
The lifecycle of topic data in Apache Pulsar is managed by two key retention policies: the topic retention policy on the broker side, and the bookie data retention policy on the bookie side. All the data deletion operations can only be triggered by the broker. We shouldn’t delete ledger files from bookies directly. Otherwise, the data will be lost.
This blog focuses on the following three topics in Pulsar:
- Topic retention policy. We will mainly discuss the cases where the retention policy doesn’t work. For more information about retention and expiry strategies, see Message retention and expiry.
- Bookie data compaction policy.
- How to detect and deal with orphan ledgers to fix bookie ledger files that can’t be deleted.
Overview: Topic data lifecycle
In Pulsar, when a producer publishes messages on a topic, these data are written to specific ledgers managed by ManagedLedger, which is owned by the Pulsar broker. The metadata is stored in Pulsar’s meta store, such as Apache ZooKeeper. Ledgers are written to specific bookies according to the replica policies configured (i.e. the values of E, WQ, and AQ). For each ledger, its metadata is stored in BookKeeper’s meta store, such as Apache ZooKeeper.
When a ledger (for example, Ledger 3 in Figure 1) needs to be deleted according to the configured retention policy, it goes through the following steps.
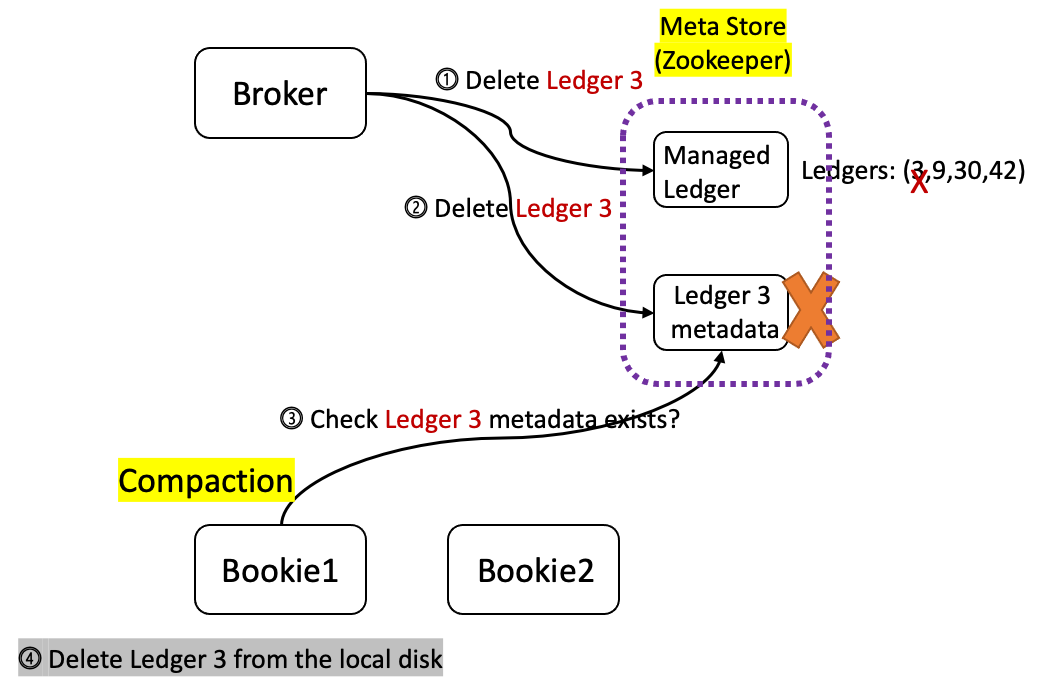
- Delete Ledger 3 from the ManagedLedger’s ledger list in the meta store.
- If the first step succeeds, the broker will send the deletion request of Ledger 3 to the BookKeeper cluster asynchronously. However, this does not ensure the ledger can be deleted successfully. The risk of leaving Ledger 3 an orphan ledger in the BookKeeper cluster still exists. For more information about how to solve this problem, see this proposal.
- Each bookie performs a regular compaction check, which is configured through minorCompactionInterval and majorCompactionInterval.
- In the compaction check, the bookie checks whether the metadata of each ledger exists in the meta store. If not, the bookie will delete the data of this ledger from the log file.
From the last two steps above, we can see that the deletion of topic data, which are stored in BookKeeper, is triggered by the compaction checker, not by the Pulsar broker. This means that the ledger data are not deleted immediately when the ledger is removed from the ManagedLedger’s ledger list.
Topic retention policy
In this section, we will briefly talk about topic retention policies in Pulsar, and focus on the drawbacks of current ledger deletion logic as well as the cases where retention policies don't work.
