
In a previous blog post, Exactly-Once Semantics with Transactions in Pulsar, we introduced the exactly-once semantics enabled by Transaction API for Apache Pulsar. That blog post covered the various message delivery semantics, including:
- The single-topic exactly-once semantics enabled by idempotent producer
- The Transaction API
- The end-to-end exactly-once processing semantics for the Pulsar and Flink integration
In this blog post, we will dive deeper into the transactions in Apache Pulsar. The goal here is to familiarize you with the main concepts needed to use the Pulsar Transaction API effectively.
Why Transactions?
Transactions strengthen the message delivery semantics and the processing guarantees for stream processing (i.e using Pulsar Functions or integrating with other stream processing engines). These stream processing applications usually exhibit a “consume-process-produce” pattern when consuming and producing from and to data streams such as Pulsar topics.
The demand for stream processing applications with stronger processing guarantees has grown along with the rise of stream processing. For example, in the financial industry, financial institutions use stream processing engines to process debits and credits for users. This type of use case requires that every message is processed exactly once, without exception.
In other words, if a stream processing application consumes message A and produces the result as a message B (B = f(A)), then exactly-once processing guarantee means that A can only be marked as consumed if and only if B is successfully produced, and vice versa.
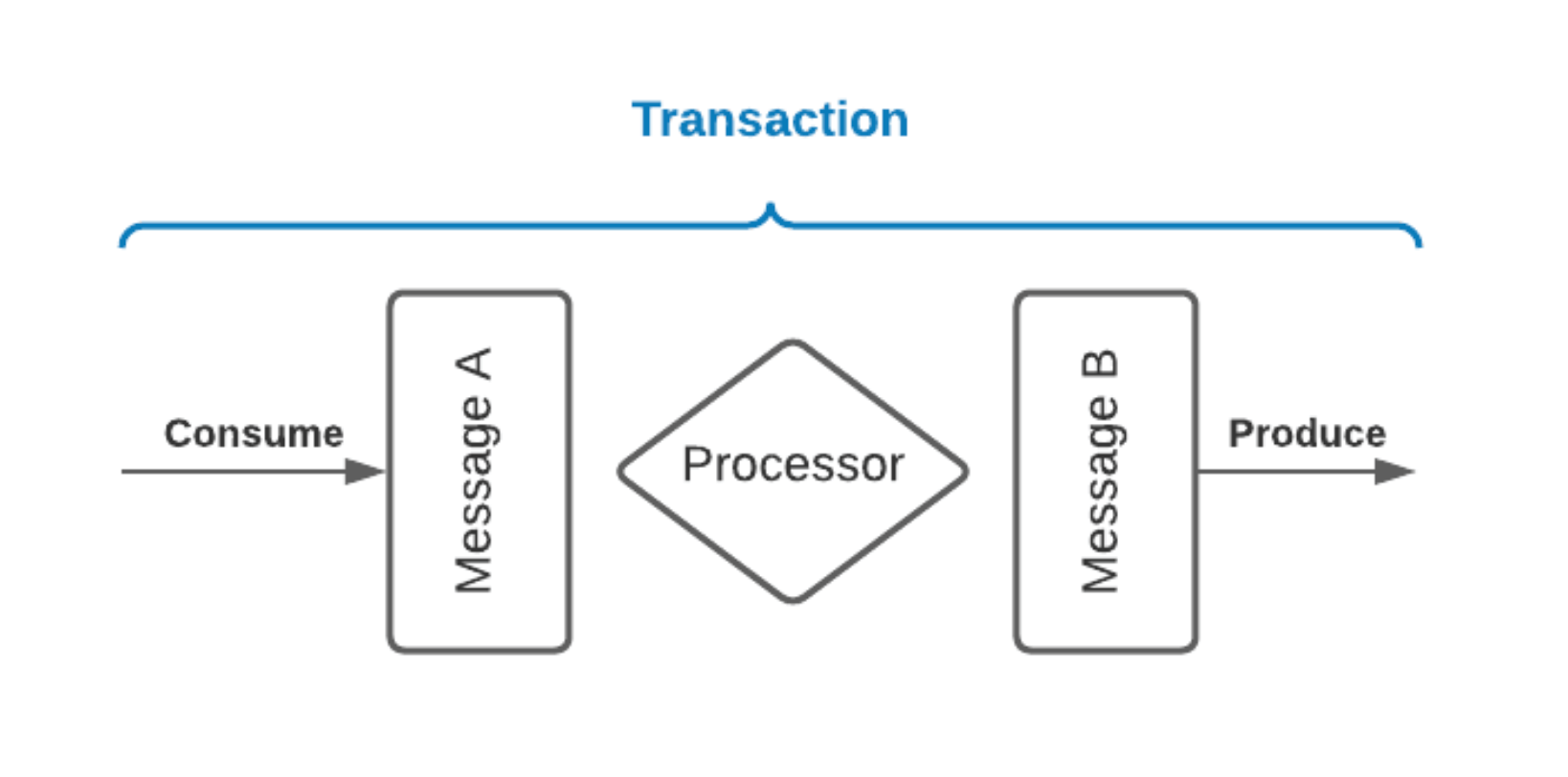
Prior to Pulsar 2.8.0, there was no easy way to build stream processing applications with Apache Pulsar to achieve exactly-once processing guarantees. If you integrate a stream processing engine, like Flink, you might be able to achieve exactly-once processing guarantees. For example, using Flink you can achieve exactly-once processing reading from Pulsar topics, but it is not possible to achieve exactly-once processing writing to Pulsar topics.
