
Partitioning in stream processing: “what does it do, and why is it not what I thought it was?”
Partitioning has been strongly associated with stream processing from the beginning. At the start, Kafka changed the industry by introducing distributed logs as a groundbreaking way to solve the major challenges of ingesting large volumes of server logs into a single platform. The idea of separating out and distributing a single log file solved the problem of providing horizontally scalable storage, which is essential to sustainably streaming data. However, the choice to use partitions to implement this structure comes with drawbacks. The implementation has been exposed to the end user in a way that has made partitioning become synonymous with event streaming - it has become the default for many users in stream processing.
Unfortunately, the pain points that come with it have also become the norm for many use cases. However, different stream processing engines handle partitioning - and alternatives to partitioning - very differently. This article covers what is often misunderstood about partitioning, how it relates to steam processing (or does it?), and what alternatives are available.
Overview
Partitioning, and related concepts like logs, have been around for a long time in software engineering and are prevalent in other industries as well. This can make for a nice foundation for understanding how these concepts fit into stream processing. However, it can also be confusing when, even within the data streaming world, these concepts function very differently depending on the technology implementing them.
Even for concepts like stream processing itself, the definitions can vary widely, so following is a brief overview of how we will be using these concepts.
Logs
Many of you will already be familiar with logs as a very basic data structure used across the software industry. Since logs are automatically and instantly instantiated, they are a highly reliable source of truth for a variety of functions. They are an essential component for analytics and testing, where the log acts as a record for any errors, anomalies, or configured alerts. Logs are also a core foundation for databases which rely on a changelog structure to track and record any modifications performed on their tables. On the most basic level, logs are an append-only sequence of inserted data, ordered by time. Logs can contain any data type.

Rebalancing can be risky.
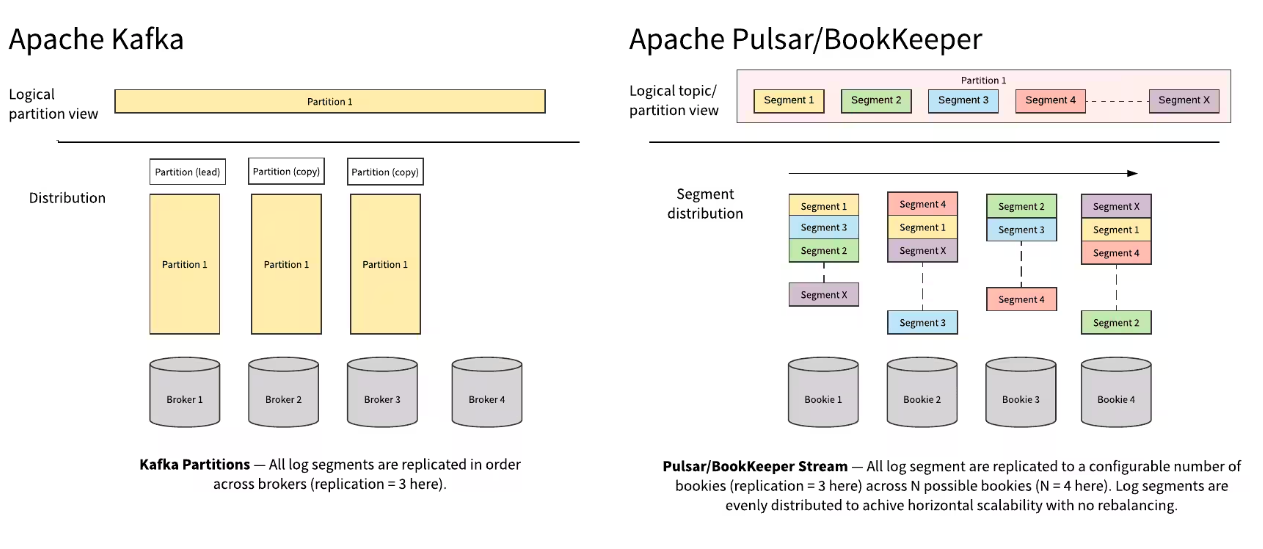
This has become the “norm” for many stream processing users, and it comes with some pain points that may be very familiar to you if you have experience in these technologies. Partitioning this way means the topics can’t accept more data than this fixed amount. This means that to scale the application at all, the number of partitions must be increased.
