
Note: This post was published in 2020 presenting StreamNative’s response to Confluent’s article “Benchmarking Apache Kafka, Apache Pulsar, and RabbitMQ: Which is the Fastest?” (2020). For the latest Pulsar vs. Kafka performance comparison, read our 2022 Benchmark Report. For a brief overview of these systems, see our review of Pulsar vs. Kafka (part 1, part 2).
Executive Summary
Today, many companies are looking at real-time data streaming applications to develop new products and services. Organizations must first understand the advantages and differentiators of the different event streaming systems before they can select the technology best-suited to meet their business needs.
Benchmarks are one method organizations use to compare and measure the performance of different technologies. In order for these benchmarks to be meaningful, they must be done correctly and provide accurate information. Unfortunately, it is all too easy for benchmarks to fail to provide accurate insights due to any number of issues.
Confluent recently ran a benchmark to evaluate how Kafka, Pulsar, and RabbitMQ compare in terms of throughput and latency. According to Confluent’s blog, Kafka was able to achieve the “best throughput” with “low latency” and RabbitMQ was able to provide “low latency” at “lower throughputs”. Overall, their benchmark declared Kafka the clear winner in terms of “speed”.
While Kafka is an established technology, Pulsar is the top streaming technology of choice for many companies today, from global corporations to innovative start-ups. In fact, at the recent Splunk summit, conf20, Sendur Sellakumar, Splunk’s Chief Product Officer, discussed their decision to adopt Pulsar over Kafka:
"... we've shifted to Apache Pulsar as our underlying streaming. It is our bet on the long term architecture for enterprise-grade multi-tenant streaming." - Sendur Sellakumar, CPO, Splunk
This is just one of many examples of companies adopting Pulsar. These companies choose Pulsar because it provides the ability to horizontally and cost effectively scale to massive data volumes, with no single point of failure, in modern elastic cloud environments, like Kubernetes. At the same time, built-in features like automatic data rebalancing, multi-tenancy, geo-replication, and tiered storage with infinite retention, simplify operations and make it easier for teams to focus on business goals.
Ultimately, developers are adopting Pulsar for its features, performance, and because all of the unique aspects of Pulsar, mentioned above, make it well suited to be the backbone for streaming data.
Knowing what we know, we had to take a closer look at Confluent’s benchmark to try to understand their results. We found two issues that were highly problematic. First, and the largest source of inaccuracy, is Confluent’s limited knowledge of Pulsar. Without understanding the technology, they were not able to set-up the test in a way that could accurately measure Pulsar’s performance.
Second, their performance measurements were based on a narrow set of test parameters. This limited the applicability of the results and failed to provide readers with an accurate picture of the technologies’ capabilities across different workloads and real-world use cases.
In order to provide the community a more accurate picture, we decided to address these issues and repeat the test. Key updates included:
- We updated the benchmark setup to include all of the durability levels supported by Pulsar and Kafka. This allowed us to compare throughput and latency at the same level of durability.
- We fixed the OpenMessaging Benchmark (OMB) framework to eliminate the variants introduced by using different instances, and corrected configuration errors in their OMB Pulsar driver.
- Finally, we measured additional performance factors and conditions, such as varying numbers of partitions and mixed workloads that contain writes, tailing-reads, and catch-up reads to provide a more comprehensive view of performance.
With these updates made, we repeated the test. The result - Pulsar significantly outperformed Kafka in scenarios that more closely resembled real-world workloads and matched Kafka’s performance in the basic scenario Confluent used.
The following section highlights the most important findings. A more comprehensive performance report in the section StreamNative Benchmark Results also gives detail of our test setup and additional commentary.
StreamNative Benchmark Result Highlights
#1 With the same durability guarantee as Kafka, Pulsar achieves 605 MB/s publish and end-to-end throughput (same as Kafka), and 3.5 GB/s catch-up read throughput (3.5 times higher than Kafka). Increasing the number of partitions and changing durability levels have no impact on Pulsar's throughput. However, the Kafka's throughput was severely impacted when changing the number of partitions or changing durability levels.
