
Apache Pulsar™, like all messaging systems, imposes a size limit on each message sent to the broker. This prevents the payload of each message from exceeding the maxMessageSize set in the broker. The default value of the broker configuration maxMessageSize is 5 MB.
However, many users need the Pulsar client to send large messages to the broker for use cases such as image processing and audio processing. You can achieve this by adjusting the maxMessageSize; however, this approach can cause many problems. For example, if a client publishes a message of 100 MB and the broker allows storing this message into the bookie, then the bookie will spend too many resources on processing this message. This will impact other clients on publishing and cause backlog draining.
Therefore, instead of increasing the value of maxMessageSize, Pulsar provides a message chunking feature to enable sending large messages. With message chunking, the producer can split a large message into multiple chunks based on maxMessageSize and send each chunk to the broker as an ordinary message. The consumer then combines the chunks back to the original message.
In this blog, we will explain the concept of message chunking, deep dive into its implementation, and share best practices for this feature, including:
- How to use message chunking correctly.
- Issues you may encounter when using chunk messages.
- How to debug chunked messages.
How Message Chunking Works
Message chunking is a process by which a large message can be split into multiple chunks for production and consumption. When using message chunking, you don’t need to worry about how Pulsar splits large messages and combines them or the detail of handling chunked messages. Pulsar does all of these things for you. In this section, let's look at how message chunking works in different scenarios.
A single producer publishes chunked messages to a topic

Publishing Chunked Messages
Once the large message is split into chunks, the producer sends each chunk as an ordinary message to the broker. Each chunk is still subject to the flow control of the producer and the memory limiter of the client as if it were an ordinary message. There is a maxPendingMessages parameter in the producer configuration that limits the maximum number of messages the producer can publish concurrently. Each chunk is counted individually in maxPendingMessages. This means that sending a large message with three chunks will take up three messages in the producer for the pending message.
When sending each chunk, an individual OpSendMsg is created for each chunk. Each OpSendMsg shares the same ChunkMessageCtx that is used to return the chunked message ID to the user. Each chunk also shares the same uuid of the chunked message in its message metadata.
