In this series of posts, I want to share some basic architectural concepts about the possible anatomy of a distributed database with a shared-nothing architecture. In the first part, we see how you can design a database as a replicated state machine. In the second part, we see how Apache BookKeeper can help us by providing powerful mechanisms to build the write ahead log of our database.
Now we are going to dig into HerdDB, a distributed database that relies on BookKeeper on implementing its own journal and deals with all of the problems we discussed in the previous posts.
Why HerdDB ?
We started HerdDB at EmailSuccess.com, a Java application that uses an SQL database to store status of email messages to deliver. EmailSuccess is an MTA (Mail Transfer Agent) that is able to handle thousands of queues with millions of messages, even with a single machine.
Now HerdDB is used in other applications, like Apache Pulsar Manager or CarapaceProxy, and we are using it in MagNews.com platform.
Initially EmailSuccess used MySQL but we need a database that runs inside the same process of the Java application for ease deployment and management, like SQLLite.
Also we needed a database that could span multiple machines and possibly leverage the intrinsic multi-tenant architecture of the system: thousands of independent queues on a few machines (usually from 1 to 10).
So here it is HerdDB ! A distributed embeddable database written in Java. Please refer to the wiki and the available documentation if you want to know more about this story.
HerdDB Data Model
An HerdDB database is made of tablespaces. Each tablespace is a set of tables and it is independent from the other tablespaces. Each table is a key-value store that maps a key (byte array) to a value (byte array).
In order to fully replace MySQL, HerdDB comes with a built in and efficient SQL Layer and it is able to support most of the features you expect from a SQL database, but with some trade-offs. We are using Apache Calcite for all of the SQL parsing and planning.
When you are using the JDBC Driver, you have only access to the SQL API, but there are other applications of HerdDB, for instance HerdDB Collections Framework uses directly the lower level model.
Each table has an SQL schema that describes columns, the primary key, constraints and indexes.
Within a tablespace, HerdDB supports joins between tables and transactions that span multiple rows and multiple tables.
For the rest of this post, we are going to talk about only the low level model:
- A tablespace is made of tables.
- A table is a dictionary that maps a binary key to a binary value.
- Supported operations on a table are: INSERT, UPDATE, UPSERT, DELETE, GET and SCAN.
- Transactions can touch multiple tables and rows within one single tablespace.
Data and Metadata
We have several layers of data and metadata.
Cluster metadata are about the overall system:
- Nodes metadata (discovery service)
- Tablespace metadata (nodes assigned to it, replication settings)
Tablespace metadata:
- Tables and indexes metadata
- Checkpoints metadata
Tablespace data:
- Snapshots of uncommitted transactions
- Data for temporary operations
- Write ahead log
Table data:
- Records
- Indexes
- Checkpoint metadata
When HerdDB runs in cluster mode, we are storing cluster metadata on Apache ZooKeeper and tablespace metadata and data on local disks; the write ahead log is on Apache BookKeeper.
Discovery service and network architecture
We have a set of machines that participate in the cluster, and we call them nodes. Each node has an ID that identifies it uniquely in the cluster.
For each node, we store on ZooKeeper all the information useful in order to locate the node, like the current network address and supported protocols (TLS availability). In this way, network addresses can easily change, in case you do not have fixed iPhone addresses or DNS names.
For each tablespace, we define a set of replica nodes. Each node stores a copy of the whole tablespace. This happens because we support queries and transactions that span over multiple records: you may access or modify many records in many tables in a single operation and this must be very efficient.
One of the nodes is elected as leader and other nodes are then named followers.
When a client issues an operation to a tablespace, it locates the leader node using tablespace metadata and the current network address using the discovery service. All of this information is on ZooKeeper and it is cached locally.
