If you use the StreamNative Platform, refer to this guide for steps to activate or update the Extensible Load Balancer. For those on the StreamNative Cloud, please reach out to the support team for help.
Intro
We are thrilled to introduce our latest addition to the Apache Pulsar version 3.0, Extensible Load Balancer, which improves the existing Pulsar Broker Load Balancer. For those seeking more details, in this blog, we're sharing the specifics of the enhancements and the obstacles we've overcome during the implementation process.
What is the Pulsar Broker Load Balancer?
The Pulsar Broker Load Balancer is a component within the Apache Pulsar messaging system. The Pulsar’s compute-storage separation architecture enables the Pulsar Broker Load Balancer to seamlessly balance groups(bundles*) of topic sessions among brokers without involving message copies. This helps ensure efficient broker resource utilization, prevents individual brokers' overloading or underloading, and provides fault tolerance by promptly redistributing the orphan workload to available brokers.
Topics are grouped into bundles in Pulsar, and Bundle is the broker load balancer unit.
The Pulsar community has recently made notable improvements to its load balancer documentation. We recommend looking at the updated documentation if you're interested in this topic.
Why do we introduce a new load balancer?
Legacy Maintenance Issues: Over time, the old load balancer's architecture introduced a long-standing maintenance challenge due to its historical design decisions. The old load balancer's design might not have been as modular as desired, making introducing new architectures, strategies, or logic challenging without affecting the existing functionality. This lack of modularity could hinder experimenting with improvements and innovations. Keeping up with maintenance might have become increasingly difficult, leading to the need for a more modern and manageable solution. This complexity could hinder implementing new features or fixing issues quickly.
Scalability Issues: As Pulsar clusters grew with more brokers and topics, the load balancer faced challenges in efficiently distributing metadata(including load balance data). The mechanism for replicating load data across brokers via metadata store(e.g. ZooKeeper) watchers became less scalable, resulting in potential performance bottlenecks and increased replication overhead.
Load Balancing Strategy: The previous load balancing strategy might have needed to have been more optimal for evenly distributing the workload, especially when dealing with dynamic load changes in adding or removing brokers.
Topic Availability During Unloading: The old load balancer might have led to resource access conflicts, causing longer temporary unavailability of topics during the unloading process, affecting the user experience and resource utilization.
Centralized Decision Making: Only the leader broker makes load balance decisions in the previous load balancer. This centralized approach could create bottlenecks and limit the system's ability to distribute the workload efficiently.
Operation: Sometimes, debugging the load balance decisions could have been clearer. Observability needs to be improved.
How do we solve the problems with the New Load Balancer?
Legacy Maintenance Challenges: The new load balancer is written with new classes with a cleaner design. This will facilitate easier maintenance, updates, and the integration of new features without disrupting the existing functionality. This enhances the system's manageability and adaptability over time.
Scalability Issues: To overcome scalability challenges, the new load balancer stores load and ownership data in Pulsar native topics and reads them via Pulsar table views. This reduces replication overhead and potential bottlenecks, ensuring smooth load data distribution even in larger Pulsar clusters.
Load Balancing Strategy: All load balancing strategies(assignment, unloading, and splitting) are revisited with the new load balancer to ensure better workload distribution. It adapts to dynamic changes and efficiently handles new broker additions and deletions, resulting in a more balanced and optimized distribution of tasks. Load balance operations and states’ idempotency have been revisited when retrying upon failures.
Topic Availability During Unloading: The new load balancer minimizes topic unavailability during unloading by pre-assigning the owner broker and gracefully transferring ownership with the bundle transfer option. This minimizes resource access conflicts and reduces temporary topic downtime, enhancing user experience.
Centralized Decision Making: The new load balancer explores decentralized decision-making (assignment and splitting), distributing load balance decisions to local brokers as much as possible rather than relying solely on a central leader. This minimizes bottlenecks, enabling more efficient and distributed workload management.
Operation: Besides, the new load balancer also introduces a new set of metrics and load balancer debug-mode dynamic config to print more useful load balance decisions in the logs.
How do we enable the New Load Balancer?
The community updated the load balancer migration steps on the Pulsar website to explain how to migrate from the modular load balancer to the extensible load balancer and vice versa.
