
Cloudera and StreamNative are pleased to announce they are open-sourcing an integration between Apache NiFi and Apache Pulsar. StreamNative was founded by the original creators of Apache Pulsar, and the team is excited to contribute this integration to the open source community. The Cloudera team includes some of the original developers of Apache NiFi and will make the connector available inside the Cloudera platform. Together, NiFi and Pulsar enable companies to create a cloud-native, scalable, real-time streaming data platform that can ingest, transform, and analyze massive amounts of data.
With this update, you will be able to consume and produce messages from Pulsar topics at scale with simple configuration settings within Apache NiFi. Cloudera makes these processors available out of the box for CDF for Data Hub7.2.14 and newer.
What is Apache NiFi?
Apache NiFi is based on technology previously called “Niagara Files” that was in development and used at scale within the National Security Agency (NSA) and was made available to the Apache Software Foundation through the NSA Technology Transfer Program.
NiFi is a visual tool that implements flow-based programming enabling you to construct data flows that move data from one technological platform (such as databases, cloud-storage, and messaging systems) to another.
NiFi automates the movement of data between disparate data sources and systems, making data ingestion fast, easy, and secure. It provides real-time control that makes it easy to manage the movement of data between any source and any destination. It also provides event-level data provenance and traceability, allowing you to trace every piece of data back to its origin.
The NiFi platform includes a collection of over 100 pre-built processors that can be used to perform enrichment, routing, and other transformations on the data as it flows from the source to destination.
What is Apache Pulsar?
Apache Pulsar is a cloud-native, distributed messaging and streaming platform originally created at Yahoo! and now a top-level Apache Software Foundation project. It is a distributed implementation of the publish-subscribe pattern designed to route messages from one end-point to another without data loss.
At its core, Pulsar uses a replicated distributed ledger to provide durable stream storage that can easily scale to retain petabytes of data. Pulsar’s scalable stream storage makes it a perfect long-term repository for event data. With Pulsar’s message retention policies, you can retain historical event data indefinitely. This allows you to perform streaming analytics on your event data at any point in the future.
Why Pulsar and NiFi?
Apache NiFi and Pulsar’s capabilities complement one another inside modern streaming data architectures. NiFi provides a dataflow solution that automates the flow of data between software systems. As such, it serves as a short-term buffer between data sources rather than a long-term repository of data.
Conversely, Pulsar was designed to act as a long-term repository of event data and provides strong integration with popular stream processing frameworks such as Flink and Spark. By combining these two technologies, you can create a powerful real-time data processing and analytics platform.
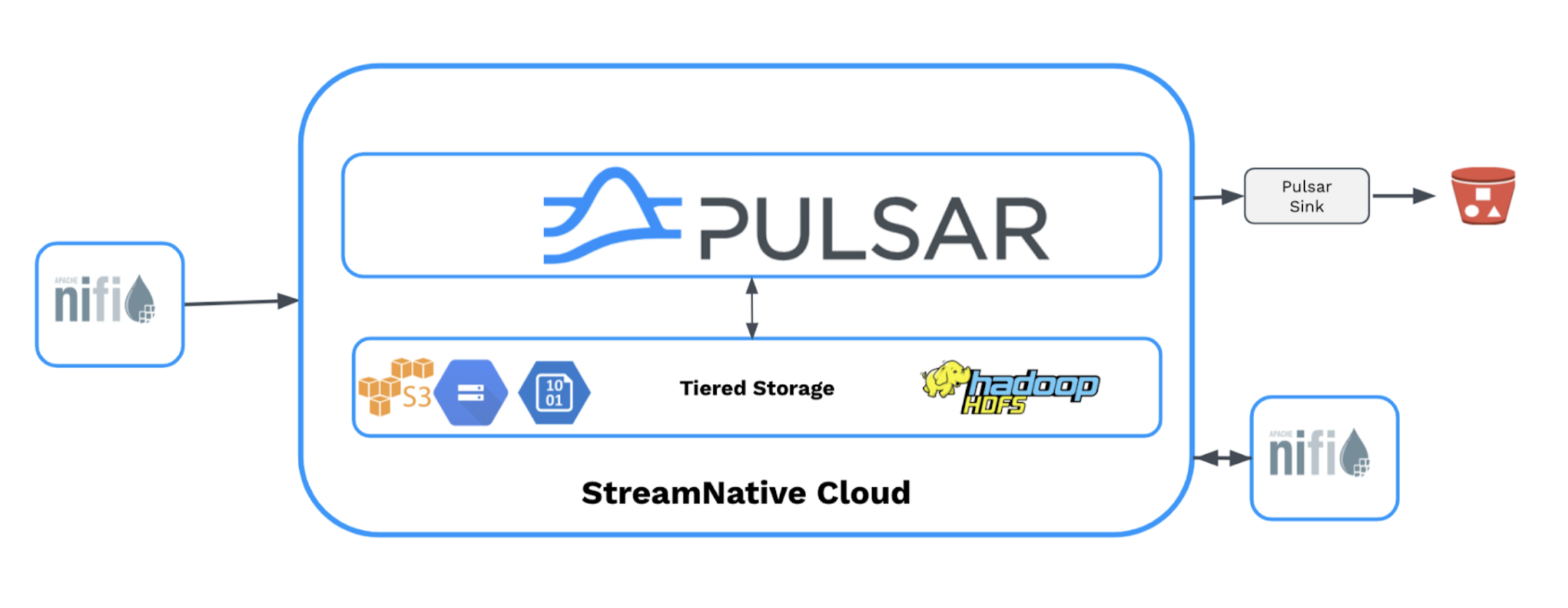
The synergies realized by combining these technologies inside your data platform will be significant. All of your dataflow management needs including prioritization, back pressure, and edge intelligence are provided by NiFi.
