
Key Takeaways
- Traditional messaging enables high-throughput, stateless processing via multiple concurrent consumers on a topic.
- Streaming provides stateful processing with a single consumer on a topic, but with a tradeoff in throughput.
- Pulsar’s Key_Shared subscription type allows you to have both high throughput and stateful stream processing on a single topic.
- Pulsar’s Key_Shared subscription is a good fit for use cases that require you to perform stateful processing on high-volumes of data such as personalization, real-time marketing, micro-targeted advertising, and cyber security.
Prior to Pulsar’s Key_Shared subscription, you had to decide between having multiple consumers on a topic for high-throughput or a single consumer for stateful processing when using traditional streaming frameworks. In this blog, you will learn how to use Pulsar’s Key-shared subscription to perform behavioral analytics on clickstream data.
Messaging vs. Streaming
It is not uncommon for developers to view messaging and streaming as essentially the same and therefore use the terms interchangeably. However, messaging and streaming are two very different things and it is important to understand the difference between them in order to choose the right one for your use case.
In this section I compare the message consumption and processing semantics of each and how they differ. This will also help you understand why sometimes neither messaging nor streaming alone is adequate for your use case and why you might need unified messaging and streaming.
Messaging
The central data structure used in messaging systems is the queue. Incoming messages are stored in a first-in-first-out (FIFO) ordering. Messages are retained inside the queue until they are consumed. Once they are consumed, they get deleted in order to make space for incoming messages.
From a consumer processing perspective, messaging is completely stateless because every message contains all the information that is required to perform the processing, and therefore can be acted upon without requiring any information from previous messages. This allows you to distribute the message processing across multiple consumers and decrease processing latency.
Messaging is the perfect fit for use cases in which you want to scale up the number of concurrent consumers on a topic in order to increase the processing throughput. A good example of this is the traditional work queue of incoming e-commerce orders that need to be processed by an order fulfillment microservice. Since each order is independent from the others, you can increase the number of microservice instances consuming from the queue to match the demand.
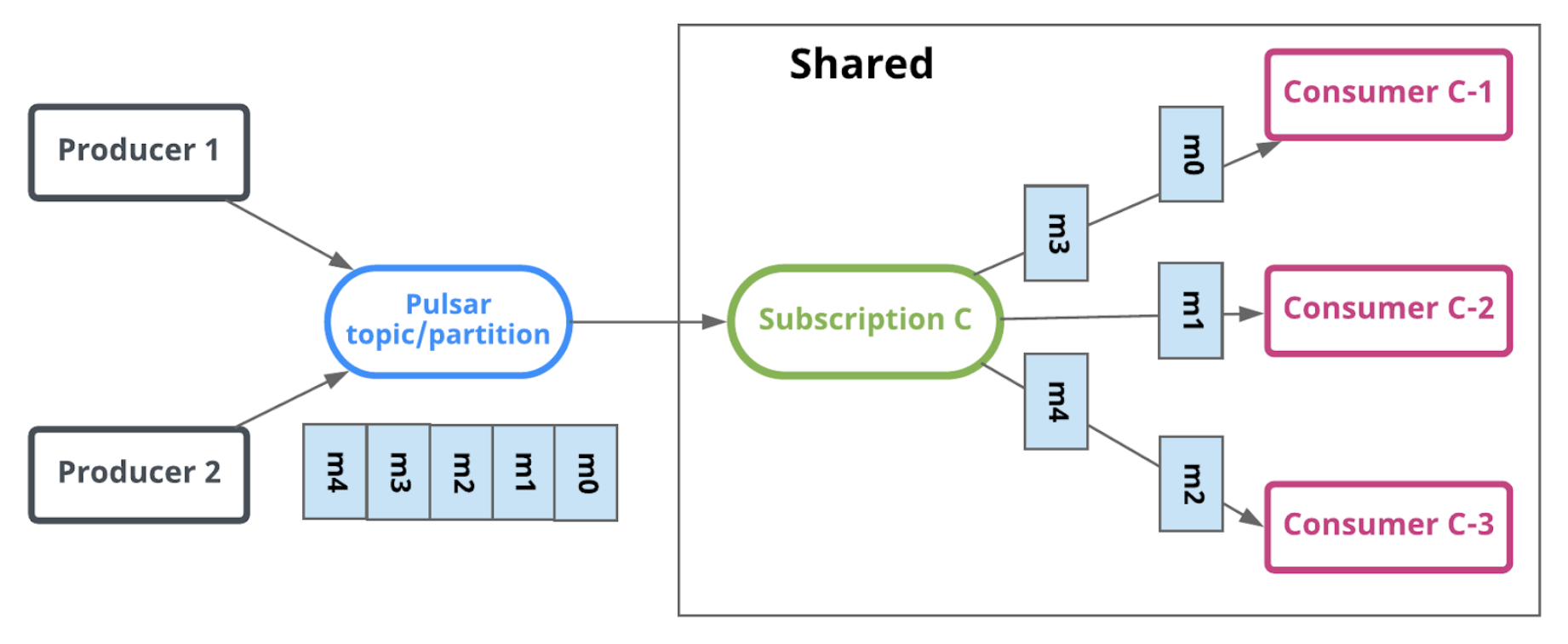
Pulsar’s Shared subscription is designed for this type of use case. As illustrated in Figure 1, it provides messaging semantics by ensuring that each message is delivered to exactly one of the consumers attached to the subscription.