Extensible Load Balancer Design
To summarize, the modular (current) and extensible (new) load balancers implement similar load balancing functionalities with different system designs.
For example, they both employ a similar approach to distributing data loads among brokers, including:
- Dynamic bundle-broker assignment
- Dynamic bundle splitting
- Dynamic bundle unloading (shedding)
However, for bundle ownership and load data stores, the modular load balancer uses a configurable metadata store (e.g., ZooKeeper), whereas the extensible load balancer uses Pulsar native System topics and Table views.
Table View has been introduced to Pulsar since 2.10, which provides a continuously updated key-value map view of the compacted topic data. This innovation greatly simplifies the new load balancer’s data architecture since each broker needs to publish load data to non-persistent (in-memory) system topics and replicate the latest views on table views. Similarly, for bundle ownership data, each broker can publish the ownership change messages to a persistent system topic and replicate the latest views on the table views.
Load Data Flow
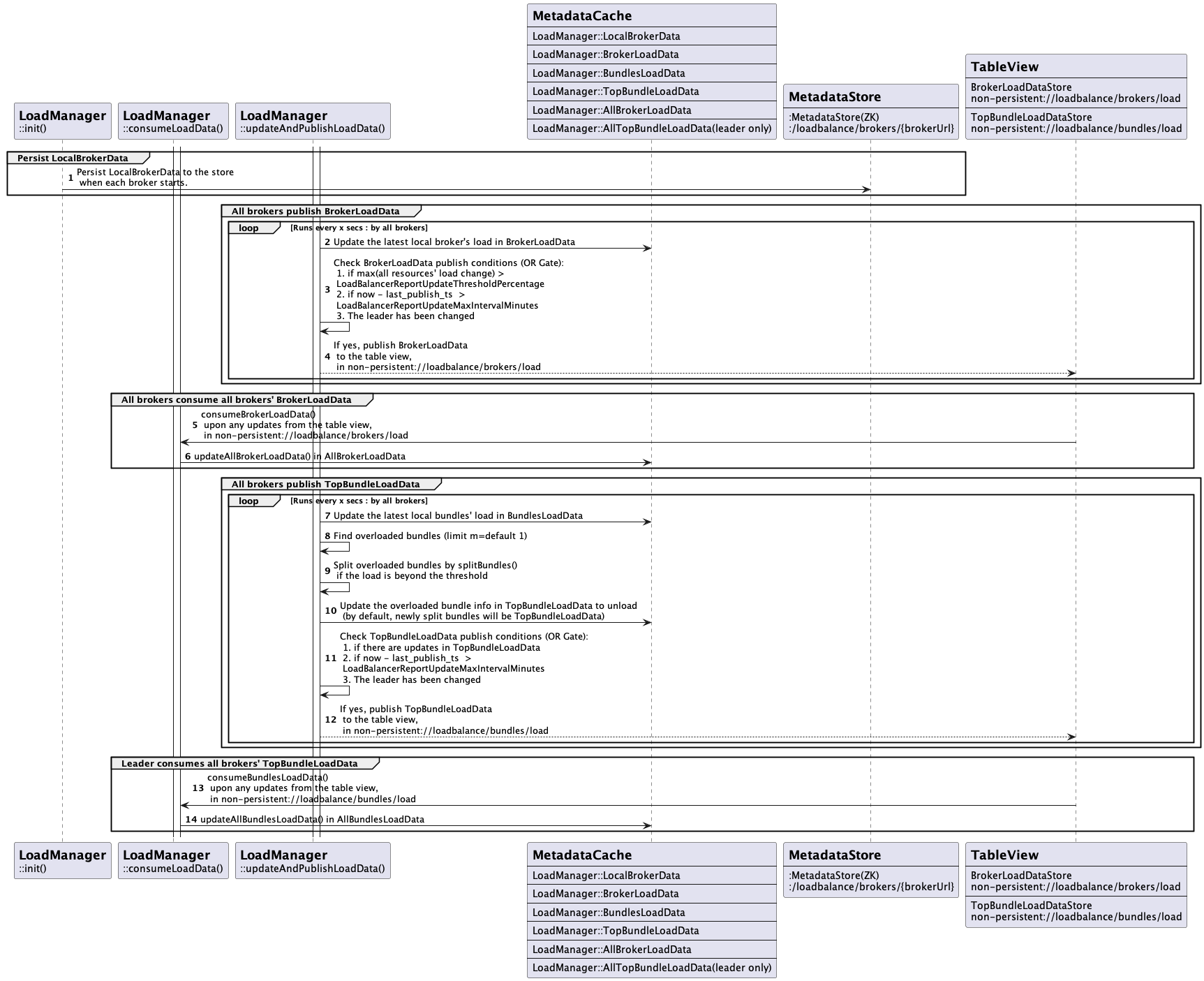
The exchange of load data holds significant importance in achieving optimal load balancing, as incorrect or sluggish load data can negatively affect balancing efficiency. In this new design, brokers periodically share their broker load and top k bundle load data by publishing them to separate in-memory system topics. Each broker utilizes this broker load data for assignments and its local bundle load data for splitting, while the leader broker triggers the global bundle unloading based on both global broker and bundle load data. This new design decouples load data stores depending on the use cases to clean the data model and ensure the modularity of the load-balancing system.
