Exporting data to objects in cloud storage is ubiquitous and key to almost every software architecture. Cloud storage can help to save costs by reducing on-premise hardware and software management, simplifying monitoring, and reducing the need for extensive capacity planning. Cloud storage can also protect data against ransomware by offering backup security advantages.
Pulsar users commonly store data on cloud platforms such as Amazon Simple Storage Service (Amazon S3) or Google Cloud Storage (Google GCS). Without a unified application to migrate topic-level data to cloud storage, users must write custom solutions, which can be a cumbersome task. Today, we are excited to announce the launch of the Cloud Storage sink connector, which provides users a simple and reliable way to stream their data from Apache Pulsar to objects in cloud storage.
What is Cloud Storage Sink Connector
The Cloud Storage sink connector periodically polls data from Pulsar and in turn moves it to objects in cloud storage (AWS S3, Google GCS, etc.) in either Avro, JSON, or Parquet formats without duplicates. Depending on your environment, the Cloud Storage sink connector can export data by guaranteeing exactly-once delivery semantics to its consumers.
The Cloud Storage sink connector provides partitioners that support default partitioning based on Pulsar partitions and time-based partitioning in days or hours. A partitioner is used to split the data of every Pulsar partition into chunks. Each chunk of data acts as an object whose virtual path encodes the Pulsar partition and the start offset of this data chunk. The size of each data chunk is determined by the number of records written to objects in cloud storage and by schema compatibility. If no partitioner is specified in the configuration, the default partitioner, which preserves Pulsar partitioning, is used. The Cloud Storage sink connector provides the following features:
- Ensure exactly-once delivery. Records, which are exported using a deterministic partitioner, are delivered with exactly-once semantics regardless of the eventual consistency of cloud storage.
- Support data formats with or without a Schema. The Cloud Storage sink connector supports writing data to objects in cloud storage in either Avro, JSON, or Parquet format. Generally, the Cloud Storage sink connector may accept any data format that provides an implementation of the Format interface.
- Support time-based partitioner. The Cloud Storage sink connector supports the TimeBasedPartitioner class based on the publishTime timestamp of Pulsar messages. Time-based partitioning options are daily or hourly.
- Support more kinds of object storage. The Cloud Storage sink connector uses jclouds as an implementation of cloud storage. You can use the JAR package of the jclouds object storage to connect to more types of object storage. If you need to customize credentials, you can register ʻorg.apache.pulsar.io.jcloud.credential.JcloudsCredential` via the Service Provider Interface (SPI).
Why Cloud Storage Sink Connector
Pulsar has a rich connector ecosystem, connecting Pulsar with other data systems. In August 2018, Pulsar IO was released to enable users to ingress or egress data from and to Pulsar and the external systems (such as MySQL, Kafka) by using the existing Pulsar Functions framework. Yet, there was still a strong demand from those looking to export data from Apache Pulsar to cloud storage. These users were forced to build custom solutions and manually run them.
To address these challenges and simplify the process, the Cloud Storage sink connector was developed. With the Cloud Storage sink connector, all the benefits of Pulsar IO, such as fault tolerance, parallelism, elasticity, load balancing, on-demand updates, and much more, can be used by applications that export data from Pulsar.
A key benefit of the Cloud Storage sink connector is ease of use. It enables users to run an object storage connector which supports multiple object storage service providers, flexible data format, and custom data partitioning.
Try it Out
In this section we’ll walk you through an exercise to set up the Cloud Storage sink connector and use the connector to export data to the cloud objects. This demonstration leverages AWS S3 as an example. In this demo, we run the cloud storage sink connector by using time-based partitioning and therefore group Pulsar records in Parquet format to AWS S3.
Prerequisites
- Create an AWS account and sign in to the AWS Management Console.
- Create an AWS S3 bucket. For details, see Creating a bucket.
- Obtain the credentials for the AWS S3 bucket. For details, see Creating an administrator IAM user and group (console).
Step 1: Install Cloud Storage Sink Connector and Run Pulsar Broker
- Download the NAR file of the Cloud Storage sink connector.
- Add this to the connector path in your Pulsar broker configuration file.
cp pulsar-io-cloud-storage-2.5.1.nar apache-pulsar-2.6.1/connectors/pulsar-io-cloud-storage-2.5.1.nar
- Start Pulsar broker with the configuration file.
cd apache-pulsar-2.6.1
bin/pulsar standalone
Step 2: Configure and Start Cloud Storage Sink Connector
- Define the Cloud Storage connector by creating a manifest file and save the manifest file cloud-storage-sink-config.yaml.
tenant: "public"
namespace: "default"
name: "cloud-storage-sink"
inputs:
- "user-avro-topic"
archive: "connectors/pulsar-io-cloud-storage-2.5.1.nar"
parallelism: 1
configs:
provider: "aws-s3",
accessKeyId: "accessKeyId"
secretAccessKey: "secretAccessKey"
role: ""
roleSessionName: ""
bucket: "s3-sink-test"
region: ""
endpoint: "us-standard"
formatType: "parquet"
partitionerType: "time"
timePartitionPattern: "yyyy-MM-dd"
timePartitionDuration: "1d"
batchSize: 10
batchTimeMs: 1000
Replace the accessKeyId and secretAccessKey with your AWS credentials. If you need to further control permissions, you can set the roleand roleSessionName fields.
- Start Pulsar sink locally.
$PULSAR_HOME/bin/pulsar-admin sink localrun --sink-config-file cloud-storage-sink-config.yaml
Step 3: Send Pulsar Messages
Run the following command to send Pulsar messages with the Avro schema. Currently, only Avro schema and JSON schema are available for Pulsar messages.
try (
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
Producer producer = pulsarClient.newProducer(Schema.AVRO(TestRecord.class))
.topic("public/default/test-parquet-avro")
.create();
) {
List testRecords = Arrays.asList(
new TestRecord("key1", 1, null),
new TestRecord("key2", 1, new TestRecord.TestSubRecord("aaa"))
);
for (TestRecord record : testRecords) {
producer.send(record);
}
}
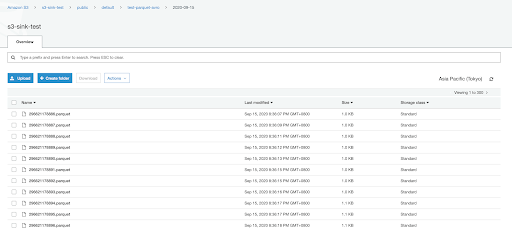
Step 4: Validate Cloud Storage Data
The view on the AWS S3 Management Console confirms the real-time upload from Pulsar to objects in AWS S3.
Conclusion
We hope to have piqued your interest in the Cloud Storage sink connector and convinced you that this is a super easy way to egress data from Pulsar to objects in cloud storage.
For any problems in the use of the Cloud Storage sink connector, you can create an issue in the connector’s GitHub repo. We will reply to you as soon as possible. Meanwhile, we look forward to your contribution to the Cloud Storage sink connector.
Have something to say about this article? Share it with us on Twitter or contact us.