Streaming
In stream processing the central data structure is the log, which is an append-only sequence of records ordered by time. Messages are appended to the end of the log, and reads proceed from the oldest to the newest messages. Message consumption is a non-destructive operation with stream processing, as the consumer just updates its location in the stream.
From a processing perspective, streaming is stateful because the processing is done on a sequence of messages that are typically grouped into fixed-sized “windows” based on either time or size (e.g., every five minutes). Stream processing depends upon information from all the messages in the window in order to produce the correct result.
Streaming is perfect for aggregation operations such as computing the simple moving average of a sensor reading, because all of the sensor readings must be combined and processed by the same consumer in order to properly calculate the value.
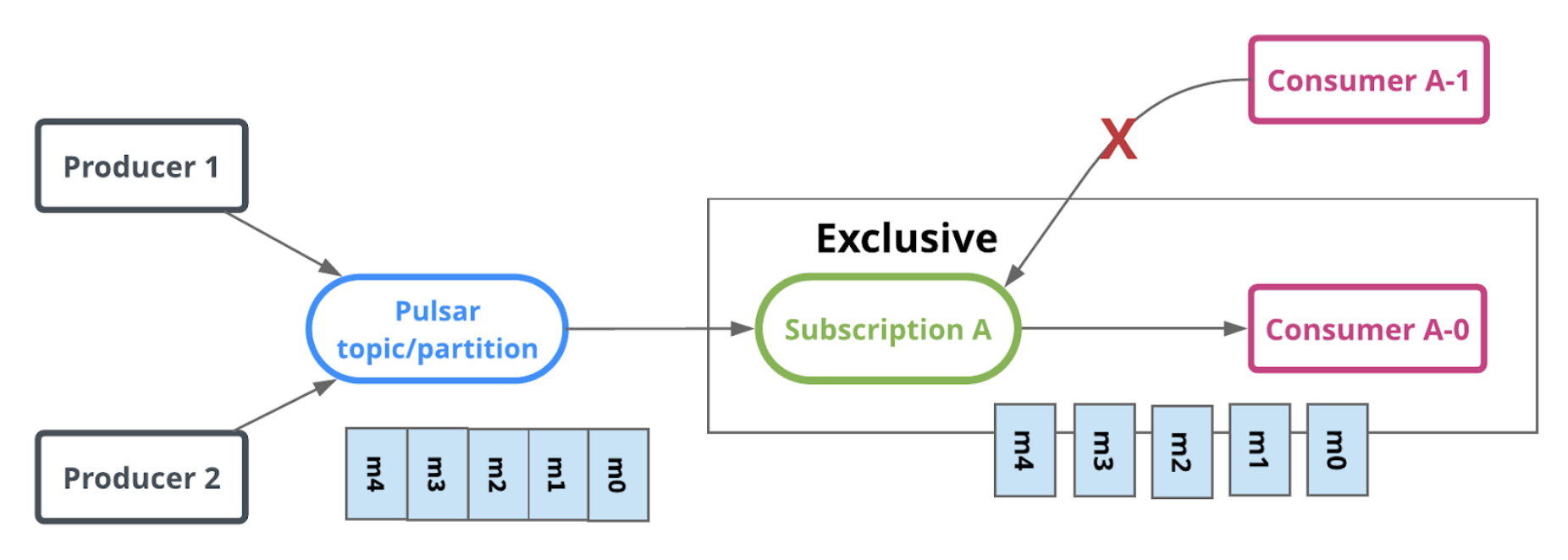
Pulsar’s Exclusive subscription provides the right streaming semantics for this type of use cases. As shown in Figure 2, the Exclusive subscription type ensures that all the messages are delivered to a single consumer in the time-order they were received.