Bundle State Channel
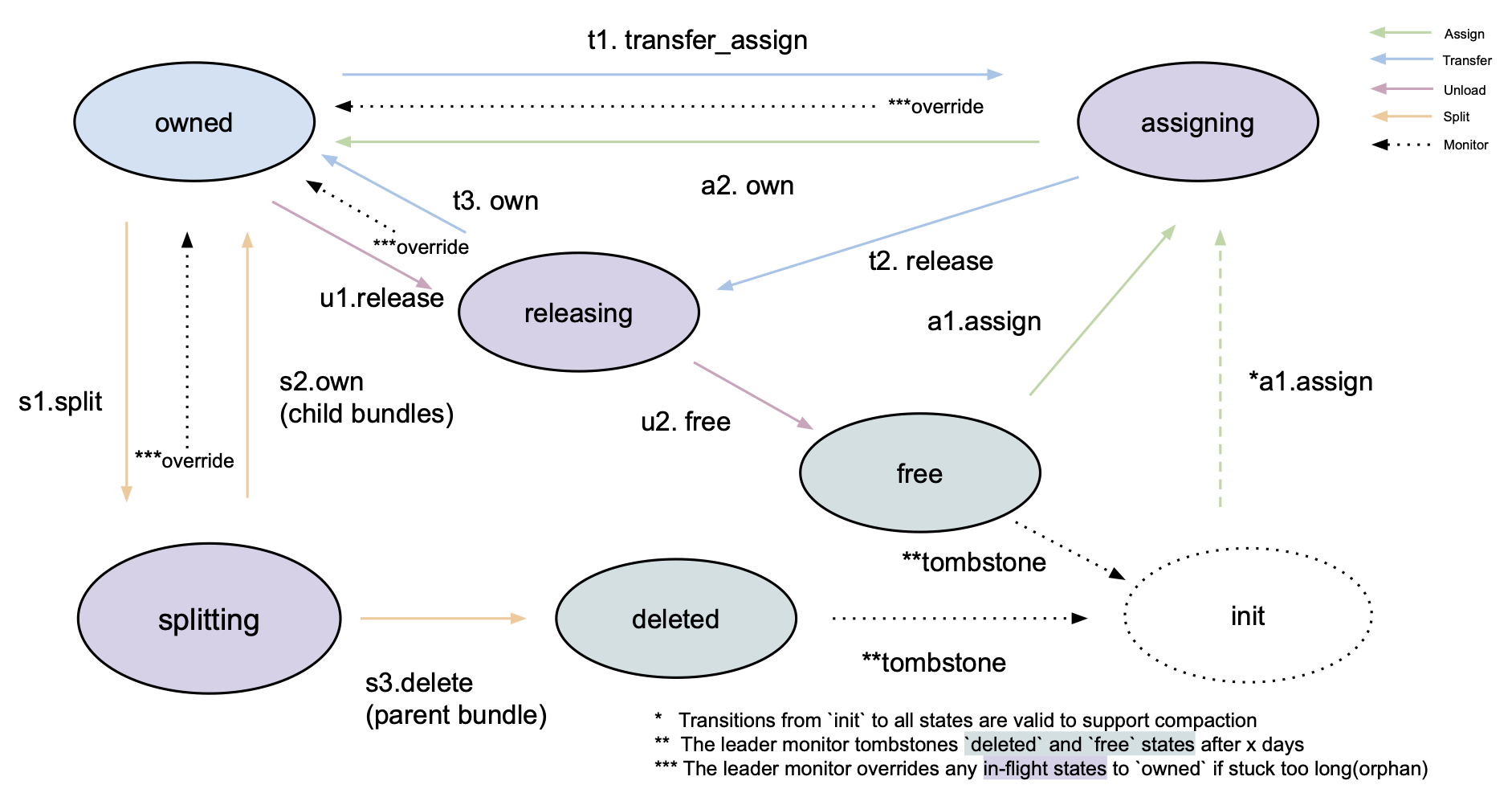
The new load balancer introduced a bundle state machine like the above to define the possible states and transitions in the bundle(group of topics) life cycle. Also, to communicate these state changes across brokers and react to them, we introduced an event-source channel, Bundle State Channel, where each actor (broker) broadcasts messages containing these state transitions to the system topic and accordingly plays the roles upon received. Since these state changes persist in the system topic, it can ensure persistence, (eventual) consistency, and idempotency of the bundle state changes, even after failing and retrying.
Managing bundle ownership and resolving conflicts among brokers presents challenges. This complexity is heightened when multiple brokers concurrently assign ownership over the same bundle, or when such assignments occur during operations like bundle splitting or unloading. Effective conflict resolution strategies are pivotal in maintaining system integrity. Several approaches are available:
- Centralized Leadership Model: This method designates a singular leader among the brokers to oversee conflict resolution. The leader takes charge of resolving ownership conflicts and ensuring uniform state transitions. While this centralizes conflict resolution, it introduces the potential for a single point of failure and potential bottlenecks if the leader becomes overwhelmed.
- Decentralized Approach: An alternative is a decentralized model, wherein individual brokers incorporate the identical conflict resolution mechanism. The brokers algorithmically deduce a consistent pathway for state transitions at the cost of additional messages on each broker.
The latter approach is pursued in the present implementation to circumvent reliance on the single leader. This involves embedding conflict resolution logic in each broker with the benefits of the “early broadcast” to defer the client lookups until the ownership is finalized. This could prevent clients from retrying