
We are excited to announce that StreamNative has open-sourced Oxia: a scalable metadata store and coordination system that can be used as the core infrastructure to build large-scale distributed systems.
Oxia is available on GitHub and released under Apache License, Version 2.0.
What is Oxia
To provide better clarity, here is some helpful context:
- Coordination: Building a distributed system often involves having multiple nodes/machines/processes to discover each other or to understand who’s serving a particular resource. In this context, “coordination” refers to service discovery, leader election, and operations on distributed locks.
- Metadata: When building a stateful system whose purpose is to store data, it is often helpful to keep “metadata.” An example of metadata is a pointer to the actual data, such as pointing to the correct server and the filename/offset where the data is located.
Oxia takes a fresh approach to address the problem space typically addressed by systems like Apache ZooKeeper, Etcd, and others.
The principal design traits for Oxia are:
- Optimized for Kubernetes environment: Simplified architecture using Kubernetes primitives.
- Linearizable per-key operations: The state is replicated and sharded across multiple nodes. Atomic operations are allowed over individual keys.
- Transparent horizontal scalability: Trivial operations to add and remove capacity in the cluster.
- Optimized data plane: Supports millions of read/write operations per second.
- Large data storage capacity: Able to store hundreds of GBs (several orders of magnitudes more than current systems).
- Ephemeral records: Records whose lifecycle is tied to a particular client instance, and they are automatically deleted when the client instance is closed.
- Namespaces support: Improved control and visibility by isolating different use cases.
Motivations
Apache Pulsar has traditionally relied on Apache ZooKeeper as the foundation for all coordination and metadata.
Over the past year, through the efforts of PIP-45, the coordination and metadata system has been placed behind a pluggable interface, enabling Pulsar to support additional backends, such as Etcd.
However, there remained a need to design a suitable system that could effectively address the limitations of existing solutions like ZooKeeper and Etcd:
- Fundamental Limitation: These systems are not horizontally scalable. An operator cannot add more nodes and expand the cluster capacity since each node must store the entire data set for the cluster.
- Ineffective Vertical Scaling: Since the max data set and the throughput are capped, the next best alternative is to scale vertically (e.g., increasing CPU and IO resources to the same nodes). However, scaling vertically is a stop-gap solution that does not ultimately resolve the problem.
- Inefficient Storage: Storing more than 1 GB of data in these systems is highly inefficient because of their periodic snapshots. This snapshot process repeatedly writes the same data, stealing all the IO resources and slowing down the write operations.
Today, Pulsar can support clusters with up to 1 million topics, which is already impressive, especially when compared to what similar systems can support. However, there are a few considerations to make:
- This represents the upper limit, and there is no practical way to exceed that.
- Reaching this amount of metadata in ZooKeeper/Etcd requires careful hardware sizing, tuning, and constant monitoring.
- Even before reaching the limits, ZooKeeper performance degrades as the metadata size grows, resulting in longer topic failover times and higher long-tail latencies for some Pulsar operations.
Ultimately, the goal is for Pulsar to reach a point where a cluster with hundreds of millions of topics is something ordinary that everyone can deploy without a lot of hardware or advanced skills. This will eventually change how developers approach messaging and simplify the architecture of their applications.
Oxia is a step towards this goal, though not the only one. Multiple changes are already happening within Pulsar: such as a new load manager implementation, rehauled metric collection component, and more updates to come.
Comparison with other approaches
Other systems, such as Apache Kafka, have followed a different approach in addressing the limitation of ZooKeeper: KRaft, introduced in KIP-500, has introduced an option to remove the dependency on ZooKeeper.
We feel that this approach replicates the same ZooKeeper/Etcd architecture without significant improvements and does not remove any complexity from the system. Instead, the existing complexity of ZooKeeper has been transferred to the Kafka brokers, replacing the existing battle-tested code with new, unproven code that would just do the same job.
Designing a new system or component provides a good opportunity to examine the problem and past approaches and focus on designing a solution for the current operating environment.
