
Abstract
Apache Pulsar™ is sometimes perceived as a complex system, due in part to its use on Apache ZooKeeper™ for metadata storage. Since its inception, Pulsar has used ZooKeeper as its distributed coordinator to store critical metadata information. This metadata information can include the broker assigned to serve a topic and the security and data retention policies for a given topic. The additional infrastructure required to run adds to the perception of Pulsar as a complex system.
In order to simplify Apache Pulsar deployments, we started a community initiative – Pulsar Improvement Plan (PIP-45) – to eliminate the ZooKeeper dependency and replace it with a pluggable framework. This pluggable framework enables you to reduce the infrastructure footprint of Apache Pulsar by leveraging alternative metadata and coordination systems based upon your deployment environment.
We’re pleased to announce that the PIP-45 code has been committed to the main branch for early access and is expected to be included in the upcoming 2.10 release. For the first time, you can run Pulsar without ZooKeeper.

Unlike Apache Kafka’s ZooKeeper replacement strategy, the goal of this initiative is not to internalize the distributed coordination functionality within the Apache Pulsar platform itself. Instead, it will allow users to replace ZooKeeper with an alternative technology that is appropriate for their environment.
Users now have the option of using lightweight alternatives that retain the metadata in-memory or on local disk for non-production environments. This allows developers to reclaim the computing resources previously required to run Apache ZooKeeper on their development laptop.
For production environments, Pulsar’s pluggable framework will enable them to utilize technologies that are already running inside their software stack as an alternative to ZooKeeper.
As you can imagine, this initiative consists of multiple steps, many of which have already been successfully implemented. I will walk you through the steps on the roadmap that have been completed thus far (Step 1-4) and outline the work that still needs to be done (Step 5-6). Please note that the features discussed in this blog are in the beta stage and are subject to change in the future.

