This article was originally published on Jack-Vanlightly.com on December 10, 2021.
In the last post I described the necessary protocol changes to ensure that all entries in closed ledgers reached Write Quorum (WQ) and all entries in all but the last fragment in open ledgers reach write quorum.
In this post we’re going to look at another tweak to the protocol to allow ledgers to be unbounded and allow writes from multiple clients over their lifetime.
Why unbounded ledgers?
Currently, ledgers are bounded. If you want to create an unbounded log then you create a log of bounded ledgers (forming a log of logs). For example, a Pulsar topic is an ordered list of ledgers. The core BookKeeper protocol does not offer this log-of-logs to you out-of-the-box, you must add that logic on top which is not trivial.
The implementations of log-of-ledgers that I know of are the Managed Ledger module in Apache Pulsar and the Distributed Log library which is a set of modules in the BookKeeper repository. Each has a fair amount of complexity.
But do ledgers need to be bounded at all? Can’t we just allow a single ledger to be an unbounded stream and make that part of the core protocol? Potentially, an UnboundedLedgerHandle could be a simpler stream API (with much less code) than the existing alternatives.
A log of logs
The great thing about using BookKeeper for log storage is its dynamic nature. For example, you can scale out your bookies and they will soon start taking on load automatically. One reason for this is that as new ledgers get added, the new bookies start getting chosen to host these ledgers. Ledgers are log segments in a larger log and each segment can be hosted on a different set of bookies.
But an individual ledger is already a log of log segments (known as fragments). Each time a write fails an ensemble change occurs where a new fragment is appended to the ledger. Each ledger is a log of fragments and each fragment is a log that shares the same bookie ensemble. For that reason a log-of-ledgers isn’t the only way to get this nice scaling ability.
Right now fragments get added on failure but for an unbounded ledger we could also set a maximum size per fragment which would trigger an ensemble change once the current fragment has reached capacity.

This way a stream (such as a Pulsar topic) is a single ledger made of a log of fragments that are distributed across the bookie cluster.
Protocol changes for unbounded ledgers
The great thing about unbounded ledgers it that the changes required are relatively small. Most of the pieces already exist.

The core of this protocol change is changing ledger fencing from a boolean “is fenced or not” to an integer term that is incremented each time a client decides it should take over.
We go from a model where a ledger can only be written to by the client that created it to one where a ledger can be written to by any client, but only one client at a time. Just as in the regular BookKeeper protocol, it is assumed there is leader election for clients external to the protocol. So under normal circumstances, there should only be one client trying to write to the ledger but the protocol can cope with two or more clients battling for control.
Fencing is replaced by terms. When a client decides it should be the one that writes to the ledger it increments the ledger term both in metadata and across the bookies of the last fragment. Recovery is now performed at the beginning of a term, rather than just when closing a ledger.
