We are very glad to see the Apache Pulsar community has successfully released the wonderful 2.4.0 release after a few months of accumulated hard works. It is a great milestone for this fast-growing project and the whole Pulsar community. Here is a selection of some of the most interesting and important features the community added to this new release.
Core Pulsar
The following are the core development updates of Pulsar 2.4.0.
PIP-26: Delayed or scheduled message delivery
Delayed message delivery and scheduled message delivery are commonly seen in the traditional messaging systems. A producer can specify a message to be delivered after a given delayed duration or at a scheduled time. The message is only dispatched to a consumer after time criteria is fully satisfied.
Pulsar introduces these two functionalities in 2.4.0 for the consumers of shared subscriptions. The following two examples demonstrate how to use these two features.
Example for delayed message delivery
The following example shows how to deliver messages after 3 minutes.
producer.newMessage()
.deliverAfter(3L, TimeUnit.Minute)
.value(“Hello Pulsar after 3 minutes!”)
.send();
Example for scheduled message delivery
The following example shows how to deliver messages at 11pm on 06/27/2019.
producer.newMessage()
.deliverAt(new Date(2019, 06, 27, 23, 00, 00).getTime())
.value(“Hello Pulsar at 11pm on 06/27/2019!”)
.send();
Note that the messages sent by deliverAfter or deliverAt will not be batched even batching is enabled at a producer side.
Pulsar broker uses a DelayedDeliveryTracker for tracking the delayed delivery of messages for a particular subscription. The current DelayedDeliveryTracker holds the delayed messages in an in-memory priority queue. So you have to plan for the memory usage when enabling the delayed delivery feature. A persistent hash-wheel based implementation was discussed in the community and is planned to add in the future to support a wider range of delay durations.
To learn more about the design of delayed message delivery, see PIP-26.
PIP-34: Key_Shared subscription
Prior to 2.4.0 release, Pulsar only supports 3 subscription modes, Exclusive, Failover and Shared. Both Exclusive and Failover subscription modes are streaming subscription modes. In such modes, a Pulsar partition can only be assigned to one consumer of the subscription to consume and the messages are dispatched in partition order. In contrast, the Shared subscription mode dispatches the messages of a single partition to multiple consumers in a round-robin fashion. Shared subscription is also known as queuing (or worker-queue) subscription mode.
In Exclusive and Failover subscriptions, the ordering of the messages is guaranteed on per partitions basis. However, the parallelism of the consumption is limited by the number of partitions of the topic. In contrast, the consumption parallelism of a Shared subscription can go beyond the number of partitions, but it doesn’t have any ordering guarantees.
In a lot of use cases such as change data capture (aka CDC) for distributed databases, applications require both the scalability of Shared subscription to increase the number of consumers for high throughput and the ordering guarantees provided in Exclusive or Failover subscription. Key_Shared subscription is introduced in 2.4.0 to meet this requirement.
In Key_Shared subscription, there can be more consumers than partitions. And the messages of the same key are routed to one consumer of the subscription.
The following example shows how to use Key_Shared subscription.
client.newConsumer()
.topic(“topic”)
.subscriptionType(SubscriptionType.Key_Shared)
.subscriptionName(“key-shared-subscription”)
.subscribe();
If you are interested in learning the design details of Key_Shared subscription, see PIP-34.
There are more cool features about Key_Shared subscription planned for 2.5.0 release. If you are interested in this feature or would like to contribute to it, you can follow the GitHub issue #4077 and discuss your ideas with Pulsar committers.
PIP-36: Configure max message size at broker side
Previously, Pulsar limits the max message size (aka MaxMessageSize) to 5 MB. This setting was hardcoded at Pulsar encoder and decoder. Administrators cannot adjust this setting by modifying the broker configuration. But in some use cases, for example, when capturing change events from databases, a change event might be larger than 5 MB. These change events cannot be produced to Pulsar successfully.
Pulsar introduces a setting at broker configuration in 2.4.0 release. This setting allows administrators to configure a different value for the max message size. Additionally, Pulsar introduces a new field max_message_size in the CommandConnected response that brokers send back to clients when they connect. Then Pulsar clients are able to learn the MaxMessageSize that each broker supports and configure the batching buffer accordingly.
You need 2.4.0 release for both brokers and clients to leverage this feature.
Note that although Pulsar allows configuring max message size, it doesn’t mean it is recommended to configure the setting to an arbitrary large value. Because a very large max message size hurts IO and resource efficiency. There are also multiple PIPs tackling supporting arbitrary large sized messages by chunking the large messages into smaller chunked messages. These PIPs are:
You can follow the GitHub issue, subscribe the Pulsar mailing lists or join the Pulsar slack channels to receive development updates about these features.