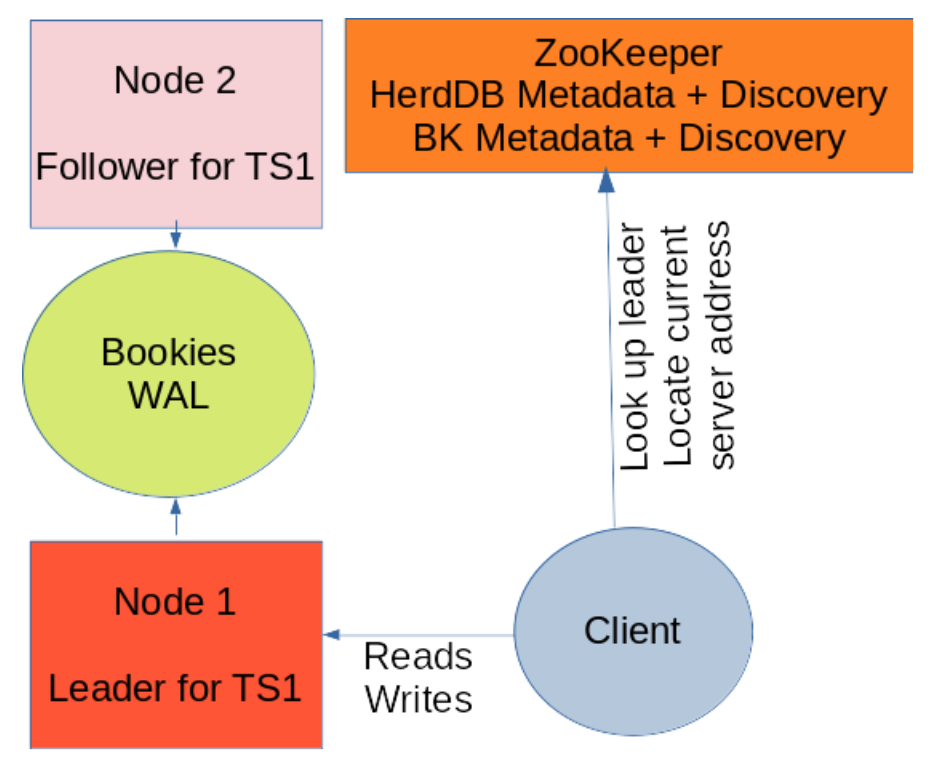
Server nodes do not talk to each other but all of the updates pass through BookKeeper.
Server-to-server communication is needed only in case of a follower node that bootstraps and it has not enough local data to recover from BookKeeper.
The Write Path
A write operation follows this flow:
- Client locates the leader node for the tablespace (metadata are cached locally).
- Client establishes a connection (connections are pooled).
- Client sends the write request.
- The node parses the SQL and plans the execution operation.
- Operation is validated and prepared for execution (row level locks, tablespace checkpoint lock, constraint validation, computation of the new value…).
- A log entry is enqueued for write to the log.
- BookKeeper sends the entry to a quorum of bookies (write quorum size configuration parameter).
- The configured number of bookies (ack quorum size configuration parameter) acknowledges the write, the BookKeeper client wakes up.
- The effects of the operation are applied to the local in memory copy of the table.
- Clean up operations are executed (release row level locks, tablespace checkpoint lock…).
- The write is acknowledged to the client.
Most of these steps are asynchronous, and this allows better throughput.
Follower nodes are continuously tailing the log: they listen for new entries from BookKeeper and they apply the same changes to the local in memory copy of the table.
We are using long-poll read mode in order to save resources. Please check BookKeeper documentation for ReadHandle#readLastAddConfirmedAndEntry.
Switch to a new leader
BookKeeper guarantees that followers will be eventually up to date with the latest version of the table but we have to implement ourselves all of the rest of the story.
We have multiple nodes. One node is the leader and the other ones are the followers. But how can we guarantee that only one node is the leader ? We must deal with network partitions.
