
Pulsar Functions is a turnkey serverless computing option native to the Pulsar messaging system. Popular use cases of Pulsar Functions include ETL jobs, real-time aggregation, microservices, reactive services, event routing, and more. Today, we are excited to introduce Function Mesh, a new feature that makes Pulsar Functions even more powerful.
Built as a Kubernetes controller, Function Mesh is a serverless framework that enables users to organize related Pulsar Functions/Connectors together to form a complex streaming job and run them natively on Kubernetes. It is a valuable tool for those who are seeking cloud-native, serverless event streaming solutions.
An Introduction to Pulsar Functions
Pulsar Functions is the native computing infrastructure of the Pulsar messaging system. It enables the creation of complex processing logic on a per message basis and brings simplicity and serverless concepts to event streaming, thereby eliminating the need to deploy a separate system such as Apache Spark or Apache Flink.
The lightweight compute functions consume messages from one or more Pulsar topics, apply user-supplied processing logic to each message, and publish computation results to a result topic. Some common use cases of Pulsar Functions include simple ETL jobs, real-time aggregation, microservices, reactive services, event routing, etc.
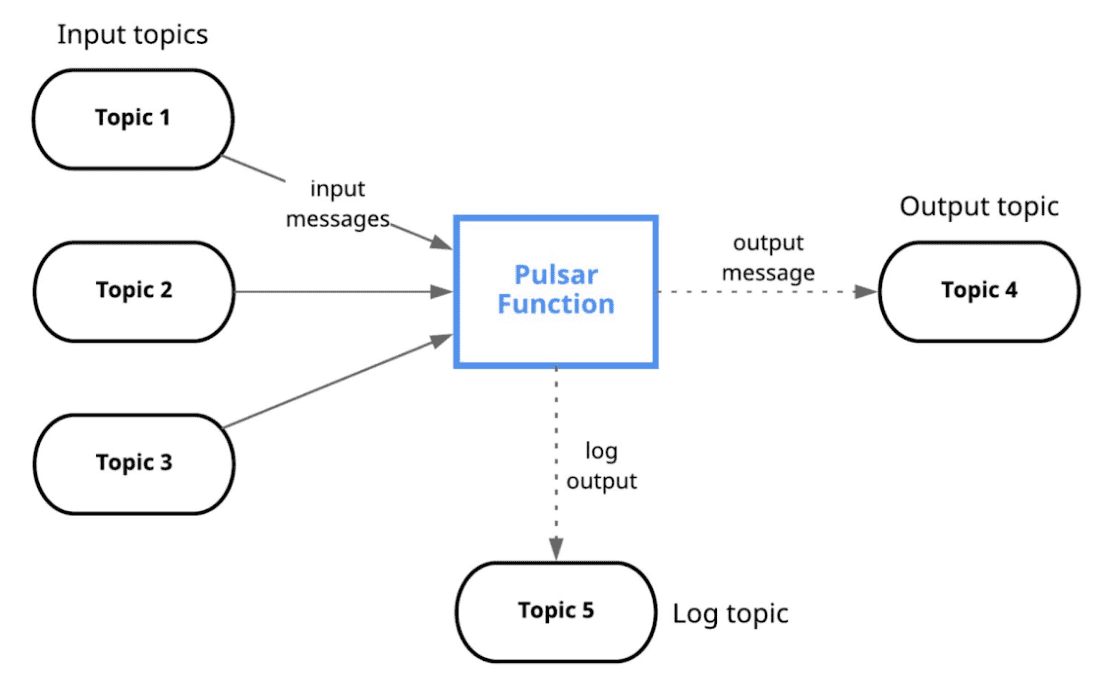
Pulsar Functions is not a full-power streaming processing engine nor a computation abstraction layer, rather, the benefits of Pulsar Functions are in its simplicity. Pulsar Functions supports multiple languages and developers do not need to learn new APIs, which increase development productivity. Using Pulsar Functions also means easier troubleshooting and maintenance because there is no need for an external processing system. For a deep dive on Pulsar Functions, read this article by Sanjeev Kulkarni, Sr. Principal Software Engineer at Splunk.
Why Do You Need Function Mesh
With the increased adoption of Pulsar Functions, we noticed that users would process data input in a stage-by-stage pattern by organizing several Pulsar Functions together.
