
In this series of posts, I want to share some basic architectural concepts about possible anatomy of a distributed database with a shared-nothing architecture.
You can see how to leverage Apache BookKeeper features to resolve most of the challenges that come into play in a distributed system.
In the end, you can learn how this architecture has been adopted in HerdDB, a distributed embeddable SQL database written in Java.
System overview
Let's start from a high-level view of what we want to build and what properties are we requiring.
- We want a database, a storage that holds data durably and it is accessible from remote clients
- We are storing data on a cluster of machines
- Our machines do not share disks or use shared mounts, only network connections (LAN or WAN)
- Machines are expected to fail, disks can be lost at any time, but we want the service to be available to clients until a part of them is up and running
- We want to be able to add and remove machines without service interruption
- We want to have complete control over consistency
This list sounds pretty generic and there are several ways of designing systems with such capabilities.
In order to make it more concrete, let's create a concrete scenario:
- We have a SQL database with one table
- Data is replicated over N machines
- No shared disks, only network connections among the servers and between servers and clients
- We adopt the architectural pattern of a replicated state machine
Write-ahead logging
In order to support the ACID (Atomicity, Consistency, Isolation, Durability) semantics, databases use write-ahead logging.
Let's assume that a database stores a copy of a table in local volatile memory (RAM). When a client requests a write (like an UPDATE operation), the database 'logs' the action to persistent storage and writes a new value for the record to the log (WAL).
When the storage acknowledges the write (fsync), the change is applied to the in-memory copy of the table.Then the storage acknowledges the result to the client. As soon as we update the in-memory copy, other clients are able to read the new value.
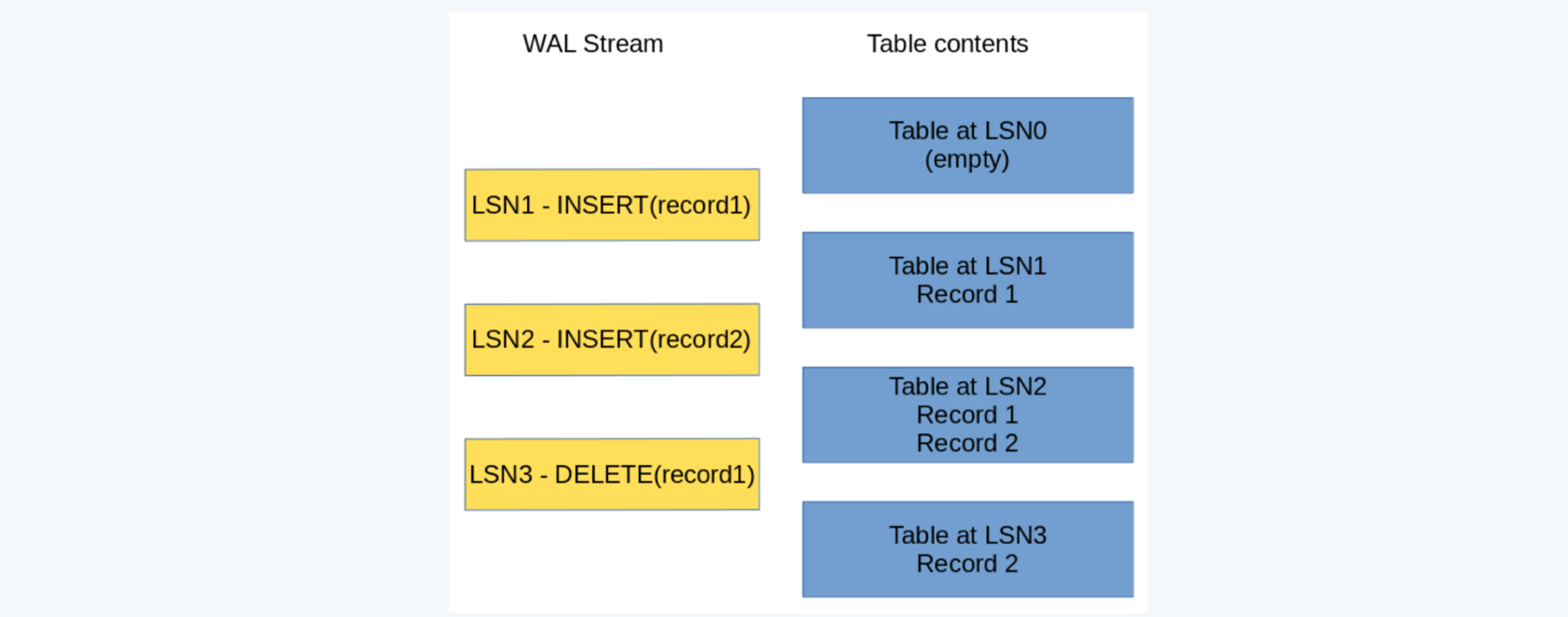
Write-ahead log stream and table contents
In the example above, the table starts empty, then we have a first write operation, INSERT (record1), that happens at LSN (log sequence number) 1. Our table now contains record1. Then we log at LSN2 another modification, INSERT (record2), now the table contains record1 and record2, then we log a DELETE (record1) at LSN3, and the table holds only record2.
