
Introduction
Do you need to quickly learn how to adapt to meet ever-expanding operations across a global reach? Do you need to figure out how to build a distributed data system in a fast, modern, open way? You're not alone.
The pressure to create and implement real-time event streaming using distributed datastores is on the rise. And, adapting and creating the architecture, techniques, and technologies to do that require education and investment. That's why we're excited to present this free Distributed Data Systems Masterclass.
Join ScyllaDB and StreamNative on Tuesday, June 21st, for a half-day event on how to build modern distributed data systems using state-of-the-art event streaming and distributed databases. In this Masterclass, our panel of experts will go in-depth on how to make the impossible possible, if not easy.
Why Take the Masterclass
Now is the time to ensure you are ready to build a system that will scale and grow with your needs, going from a trickle of data to a flood of continuous data events. The days of waiting once an hour for data to arrive are long over. You need the latest fraud detection events, logs, change data capture events from tables, real-time sensors, REST feeds, cloud data events, and so much more.
In this Masterclass, we will show you an optimal way to combine a powerful distributed data store and a unified streaming data platform.
Register today!
This is a rare opportunity to hear from developers from AWS, ScyllaDB, and StreamNative.
Meet The Speakers
Don’t miss this opportunity to learn how to build and manage enterprise-scale distributed data systems with the latest #eventstreaming and distributed #database technologies. Save your spot to attend, win swag, and have the opportunity to earn a certificate of completion!
Resources
- Registration Save your spot for the Distributed Data System Masterclass!
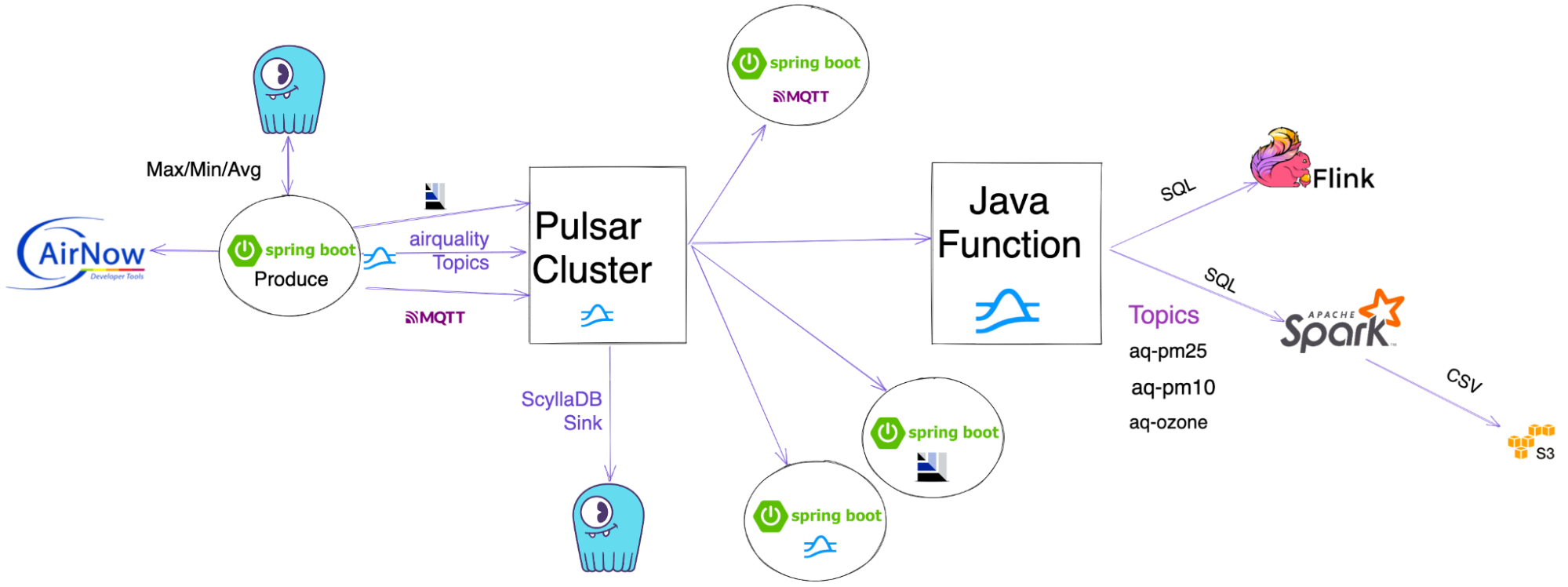
- Source Code AirQuality DataStore
More on Pulsar
- Learn the Pulsar Fundamentals: New to Pulsar? We recommend you take the self-paced Pulsar courses or instructor-led Pulsar training developed by some of the original creators of Pulsar to get started.
- Spin up a Pulsar Cluster in Minutes: If you want to try building microservices without having to set up a Pulsar cluster yourself, sign up for StreamNative Cloud today. StreamNative Cloud is the simple, fast, and cost-effective way to run Pulsar in the public cloud.
- Continued Learning: If you are interested in learning more about microservices and Pulsar, take a look at the following resources:
- 3-Part Webinar Series Building Event-Driven Microservices with Apache Pulsar. Watch the webinars on the StreamNative website.
- Pulsar Documentation How to develop Pulsar Functions
- Blog Function Mesh - Simplify Complex Streaming Jobs in Cloud