When you configure Pulsar producers and consumers for at-least-once delivery semantics, a stream processing application cannot achieve exactly-once processing semantics in the following scenarios:
- Duplicate writes: A producer can potentially write a message multiple times due to the internal retry logic. The idempotent producer addresses this via guaranteed message deduplication.
- Application crashes: The stream processing application can crash at any time. If the application crashes after writing the result message B but before making the source message A as consumed. The application can reprocess the source message A after it restarts, resulting in a duplicated result message B being written again to the output topic, violating the exactly-once processing guarantees.
- Zombie application: The stream processing application can potentially be partitioned from the network in a distributed environment. Typically, new instances of the same stream processing application will be automatically started to replace the ones which were deemed lost. In such a situation, multiple instances of the same processing application may be running. They will process the same input topics and write the results to the same output topics, causing duplicate output messages and violating the exactly-once processing semantics.
The new Transaction API introduced in Pulsar 2.8.0 release is designed to solve the second and third problems.
Transactional Semantics
The Transaction API enables stream processing applications to consume, process, and produce messages in one atomic operation. That means, a batch of messages in a transaction can be received from, produced to and acknowledged to many topic partitions. All the operations involved in a transaction succeed or fail as one single until.
But how does the Transaction API resolve the three problems above?
Atomic writes and acknowledgements across multiple topics
First, the Transaction API enables atomic writes and atomic acknowledgments to multiple Pulsar topics together as one single unit. All the messages produced or consumed in one transaction are successfully written or acknowledged together, or none of them are. For example, an error during processing can cause a transaction to be aborted, in which case none of the messages produced by the transaction will be consumable by any consumers.
What does this mean to an atomic “consume-process-produce” operation?
Let’s assume that if an application consumes message A from topic T0 and produces a result message B to topic T1 after applying some transforming logic on message A (B = f(A)), then the consume-process-produce operation is atomic only if message A and B are considered successfully consumed and published together, or not at all. The message A is ONLY considered consumed from topic T0 only when it is successfully acknowledged.
