
Having worked on large-scale distributed systems for over a decade, I have come to embrace failure as an unavoidable reality that comes with such systems. This mantra is best captured in the following quote by the CTO of Amazon, Werner Vogels.
“Failures are a given, and everything will eventually fail over time.”
Given the sheer number of components involved in modern distributed systems, maintaining 100% uptime is nearly impossible to achieve. Therefore, when you are building an application on top of a large-scale system like Apache Pulsar, it is important to build resilience into your architecture. A necessary precondition to building a resilient application is selecting reliable software systems to serve as foundational components of your application stack, and Pulsar certainly meets this requirement.
Developing a highly-available application requires more than just utilizing fault-tolerant services such as Apache Pulsar in your software stack. It also requires immediate failure detection and resolution including built-in failover when there are data center outages.
Up until now, Pulsar clients could only interact with a single Pulsar cluster and were unable to detect and respond to a cluster-level failure event. In the event of a complete cluster failure, these clients cannot reroute their messages to a secondary/standby cluster automatically.
In such a scenario, any application that uses the Pulsar client is vulnerable to a prolonged outage since the clients could not establish a connection to an active cluster. Such an outage could result in data loss and missed business SLAs.
With the upcoming release of Pulsar 2.10, this much-needed automated cluster failover capability has been added to the Pulsar client libraries. In this blog, let’s walk through the changes you need to make inside your application code to take advantage of this new capability.
Pulsar Resiliency
Apache Pulsar’s architecture incorporates several fault-tolerant features, including: component redundancy, data replication, and its connection-aware client libraries that automatically detect and recover in the event a client disconnects from one of the brokers inside the serving layer. Connection failure detection and recovery is handled entirely inside the Pulsar client itself and is completely transparent to the application.
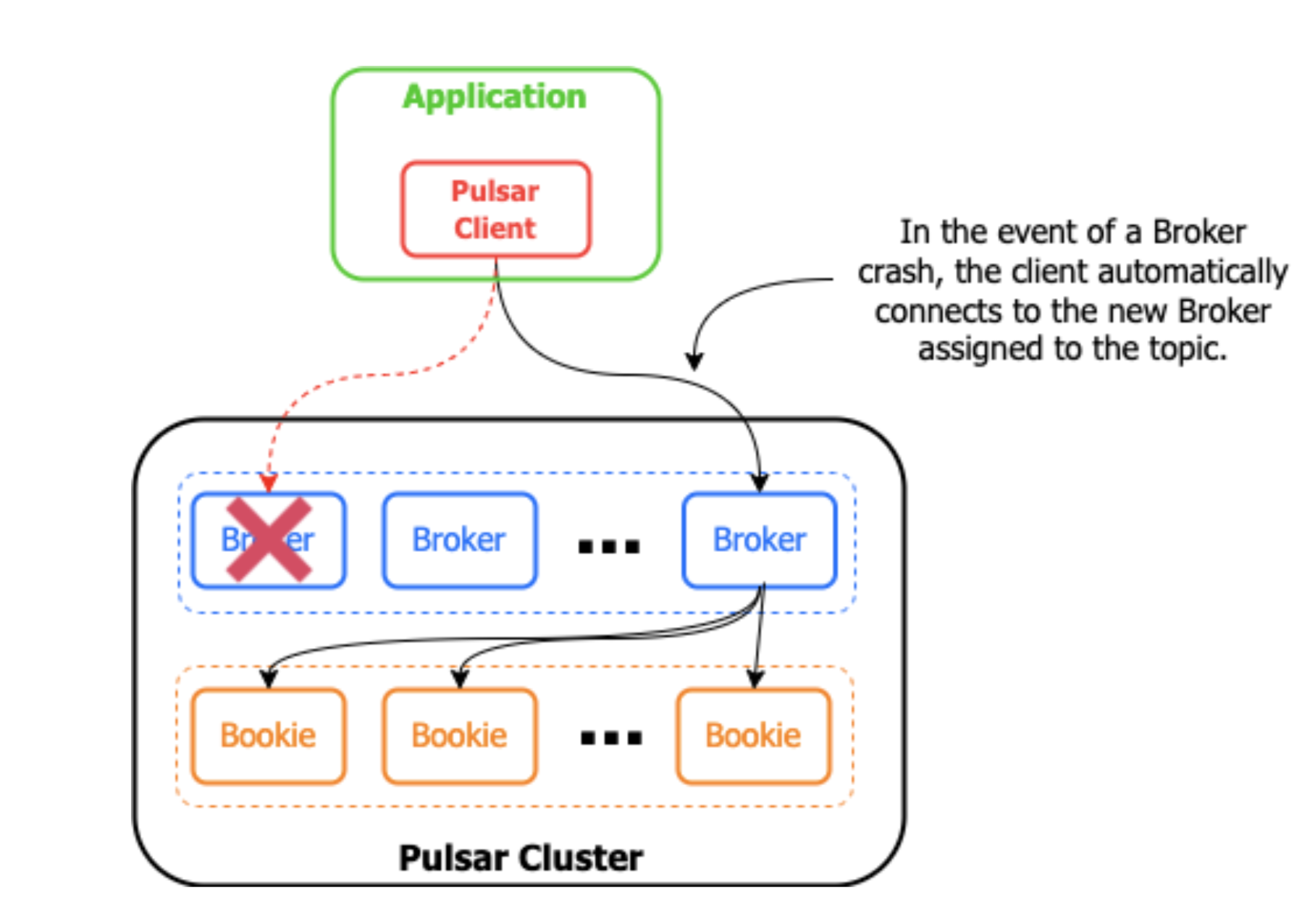
As we discussed, failures are inevitable when working with complex distributed systems. This is why Pulsar clients work intentionally on that premise. In fact, Pulsar’s automated load balancing will periodically reassign topics to different Brokers to distribute incoming client traffic more evenly. When this happens, all of the client’s reading/writing to the topic slated for reassignment will be automatically disconnected.