PIP-33: Replicated subscription
Geo-replication is one of the best features that Pulsar provides outperforming other messaging or streaming systems in the market. In a geo-replicated Pulsar instance, a topic can be configured to be replicated across multiple regions (for example, us-west, us-east and eu-central). The topic is presented as a virtual global entity in which messages can be published and consumed from any of the configured cluster.
However, the only limitation is that subscriptions are currently local to the cluster in which they are created. That says, the subscription state is NOT replicated across regions. If a consumer reconnects to a new region, it triggers the creation of a new unrelated subscription, albeit with the same name. The subscription will be created at the tail of the topic in the new region (or at the beginning, depending on its SubscriptionInitialPosition configuration) and at the same time, the original subscription will be left dangling in the previous region.
Pulsar introduces Replicated Subscription in 2.4.0. It added a mechanism to keep subscription state in-sync between multiple geo-replicated regions, within a sub-second framework.
You can configure your consumer to enable replicated subscription by setting replicateSubscriptionState to be true. The code example is shown as below:
Consumer consumer = client.newConsumer(Schema.STRING)
.topic("my-topic")
.subscriptionName("my-subscription")
.replicateSubscriptionState(true)
.subscribe();
If you are interested in learning the design details about replicated subscription, see PIP-33.
Security
PIP-30: Mutual authentication and Kerberos support
Pulsar supports pluggable authentication mechanisms, such as TLS Authentication, Athenz and JSON Web Tokens. However all the provided authentication mechanisms are one-step authentication. The current authentication abstraction is not able to support mutual authentication between client and server, such as SASL. PIP-30 changes the interface to support mutual authentication. The Kerberos Authentication was implemented using the newly changed authentication interfaces.
If you are interested in learning the implementation details, see PIP-30. If you are interested in trying the kerberos authentication, follow the instructions documented at Pulsar website.
Pulsar Functions
Go Functions
Prior to 2.4.0, users can only write Pulsar functions using Java or Python. In 2.4.0, Pulsar starts supporting writing Pulsar functions using the popular Golang.
The exclamation example of Pulsar Functions written in Golang is shown below.
import (
"fmt"
"context"
"github.com/apache/pulsar/pulsar-function-go/pf"
)
func HandleRequest(ctx context.Context, in []byte) error {
fmt.Println(string(in) + "!")
return nil
}
func main() {
pf.Start(HandleRequest)
}
Go Function support in 2.4.0 is an MVP (minimum viable product). There are more features planned in 2.5.0 for Go Function to align with the features available in Java/Python Function.
If you are interested in learning the implementation details of Go Function, see PIP-32. If you are interested in contributing to Go Function, follow the Github issue #3767 and discuss your ideas with Pulsar committers.
Schema
Pulsar introduced native schema support and provided a built-in schema registry since 2.0.0 release. After a few successful releases, Pulsar Schema has become more and more mature. Especially in 2.4.0, there are a lot of changes happen around Pulsar Schema. Here are a few highlights for them.
Schema versioning
Prior to 2.4.0, Pulsar clients only use the latest version of schema or the provided schema for encoding and decoding Pulsar messages. Hence it didn’t handle well on encoding and decoding Pulsar messages with schema evolution.
Issue #4646 introduced versioned schema reader to deserialize Pulsar messages using correct version of schema and handle schema evolution properly.
Transitive compatibility check strategies
Prior to 2.4.0, Pulsar Schema only supported ALWAYS_COMPATIBLE, ALWAYS_INCOMPATIBLE, BACKWARD, FORWARD and FULL compatibility check strategies. BACKWARD, FORWARD and FULL strategies only check the new schema with the last schema. However, it is not enough. Issue #4170 introduced three transitive check strategies to check the compatibility with all existing schemas. These transitive strategies are:
- BACKWARD_TRANSITIVE: Consumers using the new schema can read messages produced by all previous schemas, not just the last schema. For example, if there are three schemas for a topic that change in order V1, V2, and V3, then BACKWARD_TRANSITIVE compatibility ensures that consumers using the new schema V3 can process data written by the producers using the schema V3, V2, or V1.
- FORWARD_TRANSITIVE: The messages produced with a new schema can be read by consumers using all previously registered schemas, not just the last schema. For example, if there are three schemas for a topic that change in order V1, V2, and V3, then FORWARD_TRANSITIVE compatibility ensures that data written by the producers using the new schema V3 can be processed by the consumers using the schema V3, V2, or V1.