When the server restarts, it performs a recovery operation, reading all of the logs and reconstructing the contents of the table, so we end up in having only record2 in the table.
If a value is on the log, we are sure that it won't be lost and any client that reads such value before any restart event are able to read again the same value.
This could not happen if we had applied the change in memory before writing to the log.
Please note that only operations that alter the contents of the table are written to the write-ahead log: we aren't logging reads.
Checkpoints
You can always reconstruct the contents of the table from the log, but you cannot store an infinite log, so it comes the time for the log to be truncated. In order to release space, this operation is usually called a checkpoint.
When your database performs a checkpoint, it flushes on durable storage the contents of the table at a given LSN.
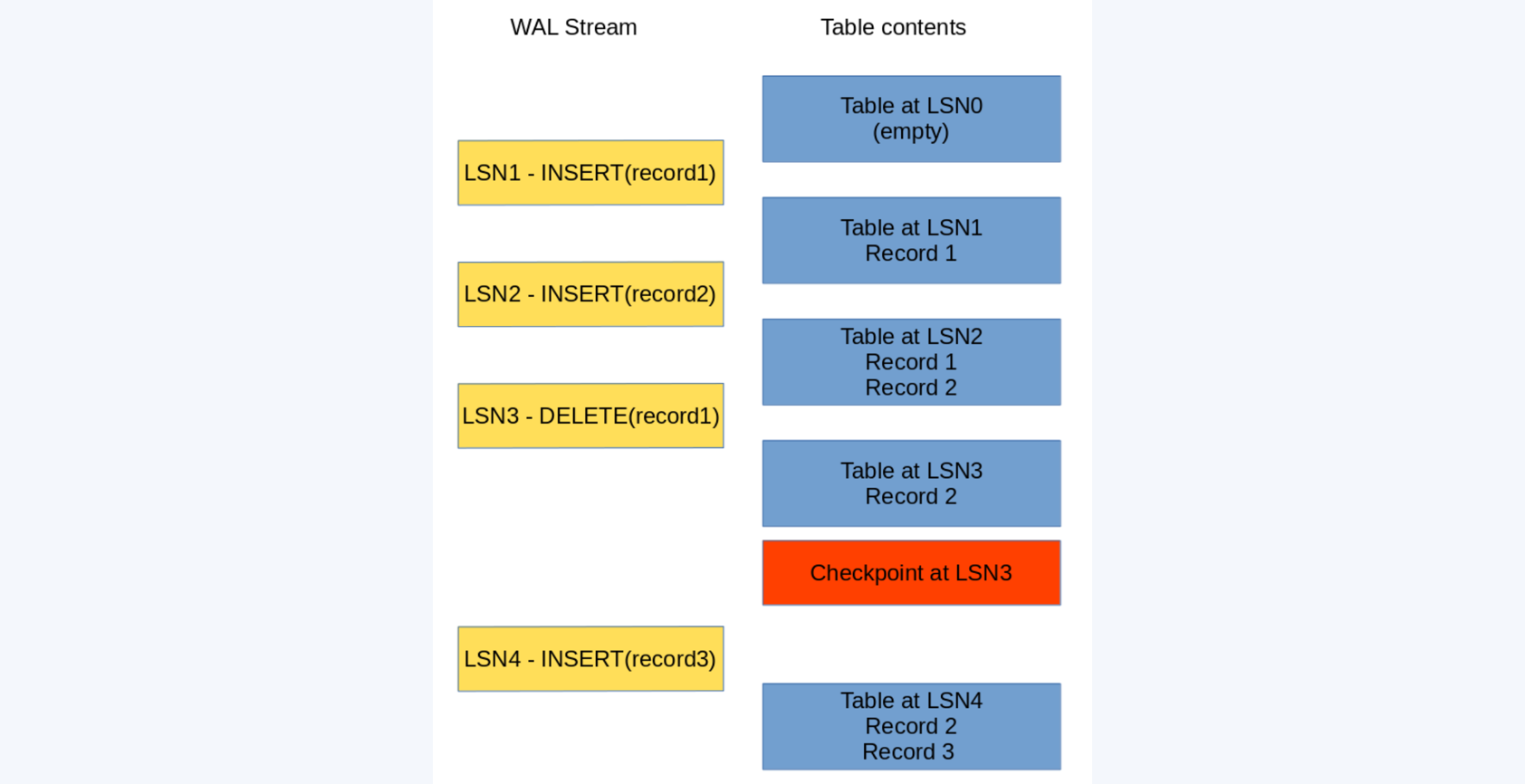
A checkpoint happens at LSN3
Now that we have persisted durably the table at LSN3, we can save resources and drop the part of the log from LSN1 to LSN3. Therefore when the server performs recovery, it has only to replay LSN4, and this in turn allows a faster start up sequence.