Trade Offs
As you can see, messaging and streaming provide different processing semantics. Messaging supports highly-scalable processing via support for multiple concurrent consumers. You should use messaging when dealing with large volumes of data that need to be processed quickly so that each message has a very low latency between when it was produced and when it is processed.
Streaming supports more complex analytical processing capabilities, but at the expense of scalability per topic partition. Only a single consumer is allowed to process the data in order to produce an accurate result, therefore the speed at which that data is processed is severely limited. This leads to higher latency in stream processing use cases.
Although you can reduce latency by using sharding and partitions, the scalability is still limited. Tying the processing scalability to the number of partitions makes the architecture less flexible. Changing the number of partitions is not an effect-free operation either, because it also affects the way in which data is published to the topic. Therefore, you should only use streaming when you need stateful processing and can tolerate slower processing.
However, what if you have a use case that needs both low latency and stateful processing? If you are using Apache Pulsar, then you should consider the Key_Shared subscription, which provides processing semantics that are a hybrid between messaging and streaming.
Apache Pulsar’s Key_Shared Subscription
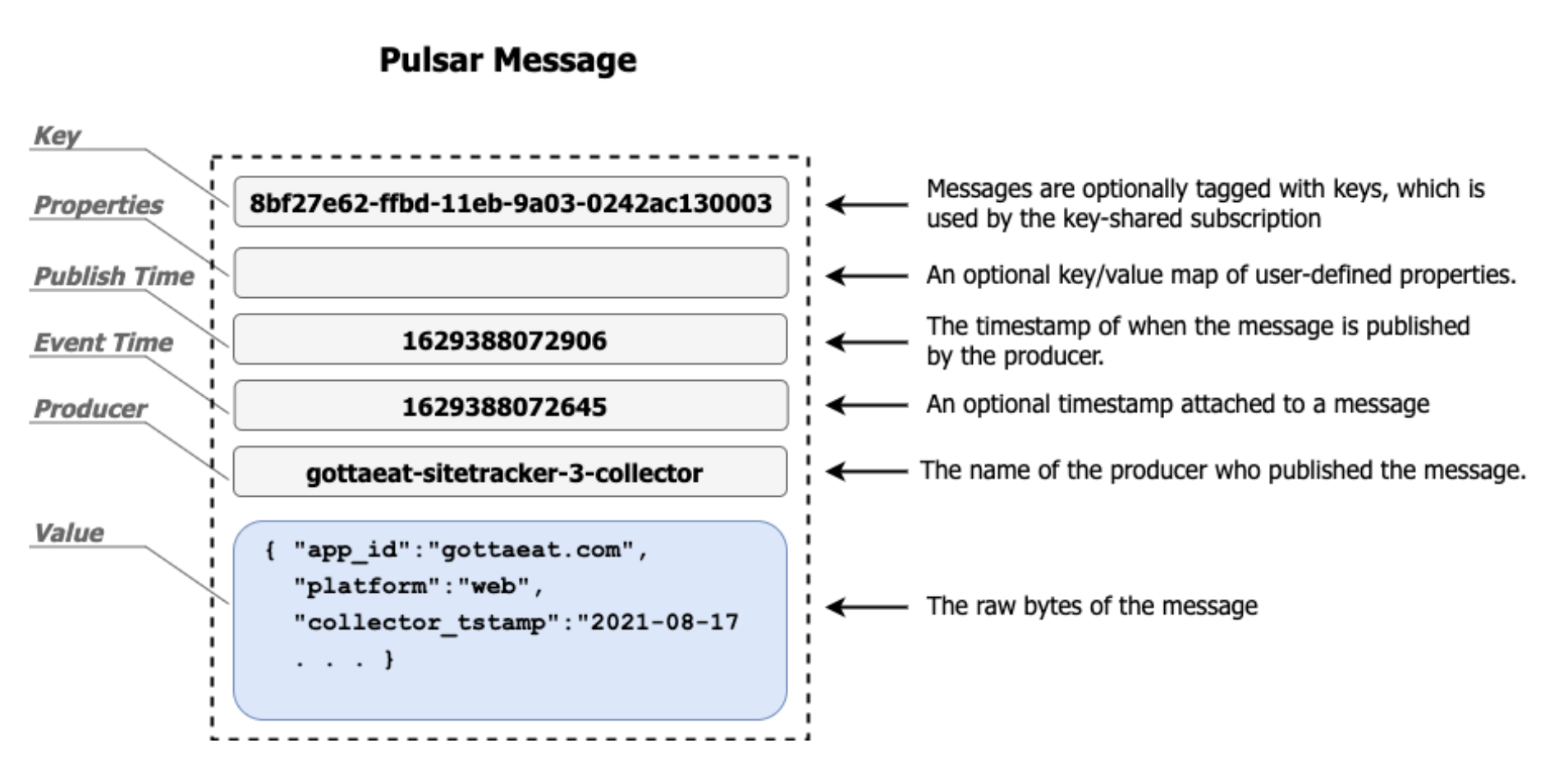
Messages are the basic unit with Pulsar, and they consist of not only the raw bytes that are being sent between a producer and a consumer, but some metadata fields as well. As you can see from Figure 3, one of the metadata fields inside each Pulsar message is the “key” field which can hold a String value. This is the field that the Key_Shared subscription uses to perform its grouping.
