CLI
bin/pulsar-admin topics stats-internal persistent://public/default/mqtt-2
Find Subscriptions to Your Topic
http://nvidia-desktop:8080/admin/v2/persistent/public/default/mqtt-2/subscriptions
Consume from Subscription via REST
http://nvidia-desktop:8080/admin/v2/persistent/public/default/mqtt-2/subscription/mqtt2/position/10
Consume Messages via CLI
bin/pulsar-client consume "persistent://public/default/mqtt-2" -s "mqtt2" -n 5
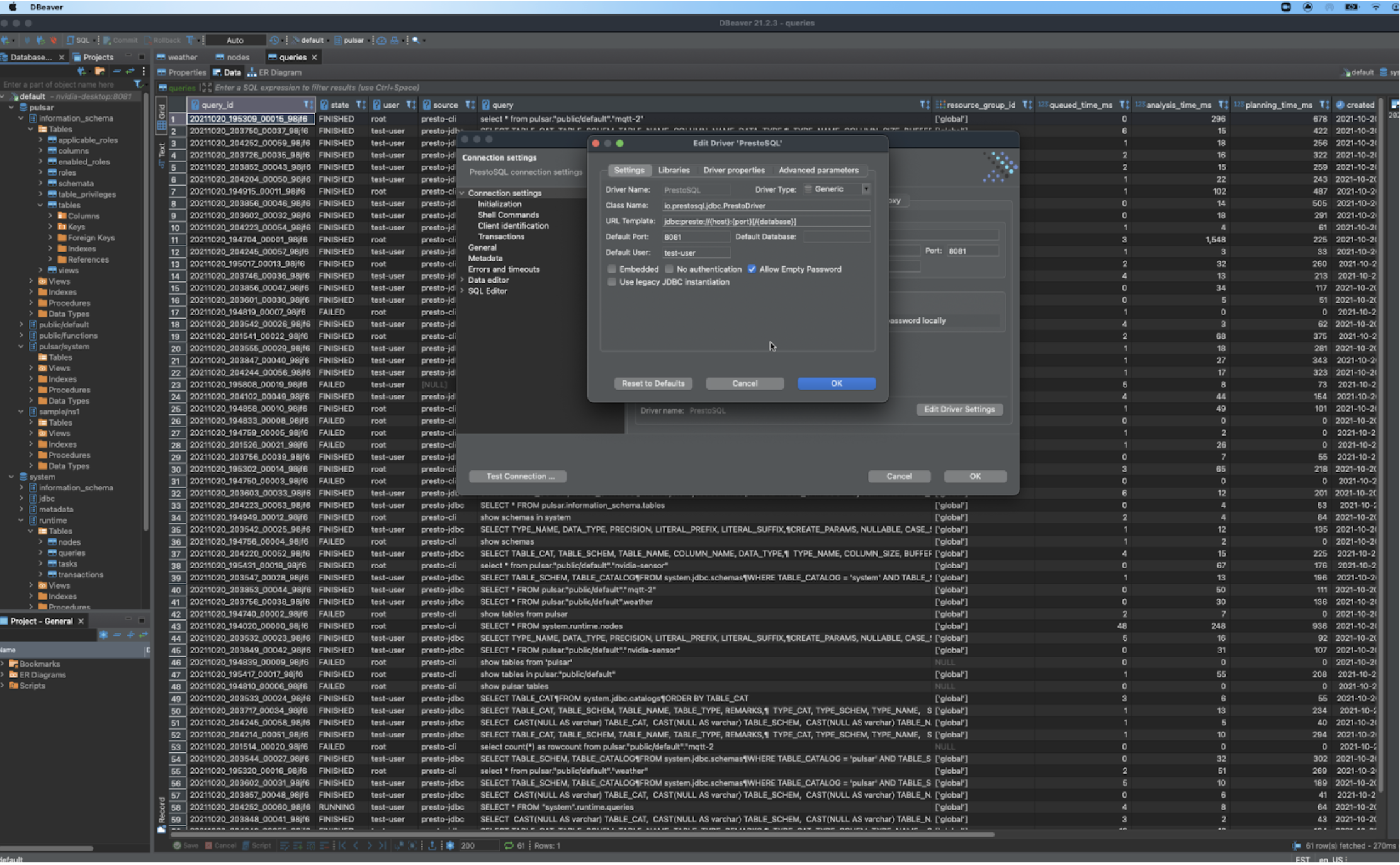
Query Topics via Pulsar SQL
select * from pulsar."public/default".iotjetsonjson;
6. Next Steps
At this point, we have built an edge application that can stream data at event speed and join thousands of other applications’ streaming data into your Apache Pulsar cluster. Next we can add rich, real-time analytics with Flink SQL. This will allow us to do advanced stream processing, join event streams, and process data at scale.
Start a trial with StreamNative Cloud now so you can start building IoT applications immediately. With StreamNative Cloud, you can spin up a Pulsar Cluster within minutes.
7. Further Learning
This blog did not cover the Pulsar fundamentals, which you will need if you want to build your own edge applications following my methods. If you are new to Pulsar, I highly recommend that you take the self-serve Pulsar courses or instructor-led Pulsar training developed by StreamNative Academy. This will get you started with Pulsar and accelerate your streaming immediately.
If you are interested in learning more about edge and building your own connectors, take a look at the following resources:
- My talk at Pulsar Summit EU 2021 - Using the FLiPN Stack for Edge AI (Flink, NiFi, Pulsar) (Get the slides here)
- Pulsar client libraries
- Example source
- InfluxDB Pulsar IO sink connector
- Java OAuth2 example for StreamNative Cloud login