lookups redundantly in the middle of bundle state changes. Also, this conflict resolution logic is straightforward to place on each broker without auxiliary metadata — given the linearized message sequence of this system topic, any message with a valid state transition and version ID will be accepted; otherwise, rejected. To generalize this custom conflict resolution strategy, the Pulsar community introduced a configurable conflict resolution strategy for both topic compaction and table views (only enabled for system topics as of today).
Also, we need to ensure the bundle ownership integrity recovers from disaster cases, such as network failure and broker crashes. Failure of this disaster recovery can cause ownership inconsistency, orphan ownerships, or state changes stuck in in-transit states. To rectify such invalid ownership states, the leader broker listens to any broker unavailability and metadata (ZooKeeper) connection stability and accordingly assigns new brokers. The leader also periodically monitors bundle states and fixes any invalid states that remain too long.
TransferShedder
The new load balancer introduced a new shedding strategy, TransferShedder. Here, we would like to highlight the following characteristics.
One major improvement is that the bundle transfer option makes the unloading process more graceful. Previously, upon unloading, the modular load balancer relied on clients’ lookups to assign new owner brokers via the leader broker. (note that the modular load balancer has recently improved this behavior) However, with this bundle transfer option (by default), TransferShedder pre-assigns new owner brokers and helps clients bypass the client-leader-involved assignment.
Another major algorithmic change is with this transfer protocol, TransferShedder unloads bundles from the next highest load brokers to the next lowest load brokers until all of the following are true:
- The standard deviation of the broker load distribution is below the configured threshold.
- There are no significantly underloaded brokers.