Pulsar’s Key_Shared subscription supports multiple concurrent consumers, so you can easily decrease the processing latency by increasing the number of consumers. So in this aspect it provides messaging-type semantics because each message can be processed independently from the others.
However, this subscription type differs from the traditional Shared subscription type in the way that it distributes the data among the consumers. Unlike traditional messaging where any message can be handled by any consumer, within Pulsar's Key_Shared subscription, the messages are distributed across the consumers with the guarantee that messages with the same key are delivered to the same consumer.
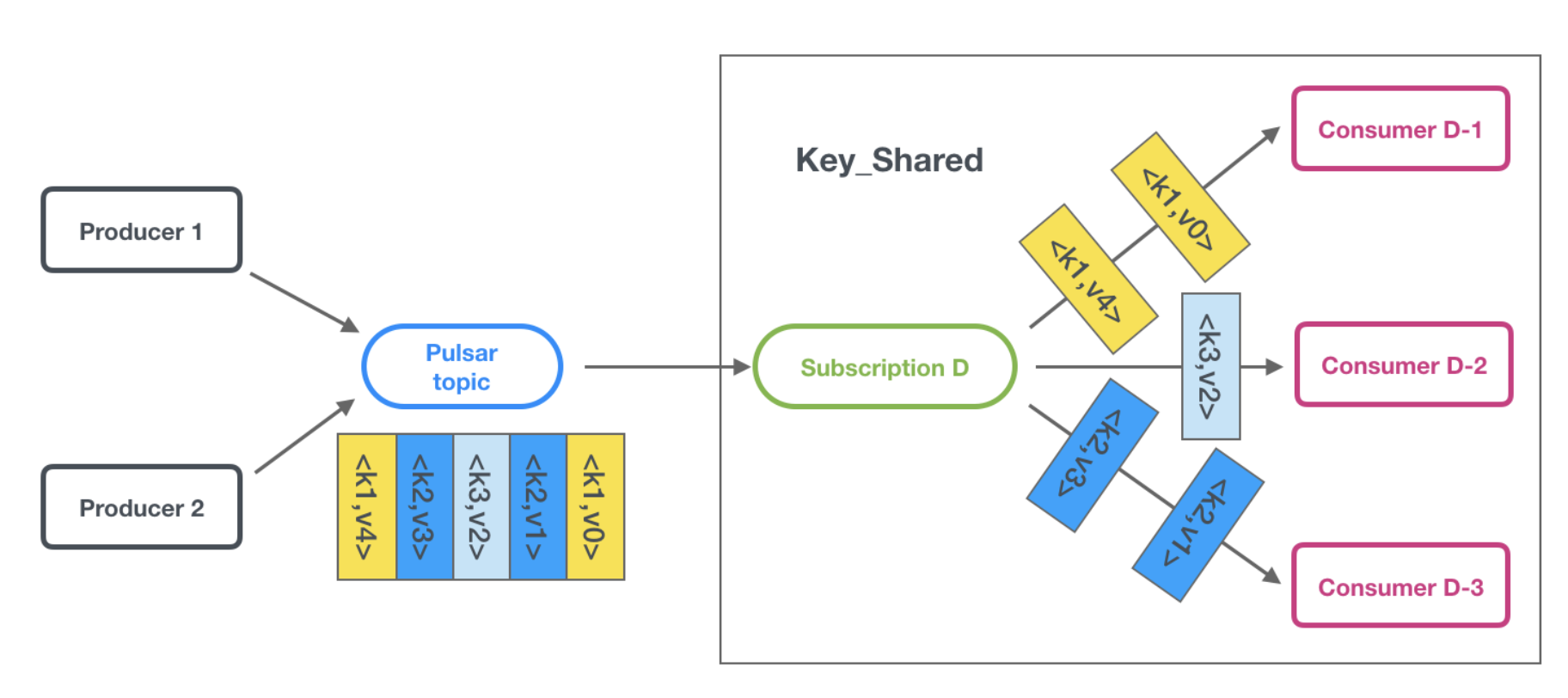
Pulsar achieves these guarantees by hashing the incoming key values and distributing the hashes evenly across all of the consumers on the subscription. Thus, we know that messages with the same key will generate the same hash value and consequently get sent to the same consumer as the previous messages with that key.