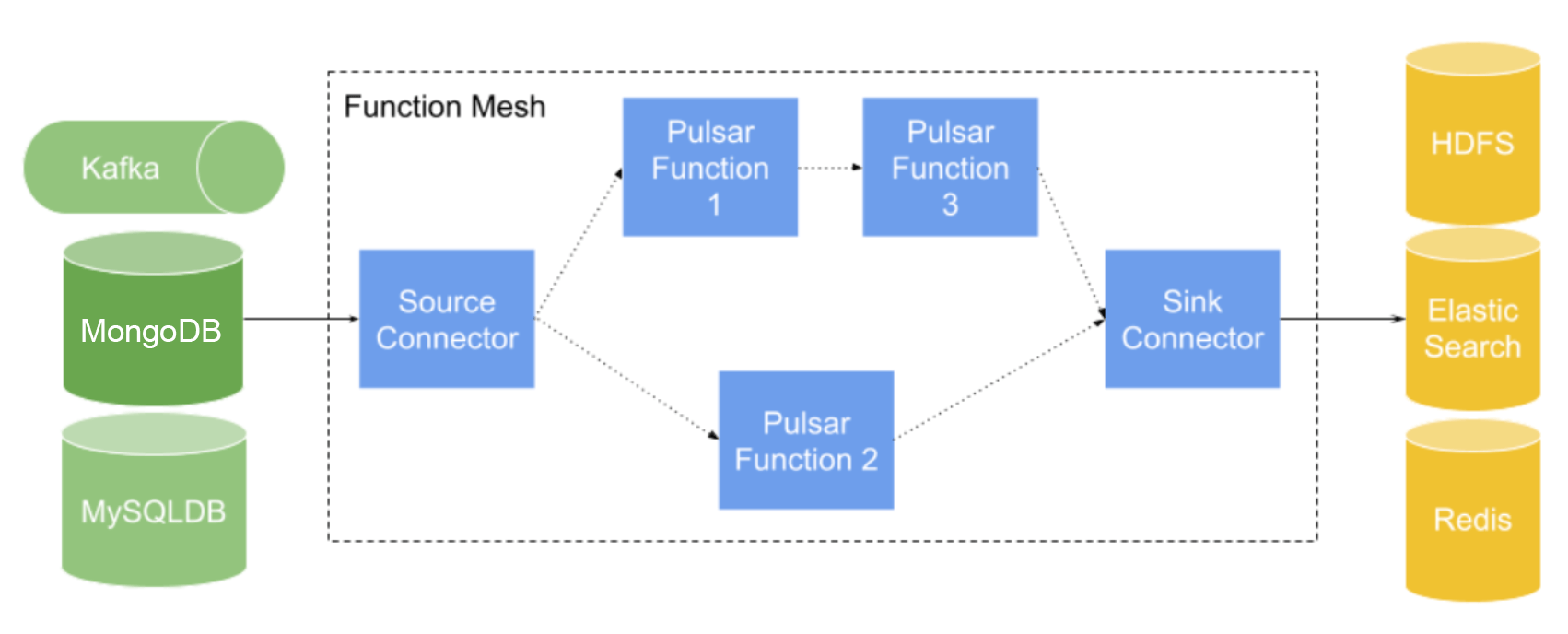
With this practice, developers had to deploy and manage each Pulsar Function individually, which is a time-consuming process. Take the framework above as an example, the owner would have to use five commands to deploy Pulsar Connectors and Pulsar Functions. Additionally, when multiple Pulsar Functions run concurrently, it is hard to track the functions since there is no aggregated view or linking among them. It is difficult to manage life cycles or know the upstream and downstream of functions.
To solve these pain points, StreamNative has created Function Mesh. Function Mesh allows people to manage functions as a unit and provides an integrated view of cooperating functions. With Function Mesh, Pulsar Functions owners can easily manage multi-stage jobs, saving substantial operational resources.
Like Pulsar Functions, Function Mesh is not a full-power streaming engine. The goal of Function Mesh is not to replace heavyweight streaming engines, such as Spark or Flink, but to use a simple API and execution framework for common lightweight streaming use cases.
Launch Function Mesh on Kubernetes
Since Kubernetes has become the standard platform for containerized applications, Function Mesh was built based on it to run Pulsar Functions in a cloud-native way. It comes with several CRD abstractions (Function, Source, Sink, FunctionMesh) to help users model the serverless computing tasks and a Kubernetes operator which reconciles the functions, connectors and meshes submitted by users. Instead of using Pulsar admin and sending function requests to Pulsar clusters, users can use kubectl to submit a Function Mesh CRD manifest directly to Kubernetes clusters. The corresponding Mesh operator installed inside Kubernetes will then launch parts individually, organize scheduling, and load balance the functions together.