- There are no significantly overloaded brokers.
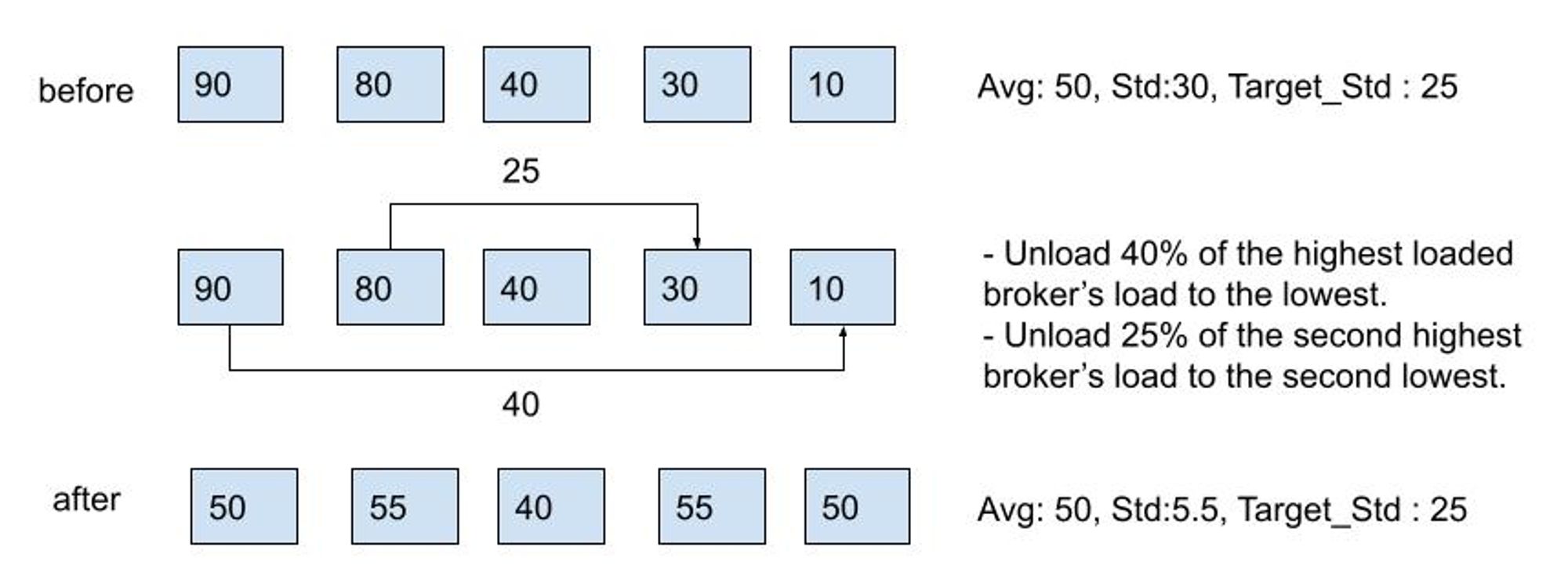
Essentially, the goal is to keep the load distribution under the target at minimal steps. For this, TransferShedder tracks the global load score distribution(Standard Deviation) and tries to keep it lower than the configured threshold, loadBalancerBrokerLoadTargetStd, by moving the loads from the highest to the lowest loaded brokers. If there are any outliers (significantly underloaded or overloaded brokers), it will try to prioritize them to unload.
Also, it helps the load balance convergence. Too aggressive load balancing could often result in infinite unloading or bundle oscillation (bouncing bundles). One example is that if one broker is slightly more overloaded than the others, unloading a bundle from that broker might overload the other broker (again slightly more than others). If the target bundle unloading is not as effective, the logic should stop further unloading to avoid this bundle oscillation. The bundle transfer option enables TransferShedder to consider this case, which helps the load balance convergence.
TransferShedder uses the same methodology for broker load score computation as ThresholdShedder, which is based on the exponential moving average of the max of the weighted resource usages among CPU, memory, and network load. It also introduced the loadBalancerSheddingConditionHitCountThreshold config to further control the sensitivity of unloading decisions when the traffic pattern is spiky. Sometimes, traffic might burst and come down soon, and users might want to avoid triggering unloading. In this case, the user could increase this threshold to make the unloading less sensitive to traffic bursts.