The producer sends each chunk to the broker in order, and the broker receives the chunks in order. This ensures that the entire chunked message is sent successfully when the publishing acknowledgment of the last chunk is received. This also ensures that all of the chunks of a chunked message are stored in the topic in order. The consumer relies on this ordering guarantee to consume the chunks in order.
Regarding a partitioned topic, the producer publishes all of the chunks of the same large message to the same partition.
Chunked Message ID
In Pulsar, after an ordinary message is published or consumed, its message ID is returned to the user. For chunked messages, how does Pulsar return the message ID to the user?
Before Pulsar 2.10.0
Before Pulsar 2.10.0, the producer or consumer only returns the message ID of the last chunk as the message ID of the entire chunked message. This implementation sometimes raises issues. For example, when we use this message ID to seek, the consumer will consume from the position of the last chunk. The consumer will mistakenly think the previous chunks are lost and choose to skip the current message. If we use inclusive seek, the consumer may skip the first message, which causes unexpected behavior.
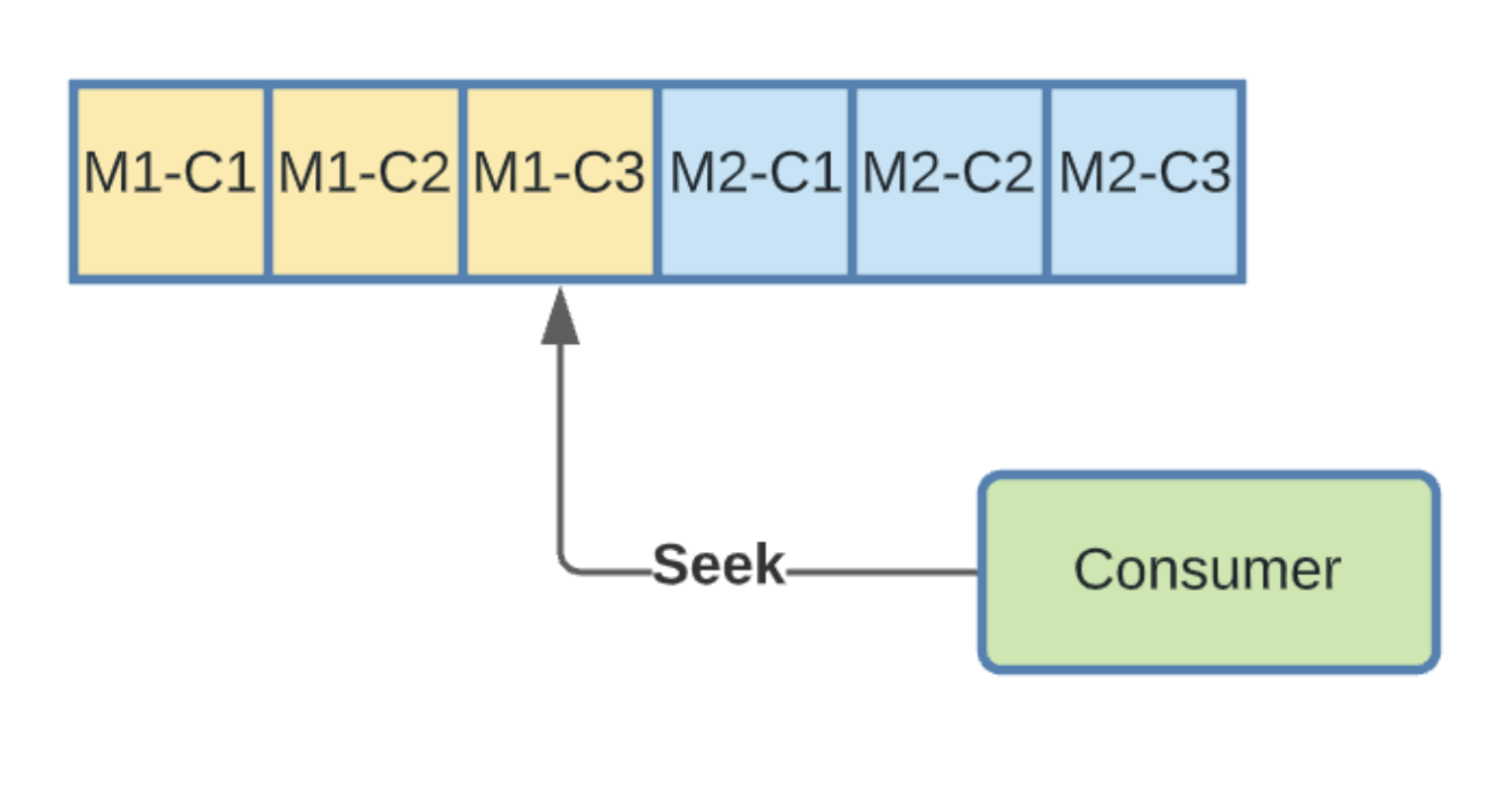
As shown in the image above, the consumer returns the message of the last chunk as the message ID of the chunked message to the user. If the consumer uses this message ID to do an inclusive seek, in the broker's view, the consumer is seeking M1-C3. According to the semantics of inclusive seek, the first message consumed by the consumer after performing an inclusive seek should be the message of the current seek position. So the first message to be consumed by the consumer after the seek is supposed to be message M1. But in fact, the first message that comes to the consumer is M1-C3. The consumer then discovers that it has not received the previous chunks of that chunked message and cannot continue to receive the previous chunks, so it will discard M1. Therefore, the first message consumed is actually M2. This is an unexpected behavior.
Introducing Chunk Message ID in Pulsar 2.10.0
To solve this issue, Pulsar introduced the feature of chunk message ID in version 2.10.0. Issue PIP 107 details the proposal of this feature. The chunk message ID is consistent with the original behavior to achieve compatibility with the original logic. It contains two ordinary message IDs: the message ID of the first chunk and the one of the last chunk. Both the producer and the consumer use chunked message context to generate the chunked message ID.