By ensuring that all messages with the same key are sent to the same consumer, that consumer is guaranteed to receive all of the messages for a given key and in the order they were received, which matches the streaming consumption semantics. Let’s explore a real-world use case where Pulsar’s Key_Shared subscription could be used effectively.
Behavioral Analytics on Clickstream Data
Providing real-time targeted recommendation on an e-commerce website based on clickstream data is a good real-world example of where the Key_Shared subscription would be particularly well-suited because it requires low latency processing of high volume data.
Clickstream Data
Clickstream data refers to the sequence of clicks performed by an individual user when they interact with a website. A clickstream contains all of a user’s interactions, such as where they click, which pages they visit, and how much time they spend on each page.
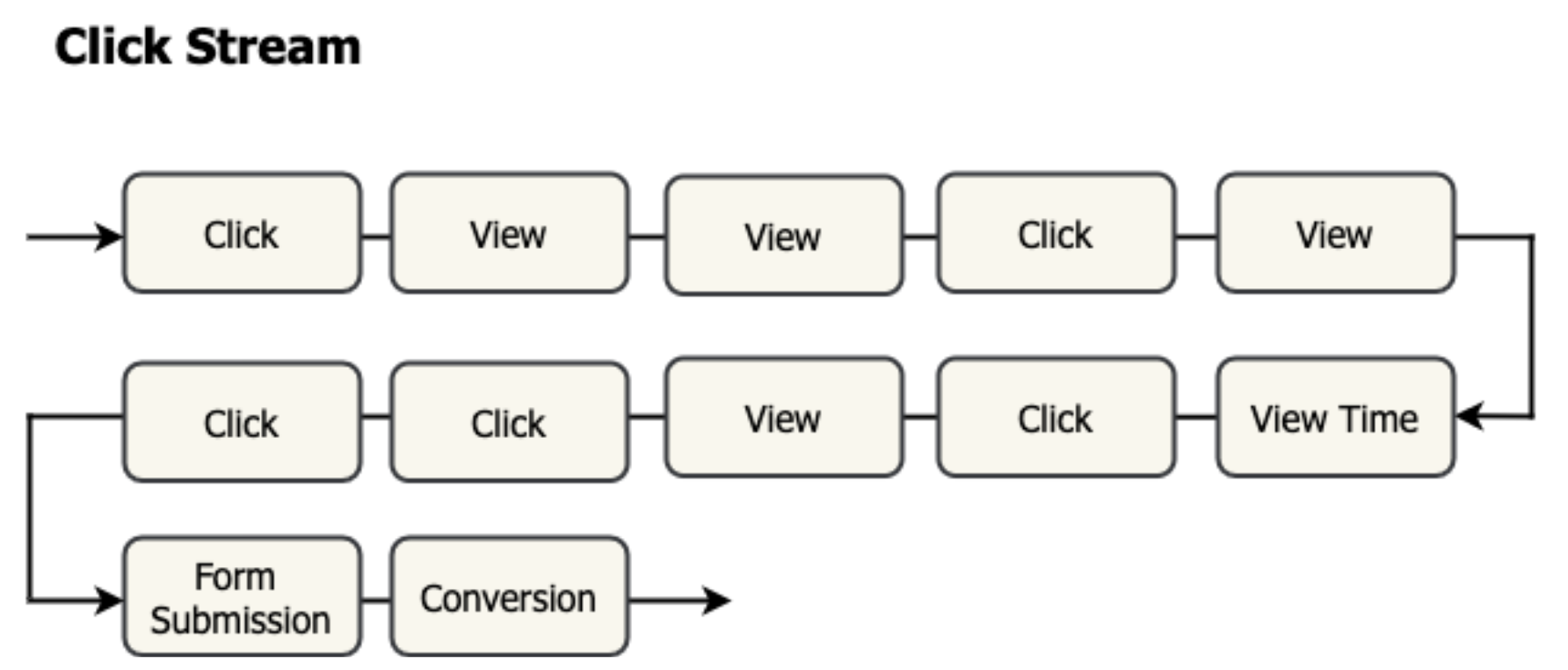
Figure 5: Clickstream data is a time series of events that represent an individual’s interaction with a website.