In this scenario, we are relying on the auto-recovery behavior of the clients to reconnect to the newly assigned Broker and continue processing without missing a beat. This transition from one Broker to another is transparent from an application perspective. No exception is raised that needs to be handled by the application.
Keep in mind that connection auto-recovery only works when the brokers are all part of the same cluster located inside the same environment. For example, in a failover scenario from an active cluster to a stand-by cluster operating in a different region, connection auto-recovery does not work. This was a big shortcoming in the Pulsar client library. Let’s explore why this is the case.
Continuous Availability
A common technique used to provide continuous-availability is to have separate cluster instances configured to run in an active/standby mode. Having redundant infrastructure in different regions helps mitigate the impact of a datacenter or cloud region failure.
In such a configuration, all traffic is routed to the “active” cluster and the data is replicated to the “standby” cluster to keep them as closely in sync as possible. This ensures that the message data is available for consumers if and when you need to switch over to the “standby” cluster.
Additionally, you must replicate all Pulsar subscriptions to ensure that consumers resume message consumption from the exact point where they left off before the failure occurred.
To achieve continuous availability: If the “active” cluster fails for any reason, all active producers and consumers should be immediately redirected to the “warm” standby cluster. This transition should be transparent to the connected applications.
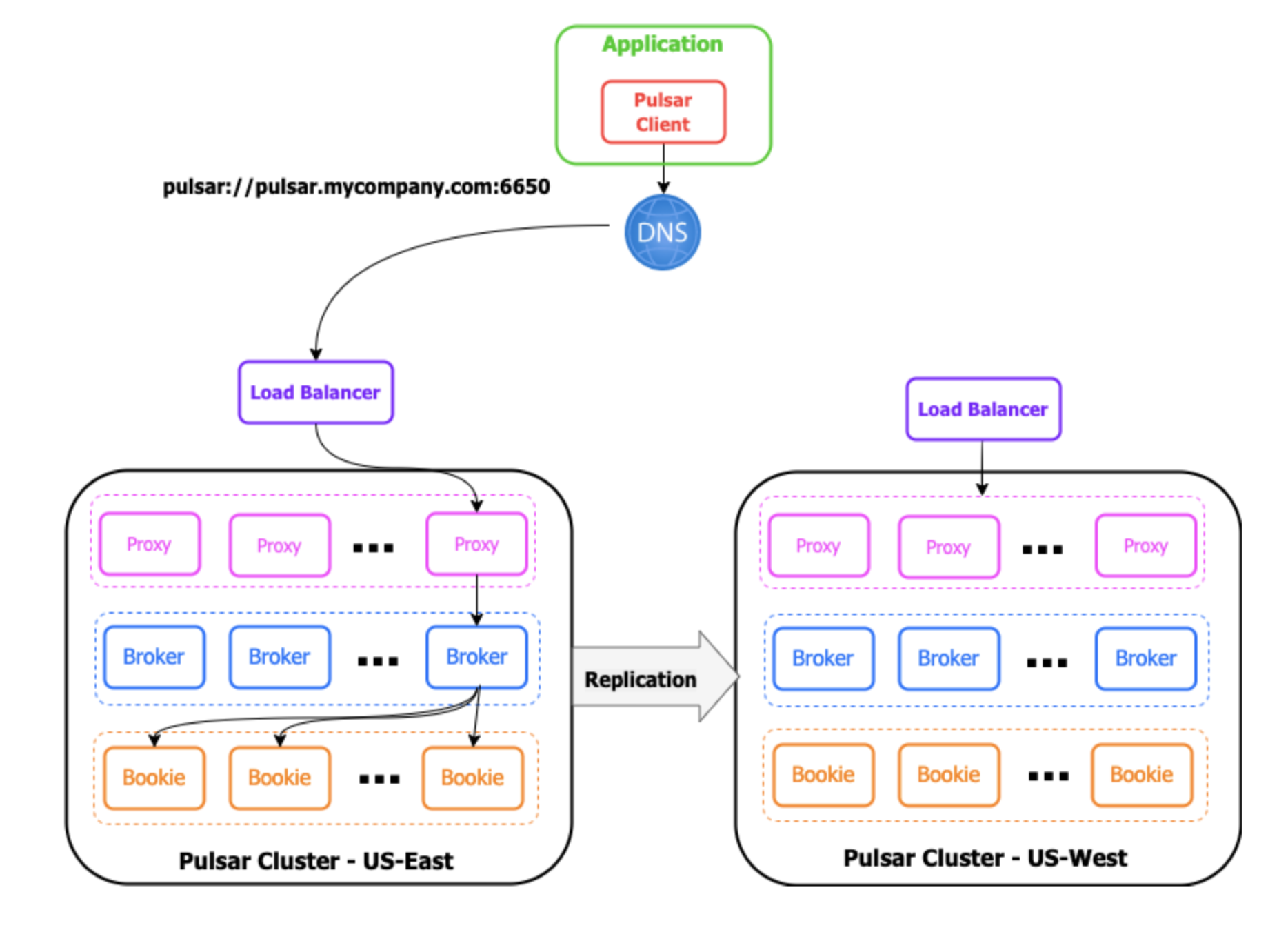 Multi-region active/stand-by Pulsar installation, data is geo-replicated between the two instances and the clients are directed to the active cluster via the DNS record for the single static URL.
This configuration relies upon a regional load balancer that routes requests to a pool of Pulsar proxies inside each cluster. These proxy instances are also stateless and able to route incoming requests, based on the topic name, to the proper Broker.
Multi-region active/stand-by Pulsar installation, data is geo-replicated between the two instances and the clients are directed to the active cluster via the DNS record for the single static URL.
This configuration relies upon a regional load balancer that routes requests to a pool of Pulsar proxies inside each cluster. These proxy instances are also stateless and able to route incoming requests, based on the topic name, to the proper Broker.