- FULL_TRANSITIVE: The new schema is forward and backward compatible with all previously registered schemas, not just the last one. For example, if there are three schemas for a topic that change in order V1, V2, and V3, then FULL_TRANSITIVE compatibility ensures that the consumers using the new schema V3 can process data written by the producers using the schema V3, V2, and V1, and data written by the producers using the new schema V3 can be processed by the consumers using the schema V3, V2, and V1.
The completed list of compatibility check strategies is shown below.
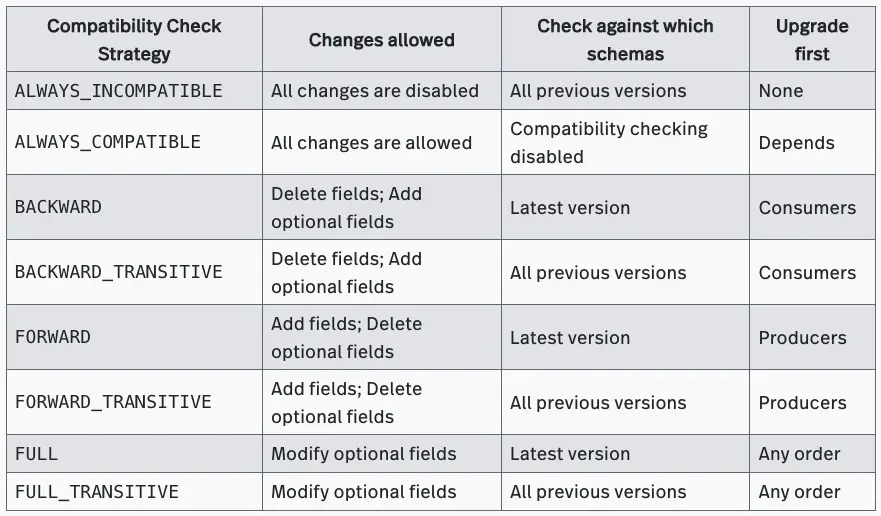
For more information, see Pulsar Schema.
GenericSchema and AutoConsume
Prior to 2.4.0, Pulsar only supported constructing schemas using static POJOs. This is convenient for applications that can know the schema ahead of time. However, in some use cases (for example, CDC - change data capture), applications don’t know the schema ahead of time. In such use cases, there is no way for applications to declare the schema programmably or dynamically. Pulsar resolves the problem by introducing GenericSchema and GenericRecord in 2.4.0.
You can declare a schema programmably by using GenericSchemaBuilder. The code example of constructing a generic schema is shown below:
RecordSchemaBuilder recordSchemaBuilder = SchemaBuilder.record("schemaName");
recordSchemaBuilder
.field("intField")
.type(SchemaType.INT32);
SchemaInfo schemaInfo = recordSchemaBuilder.build(SchemaType.AVRO);
Schema schema = Schema.generic(schemaInfo);
After you declared a generic schema, you can build the records programmatically. The code example of building a generic record is shown below:
Producer producer = client.newProducer(Schema.generic(schemaInfo)).create();
producer.newMessage().value(schema.newRecordBuilder()
.set("intField", 32)
.build()).send();
If you don’t know the schema of a topic, you can use AUTO_CONSUME to consume the topic into GenericRecord. The GenericRecord will provide the schema associated with this record. The example of using AUTO_CONSUME is shown below:
Consumer pulsarConsumer = client.newConsumer(Schema.AUTO_CONSUME())
…
.subscribe();
Message msg = consumer.receive() ;
GenericRecord record = msg.getValue();
KeyValue Schema
KeyValue Schema was first introduced to Pulsar in 2.3.0 release. The first implementation of KeyValue schema encoded a key/value pair together into the payload of a message and it didn’t store key schema and value schema.
In 2.4.0, Pulsar stores both key and value schemas as the schema data in KeyValue schema, so Pulsar can handle the schema evaluation on both key and value. Additionally, Pulsar introduces a new encoding mode that encodes key into the key part of a message and value into the payload part of a message. This allows leverage Pulsar features related to message keys.
The example of constructing a key/value schema with SEPARATED encoding type is shown below:
Schema> kvSchema = Schema.KeyValue(
Schema.INT32,
Schema.STRING,
KeyValueEncodingType.SEPARATED
);
More information
- Pulsar 2.4.0 release notes, click here.
- If you are interested in Pulsar community news, Pulsar development details, and Pulsar user stories on production, follow StreamNative Medium or @streamnativeio on Twitter.
- If you are interested in Pulsar examples, demos, tools and extensions, check out StreamNative GitHub.