PIP-45 provides a technology-agnostic interface for both metadata management and distributed coordination, thereby providing the flexibility to use systems other than ZooKeeper to fulfill these roles.
The ZooKeeper client API has historically been used throughout the Apache Pulsar codebase, so we first needed to consolidate all these accesses through a single, generic MetadataStore interface. This interface is based on the needs that Pulsar has in interacting with metadata and with the semantics offered by existing metadata stores, such as ZooKeeper and etcd.
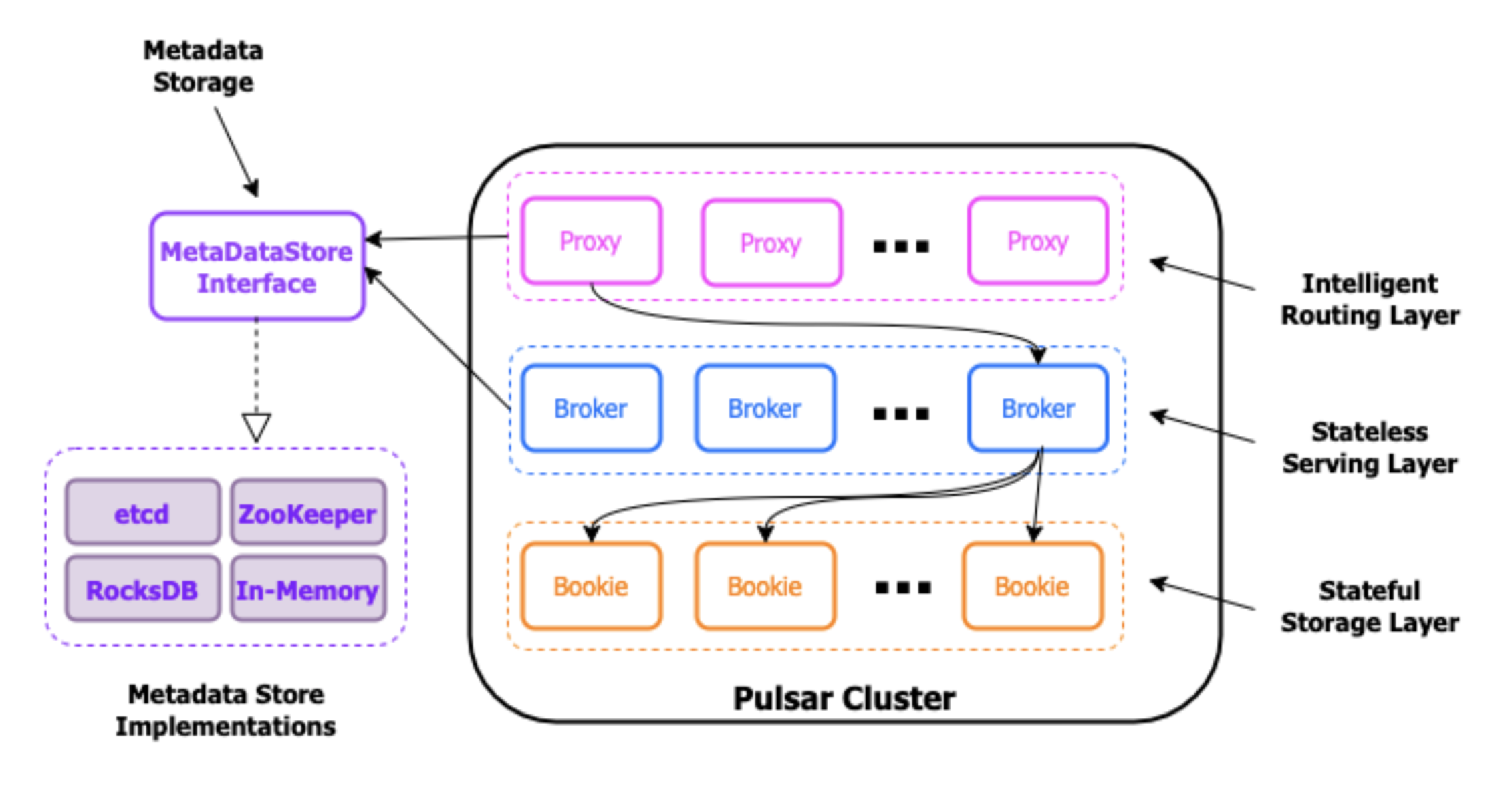
Figure 1: Replacing the direct dependency on Apache ZooKeeper with an interface permits the development of different implementations of the MetadataStore and provides the flexibility to choose the right one for your environment.
Not only does this approach decouple Pulsar from the ZooKeeper APIs, but it also creates a pluggable framework in which various implementations of these interfaces can be used interchangeably based on the deployment environment.
These new interfaces allow Pulsar users to easily swap out Apache ZooKeeper for other metadata and coordination service implementations based upon the value of the metadataURL configuration property inside the broker configuration file. The framework will automatically instantiate the correct implementation class based on the prefix of the URL. For example, a RocksDB implementation will be used if the metadataURL configuration property starts with the rocksdb:// prefix.

Once these interfaces were defined, a default implementation based on Apache ZooKeeper was created to provide a smooth transition for existing Pulsar deployments over to the new pluggable framework.
Our primary goal of this phase was to prevent any breaking changes for users with existing Pulsar deployments who want to upgrade their Pulsar software to a newer version without replacing Apache ZooKeeper. Therefore, we needed to ensure that the existing metadata currently stored in ZooKeeper could be kept in the same location and in the same format as before.
The ZooKeeper-based implementation allows users to continue to use Apache ZooKeeper as the metadata storage layer if they choose, and is currently the only production-quality implementation available until the etcd version is completed.

After addressing the backward compatibility concerns of these changes, the next step was to provide a non-ZooKeeper based implementation in order to demonstrate the pluggability of the framework. The easiest path for proving out the framework was a RocksDB-based implementation of the MetaDataStore that could be used in standalone mode.
Not only did this demonstrate the ability to swap in different MetaDataStore implementations, but it also significantly reduced the amount of resources required to run a completely self-contained Pulsar cluster. This has a direct impact on developers who choose to run Pulsar locally for development and testing, which is typically done inside a Docker container.