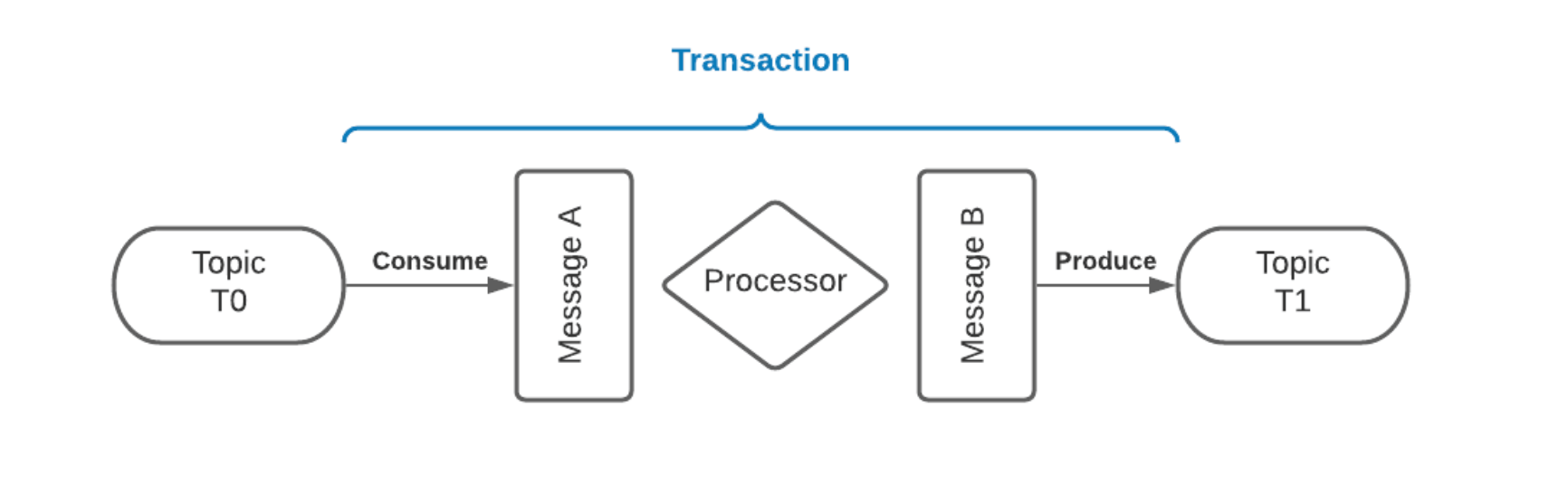
Transaction API ensures the acknowledgement of message A and the write of message B to happen as atomic, hence the “consume-process-produce” operation is atomic.
Fence zombie instances via conditional acknowledgement
We solve the problem of zombie instances by conditional acknowledgement. Conditional acknowledgement means if there are two transactions attempting to acknowledge on the same message, Pulsar guarantees that there is ONLY one transaction that can succeed and the other transaction is aborted.
Read transactional messages
What is the guarantee for reading messages written as part of a transaction?
The Pulsar broker only dispatches transactional messages to a consumer if the transaction was actually committed. In other words, the broker will not deliver transactional messages which are part of an open transaction, nor will it deliver messages which are part of an aborted transaction.
However, Pulsar doesn’t guarantee that the messages produced within one committed transaction will be consumed all together. There are several reasons for this:
- Consumers may not consume from all the topic partitions that participated in the committed transaction. Hence they will never be able to read all the messages that are produced in that transaction.
- Consumers may have a different receiver queue size or buffering window size, allowing only a certain amount of messages. That amount can be any arbitrary number.
Transactions API
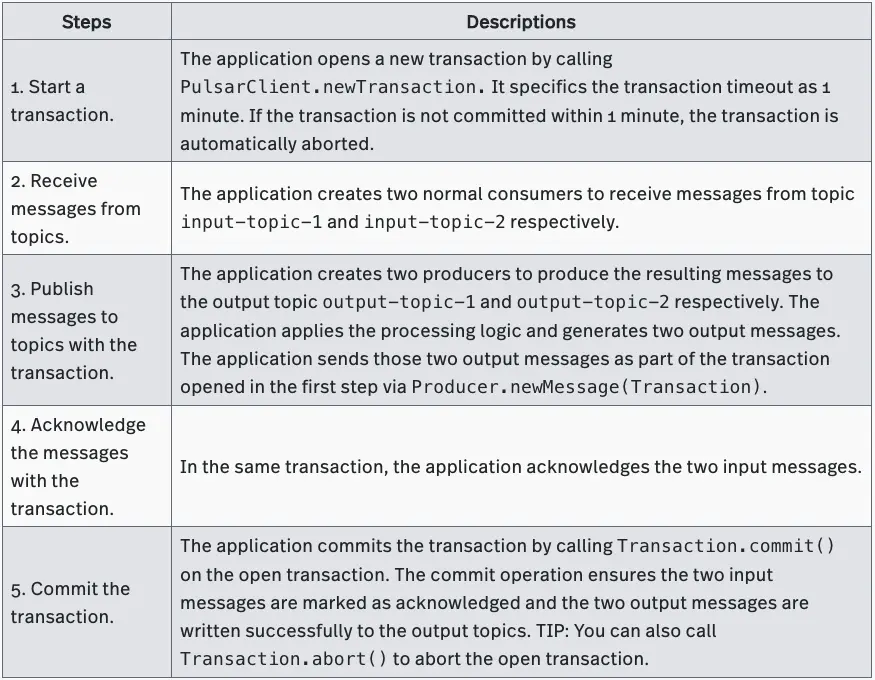
The transaction feature is primarily a server-side and protocol-level feature. Currently it is only available for Java clients. (Support for other language clients will be added in the future releases.) An example “consume-process-produce” application written in Java and using Pulsar’s transaction API would look something like:

Let’s walk through this example step by step.