Additionally, the extensible load balancer exposes loadBalancerMaxNumberOfBundlesInBundleLoadReport and loadBalancerMaxNumberOfBrokerSheddingPerCycle configs to control the maximum number of bundles and brokers for each unloading cycle. If users need to slow down the load balance impact and limit the impacted bundles and brokers for each unloading cycle (default 1 min), these configs could help them.
Operational Improvement
Recently, Pulsar improved the bundle unload command to specify the destination broker. This will continue to work for the new load balancer, so if manual unloading is needed, admins could try this command as a one-time resolution.
Operationally, we introduced additional metrics from this new load balancer. The community recently updated the metrics page to reflect this addition. To summarize, we are trying to show additional breakdown metrics for the decision count grouped by the reason label.
It is also possible to closely monitor the load score for each broker. This will better inform the actual load score used for the load balance decision instead of tracking the root signals, such as memory, CPU, and network load. Additionally, there are other metrics to show what the current load score distribution (avg and std) is.
- pulsar_lb_resource_usage_stats{feature=max_ema, stat=avg} (gauge) - The average of brokers' load scores.
- pulsar_lb_resource_usage_stats{feature=max_ema, stat=std} - The standard deviation of brokers’ load scores.
We added a new sample load balancer dashboard for these metrics here, so please try it and let us know if you have any questions about how to read them.
Lastly, we added a dynamic config loadBalancerDebugModeEnabled. Often, printing out logs can be the best way to debug issues, and under this debug flag, we tried to put as many decision logs as possible. You can enable this flag without restarting brokers and check the logs for the load balance decisions. This could help to tune the configs. Once the debugging is done, the admin can simply turn off this flag again without restarting brokers.
Modular(Current) vs. Extensible(New) Load Balancer Performance Tests
We performed four tests to evaluate performance improvement from this new load balancer. These four tests separately ran on the existing load balancer (modular load balancer) and the new one (extensible load balancer). These tests used Puslar-3.0.
- Assignment Scalability Test:
Goal: When many clients reconnect, many systems, including Pulsar, suffer from “thundering herd reconnection,” where the brokers are suddenly bombarded by many reconnection(lookup) requests. We expect the shortened lookup path by the new load balancer to help in this scenario.
Methodology: We measure the start and end time to reconnect a large number of publishers(100k) when a large cluster(100 brokers) with many bundles(60k) restarts all brokers in a short time frame(2 mins).
- Assignment Latency Test:
Goal: We are also interested in how the new load balancer improves individual message delays(how quickly an individual message can be re-published) when restarting brokers one by one. Similarly, we expect the shortened lookup path to reduce the latency in this scenario.
Methodology: We compare p99.99 latency of messages(10k partitions, 1000 bundles at 1000 msgs/s) published when a cluster(10 brokers) restarts brokers one by one.
- Unload Test:
Goal: Automatic Topic(bundle) unloading helps load balancing, especially when scaling brokers up or down because such scaling events suddenly cause load imbalance. We expect the new way of sharing load data, via in-memory non-persistent topics, to propagate load data faster and more lightweight than the Metadata store(ZK). Also, we want to compare a new unloading strategy, TransferShedder, with the current default, ThresholdShedder.
Methodology: We compare time to unload and balance the load(100 bundles, 10k topics/ publishers) when a set of brokers joins/leaves the cluster(5→10, 10→5 broker scaling).
- Split(Hot-spot) Test:
Goal: Automatic bundle splitting is the other important Pulsar load balance feature when topics are suddenly overloaded, “hot-spot.” This bundle split can isolate such hot-spot topics by splitting the owner bundles into smaller pieces. The child bundles can be more easily unloaded to other brokers to reduce the load on the issuing broker. We want to measure how the new load balancer can improve this process.
Methodology: We compare the time to split one bundle to 128 bundles and balance the load(10k topics/ publishers) when the topics have a high load.