For each tablespace, we store in ZooKeeper a structure (Tablespace metadata) that describes all of these metadata, in particular:
- Set of nodes that hold the data
- Current leader node
- Replication parameters:
- Expected number of replicas
- Maximum leader activity timeout
We are not digging into how leader election works in HerdDB. Let’s focus on the mechanism that guarantees consistency of the system.
The structure above is useful for clients and for management of the system, but we need another data structure that holds the current set of ledgers that make the log and this structure will also be another key of leadership enforcement.
We have the LedgersInfo structure:
- The list of the ledger that build the log (activeledgers)
- The ID of the first ledger in the history of the tablespace (firstledgerid)
The leader node keeps only one ledger open for writing and this is always the ledger in the tail of the lactiveledgers list.
BookKeeper guarantees that the leader is the only one that can write to the log, as ledgers can be written only once and from one client.
Each follower node uses LedgerInfo to look for data on BookKeeper.
When a new follower node starts, it checks the ID of the first ledger. If the first ledger is still on the list of active ledgers, then it can perform recovery just by reading the sequence of ledgers for the first to the latest.
If this ledger is no more in the list of active ledgers, it must locate the leader and download a full snapshot of data.
When a follower node is promoted to the leader role, it performs two steps:
- It opens all of the ledgers in the activeledgers list with the "recovery" flag, and this will in turn fence off the current leader.
- It opens a new ledger for writing.
- It adds it to the list of activeledgers.
All of the writes to the LedgersInfo are performed using ZooKeeper compare-and-set built in feature, and this guarantees that only one node is enforce its leadership.
In case of two concurrent new leaders that try to append their own ledger ID to the list, one of them will fail the write to ZooKeeper and it will fail the bootstrap.
Checkpoints
HerdDB cannot keep all of the ledgers forever, because they will prevent the Bookies from reclaiming space, so we must delete them when it is possible.
Each node, leader or follower, performs periodically a checkpoint operation:
During a checkpoint, the server consolidates its own local copy of data and the current position on the log: from this point in time the portion of log up to this position is useless and it could be deleted.
But in cluster mode you cannot do it naively:
- You cannot delete only a part of a ledger, but only whole ledgers.
- Followers are still tailing the logs, and the leader can’t delete precious data that has not already been consumer and checkpointed on every other node.
- Follower are not allowed to alter the log (only the leader can touch the LedgerInfo structure).
Current HerdDB approach is to have a configuration parameter that defines a maximum time to live of a ledger. After that time, all of the old ledgers that are useless during the checkpoint of the leader node are simply dropped.
This approach works well if you have a small set of followers (usually two) and they are up and running, which is the very case of most of HerdDB installations currently. It is not expected that a follower node is down for more than the log time to live period.
By that way, if it happens, the booting follower can connect to the leader and then download a snapshot of a recent checkpoint.
Usually an HerdDB cluster of very few machines holds tens to hundreds of tablespaces and each node is leader for some tablespaces and follower for the other ones.
Transactions
Every operation must be acknowledged by BookKeeper before applying it to the local memory and returning a response to the client. BookKeeper sends the write to every bookie in the quorum and waits. This can be very slow!
Within a transaction, the client expects that the results of the operations of the transaction will be atomically applied to the table if and only if the transaction is committed successfully.
There is no need to wait for bookies to acknowledge every write belonging to a transaction, you only have to wait and check the result of the write of the final commit operation, because BookKeeper guarantees that all of the writes before it are persisted durably and successfully.