How transactions work
In this section, we present a brief overview of the new components and new request flows introduced by the Transaction APIs. For a more exhaustive treatment of this subject, you may checkout the original design document, or watch the upcoming Pulsar Summit talk where transactions were introduced.
The content below provides an overview to help with debugging or tuning transactions for better performance.
Components
Transaction coordinator and Transaction log
The transaction coordinator (TC) maintains the topics and subscriptions that interact in a transaction. When a transaction is committed, the transaction coordinator interacts with the topic owner broker to complete the transaction.
The transaction coordinator is a module running inside a Pulsar broker. It maintains the entire life cycle of transactions and prevents a transaction from getting into an incorrect status. The transaction coordinator also handles transaction timeout, and ensures that the transaction is aborted after a transaction timeout.
All the transaction metadata persists in the transaction log. The transaction log is backed by a Pulsar topic. After the transaction coordinator crashes, it can restore the transaction metadata from the transaction log.
Each coordinator owns some subset of the partitions of the transaction log topics, i.e. the partitions for which its broker is the owner.
Each transaction is identified with a transaction id (TxnID). The transaction id is 128-bits long. The highest 16 bits are reserved for the partition of the transaction log topic and the remaining bits are used for generating monotonically increasing numbers by the TC who owns that transaction log topic partition.
It is worth noting that the transaction log topic just stores the state of a transaction and not the actual messages in the transaction. The messages are stored in the actual topic partitions. The transaction can be in various states like “Open”, “Prepare commit”, and “committed”. It is this state and associated metadata that is stored in the transaction log.
Transaction buffer
Messages produced to a topic partition within a transaction are stored in the transaction buffer of that topic partition. The messages in the transaction buffer are not visible to consumers until the transactions are committed. The messages in the transaction buffer are discarded when the transactions are aborted.
Pending acknowledge state