Topic retention and TTL
When messages arrive at a broker, they are stored until they have been acknowledged on all subscriptions, at which point it is marked for deletion. You can control this behavior and retain messages that have already been acknowledged on all subscriptions by setting a retention policy for all topics in a given namespace. If messages are not acknowledged, Pulsar stores them forever by default, which can lead to heavy disk space usage. This is where TTL (Time to live) can be useful as it determines how long unacknowledged messages will be retained. For more information, see Message retention and expiry.
Drawbacks of the current ledger deletion logic
The current logic entails two separate steps to delete a ledger.
- Remove all the ledgers to be deleted from the ledger list and update the newest ledger list in the meta store.
- In the meta store update callback operation, remove the ledgers to be deleted from storage asynchronously, such as BookKeeper or Tiered storage. Note that this does not ensure the deletion is successful.
As these two steps are separated, we can't ensure the ledger deletion transaction. If the first step succeeds and the second step fails, then the ledgers can no longer be deleted from the storage system. The second step may fail in some cases (for example, the broker restarts), resulting in orphan ledgers in the storage system.
Can we swap step 1 with step 2 to fix this problem? No, If we delete the ledger from the storage system first, and then remove the ledger from ManagedLedger’s ledger list, we still can’t ensure the ledger deletion transaction. If we delete the ledger from the storage system successfully while the ledger fails to be removed from the ManageLedger’s ledger list, consumers will fail to read data from the topic. This is because the topic still sees the deleted ledger as readable. This issue is even more serious than orphan ledgers.
Another risk in topic deletion is that when a ledger is deleted on the broker side (i.e. removed from the ManagedLedger’s ledger list), the topic metadata may remain if the ledger fails to be deleted in BookKeeper. Therefore, when a consumer fetches data according to the topic metadata, it will fail since the actual data does not exist on bookies.
In order to resolve the above issues, we are working on a proposal to introduce a two-phase deletion protocol to make sure the ledger deletion from the storage system is retriable.
Why doesn’t the retention policy work?
Topic retention policies may not take effect in the following two cases.
The topic is not loaded into brokers
Each topic’s retention policy checker belongs to its own ManagedLedger. If the ManagedLedger is not loaded into the broker, the retention policy checker won’t work. Let’s see the following example.
We produce 100GB of data on topic-a at timestamp t0, and finish producing messages at t0 + 3 hours. The retention policy of topic-a is configured for 6 hours, which means the data won’t be expired until t0 + 6 hours later. However, topic-a may be unloaded between t0 + 3, t0 +6 due to broker restarts, its bundle unloaded by the load balancer, or related operations triggered by the pulsar-admin command. If there is no producer, consumer, or other load topic operations for it, it remains in the unloaded status. When the time reaches t0 + 6 hours, the 100GB of data on topic-a should be expired according to the retention policy. However, as topic-a is not loaded into any broker, the broker's retention policy checker cannot find topic-a. Therefore, the retention policy does not work. In this case, the 100GB of data won’t be expired until topic-a is loaded into the broker again.
We are developing a tool to fix this issue. In this tool, we will check all the long-term ledgers stored in the BookKeeper cluster, and parse out the topic names that the ledgers belong to. After that, these topics can be loaded into Pulsar brokers so that the retention policy can be applied to them.
The ledger is in the OPEN state
The retention policy checker applies each topic’s retention policy, while it only checks the ledgers in the CLOSED state. If a ledger is OPEN, the retention policy won’t take effect even though the ledger should be expired. See the following example for details.
We produce messages to a topic at the rate of 100MB/s with the minimum rollover time of the ledger set to 10 minutes. The minimum rollover time is used to prevent ledger rollovers from happening frequently, and it must be reached before a ledger rollover.
This means the ledger will remain in the OPEN state until 10 minutes are reached. 10 minutes later, the ledger size is about 60GB. If we set the retention time to 5 minutes, these data cannot be expired since the ledger is in the OPEN state. Note that a ledger rollover can be triggered after the minimum rollover time (managedLedgerMinLedgerRolloverTimeMinutes) is reached and one of the following conditions is met:
- The maximum rollover time has been reached (managedLedgerMaxLedgerRolloverTimeMinutes).
- The number of entries written to the ledger has reached the maximum value (managedLedgerMaxEntriesPerLedger)
- The entries written to the ledger have reached the maximum size value (managedLedgerMaxSizePerLedgerMbytes).
These parameters can be configured in broker.conf.
In this example, if the topic is unloaded at timestamp t0 + 9 minutes and remains unloaded, there will be at least about 54GB of data that cannot be expired no matter what the configured retention policy is.