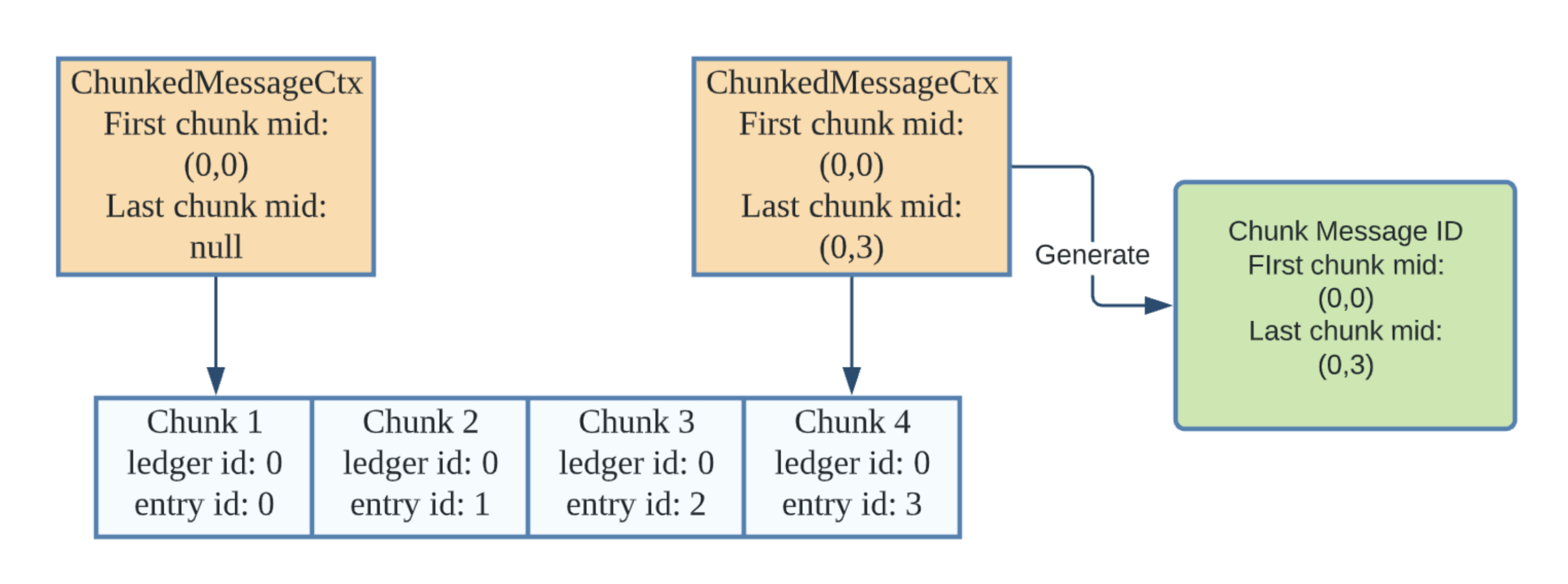 As shown in the figure above, the producer gets the message ID of the first chunk (corresponding to “first chunk mid”) and the message ID of the last chunk while receiving the publishing acknowledgment of each chunk. The producer buffers them in the chunked message context and generates the chunk message ID after receiving the last chunked message ID. The same is true for the consumer. The difference is that the consumer gets the message ID by receiving the message.
As shown in the figure above, the producer gets the message ID of the first chunk (corresponding to “first chunk mid”) and the message ID of the last chunk while receiving the publishing acknowledgment of each chunk. The producer buffers them in the chunked message context and generates the chunk message ID after receiving the last chunked message ID. The same is true for the consumer. The difference is that the consumer gets the message ID by receiving the message.
The chunk message ID feature not only fixes the issues caused by seeking, but also allows you to get more information about the chunked message.
Combining Chunks
The consumer needs to combine all of the chunks into the original message before returning it to the application. The consumer uses the chunked message context to buffer all the chunk data, such as payload, metadata, and message ID. When processing chunked messages, the consumer assumes that the chunks are received in order and will discard the whole chunked message if the received chunks are out of order.