Test Results
Assignment Scalability Test Result
100k Publisher Connection Recovery Time
Modular LB
At 12:25, the restart happened
.png)
Extensible LB
At 09:33, the restart happened
.png)
Publisher Connection Recovery Time:
- Modular LB: 20 mins
- Extensible LB: 10 mins
Assignment Latency Test Result
p99.99 Pub Latency when restarting brokers one by one (total 10 brokers)
.png)
p99.99 Pub Latency:
- Modular LB: 1841 ms
- Extensible LB: 1228 ms
Unload Test Result
Modular LB
At 01:38, scaled down from 10 to 5
At 01:58, scaled up from 5 to 10
.png)
Extensible LB
At 21:58, scaled down from 10 to 5
At 22:08, scaled up from 5 to 10
.png)
Case 1: Time to balance the load from scaling down from 10 brokers to 5 brokers
Time to balance the load:
- Modular LB: 5 mins
- Extensible LB: 3 mins
Case 2: Time to balance the load from scaling up from 5 brokers to 10 brokers
Time to balance the load:
- Modular LB: 7 mins
- Extensible LB: 5 mins
Split Test Result
Time to balance the load by splitting bundles starting from 1 bundle (up to 128 bundles) and unloading to 10 brokers
Modular LB
.png)
Extensible LB
.png)
Time to balance the load:
- Modular LB: 15 mins
- Extensible LB: 13 mins
Also, with loadBalancerBrokerLoadTargetStd=0.1, the new load manager shows a better topic load balance, max - min= 1.1k -779 = 321, than the old load manager’s, 1.6k - 394= 1.2k, which is about 4x better.
Max Topic Count - Min Topic Count:
- Modular LB: 1.1k -779 = 321
- Extensible LB: 1.6k - 394= 1.2k
Please note that the split and unloading cycles occur concurrently. Because of that, unloading could be delayed if the next split occurs faster before unloading. We could further optimize this behavior by splitting the parent bundles in the n-way instead of the current 2-way and immediately triggering unloading post splits. Meanwhile, users could tune loadBalancerSplitIntervalMinutes(default 1min) and loadBalancerSheddingIntervalMinutes(default 1min) if they need to tune those frequencies.
Test Result Summary

As we shared earlierHow do we solve the problems in New Load Balancer?, the new load balancer implemented the following changes, and we are glad to share that these changes can help the above load balance cases up to 2x better.
Distributed load balance decisions
- Topic lookup and split decisions on every broker instead of going through the leader
Optimized load data sharing
- The load data is shared in a shorter path. Broker and bundle load data are shared with other brokers via non-persistent(in-memory) Pulsar system topics instead of involving disk persistence in the metadata store(ZK). This makes load balance decisions more up-to-date. Pulsar takes one step closer to a ZK-less architecture.
- The amount of shared load data is minimized. Each broker shares only the top K bundles’ load instead of all, which scales better when there are many bundles. Broker and bundle load data are decoupled into different topics because their update cadence differs with different consumption patterns.
Optimized ownership data sharing
- Ownership data is shared via a Pulsar system topic instead of via metadata store (ZK).
- Bundle ownership transfers(pre-assigns) to other brokers upon unloading and broker shutdown.
Improved Shedding algorithm
- TransferShedder improves the unloading behavior to redistribute the load with minimal steps.
Conclusion
Extensible Load Balancer reduced the ZK dependencies in Pulsar by Pulsar native topics and table views. Along with this architectural design change, the test data shows that distributed load balance decisions, optimized load data and ownership data sharing, and new load balance algorithms with the bundle transfer option help to improve the broker load balance performance.
Last year, the pulsar community worked hard to push this load balancer improvement project out to the public, including the load balancer docs and migration steps. We very much appreciate all of the contributors to this project. We are excited to introduce this new load balancer in Pulsar 3.0 with promising performance results.
Furthermore, in addition to this load balancer improvement, there are other innovations in Pulsar 3.0. We strongly recommend checking this Pulsar-3.0 release post, and we look forward to hearing feedback and contributions from the Pulsar community.
StreamNative proudly holds the position of a major contributor to the development of Apache Pulsar. Our dedication to driving innovation within the Apache Pulsar project remains resolute, and we are steadfast in our commitment to pushing its boundaries even further.