Building Oxia
When designing Oxia, the architecture was adapted to take advantage of the primitives available in a Kubernetes environment rather than designing solely for a bare-metal environment.
One clear aspect since the beginning was that we didn’t want to reimplement a Paxos/Raft consensus protocol for data replication.
Instead, we bootstrap the cluster by using Kubernetes ConfigMaps as a source of cluster status checkpoint. This checkpoint is used to have a single consistent view of the Oxia cluster, its shards, and assignments.
This status is minimal in size and infrequently updated, and it enormously simplifies the task of consistent data replication.
Instead of implementing a full-blown Paxos/Raft consensus algorithm, we can decouple the problem into two parts:
- Log-replication, without fault-recovery
- The fault-recovery process
This is a similar approach to what is employed by Apache BookKeeper for its data replication mechanism.
Log replication becomes more straightforward and approachable if we strip out the fault-recovery aspect, making it easier to implement and easier to optimize for speed.
On the other hand, fault recovery is generally more complex to understand and implement. However, it only needs to be optimized for “readability” rather than speed. Furthermore, using the cluster status checkpoint makes fault recovery easier because we can assume one single process to perform the recovery and have a monotonically increasing sequencer.
In Oxia, the leader election and fault-recovery tasks are assigned to the “Coordinator” process, while multiple storage pods serve client requests and perform log replication.
Figure 1 shows the architectural diagram of an Oxia cluster running in a Kubernetes environment.
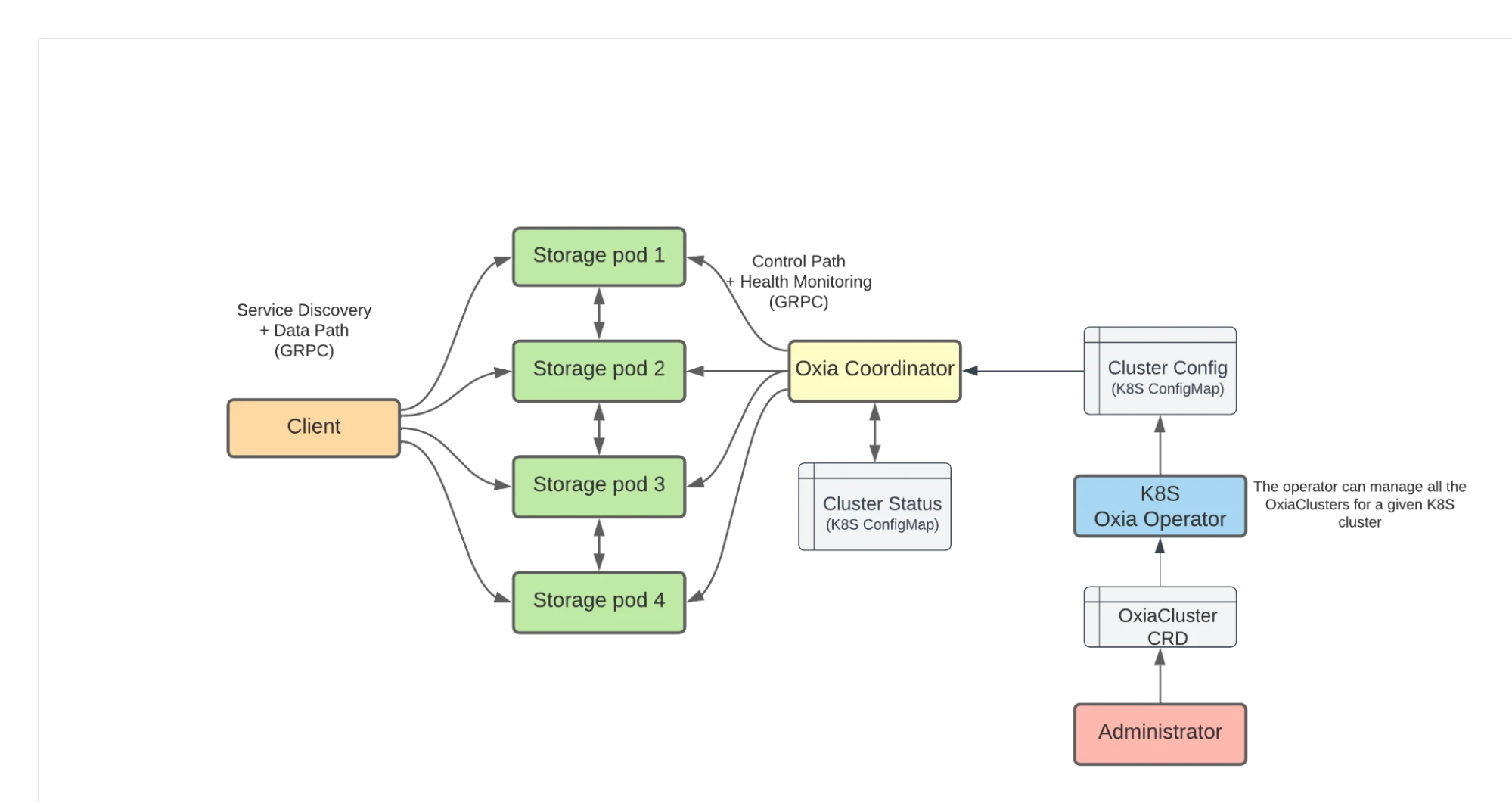 Figure 1. Oxia architecture
Figure 1. Oxia architecture
Verifying correctness
Given the goal of Oxia being a critical component of Apache Pulsar and, in general, sitting at the core of distributed systems infrastructure, testing its correctness under all conditions is of paramount importance.
We have employed three approaches to validate the correctness of Oxia:
TLA+ model
TLA+ is a high-level language for modeling distributed and concurrent systems.