Durability in Kafka
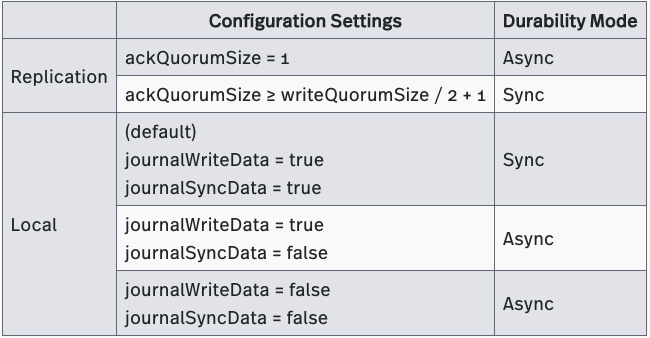
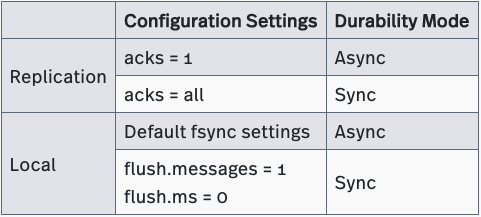
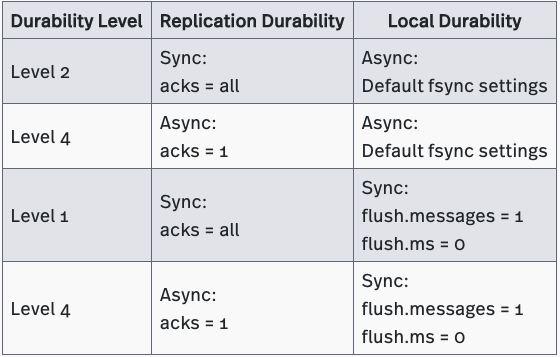
Kafka offers three durability levels: Level 1, Level 2 and Level 4. Kafka can provide replication durability at Level 2 (default settings), but offers no durability guarantees at Level 4 because it lacks the ability to fsync data to disks before acknowledging writes. Kafka can be configured to operate as a Level 1 system by setting flush.messages to 1 and flush.ms to 0. However such setup is rarely seen in Kafka production deployments.
Kafka’s ISR replication protocol controls replication durability. You can tune Kafka’s replication durability mode by adjusting the acks and min.insync.replicas parameters associated with this protocol. The settings for these parameters are described in Table 10 below. The durability levels supported by Kafka are described in Table 11 below. (A detailed explanation of Kafka’s replication protocol is beyond the scope of this article; however, we will explore how Kafka’s protocol differs from Pulsar’s in a future blog post.)
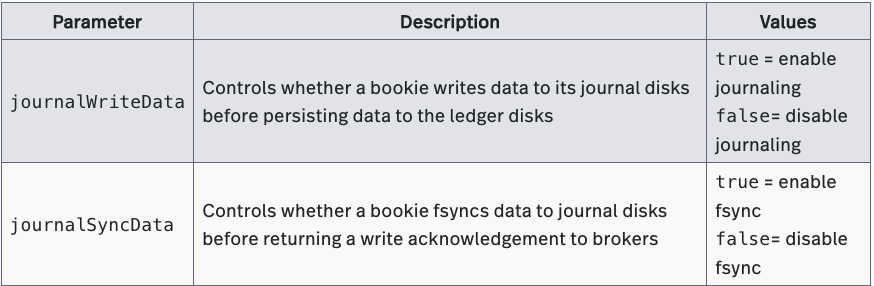
Unlike Pulsar, Kafka does not write data to a separate journal disk(s). Instead, Kafka acknowledges writes before fsyncing data to disks. This operation minimizes I/O contention between writes and reads, and prevents performance degradation.
Kafka’s does offer the ability to fsync after every message, with the above flush.messages = 1 and flush.ms = 0, and while this can be used to greatly reduce the likelihood of message loss, however it severely impacts the throughput and latency, which ultimately means such settings is rarely used in production deployments.
Kafka’s inability to journal data makes it vulnerable to data loss in the event of a machine failure or power outage. This is a significant weakness, and one of the main reasons why Tencent chose Pulsar for their new billing system.
Durability Differences Between Pulsar and Kafka
Pulsar’s durability settings are highly configurable and allow users to optimize durability settings to meet the requirements of an individual application, use case, or hardware configuration.
Because Kafka offers less flexibility, depending on the scenario, it is not always possible to establish equivalent durability settings in both systems. This makes benchmarking difficult. To address this, the OMB Framework recommends using the closest settings available.
With this background, we can now describe the gaps in Confluent’s benchmark. Confluent attempted to simulate Pulsar’s fsyncing behavior. In Kafka, the settings Confluent chose provide async durability. However, the settings they chose for Pulsar provide sync durability. This discrepancy produced flawed test results that inaccurately portrayed Pulsar’s performance as inferior. As you will see when we review the results of our own benchmark later, Pulsar performs as well as or better than Kafka, while offering stronger durability guarantees.
StreamNative Benchmark
To get a more accurate picture of Pulsar’s performance, we needed to address the issues with the Confluent benchmark. We focused on tuning Pulsar’s configuration, ensuring the durability settings on both systems were equivalent, and including additional performance factors and conditions, such as varying numbers of partitions and mixed workloads, to enable us to measure performance across different use cases. The following sections explain the changes we made in detail.