Another use case that would benefit greatly from scaling down the metadata store is unit and integration testing. Rather than repeatedly incurring the cost of spinning up a ZooKeeper cluster in order to perform a suite of tests and then tearing it down, we found that an in-memory implementation of the MetaDataStore API is more suited for this scenario.
Not only are we able to reduce the amount of resources required to run the complete suite of integration tests for the Apache Pulsar project, but we are also able to reduce the time to run the tests as well.
Utilizing the in-memory implementation of the MetaDataStore API significantly reduces the build and release cycle of the Apache Pulsar project, allowing us to build, test, and release changes to the community more quickly.

Given that Apache Pulsar was designed to run in cloud environments, the most obvious replacement option for ZooKeeper is etcd, which is the consistent and highly-available key-value store used as Kubernetes' backing store for all cluster data.
In addition to its vibrant and growing community, wide-spread adoption, and performance and scalability improvements, etcd is readily available inside Kubernetes environments as part of the control plane. Since Pulsar was designed to run inside Kubernetes, most production deployments will have direct access to an etcd instance already running in their environment. This allows you to reap the benefits of etcd without incurring the operational costs that come with ZooKeeper.
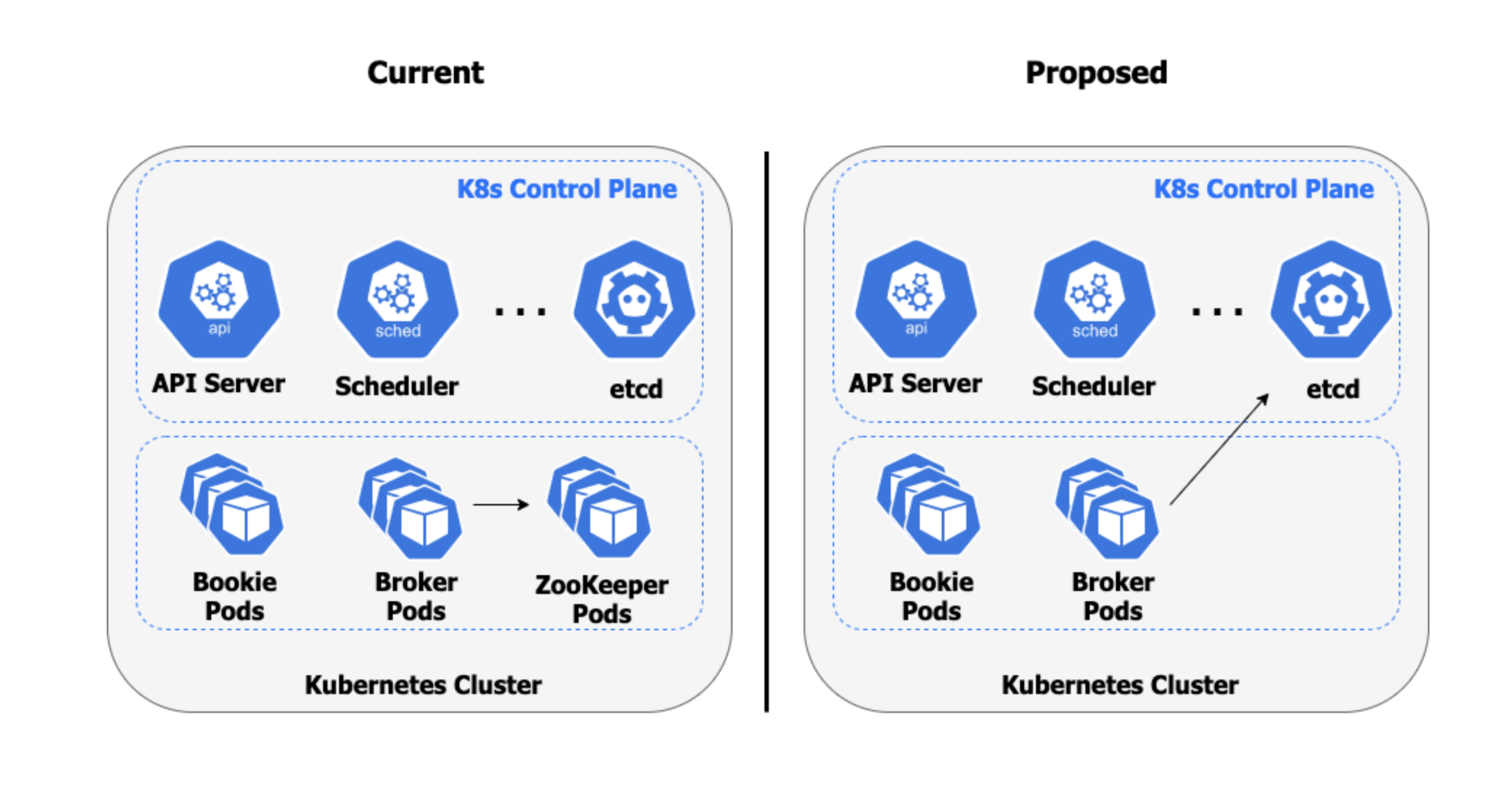
Leveraging the existing etcd service running inside the Kubernetes cluster to act as the metadata store does away with the need to run ZooKeeper entirely. Not only does this reduce the infrastructure footprint of your Pulsar cluster, but it also eliminates the operational burden required to run and operate an complex distributed system
We are particularly excited about the performance improvements we anticipate from etcd, which was designed to solve many of the issues associated with Apache ZooKeeper. For starters, it was written entirely in Go, which is generally considered a much more performant programming language than ZooKeeper’s primary language Java.
Additionally, etcd uses the newer Raft consensus algorithm which is equivalent to the Paxos algorithm used by ZooKeeper in terms of fault tolerance and performance. However, it is much easier to understand and implement than the ZaB protocol used by ZooKeeper.
The biggest difference between etcd’s Raft implementation and Kafka’s (KRaft) is that the latter uses a pull-based model for updates, which has a slight disadvantage in terms of latency1. The Kafka version of the Raft algorithm is also implemented in Java, which can suffer from prolonged pauses during garbage collection. This is not an issue for etcd’s Go-based Raft implementation.