We have started by defining a TLA+ model of the Oxia replication protocol. Using the TLA+ tools, we ran the Oxia model and explored all the possible states and transitions, validating that the guarantees are not violated (e.g., all the updates are replicated across all the nodes in the correct order, with no missing or duplicated entries).
Maelstrom / Jepsen test
Maelstrom is a tool that makes it easy to run a Jepsen simulation to verify the correctness of a system.
Unlike TLA+, Maelstrom works by running the actual production code, injecting different kinds of failures, and verifying that the external properties are not violated using the Jepsen library.
For Oxia, we run a multi-node Oxia cluster as a set of multiple processes running in a single physical machine. Instead of TCP networking through gRPC, we run Oxia nodes that use stdin/stdout to communicate using the JSON-based Maelstrom protocol.
Chaos Mesh
Chaos Mesh is a tool that helps to define a testing plan and generate different classes of failure in a system.
In Oxia, we use ChaosMesh to validate how the system responds to the injected failures, whether the semantic guarantees are respected, and whether the degraded performance is appropriate with respect to the injected failures.
We continuously test Oxia’s correctness as a critical component of Apache Pulsar and distributed systems infrastructure. The testing with Chaos Mesh and Maelstom is ongoing and aims to ensure the system's correctness is not violated, it functions as expected, and the performance meets expectations.
Conclusion and future work
A huge thanks to the team that created Oxia, including Dave Maughan, Andras Beni, Elliot West, Qiang Zhao, Zixuan Liu, and Cong Zhao.
Replacing ZooKeeper usage in Apache Pulsar is just the tip of the iceberg for the versatile and powerful Oxia. Our team is confident that Oxia will prove to be a valuable solution in a wide range of applications, not just limited to Pulsar but also for other distributed systems experiencing similar problems and constraints with existing solutions.
There are numerous possibilities for further enhancing Oxia: such as augmenting the Oxia operator with more intelligence or introducing automatic shard splitting and merging to adapt to changing load conditions.
We invite everyone to try Oxia and reach out with any questions, feedback, or ideas for improvement. As an open-source project, we rely on community contributions to continue advancing the technology, and your involvement will help make Oxia more widely beneficial.