Bookie data compaction policy
Whether a ledger still exists or not in the BookKeeper cluster is tracked based on the ledger metadata stored in the meta store, such as Zookeeper. If Pulsar has deleted the metadata from the meta store, it means the ledger data needs to be removed from all the bookies that store the ledger’s replicas. When a ledger needs to be deleted based on the topic retention policy, Pulsar only deletes the ledger’s metadata instead of the actual replica data stored on bookies. Whether the actual data is deleted depends on each bookie’s garbage collection thread.
Each bookie’s garbage collection can be triggered in the following three cases.
- Minor compaction. You can configure it through minorCompactionThreshold=0.2 and minorCompactionInterval=3600. By default, minor compaction is triggered every hour. If an entryLogFile’s remaining data size is less than 20% of the total size, the entryLogFile will be compacted.
- Major compaction. You can configure it through majorCompactionThreshold=0.5 and majorCompactionInterval=86400. By default, major compaction is triggered every day. If the remaining data size of an entry log file is less than 50% of the total size, the entry log file will be compacted.
- Compaction triggered by REST API. curl -XPUT http://localhost:8000/api/v1/bookie/gc. For the rest api, we should turn it on first by setting httpServerEnabled=true.
How bookie GC works
When a bookie triggers compaction, the compaction checker checks each ledger’s metadata to get the ledger list. For each ledger in the ledger list, it checks whether the ledger’s metadata still exists in the meta store, such as Ledger 2 in Figure 2.
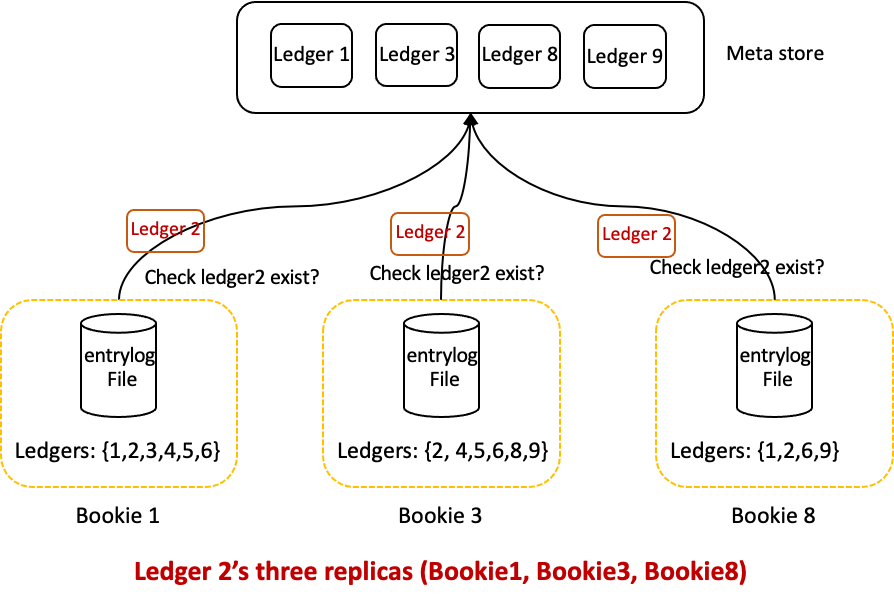
After that, the compaction checker filters out the ledgers that still exist, and calculates the remaining data size percentage of the entry log file. If the percentage is lower than the threshold (by default, minorCompactionThreshold=0.2 and majorCompactionThreshold=0.5), it starts the compaction for the entry log file. Specifically, it reads the remaining ledger’s data from the old entry log file and writes them into the current entry log file. After all the remaining ledgers are compacted successfully, it deletes old entry log files. This frees up storage space.
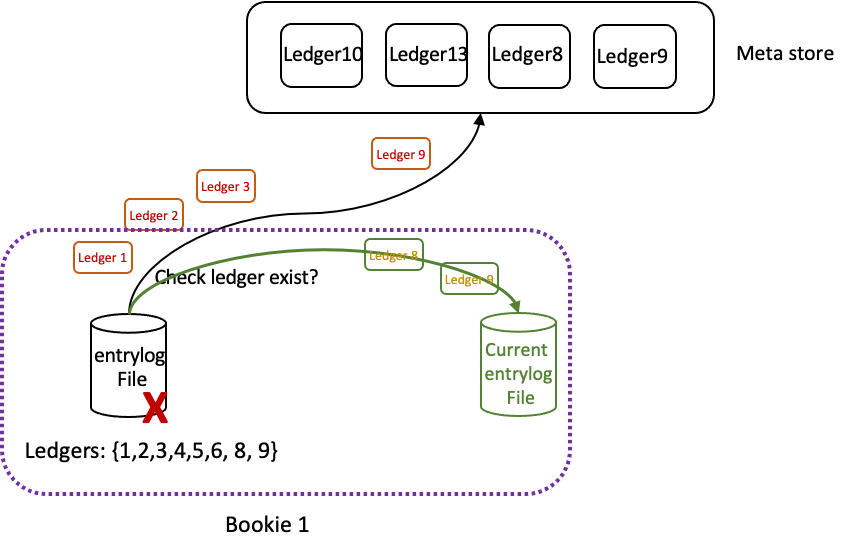 Figure 3
Figure 3
How to reduce GC IO impacts
As the compaction checker reads data from old entry log files and writes them into current ones, it may cause mixed read and write IOs for disks. If we do not introduce a throttling policy, it will affect the performance of the ledger disk.