$ kubectl apply -f function-mesh.yaml
apiVersion: cloud.streamnative.io/v1alpha1
kind: FunctionMesh
metadata:
name: functionmesh-sample
Spec:
sources:
- name: MangoDBSource
...
functions:
- name: f1
...
- name: f2
...
- name: f3
...
sinks:
- name: ElasticSearchSink
...
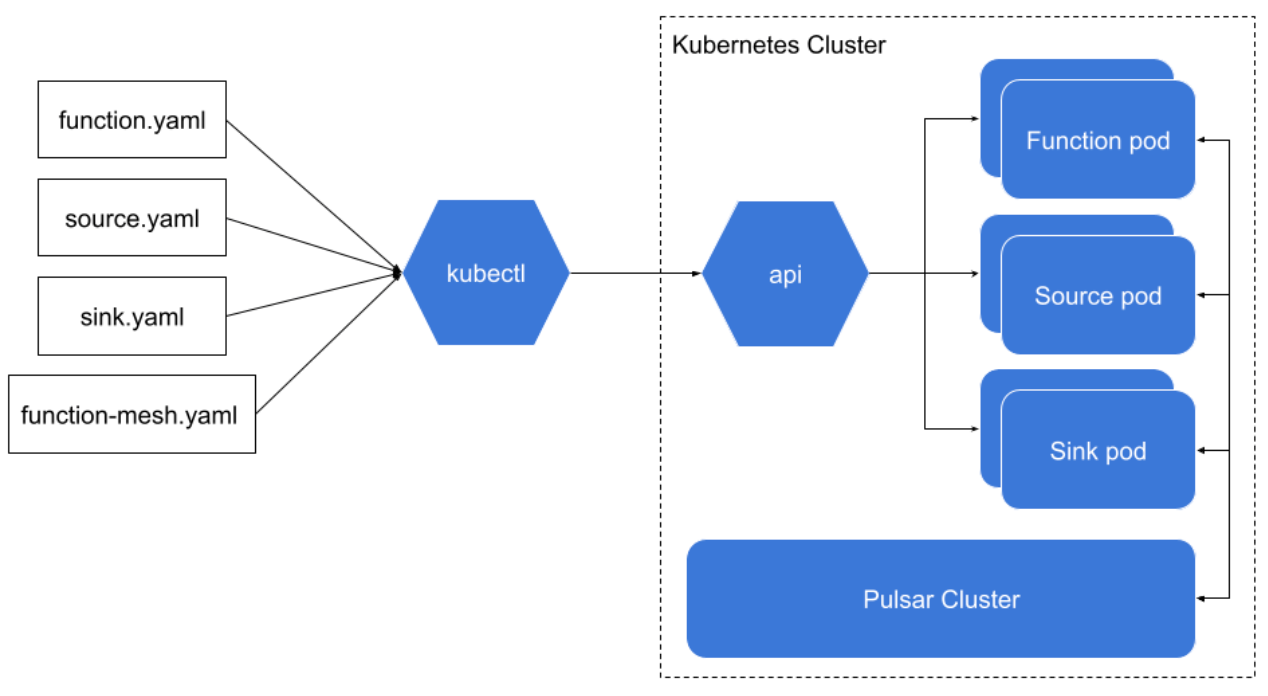
We implemented custom resources, including Function, Source, Sink, and FunctionMesh. These custom resources allow users to run Pulsar Functions and Connectors on Kubernetes with simplicity. With these Function Mesh CRDs, you can define your Function Mesh, organize the functions, and then submit it to Kubernetes. The diagram below illustrates the scheduling process.
The user provides CRD definitions for Pulsar Functions, Pulsar Connectors or Function Meshes. Once your Kubernetes cluster receives this CRD request, the Function Mesh operator will schedule individual parts and run the functions you desire as a stateful set.
For those who are seeking cloud-native, serverless streaming solutions, Function Mesh brings many benefits beyond making managing Pulsar Functions easier. The benefits of Function Mesh include:
- Allowing Pulsar Functions owners to utilize the full power of Kubernetes Scheduler, including rebalancing, rescheduling, fault-tolerance, etc. These features are crucial in production setups.
- It makes Pulsar Functions a first-class citizen in the cloud environment, which leads to greater possibilities when more resources become available in the cloud.
- Function Mesh runs Pulsar Functions separately from Pulsar, which enables it to work with different messaging systems and integrate with existing tools in the cloud environment.
Try Function Mesh Now!
Function Mesh is now available in private beta and we invite you to become one of the first users! Contact us to try Function Mesh on your Kubernetes clusters today.