Message acknowledgments within a transaction are maintained by the pending acknowledge state before the transaction is committed. If a message is in the pending acknowledge state, the message cannot be acknowledged by other transactions until the message is removed from the pending acknowledge state when a transaction is aborted.
The pending acknowledge state is persisted to the pending acknowledge log. The pending acknowledge log is backed by a cursor log. A new broker can restore the state from the pending acknowledge log to ensure the acknowledgement is not lost.
Data flow
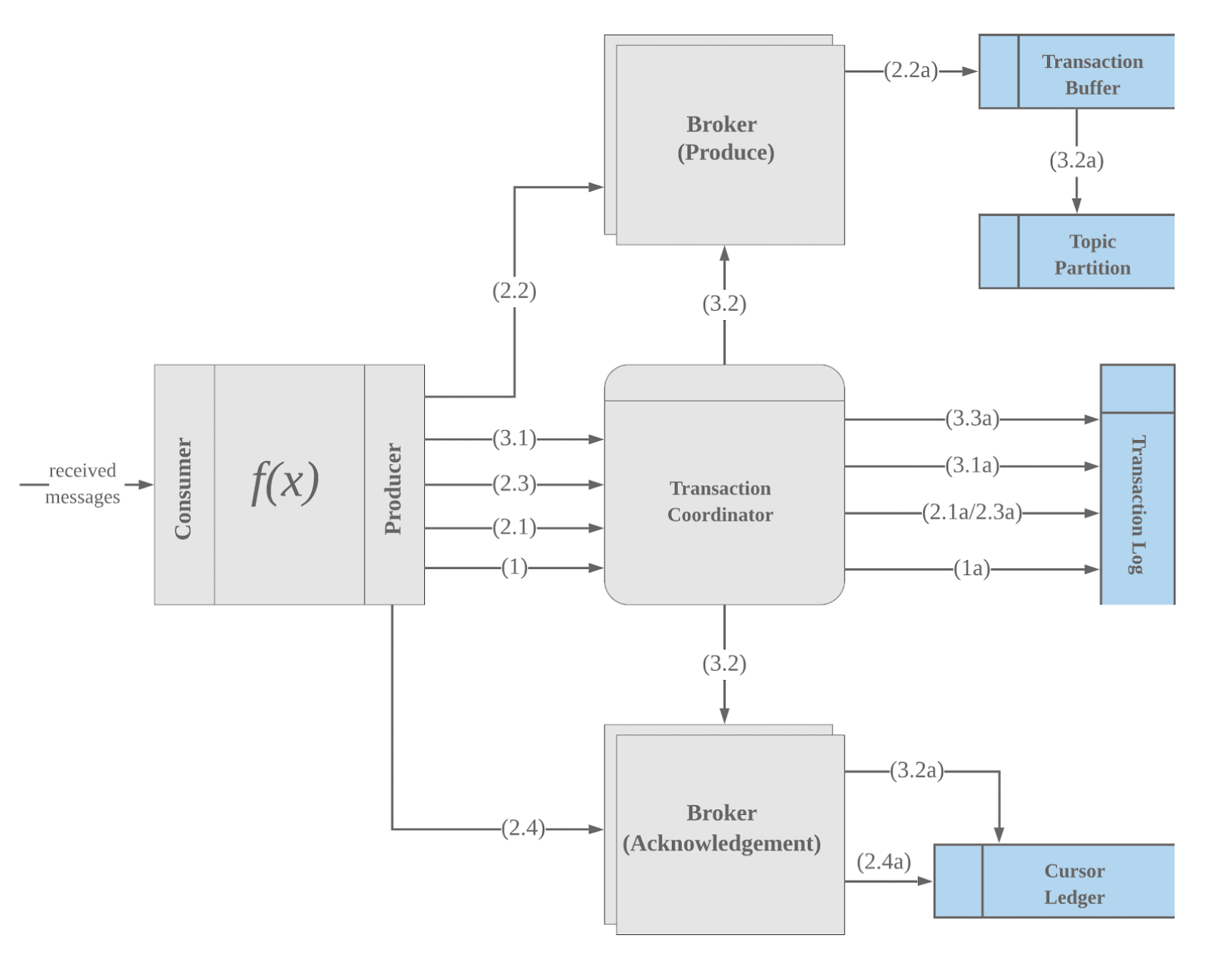
At a high level, the data flow can be broken into multiple steps. 1. Start a transaction. 2. Publish messages with a transaction. 3. Acknowledge messages with a transaction. 4. Complete a transaction.
Begin transaction
At the beginning of a transaction, the Pulsar client will locate a Transaction Coordinator to request a new transaction ID. The Transaction Coordinator will allocate a transaction ID for the transaction. The transaction will be logged with its transaction id and status of OPEN in the transaction log (as shown in step 1a). This ensures the transaction status is persisted regardless of whether the Transaction Coordinator crashes. After a transaction status entry is logged, TC returns the transaction ID back to the Pulsar client.
Publish messages with a transaction
Before the pulsar client produces messages to a new topic partition, the client sends a request to TC to add the partition to the transaction. TC logs the partition changes into its transaction log for durability (as shown in 2.1a). This step ensures TC knows all the partitions that a transaction is handling, so TC can commit or abort changes on each partition at the end-partition phase.
The Pulsar client starts producing messages to partitions. This producing flow is the same as the normal message producing flow. The only difference is the batch of messages produced by a transaction will contain the transaction id. The broker that receives the batch of messages checks if the batch of messages belongs to a transaction. If it doesn’t belong to a transaction, the broker handles the writes as it normally would. If it belongs to a transaction, the broker writes the batch into the partition’s transaction buffer.
Acknowledge messages with a transaction
The Pulsar client sends a request to TC the first time a new subscription is acknowledged as part of a transaction. The addition of the subscription to the transaction is logged by TC in step 2.3a. This step ensures TC knows all the subscriptions that a transaction is handling, so TC can commit or abort changes on each subscription at the EndTxn phase.