You can use NiFi’s extensive suite of connectors to automate the flow of data into your streaming platform while performing ETL processing along the way. After the data has been transformed, it can be routed directly to Pulsar’s durable stream storage for long-term retention via these new NiFi processors designed for Apache Pulsar.
Once the data has been stored inside Pulsar, it can be made readily available to various popular stream processing engines such as Flink or Spark, for more complex streaming processing and analytics use cases.
In short, NiFi’s extensive suite of connectors makes it easy to “get data in” to your streaming platform, and Pulsar’s integration with Flink and Spark makes it easy to get real-time insights out.
Combining these technologies together creates a complete edge-to-cloud data streaming platform that can be used to provide real-time insights across multiple application domains. For example, the ability to ingest and parse log data will be extremely useful in the cybersecurity industry, as you need to identify and detect threats as quickly as possible.
A wide range of industries such as manufacturing, mining, and oil & gas require the ability to ingest large amounts of IoT sensor data from a variety of locations. These high-volume datasets need to be analyzed in near real-time in order to prevent catastrophic equipment failures and/or prevent disruptions that could bring your operations to a screeching halt.
Within the financial services industry, the ability to ingest and process data in near-real time provides a clear competitive advantage in time-sensitive applications such as algorithmic trading or cryptocurrency arbitrage.
Demo
Without further ado, let’s take a look at these new NiFi processors in action. In this video, I walk through the process of configuring and using these processors to send data to and receive data from an Apache Pulsar cluster.
As you can see from the video demonstration, there are a total of four Processors: two for publishing data to Pulsar, PublishPulsar and PublishPulsarRecord; and two for consuming data from Pulsar, ConsumePulsar and ConsumePulsarRecord. There are also two controller services included in the bundle as well. One is used for creating Pulsar clients, and another for authentication to secure Pulsar clusters.
Availability
These processors will be available starting with version 7.2.14 of CDF on the Public Cloud. If you wish to use these processors in other Apache NiFi clusters, you may download the artifacts directly from the maven central repository, or you can build them directly from the source code.
What’s Next?
- Learn more about the Apache NiFi and Apache Pulsar Connector here.
- Get your own free Pulsar cluster by signing up for StreamNative Cloud.
- Join Tim Spann, (Developer Advocate, StreamNative) and John Kuchmek, (Principal Solutions Engineer, Cloudera) for the upcoming Meetup: "Apache Pulsar and Apache NiFi for Cloud Data Lakes" on Thursday, March 10th at 3 PM PST / 6 PM EST.
- You can also review some talks to get a better understanding of the types of use cases that can be solved by combining these two open-source technologies.
- Devfest UK & Ireland
- ApacheCon 2021
- Using the FLiPN Stack for Edge AI
- DevNet Create 2021
- Download some demo code and try it out for yourself.
- Producing and Consuming Pulsar messages with Apache NiFi
- FLiP-Transit GitHub Repo
- Awesome Apache NiFi + Apache Pulsar GitHub Repo
- FLiPN-Demos GitHub Repo