To ensure continuous availability, the Pulsar clients are configured to use a single static URL to connect to the load balancer that sits in front of the Pulsar proxies. The DNS record is updated to point to the regional load balancer of the “active” cluster, which, in turn, routes all the traffic on to the Pulsar brokers in that cluster. It doesn’t matter which proxy instance is chosen, because they all perform exactly the same function and forward the traffic to the proper Broker, based on the topic name.
Current Cluster Failover
To redirect the clients from the “active” to the standby cluster, the DNS entry for the Pulsar endpoint that the client applications are using must be updated to point to the load balancer of the standby cluster.
In theory, the clients will be re-routed to the stand-by cluster when the DNS record has been updated. However, this approach has two shortcomings:
- It requires your DevOps team to monitor the health of your Pulsar clusters and manually update the DNS record to point to the stand-by cluster when you have determined that the active cluster is down. This cutover is not automatic and the recovery time is determined by the response time of your DevOps team.
- Even after the DNS record has been changed, both the Pulsar client and the DNS system cache the resolved IP address. Therefore, it will take some additional time before the cache entries time out and the updated DNS entry is used. This creates a further delay in the client’s recovery time.
Neither of these issues are fatal. The clients will eventually get re-routed to the stand-by cluster. However, be careful to not discount the potential delay that can occur due to one or both of these issues. In fact, members of the Pulsar community have seen delays in excess of 30 minutes!
Obviously, nothing good can come from such a prolonged outage. SLAs are going to be missed, inbound data will start backing up and potentially get dropped. Ideally, you want the cutover time to be as low as possible.
Improved Cluster Failure: New Strategies
We’re pleased to announce that there are two new alternative strategies for avoiding the prolonged delay caused by the DNS change method for cluster failover included in the upcoming 2.10 release. One supports automatic failover in the event of a cluster outage, while the other enables you to control the switch-over through an HTTP endpoint.
Auto Cluster Failover Strategy
The first failover strategy, AutoClusterFailover, automatically switches from the primary cluster to a stand-by cluster in the event of a cluster outage.