The Pulsar client starts acknowledging messages on subscriptions. This transactional acknowledgement flow is the same as the normal acknowledgement flow. However the ack request carries a transaction id. The broker receiving the acknowledgement request checks if the acknowledgment belongs to a transaction or not. If it belongs to a transaction, the broker will mark the message as:PENDING_ACK state. PENDING_ACK state means the message can not be acknowledged or negative-acknowledged by other consumers until the ack is committed or aborted. This ensures if there are two transactions attempting to acknowledge one message, only one will succeed and the other one will be aborted.
The Pulsar client will abort the whole transaction when it tries to acknowledge but the conflict is detected on both individual and cumulative acknowledgements.
Complete a transaction
At the end of a transaction, the application will decide to commit or abort the transaction. The transaction can also be aborted if a conflict is detected when acknowledging messages.
When a pulsar client is finished with a transaction, it can issue an end transaction request to TC, with a field indicating whether the transaction is committed or aborted.
TC writes a COMMITTING or ABORTING message to its transaction log (as shown in 3.1a) and begins the process of committing or aborting messages or acknowledgments to all the partitions involved in this transaction. It is shown in 3.2.
After all the partitions involved in this transaction are successfully committed or aborted, TC writes COMMITTED or ABORTED messages to its transaction log. It is shown in 3.3 in the diagram.
How transactions perform
So far, this document covered the semantics of transactions and how they work, next let’s turn our attention to how transactions perform.
Performance for transactional producers
Transactions cause only moderate write amplification. The additional writes are due to:
- For each transaction, the producers receive additional requests to register the topic partitions with the coordinator.
- When completing a transaction, one transaction marker is written to each partition participating in the transaction.
- Finally, the TC writes transaction status changes to the transaction log. This includes a write for each batch of topic partitions added to the transaction ( “prepare commit” and the “committed” status).
The overhead is independent of the number of messages written as part of a transaction. So the key to having higher throughput is to include a large number of messages per transaction. Smaller messages or shorter transaction commit intervals result in more amplification.
The main tradeoff when increasing the transaction duration is that it increases end-to-end latency. Recall that a consumer reading transactional messages will not deliver messages which are part of open transactions. So the longer the interval between commits, the longer consumers will have to wait, increasing the end-to-end latency.
Performance for transactional consumers
The transactional consumer is much simpler than the producer. All the logic is done by the Pulsar broker at the server side. The broker only dispatches the messages that are in completed transactions.
Further reading
In the blog post, we only scratched the surface of transactions in Apache Pulsar. All the details of the design are documented online. You can find those references listed below:
- The design document: This is the definitive place to learn about the public interfaces, the data flow, the components. You will also learn about how each transaction component is implemented, how each transactional request is processed, how the transactional data is purged, etc.
- The Pulsar Client javadocs: The Javadocs is a great place to learn about how to use the new APIs.
- Exactly-Once Semantics with Transaction Support in Pulsar: This is the first part of this blog series.
My fellow colleagues Sijie Guo and Addison Higham are going to give a presentation “Exactly-Once Made Easy: Transactional Messaging in Apache Pulsar” at the upcoming Pulsar Summit North America 2021 on June 16-17th. If you are interested in this topic, reserve your spot today and listen to them diving into every detail of Pulsar Transaction.
Conclusion
In the first blog post of this series, Exactly-Once Semantics Made Simple with Transaction Support in Pulsar, we introduced the exactly-once semantics enabled by Transaction API for Apache Pulsar. In this post, we talked about the key design goals for the Transaction API in Apache Pulsar, the semantics of the transaction API, and a high-level idea of how the APIs actually work.
If we consider stream processing as a read-process-write processor, this blog post focuses on the read and write paths with the processing itself being a black box. However, in the real world, a lot happens in the processing stage, which makes exactly-once processing impossible to guarantee using the Transaction API alone. For example, if the processing logic modifies external storage systems, the Transaction API covered here is not sufficient to guarantee exactly-once processing.
The Pulsar and Flink integration uses the Transaction API described here to provide end-to-end exactly-once processing for a wide variety of stream processing applications, even those which update additional state stores during processing.
In the next few weeks we will share the third blog in this series to provide the details on how the Pulsar and Flink integration provides end-to-end exactly-once processing semantics based on the new Pulsar transactions, as well as how to easily write streaming applications with Pulsar and Flink.
If you want to try out the new exactly-once functionality, check out StreamNative Cloud or install the StreamNative Platform today, to create your own applications to process streams of events using the Transaction API.