Unfortunately, this creates a dilemma where higher numbers of partitions can get very expensive, and increasing the number of partitions requires rebalancing. Rebalancing is required anytime partitions are increased because Kafka utilizes a hash key system for partitioning, where data placement is coupled to the hash key. A new partition being added means that the process essentially has to start all over again: all of the data will need to be reallocated across the new number of partitions. This also means that new data cannot continue to flow through the topics during the rebalancing.
Consider a typical process of building a new product or application within your company. In other technologies that implement partitions, the user would have to anticipate the number of partitions needed before the application can even be used- you can’t send data through a topic without having already established the number of partitions. It may be a while before the project needs to scale up at all, meaning that an expensive amount of storage could be reserved and not even used for a considerable amount of time, and many companies may not want to invest in this expense without a return on investment in sight. The only other option that the user has is to save on initial storage cost by setting a lower number of partitions. However, if the application needs to scale in the future (which is usually the goal for most stream processing applications), rebalancing is required, and this process comes with its own expenses, as well as risks as outlined above.
It is often overlooked that partitioning is also not inherently a streaming pattern. Users have had to predetermine the number of partitions from the very introduction of stream processing, making it the standard and expected experience. This strong association between partitioning and streaming leads to the impression that the two are intertwined. However, this is not the case: partitioning is simply an implementation detail of Kafka itself. Moreover, the fact that this internal detail is exposed to the end user violates basic OOP interface design principles, specifically of the implementation being able to be changed at a later point without breaking the API.
Segmentation: The Scalable Alternative
What is it?
Similar to partitioning, segmentation takes a single log and breaks it down into a sequence of smaller pieces. These pieces, or segments, are distributed across nodes that all reside within a separate storage layer. By default, there are 50k records per segment when the segments are instantiated, but this number is also configurable.
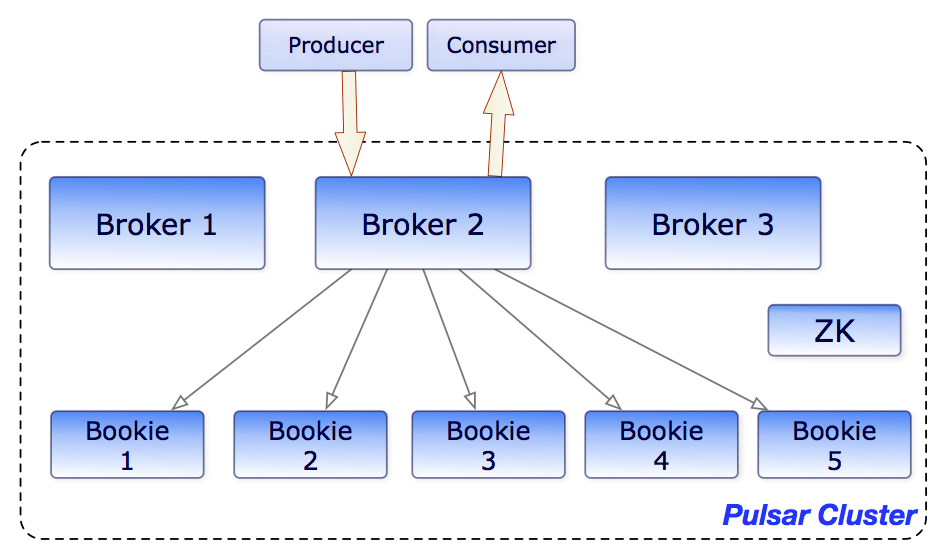
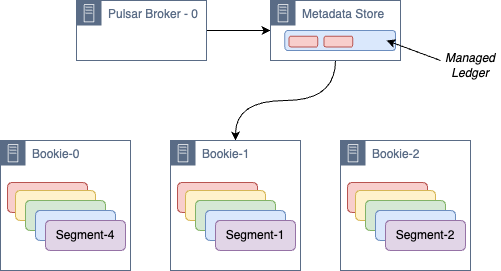
A whole segment is stored on a single bookie. And, in order to ensure proper redundancy, Apache Pulsar, by default, creates several replicas of each segment. Moreover, these segments can be stored anywhere within this layer where storage is available. By comparison, in Kafka, partitions are stored on a specific broker within the cluster, which is very limiting. The only potential downside here would be tracking where all the segments are stored, but Apache Pulsar already automatically creates a metadata store that contains a record of segments in a topic.