This behavior is controlled by a probe task that monitors the primary cluster. When it finds the primary cluster failed for more than failoverDelayMs, it will switch the client connections over to the secondary cluster. The following code snippet shows how to construct such a client.
Map secondaryAuth =
new HashMap();
secondaryAuth.put("other", AuthenticationFactory.create(
"org.apache.pulsar.client.impl.auth.AuthenticationTls",
"tlsCertFile:/path/to/my-role.cert.pem," +
"tlsKeyFile:/path/to/my-role.key-pk8.pem"));
ServiceUrlProvider failover =
AutoClusterFailover.builder()
.primary("pulsar+ssl://broker.active.com:6651/")
.secondary(
Collections.singletonList("pulsar+ssl://broker.standby.com:6651"))
.failoverDelay(30, TimeUnit.SECONDS)
.switchBackDelay(60, TimeUnit.SECONDS)
.checkInterval(1000, TimeUnit.MILLISECONDS)
.secondaryAuthentication(secondaryAuth)
.build();
PulsarClient pulsarClient =
PulsarClient.builder()
.serviceUrlProvider(failover)
.authentication("org.apache.pulsar.client.impl.auth.AuthenticationTls",
"tlsCertFile:/path/to/my-role.cert.pem" +
"tlsKeyFile:/path/to/my-role.key-pk8.pem")
.build();
Note that the security credentials for the secondary/standby cluster are provided inside a java.util.Map, while the primary cluster authentication credentials are included in the original PulsarClientBuilder. In this particular case, even though the TLS certificates will work for both Pulsar clusters, we still need to provide them separately.
After switching to the secondary cluster, the AutoClusterFailover will continue to probe the primary cluster. If the primary cluster comes back and remains active for switchBackDelayMs, it will switch back to the primary cluster.
Controlled Cluster Failover Strategy
The other failover strategy, ControlledClusterFailover, supports switching from the primary cluster to a stand-by cluster in response to a signal sent from an external service. This strategy enables your administrators to trigger the cluster switch over.
The following code snippet shows how to construct such a client. In this particular case, the security credentials provided inside a java.util.Map are for the Pulsar client to use to authenticate with the service specified by the urlProvider property and NOT the standby Pulsar cluster.
Map header = new HashMap<>();
header.put("clusterA", "");
ServiceUrlProvider provider =
ControlledClusterFailover.builder()
.defaultServiceUrl("pulsar+ssl://broker.active.com:6651/")
.checkInterval(1, TimeUnit.MINUTES)
.urlProvider("http://failover-notification-service:8080/check")
.urlProviderHeader(header)
.build();
PulsarClient pulsarClient =
PulsarClient.builder()
.serviceUrlProvider(provider)
.build();
This client will query the urlProvider endpoint every minute to retrieve the service URL of the Pulsar cluster with which it should be interacting.
The Pulsar client expects the call to the urlProvider endpoint to return a JSON formatted message that contains not only the stand-by cluster connection URL, but also any required authentication-related parameters. An example of such a message would be as follows:
{
"serviceUrl": "pulsar+ssl://standby:6651",
"tlsTrustCertsFilePath": "/security/ca.cert.pem",
"authPluginClassName":"org.apache.pulsar.client.impl.auth.AuthenticationTls",
"authParamsString": " \"tlsCertFile\": \"/security/client.cert.pem\"
\"tlsKeyFile\": \"/security/client-pk8.pem\" "
}
Therefore, you will need to be aware of this format when you are writing the endpoint service you will be using to control the failover of your Pulsar clusters.
Conclusion
Failures are inevitable when you are continuously running any sort of software system at scale. Therefore, it is important to have a contingency plan to handle unexpected regional failures. While geo-replication of data is an important component of such a plan, it is not enough. It is equally important to have failure-aware clients that are able to detect and respond to such an outage automatically. Until now, Apache Pulsar only provided the Geo-replication mechanism.
The latest release of Apache Pulsar now provides two different types of failure-aware clients that you can use to ensure that your applications are not impacted by a regional outage. In this blog, you have learned about both of these clients, and you even have code examples to try.
Most importantly, these clients are 100% backward-compatible with your existing Pulsar Clients. This means you can replace your existing clients within your existing code base, without any problems. Currently, these new classes are only available for the Java client library, but they will be added to the other clients in the near future.
References
- PIP-121: Pulsar cluster level auto failover on client side: https://github.com/apache/pulsar/issues/13315
- Files PIP-121: Pulsar cluster level auto failover on client side: https://github.com/apache/pulsar/pull/13316/files