StreamNative Setup
Our benchmarking setup included all the durability levels supported by Pulsar and Kafka. This allowed us to compare throughput and latency at the same level of durability. The durability settings we used are described below.
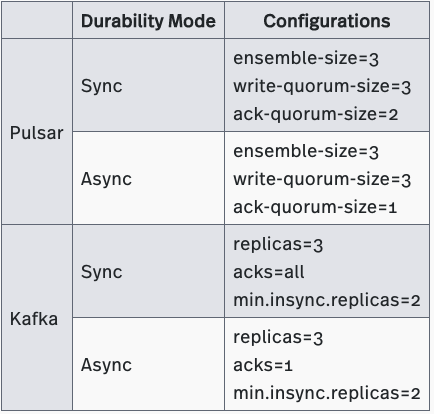
Replication Durability Setup
Our replication durability setup was identical to Confluent’s. Although we made no changes, we are sharing the specific settings we used in Table 12 for completeness.
A new Pulsar feature gives applications the option to skip journaling, which relaxes the local durability guarantee, avoids write amplification, and improves write throughput. (This feature will be available in the next release of Apache BookKeeper). However, this feature will not be made the default, nor do we recommend it for most scenarios, as it still introduces the potential for message loss.
We used this feature in our benchmark to ensure an accurate performance comparison between the two systems. Bypassing journaling on Pulsar provides the same local durability guarantee as Kafka’s default fsync settings.
Pulsar’s new feature includes a new local durability mode (Async - Bypass journal). We used this mode to configure Pulsar to match Kafka’s default level of local durability. Table 13 shows the specific settings for our benchmark.
StreamNative Benchmark Results
We have summarized our benchmark results below. You can find our complete benchmark report.
Maximum Throughput Test
See the full report of “Maximum Throughput Test” here.
The Maximum Throughput Test was designed to determine the maximum throughput each system can achieve when processing workloads that include publish and tailing-reads under different durability guarantees. We also varied the number of topic partitions to see how each change impacted the maximum throughput.
We found that:
- When configured to provide level-1 durability (sync replication durability and sync local durability), Pulsar achieved a throughput of ~300 MB/s, which reached the physical limit of the journal disk’s bandwidth. Pulsar is implemented on top of a scalable and durable log storage (Apache BookKeeper) to make maximum use of disk bandwidth without sacrificing durability guarantees. Kafka was able to achieve ~420 MB/s with 100 partitions. It should be noted that when providing level-1 durability, Pulsar was configured to use one disk as journal disk for writes and the other disk as ledger disk for reads, comparing to Kafka use both disks for writes and reads. While Pulsar's setup is able to provide better I/O isolation, its throughput was also limited by the maximum bandwidth of a single disk (~300 MB/s). Alternative disk configurations can be beneficial to Pulsar and allow for more cost effective operation, which will be discussed in a later blog post.
- When configured to provide level-2 durability (sync replication durability and async local durability), Pulsar and Kafka each achieved a max throughput of ~600 MB/s. Both systems reached the physical limit of disk bandwidth.
- The maximum throughput of Kafka on one partition is only ½ of the max throughput of Pulsar.
- Varying the number of partitions had no effect on Pulsar’s throughput, but it did affect Kafka’s.
- Pulsar sustained maximum throughput (~300 MB/s under a level-1 durability guarantee and ~600 MB/s under a level-2 durability guarantee) as the number of partitions was increased from 100 to 2000.
- Kafka’s throughput decreased by half as the number of partitions was increased from 100 to 2000.
Publish and End-to-End Latency Test
See the full report of “Publish and End-to-End Latency Test” here.
The Publish and End-to-End Latency Test was designed to determine the lowest latency each system can achieve when processing workloads that consist of publish and tailing-reads under different durability guarantees. We varied the number of subscriptions and the number of partitions to see how each change impacted both publish and end-to-end latency.
We found that
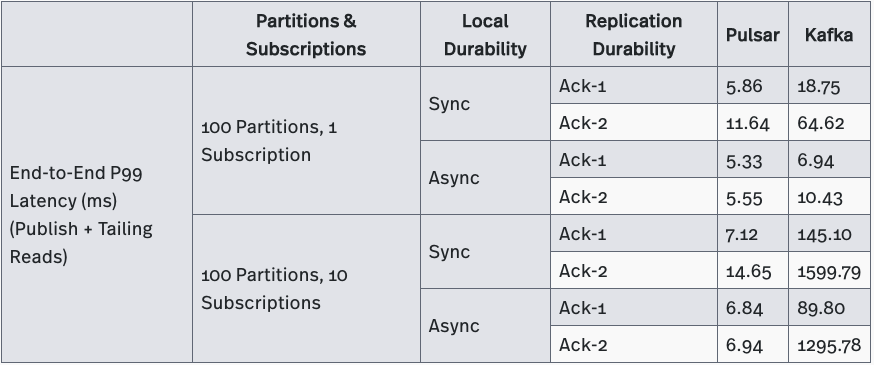
- Pulsar’s publish and end-to-end latency were significantly (up to hundreds of times) lower than Kafka’s in all test cases, which evaluated various durability guarantees and varying numbers of partitions and subscriptions. Pulsar’s 99th percentile publish latency and end-to-end latency stayed within 10 milliseconds, even as the number of partitions was increased from 100 to 10000 or as the number of subscriptions was increased from 1 to 10.