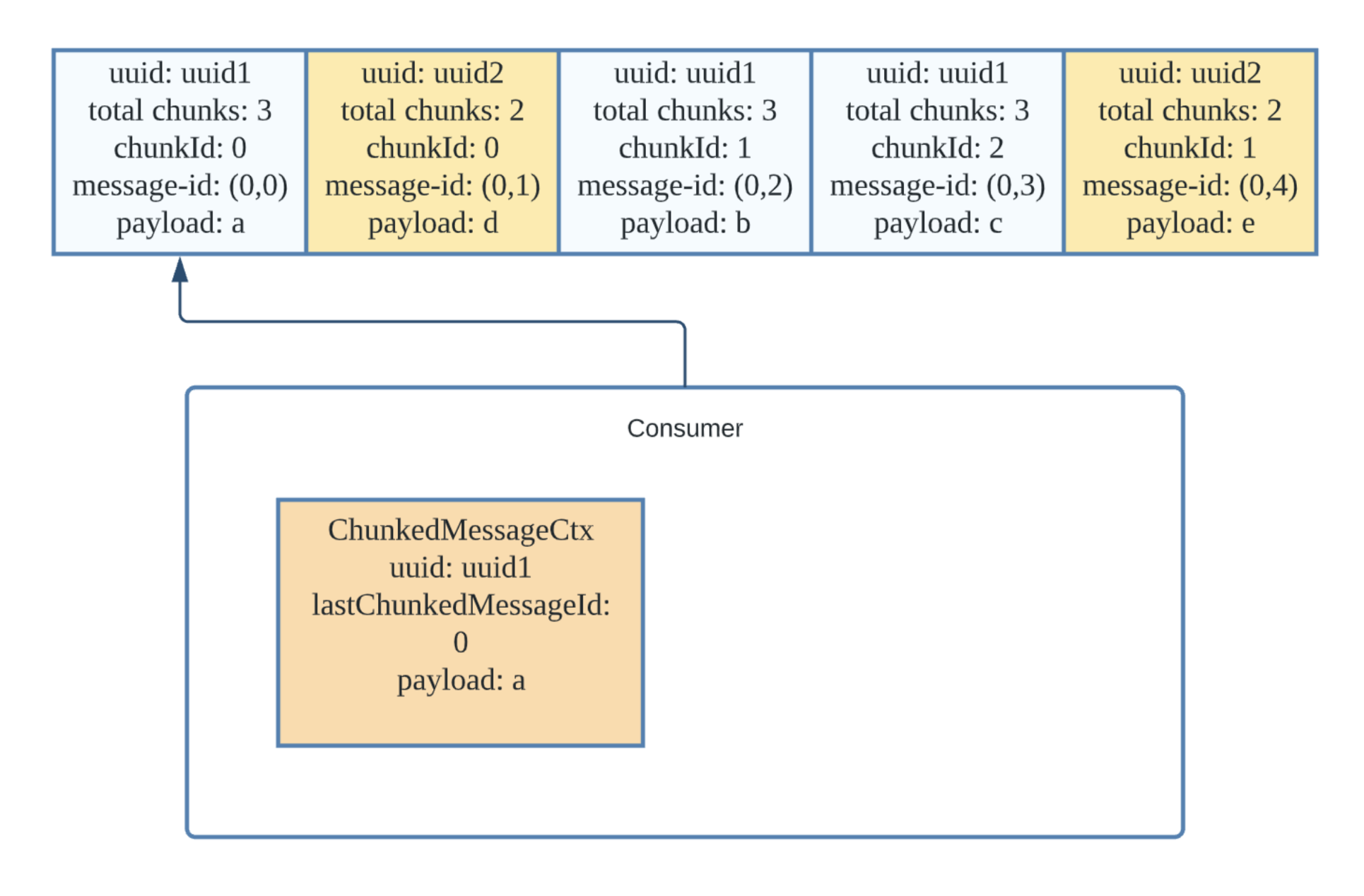 Suppose we have published two large messages, “abc” and “de,” as shown in the image above. They are waiting to be consumed on the topic. The maxMessageSize for the broker is set too small (just 1 byte), resulting in a small payload size in every chunk.
Suppose we have published two large messages, “abc” and “de,” as shown in the image above. They are waiting to be consumed on the topic. The maxMessageSize for the broker is set too small (just 1 byte), resulting in a small payload size in every chunk.
When the consumer consumes the first message, it finds the message to be a chunked message and creates a ChunkedMessageCtx. (We did not list all of the fields in the chunked message context in the example above.) The uuid uniquely identifies the chunked message so that we can know in which context the chunk should be placed. The lastChunkedMessageId in the context means the chunked ID of the last received chunk. It will be updated whenever the consumer receives a new chunk. The payload of the context is the payload of the entire chunked message currently buffered. It will keep growing as the consumer receives more chunks.