This data can be analyzed to report user behavior on a specific website, such as routing, stickiness, and tracking of the common user paths through your website. The clickstream behavior is basically a sequence of the user’s interactions with a particular website.
Tracking
In order to receive this clickstream data, you need to embed some tracking software into your website that collects the clickstream events and forwards it to you for analysis. These tags are typically small pieces of JavaScript that capture user behavior at the individual level using personally identifiable data such as IP addresses and cookies. Every time a user clicks on a tagged website, the tracking software detects the event and forwards that information in JSON format to a collection endpoint via an HTTP POST request.
An example of such a JSON object generated by such a tracking library is shown below in Listing 1. As you can see, these clickstream events can contain a lot of information that needs to be aggregated, filtered, and enriched before it can be consumed for generating insights.
{
"app_id":"gottaeat.com",
"platform":"web",
"collector_tstamp":"2021-08-17T23:46:46.818Z",
"dvce_created_tstamp":"2021-08-17T23:46:45.894Z",
"event":"page_view",
"event_id":"933b4974-ffbd-11eb-9a03-0242ac130003",
"user_ipaddress":"206.10.136.123",
"domain_userid":"8bf27e62-ffbd-11eb-9a03-0242ac130003",
"session_id":"7",
"page_url":"http://gottaeat.com/menu/shinjuku-ramen/zNiq_Q8-TaCZij1Prj9GGA"
...
Listing 1: An example clickstream event containing personally identifiable information.
There can be potentially hundreds of active JavaScript trackers at any given time, each of which are collecting the clickstream events for an individual visitor on the company’s website. These events are forwarded to a single tag collector that publishes them directly into a Pulsar topic.
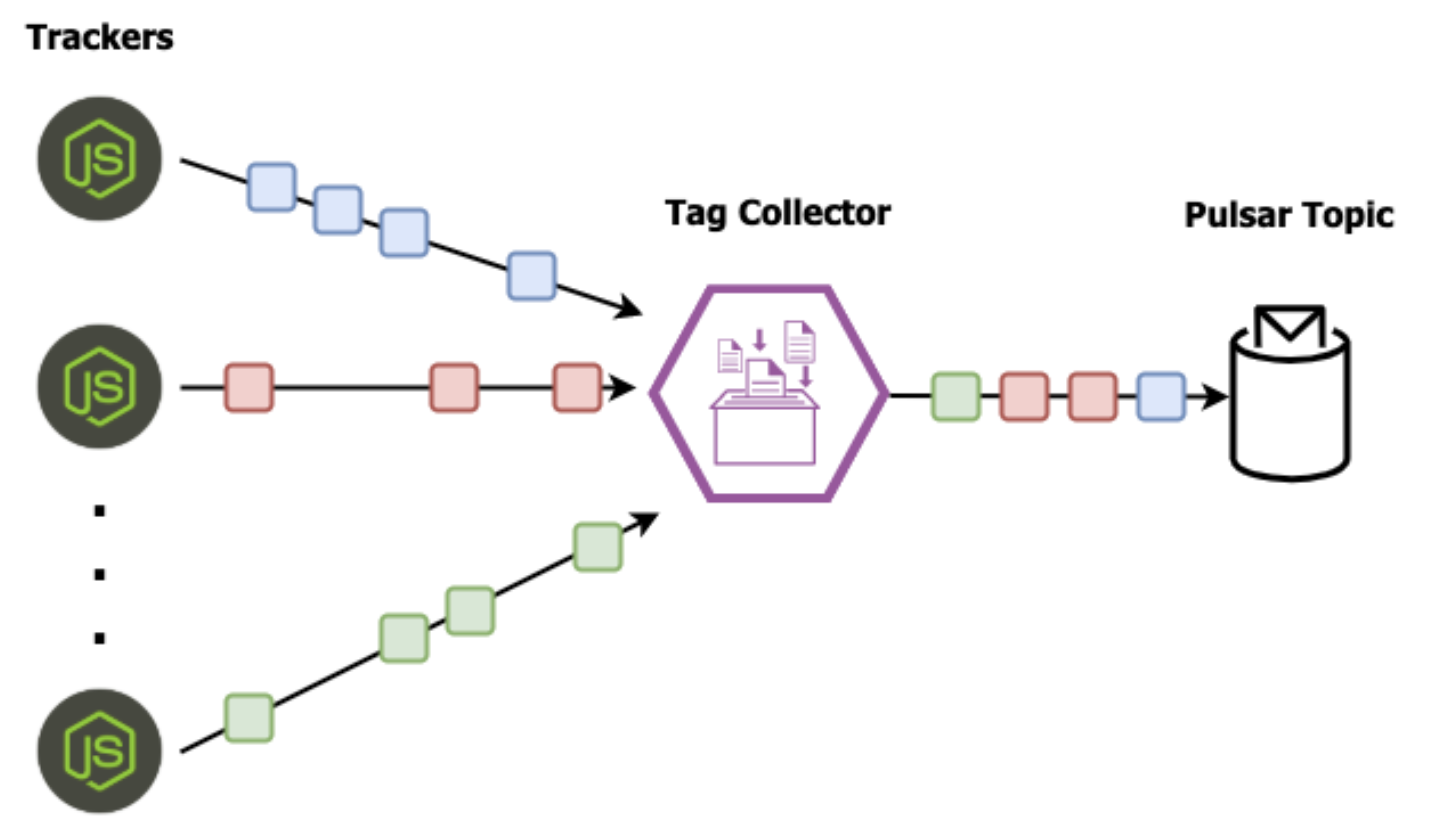
As you can see from Figure 6, since these JavaScript tags don’t coordinate with one another, the clickstream data from multiple users ends up getting intermingled within your Pulsar topic. This poses a big problem because we can only perform behavioral analytics on an individual user’s clickstream.
Identity Stitching
In order to properly analyze the data, the raw clickstream events first need to be grouped together for each individual user to ensure that we have a complete picture of their interactions in the order they occurred. This process of reconstructing each user's clickstream from the commingled data is known as identity stitching. It is done by correlating clickstream events together based upon as many of a user’s unique identifiers as possible.
This is a perfect use case for the Key_Shared subscription because you need to process each individual user's complete stream of events in the order they occurred, so you need stream data processing semantics. At the same time, you also need to scale out this processing to match the traffic on your company website. As we shall see, Pulsar’s Key_Shared subscription allows you to do both.
