
Modern data platforms increasingly converge on open lakehouse architectures, where real-time data ingestion, open table formats, and independent optimization layers work together. The combination of StreamNative and Ryft exemplifies this pattern - each system focusing on what it does best.
StreamNative and Ryft address this end-to-end: StreamNative ensures reliable, low-latency ingestion of streaming data into Apache Iceberg, while Ryft continuously manages those tables so they remain fast, cost-efficient, and compliant as they grow.
The Challenge
Modern lakehouses face increasing pressure as data volumes grow and businesses demand lower latency for real-time, mission-critical analysis.
Handling this challenge requires a robust streaming system, capable of handling high throughput and ensuring reliable data ingestion at scale.
It also requires handling challenges in the storage layer - the rapid generation of data and metadata files which can degrade performance if not managed effectively.
Architectural Overview
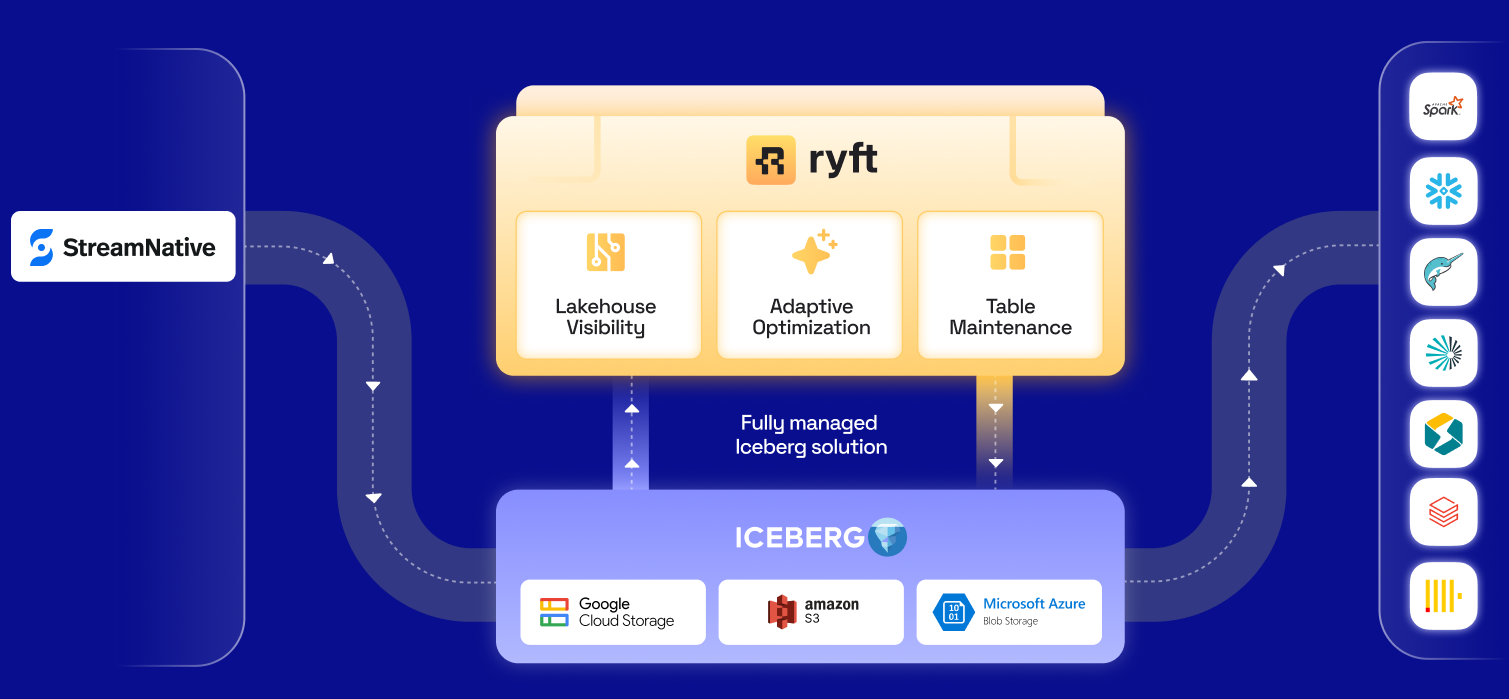
StreamNative and Ryft work together to address those 2 challenges. This architecture offers a clean separation of concerns.
StreamNative: Real-Time Ingestion into Iceberg
StreamNative brings real-time streaming directly into the lakehouse by:
- Continuously ingesting high-volume, real-time Pulsar or Kafka topics
- Writing data as Apache Iceberg tables, rather than transient files
- Enabling downstream analytics engines to query fresh data with minimal latency
This approach removes any batch pipelines and ETL chains, making streaming data immediately available for analytics, AI, and operational use cases.
Ryft: Optimizing and Managing Iceberg Tables
Once Iceberg tables are created by StreamNative, Ryft steps in to handle the heavy lifting of lakehouse operations, including:
- Compaction and file optimization to improve query performance
- Intelligent snapshot lifecycle to control table growth in streaming use cases by keeping daily or weekly snapshots
- Data Lifecycle management, including data tiering and data retention for storage efficiency and compliance use-cases
- Governance & GDPR: safe and efficient deletion of regulated or expired data
Flexible and Open Lakehouse
This architecture supports any object storage and catalog - no need for heavy rewrites or migrations.
StreamNative and Ryft make your tables available and performant in real-time, and your lakehouse remains fully open for any catalog and query engine.
What Customers Get
Real-Time Data Without Long-Term Degradation
StreamNative writes streaming data directly into Iceberg tables in high throughput, making data immediately queryable. Ryft ensures those same tables stay fast and usable over time by performing intelligent compaction and snapshot management.
Since Ryft connects directly to the catalog and storage, it can be used together with StreamNative without changing any streaming pipelines.
Together, they form a low-latency, open lakeouse, that is ready for fast AI and analytics use cases.
Key Use Cases
1. Real-Time Analytics
Serve fresh, continuously updated data to analytical queries with low latency, enabling dashboards, alerting, and operational decision-making on live business events. Support high-concurrency access patterns without relying on precomputed aggregates or batch refresh cycles.
2. AI & ML Pipelines
Provide consistent, point-in-time datasets for feature engineering, model training, and evaluation, ensuring reproducibility across experiments. Enable reuse of the same data for offline training and online inference.
3. Production Workloads
Power real-time, customer-facing applications such as personalization, recommendations, pricing, and fraud detection using shared lakehouse data as the system of record. Enable consistent, up-to-date data access across online services and batch pipelines without duplicating data into separate operational stores.
Final Takeaway
Together, StreamNative and Ryft enable real-time lakehouses that remain reliable at scale. Streaming data flows continuously into Apache Iceberg and becomes immediately available for analytics and AI, while the tables themselves are continuously kept performant, bounded, and compliant as data volumes grow. File layouts are optimized, snapshots and storage are controlled, and retention and GDPR policies are enforced at the table level, so teams can ingest aggressively without accumulating performance, cost, or governance debt over time.
Sign up for a trial and get started for free.