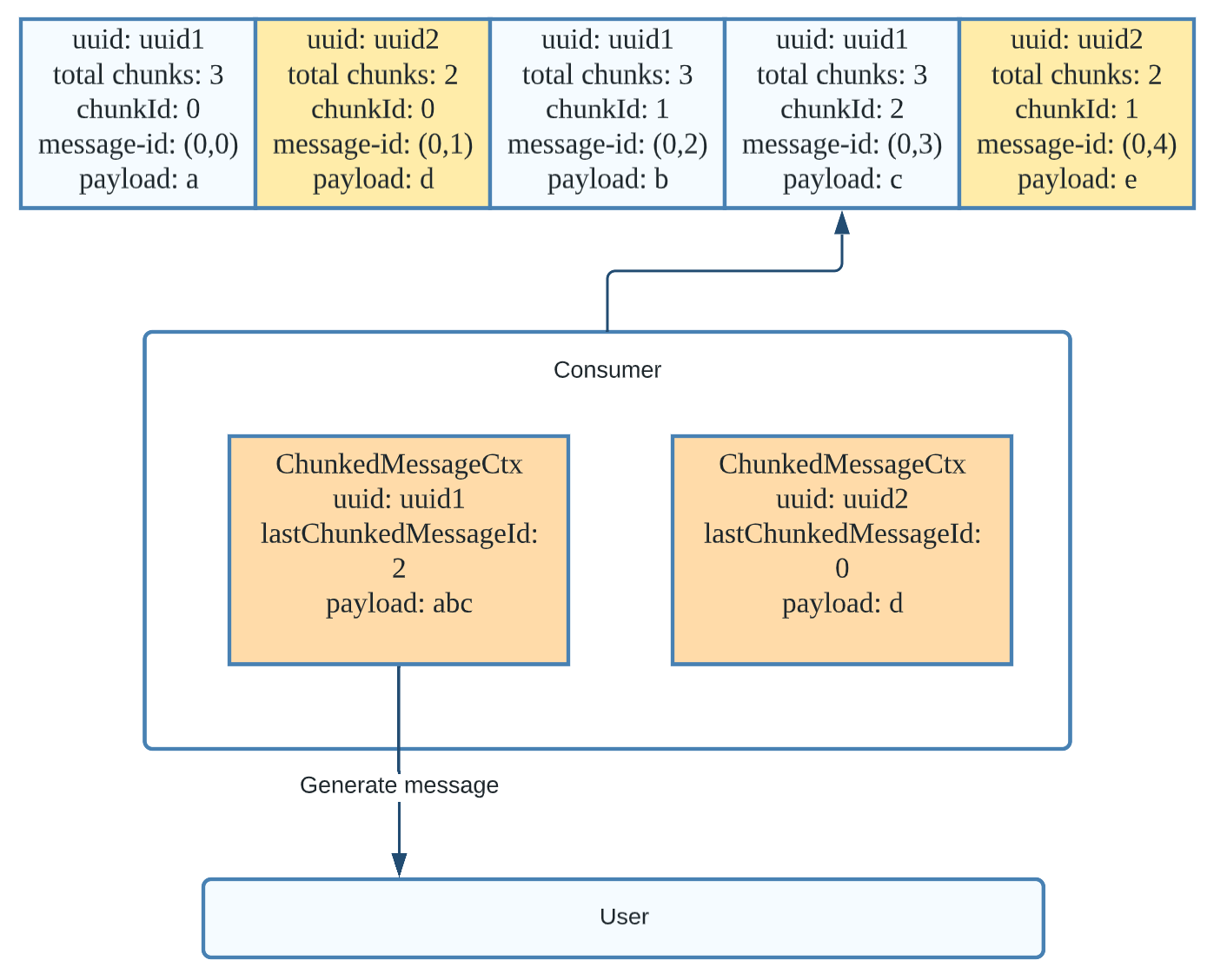 Once the consumer receives all the chunks of the message with the uuid of uuid1, it can use the chunked message context to generate the original message. The complete message is then returned to the application and the consumer releases that context. Note that because we have received a chunk of message uuid2 during this process, a second chunked message context is created in the consumer.
Once the consumer receives all the chunks of the message with the uuid of uuid1, it can use the chunked message context to generate the original message. The complete message is then returned to the application and the consumer releases that context. Note that because we have received a chunk of message uuid2 during this process, a second chunked message context is created in the consumer.