In order to reconstitute each user's clickstream, we will use the domain_userid field inside the clickstream event, which is a unique identifier generated by the JavaScript tag. This field is a randomly generated universally unique identifier (UUID) that uniquely identifies each user. Therefore we know that all clickstream events with the same domain_userid value belong to the same user. As you shall see, we will use this value to have Pulsar’s Key_Shared subscription to group all of the user’s events together for us.
Implementation
In order to perform behavioral analytics we need to have a complete picture of the user's interaction with our website. Therefore we need to ensure that we are grouping all of the clicks for an individual user together and delivering them to the same consumer. As we discussed in the last section, the domain_userid field inside each clickstream event contains a user’s unique identifier. By using this value as the message key we are guaranteed to have all of the same user’s events delivered to the same consumer when we use a Key_Shared subscription.
Data Enrichment
The JSON objects collected from the JavaScript tags and forwarded by the tag collector only contain raw JSON bytes (the key field is empty). Therefore, in order to utilize the Key_Shared subscription, we first need to enrich these messages by populating the message key with the value of the domain_userid field inside each JSON object.
import org.apache.pulsar.functions.api.Context;
import org.apache.pulsar.functions.api.Function;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.manning.pulsar.chapter4.types.TrackingTag;
import org.apache.pulsar.client.impl.schema.JSONSchema;
public class WebTagEnricher implements Function {
static final String TOPIC = "persistent://tracking/web-activity/tags";
@Override
public Void process(String json, Context ctx) throws Exception {
ObjectMapper objectMapper = new ObjectMapper();
TrackingTag tag = objectMapper.readValue(json, TrackingTag.class);
ctx.newOutputMessage(TOPIC, JSONSchema.of(TrackingTag.class))
.key(tag.getDomainUserId())
.value(tag)
.send();
return null;
}
}
Listing 2: The Pulsar Function converts the raw tag bytes into a JSON object, and copies the value of the domain_userid field into the key field of the outgoing message.
This can be accomplished via a relatively simplistic piece of code as shown in Listing 2, which parses the JSON object, grabs the value of the domain_userid field, and outputs a new message containing the original clickstream event that has a key that is populated with the user’s UUID. This type of logic is a perfect use case for Pulsar Functions. Moreover, since the logic is stateless, it can be performed in parallel using the Shared subscription type, which will minimize the processing latency required to perform this task.