Where are you storing the contents of the table during the checkpoint ? You can have several strategies, for instance, you can store the contents on some local disk (remember to fsync). But if the contents of the table are really small in respect to the number of writes to the WAL (so you have many changes on the same little set of records), you can think about dumping the contents of the table to the WAL itself.
Replicated state machines
A replicated state machine is an entity, in this case the table, that is at a given state (the contents of the table) at given time (log sequence number) and the sequence of changes to the state is the same over a set of interconnected machines, so eventually each machine holds the same state.
Whenever you change one record on a machine, you must apply the same change on every other copy.
We need a total order of the changes to the state of the machine, and our write-ahead log is perfect for this purpose.
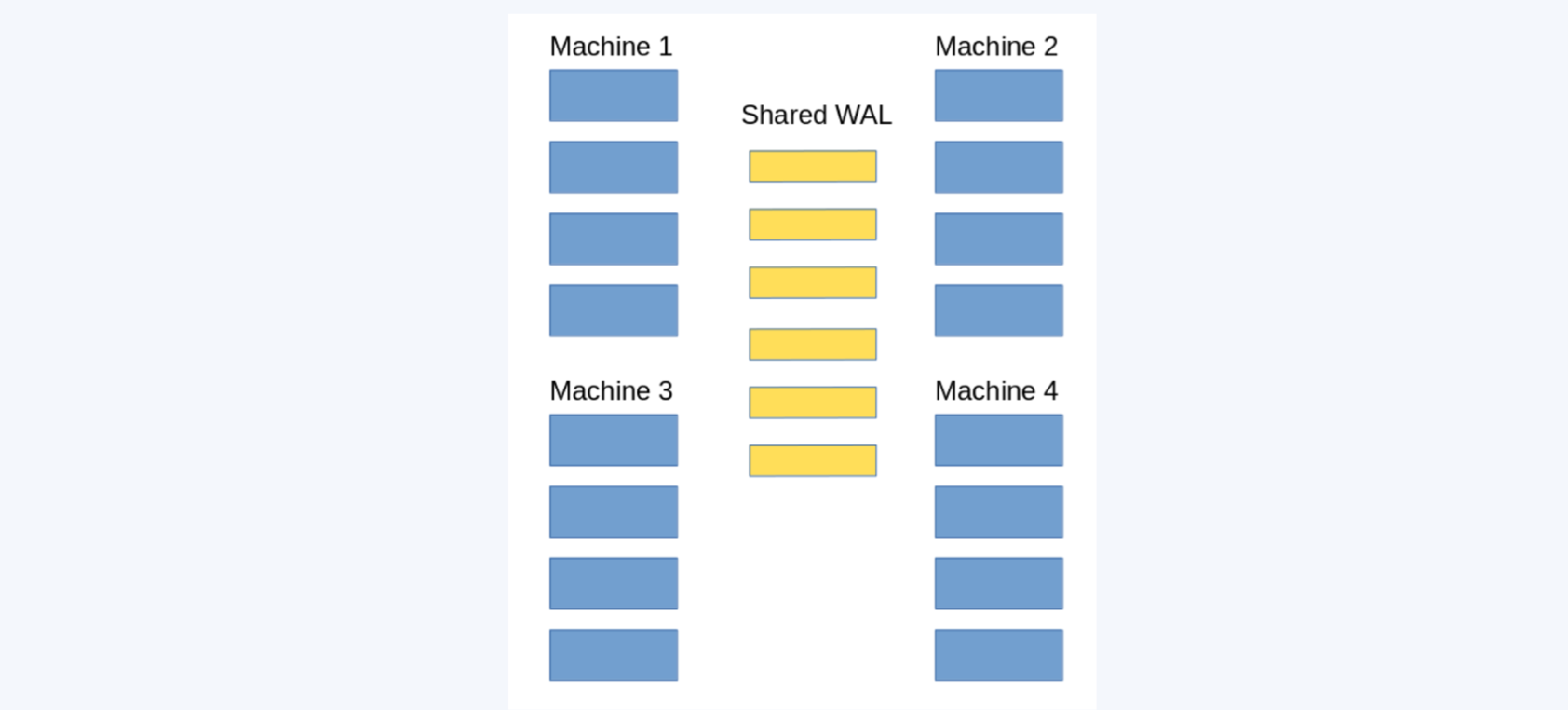
Each node has a copy of the table and the WAL is shared
In our architecture, only one node is able to change the state of the system, that is to alter the contents of the table: let's call this one the leader.
Every node has a copy of the entire table in memory. When a write occurs, it is written to the WAL and then it is made visible to clients for reads.
Other non leader nodes, the followers, tail the log, it continuously reads the changes from the log, exactly in the same order as they are issued by the leader.
Followers apply every change to their own local copy, this way they will see the same history for the table.
It is also important that every change is applied by the follower only after the same change has been acknowledged by the WAL, otherwise, followers would be in the future in respect to the leader.
Apache BookKeeper is the write-ahead log we need: it is durable and distributed. It doesn't need shared disks or remote storages, guarantee a total order of the items, and support fencing. In the next posts, I will show you how Apache Bookkeeper guarantees fulfills our needs.