- Kafka’s publish and end-to-end latency was greatly affected by variations in the numbers of subscriptions and partitions.
- Both publish and end-to-end latency increased from ~5 milliseconds to ~13 seconds as the number of subscriptions was increased from 1 to 10.
- Both publish and end-to-end latency increased from ~5 milliseconds to ~200 seconds as the number of topic partitions was increased from 100 to 10000.
Catch-up Read Test
See the full report of “Catch-up Read Test” here.
The Catch-up Read Test was designed to determine the maximum throughput each system can achieve when processing workloads that contain catch-up reads only. At the beginning of the test, a producer sent messages at a fixed rate of 200K per second. When the producer had sent 512GB of data, consumers began to read the messages that had been received. The consumers processed the accumulated messages and had no difficulty keeping up with the producer, which continued to send new messages at the same speed.
When processing catch-up reads, Pulsar’s maximum throughput was 3.5 times faster than Kafka’s. Pulsar achieved a maximum throughput of 3.5 GB/s (3.5 million messages/second) while Kafka achieved a throughput of only 1 GB/s (1 million messages/second).
Mixed Workload Test
See the full report of “Mixed Workload Test” here.
This Mixed Workload Test was designed to determine the impact of catch-up reads on publish and tailing reads in mixed workloads. At the beginning of the test, producers sent messages at a fixed rate of 200K per second and consumers consume messages in tailing mode. After the producer produces 512GB of messages, it will start a new set of catch-up consumers to read all the messages from the beginning. At the same time, producers and existing tailing-read consumers continued to publish and consume messages at the same speed.
We tested Kafka and Pulsar using different durability settings and found that catch-up reads seriously affected Kafka’s publish latency, but had little impact on Pulsar. Kafka’s 99th percentile publish latency increased from 5 milliseconds to 1-3 seconds. However, Pulsar maintained a 99th percentile publish latency ranging from several milliseconds to tens of milliseconds.
The links below provide convenient access to individual sections of our benchmark report.
- Max Throughput Test
- 100 partitions, 1 subscription, 2 producers / 2 consumers
- 2000 partitions, 1 subscription, 2 producers / 2 consumers
- 1 partition, 1 subscription, 2 producers / 2 consumers
- 1 partition, 1 subscription, 1 producer / 1 consumer
- Publish and End-to-End Latency Test
- 100 partitions, 1 subscription
- 100 partitions, 10 subscriptions
- Different partitions: 100, 1000, 2000, 5000, 8000, 10000
- Catchup Read Throughput Test
- Mixed Workload Test
All the raw data of the benchmark results are also available at here.
Conclusion
A tricky aspect of benchmarks is that they often represent only a narrow combination of business logic and configuration options, which may or may not reflect real-world use cases or best practices. Benchmarks can further be compromised by issues in their framework, set-up, and methodology. We noted all of these issues in the recent Confluent benchmark.
At the community’s request, the team at StreamNative set out to run this benchmark in order to provide knowledge, insights, and transparency into Pulsar’s true performance capabilities. In order to run a more accurate benchmark, we identified and fixed the issues with the Confluent benchmark, and also added new test parameters that would provide insights into how the technologies compared in more real-world use cases.
The results to our benchmark showed that, with the same durability guarantee as Kafka, Pulsar is able to outperform Kafka in workloads resembling real-world use cases and to achieve the same end-to-end through as Kafka in Confluent’s limited use case. Furthermore, Pulsar delivers significantly better latency than Kafka in each of the different test cases, including varying subscriptions, topics, and durability guarantees, and better I/O isolation than Kafka.
As noted, no benchmark can replace testing done on your own hardware with your own workloads. We encourage you to test Pulsar and Kafka using your own setups and workloads in order to understand how each system performs in your particular production environment.
More resources
- Get the 2022 Pulsar vs. Kafka Benchmark Report: Read the latest performance comparison on maximum throughput, publish latency, and historical read rate here.
- Make an inquiry: Have questions on benchmark results? Interested in a fully-managed Pulsar offering built by the original creators of Pulsar? Contact us now.
- Learn the Pulsar Fundamentals: Sign up for StreamNative Academy, developed by the original creators of Pulsar, and learn at your own pace with on-demand courses and hands-on labs.