How is this useful?
Utilizing the storage in this way allows any individual log the same storage availability of however many machines that its segments are stored across, making it truly horizontally scalable. Additionally, the number of nodes can be dynamically increased within this separate storage layer, thus making it easy to scale up the overall storage capacity. All that is required is to increase the number of bookies, and new segments will automatically be written to the newly created bookies.
As we covered earlier, in Kafka, this same action would have required the costly and risky act of rebalancing. The fact that each segment is stored on separate bookie brings even more of a contrast between Apache Pulsar vs Kafka. In Apache Pulsar, if a bookie goes down or incurs any issues, there is no impact on the rest of the system. However with Kafka, since brokers are shared between partitions, if there is an error with one partition, it could easily impact other topics that share that resource.
In Pulsar, the storage and computing layers are already separated, which naturally eliminates the need to rebalance the data. This creates a drastic difference in storage requirements and performance by eliminating most of the storage issues while maintaining resilient failover. Apache Pulsar’s architecture already decouples the layer serving the messages from the storage layer, which “allows each to scale independently” (Kjerrumgaard, “Apache Pulsar in Action”). This contrasts with technologies like Kafka, where the serving and storage layers occur on the same instances or cluster nodes.
Additionally, the integration of Apache BookKeeper provides persistent message storage. Apache BookKeeper creates segments, converting and storing data streams into sequential logs. Each segment contains multiple logs distributed among multiple “Bookies” (BookKeeper nodes). These segments are all contained within the storage layer, and thus provide extra redundancy. They can also reside anywhere within this layer where there is sufficient storage capacity. Because of this and since there is not the same cost to increasing the number of segments, horizontal scalability is inherently possible.
Structuring the architecture in this way is what enables segmentation to be a true stream processing pattern. The storage is truly horizontally scalable, and all of this management and configuration can be done dynamically, with no limitations, slowdowns or pauses to the stream of data.
Conclusion
Is partitioning a feature or a bug? The answer to this is that it is not a true stream processing concept. So, it may not be a bug in other contexts, however, there are alternatives out there that are better suited for stream processing.
Where partitioning is hindered by a rigid, predetermined number of partitions and therefore amount (and cost) of available storage, segmentation provides a dynamic option with true horizontal scaling. In contrast, segmentation also offers the best of both worlds -reliability and efficiency. Segmentation automatically creates replication where needed and guaranteed reads, while also providing a highly performant read/write process and capacity for low latency and high throughput. And then there’s the user experience - no rebalancing required! Not only does this add to the lowered risk and cost of this method, but it eliminates many of the pain points that have often become expected with the development process of stream processing.
Want to Learn More?
For more on Pulsar, check out the resources below.
- Learn more about how leading organizations are using Pulsar by checking out the latest Pulsar success stories.
- Use StreamNative Cloud to spin up a Pulsar cluster in minutes. Get started today.
- Engage with the Pulsar community by joining the Pulsar Slack channel.
- Expand your Pulsar knowledge today with free, on-demand courses and live training from StreamNative Academy.