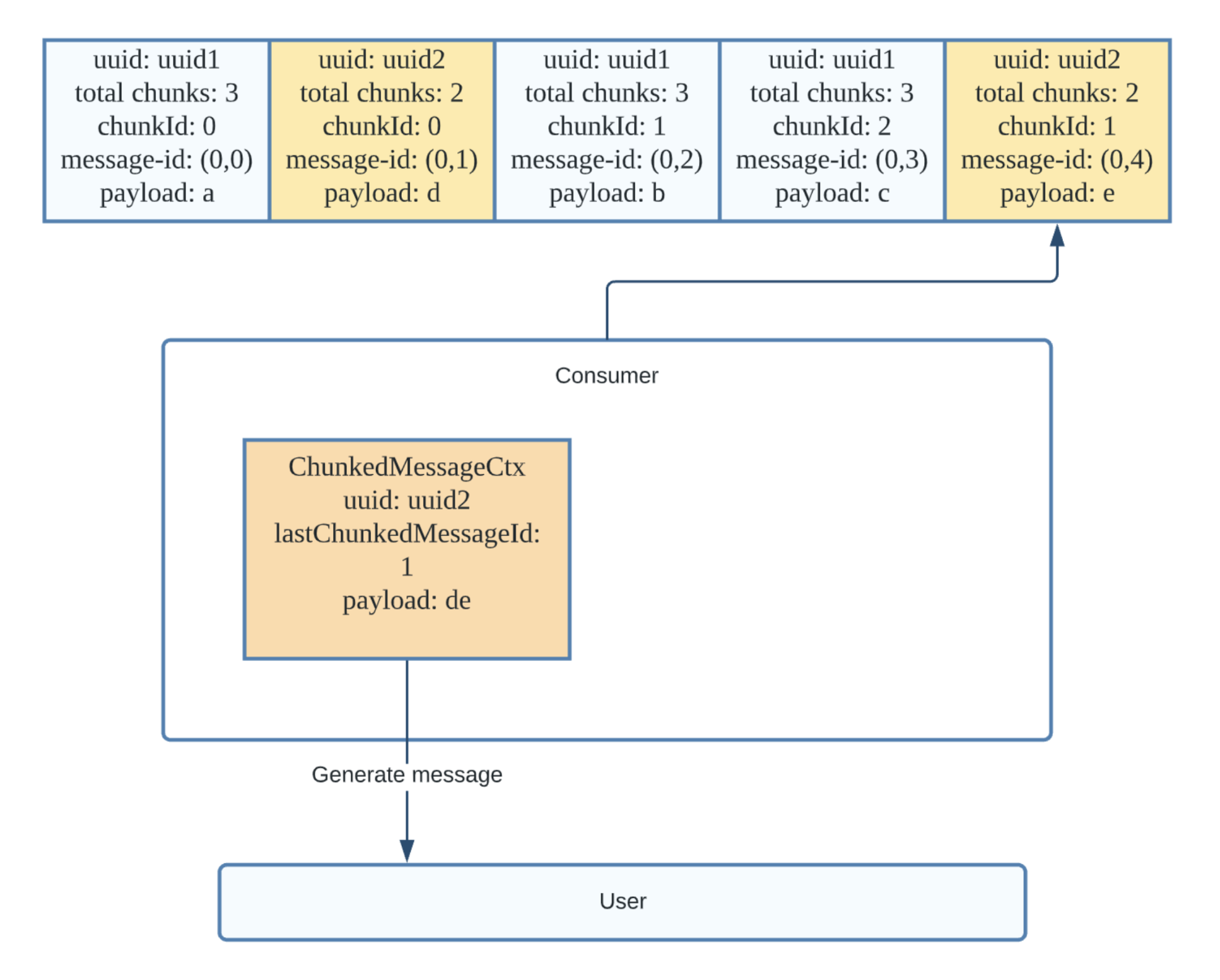 Just like the previous example, when the consumer receives all of the chunks of uuid2, it generates a new message from the chunked message context and returns the complete message to the application.
Just like the previous example, when the consumer receives all of the chunks of uuid2, it generates a new message from the chunked message context and returns the complete message to the application.
Best Practices for Message Chunking
In this section, we share some best practices for using message chunking.
Don’t use large message metadata
It is not recommended to set very large message metadata in chunked messages. The producer often publishes chunks with the maximum payload size. In the process of writing a chunk to a bookie, if the header part (which includes the message metadata) of the chunk exceeds 10 KB (the padding max frame size for a bookie), there will be an error.
The maxMessageSize limits the size of the payload for each message from the client to the broker, but it doesn't count the size of the header. In BookKeeper, there is a similar setting called nettyMaxFrameSizeBytes that limits the size of writing to each message. Any message sent to the BookKeeper larger than nettyMaxFrameSizeBytes will be rejected. In BookKeeper, the message size calculation includes the message header and payload. There are differences in the way the BookKeeper and the broker calculate maxMessageSize. As a result, the broker will reserve some padding size for the message's header, and the value is 10 KB (which is defined in Commands.MESSAGE_SIZE_FRAME_PADDING). The broker will set nettyMaxFrameSizeBytes to maxMessageSize plus 10 KB when establishing a connection with the BookKeeper.