Identity Stitching with the Key_Shared Subscription
Once we have properly enriched the messages containing the clickstream events with the correct key value, the next step is to confirm that the Key_Shared subscription is performing the identity stitching for us. The code in Listing 3 starts a total of five consumers on the Key_Shared subscription.
public class ClickstreamAggregator {
static final String PULSAR_SERVICE_URL = "pulsar://localhost:6650";
static final String MY_TOPIC = "persistent://tracking/web-activity/tags\"";
static final String SUBSCRIPTION = "aggregator-sub";
public static void main() throws PulsarClientException {
PulsarClient client = PulsarClient.builder()
.serviceUrl(PULSAR_SERVICE_URL)
.build();
ConsumerBuilder consumerBuilder =
client.newConsumer(JSONSchema.of(TrackingTag.class))
.topic(MY_TOPIC)
.subscriptionName(SUBSCRIPTION)
.subscriptionType(SubscriptionType.Key_Shared)
.messageListener(new TagMessageListener());
IntStream.range(0, 4).forEach(i -> {
String name = String.format("mq-consumer-%d", i);
try {
consumerBuilder
.consumerName(name)
.subscribe();
} catch (PulsarClientException e) {
e.printStackTrace();
}
});
}
}
Listing 3: The main class launches the consumers on the same Key_Shared subscription using the MessageListener interface that runs them inside an internal thread pool.
The processing logic that is executed when a new event arrives exists inside the TagMessageListener class, which is shown below. Since the consumer will most likely be assigned multiple keys, the incoming clickstream events need to be stored inside an internal map that uses the UUID for each web page visitor as the key. Therefore we decided to practice a bit of defensive programming by using the least recently used (LRU) map implementation from the Apache Commons library which ensures that the map remains a fixed size by removing the oldest elements in the event as it becomes full.
import org.apache.commons.collections4.map.LRUMap;
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.Message;
import org.apache.pulsar.client.api.MessageListener;
public class TagMessageListener implements MessageListener {
private LRUMap> userActivity =
new LRUMap>(100);
@Override
public void received(Consumer consumer,
Message msg) {
try {
recordEvent(msg.getValue());
invokeML(msg.getValue().getDomainUserId());
consumer.acknowledge(msg);
} catch (PulsarClientException e) {
e.printStackTrace();
}
}
private void recordEvent(TrackingTag event) {
if (!userActivity.containsKey(event.getDomainUserId())) {
userActivity.put(event.getDomainUserId(),
new ArrayList ());
}
userActivity.get(event.getDomainUserId()).add(event);
}
// Invokes the ML model with the collected events for the user
private void invokeML(String domainUserId) {
. . .
}
}
Listing 4: The class responsible for aggregating the clickstream events uses an LRU map to sort the events by user id. Each new event is appended to the list of previous events. These lists can then be fed through a machine learning model to produce a recommendation.
When a new event arrives, it is added to the clickstream for the corresponding user. Thereby reconstructing the clickstream for the user keys that have been assigned to the consumer.
Real-Time Behavior Analytics
Now that we have reconstructed the clickstreams, we can feed them to a machine learning model that will provide a targeted recommendation for each visitor to our company’s web site. This might be a suggestion for an item to add to cart based on items in the cart, a recently viewed item, or a coupon. With real-time behavioural analytics we are able to improve the user experience through personalized recommendations, which helps to increase conversion and the average order size.
Summary
Traditional messaging enables scalable processing via multiple concurrent consumers on a topic. A classic use case for this is the traditional work queue of incoming e-commerce orders that need to be processed by an order fulfillment microservice. You should use Pulsar’s Shared subscription for this type of use case.
Traditional streaming provides stateful processing with a single consumer on a topic, but with a tradeoff in throughput. Streaming is used for its more complex analytical processing capabilities. Pulsar’s Exclusive and Failover subscriptions are designed to support this semantic.
Pulsar’s Key_Shared subscription type allows you to have both high throughput and stateful processing on a single topic. It is a good fit for use cases that require you to perform stateful processing on high-volumes of data such as personalization, real-time marketing, micro-targeted advertising, and cyber security.
More Resources
- To learn more about Pulsar’s Key_Shared subscription, watch this video from Matteo Merli, CTO of StreamNative and PMC Chair of Apache Pulsar.
- Read the Apache Pulsar documentation to learn more about Pulsar’s different subscription types.
- To learn more about Apache Pulsar use cases, check out this page.
- Interested in spinning up a Pulsar cluster in minutes using StreamNative Cloud? Contact us today.
- Learn Pulsar from the original creators of Pulsar. Watch on-demand videos, enroll in self-paced courses, and complete our certification program to demonstrate your Pulsar knowledge.