Compaction throttling
In bookies, there are two kinds of compaction throttle policies, namely by bytes or by entries. The related configurations are listed as follows.
# Throttle compaction by bytes or by entries.
isThrottleByBytes=false
# Set the rate at which compaction will re-add entries. The unit is adds per second.
compactionRateByEntries=1000
# Set the rate at which compaction will re-add entries. The unit is bytes added per second.
compactionRateByBytes=1000000
By default, the bookie uses the throttle-by-entries policy. However, as the data size of each entry is not the same, we cannot control the compaction read and write throughput, and it will have a great impact on the ledger disk performance. Therefore, we recommend using the throttle-by-bytes policy.
PageCache pre-reads
For an entry log file, if more than 90% of the entries have been deleted, the compactor will scan the entries' header metadata one by one. When reading one entry's metadata, it will miss the BufferedChannel read buffer cache, and it will trigger prefetch from the disk. For the following entries, the header metadata reading will also miss the BufferedChannel read buffer cache, and will continue to prefetch from the disk without throttling. This will lead to high ledger disk IO utilization. For more information, see this pull request #3192 to fix this bug.
Moreover, each prefetch operation from the disk will also trigger OS PageCache prefetch. For the compaction model, the OS PageCache prefetch will lead to PageCache pollution, and may also affect the journal sync latency. To solve this problem, we can use the Direct IO to reduce the PageCache effect. For more information, see this issue #2943.
Why doesn’t the bookie GC work
When one ledger disk reaches the maximum usage threshold, it suspends minor and major compaction. When we use the curl -XPUT http://localhost:8000/api/v1/bookie/gc command to trigger compaction, it will be filtered by the suspendMajor and suspendMinor flags. Consequently:
- The bookie doesn’t clean up deleted ledgers.
- The disk space can't be freed up.
- The bookie can't recover from the readOnly state to the Writable state.
In this case, we can only trigger compaction through the following steps.
- Increase the maximum disk usage threshold.
- Restart the bookie.
- Use the command curl -XPUT http://localhost:8000/api/v1/bookie/gc to trigger compaction.
There is a pull request #3205 to add a flag forceAllowCompaction=true for REST API to ignore the suspendMajor and suspendMinor flags to force trigger compaction.
Remove entry log files that cannot be deleted
When a Pulsar cluster keeps running for a few months, some old entry log files on bookies may fail to be deleted. The main reasons are listed as follows.
- Ledger deletion logic’s bug, which leads to orphan ledgers.
- Inactive topics are not loaded into the broker. As a result, the topic retention policy can’t take effect on them.
- Inactive cursors still exist in the cluster, and their corresponding cursor ledgers can’t be deleted.
We need a tool to detect and repair these ledgers in the above cases.
For case 1, after this proposal is applied, it can be resolved. However, the existing orphan ledgers still can’t be deleted. We need to scan the whole BookKeeper cluster’s metadata, and check each ledger’s metadata. If the ledger related topic’s ledger list doesn’t contain the ledger, it means the ledger has been deleted. We can directly delete these ledgers safely using the bookkeeper command. For more information, see the tool here.
For case 2, we will develop a checker to detect inactive topics, which still hold ledger data. After these topics are detected, an operation will be triggered to load them into brokers, and apply a retention policy for them. This feature is still in development.
For case 3, we are considering directly deleting the cursors which have been inactive for a long time, such as 7 days.
Summary
This blog explains the topic data lifecycle in Apache Pulsar, including the topic retention policy and BookKeeper garbage collection logic. At the same time, it also discusses cases where topic data can’t be deleted, and gives some solutions.
More on Apache Pulsar
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community that continues to drive innovation and improvements to the project.
- Start your on-demand Pulsar training today with StreamNative Academy.
- Spin up a Pulsar cluster in minutes with StreamNative Cloud. StreamNative Cloud provides a simple, fast, and cost-effective way to run Pulsar in the public cloud.
- Pulsar Summit Asia 2022 will take place on November 19th and 20th, 2022. The CFP is open now! Submit a proposal to share your Pulsar story!