For this reason, you need to ensure the size of the message header does not exceed 10 KB when sending large messages. You should also not exceed this limit when setting values of the key and other properties of large messages. There has been a new proposal to lift this limitation by including the header part on the client-side when splitting the message.
Topic level maxMessageSize restriction
It is not recommended to set the topic level maxMessageSize for a topic if you want to publish chunked messages to that topic.
The topic level maxMessageSize was introduced in Pulsar 2.7.1, and it can cause some problems when message chunking is enabled. As mentioned above, the chunked message splitting uses broker level maxMessageSize as the chunk size. In most use cases, the topic level maxMessageSize is always less or equal to the broker level maxMessageSize. In this case, publishing a chunked message will be rejected by the broker. Because the payload size of some chunks in this message will reach the broker level maxMessageSize and exceed topic level maxMessageSize, causing the broker to reject it. In addition, the broker calculates the header and payload together when checking whether the message exceeds the topic level maxMessageSize. Therefore, when we use the chunked message feature, you should be careful not to set the topic level maxMessageSize on that topic.
A fix to this known issue has been released in Pulsar 2.10. The topic level maxMessageSize check for chunked messages is removed. Upgrade your Pulsar version to 2.10 to get this fix. Read PIP-131 to learn more.
Best practices for the consumer
You can use maxPendingChunkedMessage, expireTimeOfIncompleteChunkedMessage, and autoAckOldestChunkedMessageOnQueueFull in the consumer configuration to control the memory used in the consumer for chunked messages.
The chunked message contexts are buffered in the client’s memory. As the consumer creates more context, it may take up too much memory and lead to an out-of-memory error. Therefore, Pulsar introduced maxPendingChunkedMessage in the consumer configuration. It limits the maximum number of chunked message contexts that a consumer can maintain concurrently.
In addition, you can also set the expiration time of the chunked message context by setting the expireTimeOfIncompleteChunkedMessage in the consumer configuration. If the producer fails to publish all of the chunks of a message, resulting in the consumer unable to receive all of the chunks with the expiration time, the consumer will then expire incomplete chunks. The default value is one minute.
You can also delete the oldest context when the maximum number of pending chunked messages has reached the context is expired using a setting called autoAckOldestChunkedMessageOnQueueFull. If the setting is set to true, the consumer will drop the chunked message context that you want to delete by silently acknowledging it; if not, the consumer will mark the message for redelivery.
Below is an example of how to configure message chunking on the consumer.
Consumer consumer = client.newConsumer()
.topic(topic)
.subscriptionName("test")
.autoAckOldestChunkedMessageOnQueueFull(true)
.maxPendingChunkedMessage(100)
.expireTimeOfIncompleteChunkedMessage(10, TimeUnit.MINUTES)
.subscribe();
It is also not recommended to publish chunked messages that are too large as it can lead to high memory usage on the consumer side. Although the consumer can limit the number of chunked messages that can be buffered at the same time, there is no easy way to control the amount of memory used by buffered chunked messages.
Best practices for debugging
In the broker, you can debug message chunking by checking certain stats in a topic. Below are three commonly used ones:
- msgChunkPublished: A boolean type. It shows whether this topic has a chunked message published on it.
- chunkedMessageRate in publishers: It shows the total count of chunked messages received for this producer on this topic.
- chunkedMessageRate in subscriptions and consumers: It tells you the chunked message dispatch rate in the subscription or the consumer.
Read Manage Topics in the Pulsar documentation to learn more.
Upgrade your Pulsar version
It’s best to keep your Pulsar version up to date as the Pulsar community continues to optimize message chunking. We recommend updating your Pulsar version to 2.10 or later. There are important bug fixes for message chunking, such as fixing memory leak with the flow control of chunked messages and fixing the issue with seeking chunked messages.
More Resources
If you have any better ideas or encounter any issues when using message chunking, please feel free to create an issue in the Pulsar repo.
You can find more details about the message chunking implementation in the following links:
- PIP 37: Large message size handling in Pulsar
- PR: PIP 37: Pulsar-client support large message size
- PIP 107: Introduce the chunk message ID
- PR: [PIP 107]Client Introduce chunk message ID