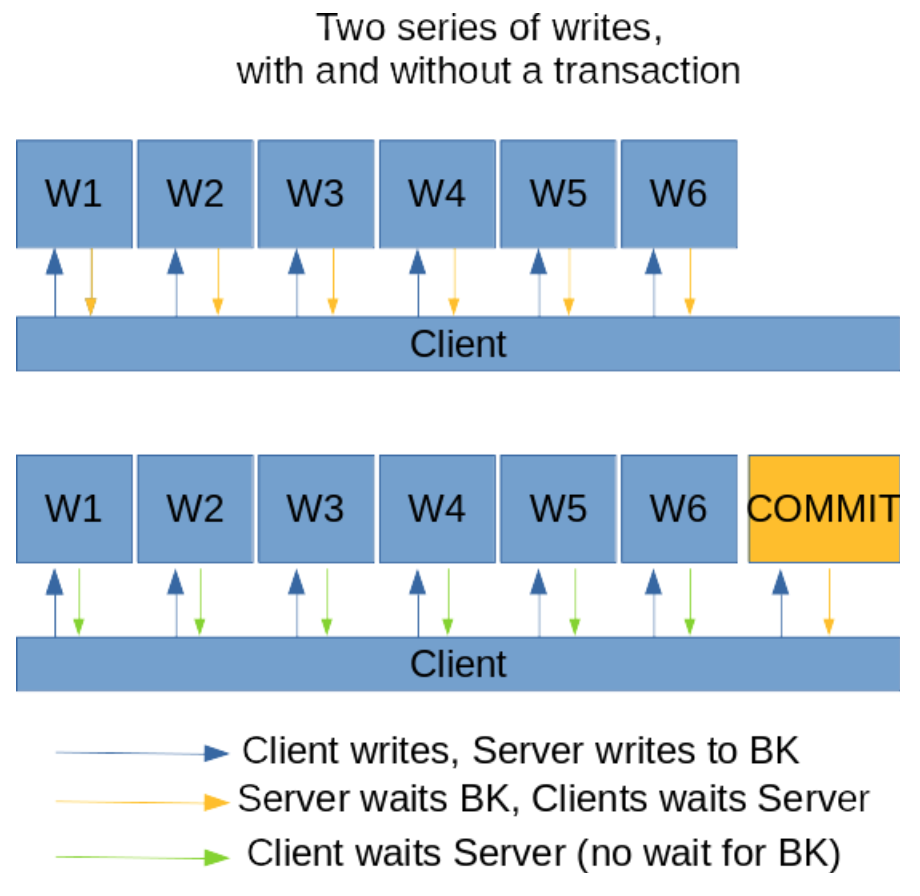
This is not simple as you could expect, for instance you must deal with the fact that a client could send a long running operation in the context of a transaction and issue a rollback command due to some application level timeout: the rollback must be written to the log after all of the other operations of the transaction, otherwise followers (and the leader node itself during self recovery) will see a weird sequence of events: "begin transaction", operations, "rollback transaction" and then other operations for a transaction that does not exist anymore.
Roll new ledgers
If the leader does not come into trouble and it is never restarted, it can keep only one single ledger open and continue to write to it.
In practice, this is not a good idea, because that ledger will grow without bounds and with BookKeeper you cannot delete parts of one ledger but only full ledgers, so Bookies won’t be able to reclaim space.
In HerdDB, we are rolling a new ledger after a configured amount of bytes. By this way, you can reclaim space quickly in case of continuous writes to the log.
But BookKeeper guarantees apply only while dealing with a single ledger. It guarantees that each write is acknowledged to the writer if and only if every other entry with an ID less than the ID of the entry has been successfully written.
When you start a new ledger, you must wait and check the outcome of all of the writes issued to the previous ledger (or at least the last one).
You could also take a look to Apache DistributedLog, that is a higher level API to Apache BookKeeper and it solves many of the problems I have discussed in this post.
Wrap up
We have seen a real application of BookKeeper, and how you can use it in order to implement the write-ahead-log of a distributed database. Apache BookKeeper and Apache ZooKeeper provide all of the tools you need to deal with consistency of data and metadata. Dealing with asynchronous operations can be tricky and you will have to deal with lots of corner cases. You also have to design your log and let it reclaim disk space without preventing the correct behaviour of follower nodes.
HerdDB is still a young project but it is running in production in mission critical applications, the community and the product grow as much as new users propose their use cases.