Today, the biggest obstacle to scaling a Pulsar cluster is the storage capacity of the metadata layer. When using Apache ZooKeeper to store this metadata, it must be retained in-memory in order to provide reasonable latency performance. This is best characterized by the phrase ‘the disk is death to ZooKeeper”2.
Instead of the hierarchical tree structure used by ZooKeeper, the data in etcd is stored in a b-tree data structure, which is stored on disk and mapped to memory to support low-latency access.
The significance of this is that it effectively increases the storage capacity of the metadata layer from memory-scale to disk-scale, allowing us to store a significantly larger amount of metadata. In the case of ZooKeeper vs. etcd, the increase extends from a few gigabytes of memory in Apache ZooKeeper to over 100GB of disk storage inside etcd3.
What’s Next
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community that continues to drive innovation and improvements to the platform as demonstrated by the PIP-45 project.
- For those of you looking to get started right away with a ZooKeeper-less Pulsar installation, you can download the latest version of Pulsar and run it in standalone mode as outlined here or here.
- Take the 2022 Apache Pulsar User Survey here and let the community know what improvements you’d like to see next. You could win one of five $50 Visa gift cards!
- Start your on-demand Pulsar training today with StreamNative Academy.
References
- PIP-117: Change Pulsar standalone defaults
- Dzone Article - Apache ZooKeeper vs. etcd3
- CNCF Article - Performance optimization of etcd in web scale data scenario