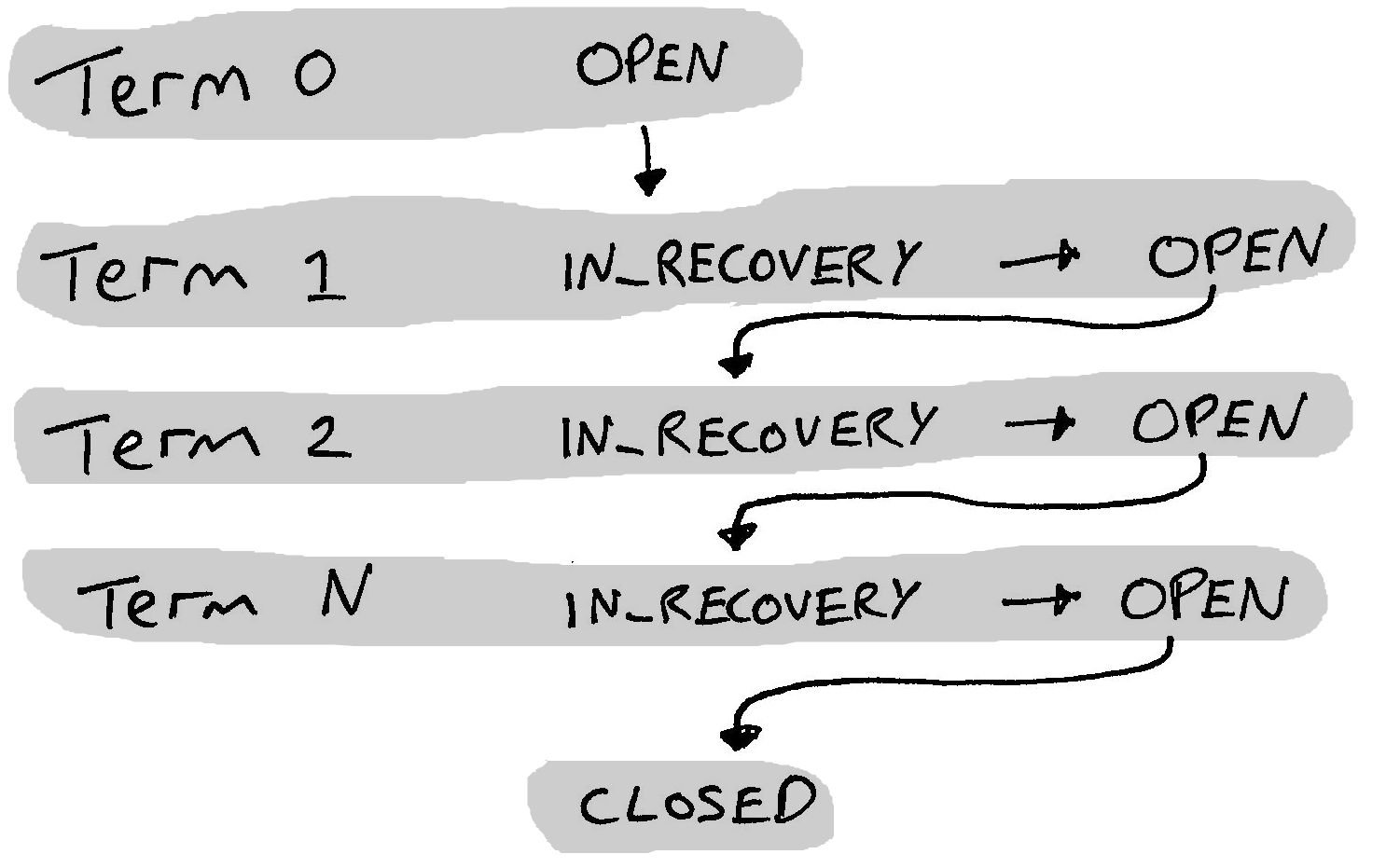
Each fragment is not linked to any particular term, the term is simply a fencing mechanism to prevent former leader clients from making progress.
The metadata gets a new field for term but the existing ensembles field would need to be modified as the list of ensembles (fragments) could grow very large due to the long lived nature of a ledger. In order to enforce data retention policies, the systems that use BookKeeper would need to be able to delete fragments, rather than ledgers.
 Fig 3. Metadata gets a new field for term. The ensembles field now needs to be rethought as it will likely grow too large.
The fencing mechanism is very similar. When a new client wants to take over a ledger it increments the term in the ledger metadata and then starts ledger recovery. The client sends the LAC requests to the current fragment as normal, but with the new term, rather than a fencing flag.
Fig 3. Metadata gets a new field for term. The ensembles field now needs to be rethought as it will likely grow too large.
The fencing mechanism is very similar. When a new client wants to take over a ledger it increments the term in the ledger metadata and then starts ledger recovery. The client sends the LAC requests to the current fragment as normal, but with the new term, rather than a fencing flag.
 The following requests need to include the current term of the client:
The following requests need to include the current term of the client:
- normal adds
- recovery adds
- recovery LAC reads
- recovery reads
Normal reads do not care about terms. The only thing normal reads should care about is the LAC as always.
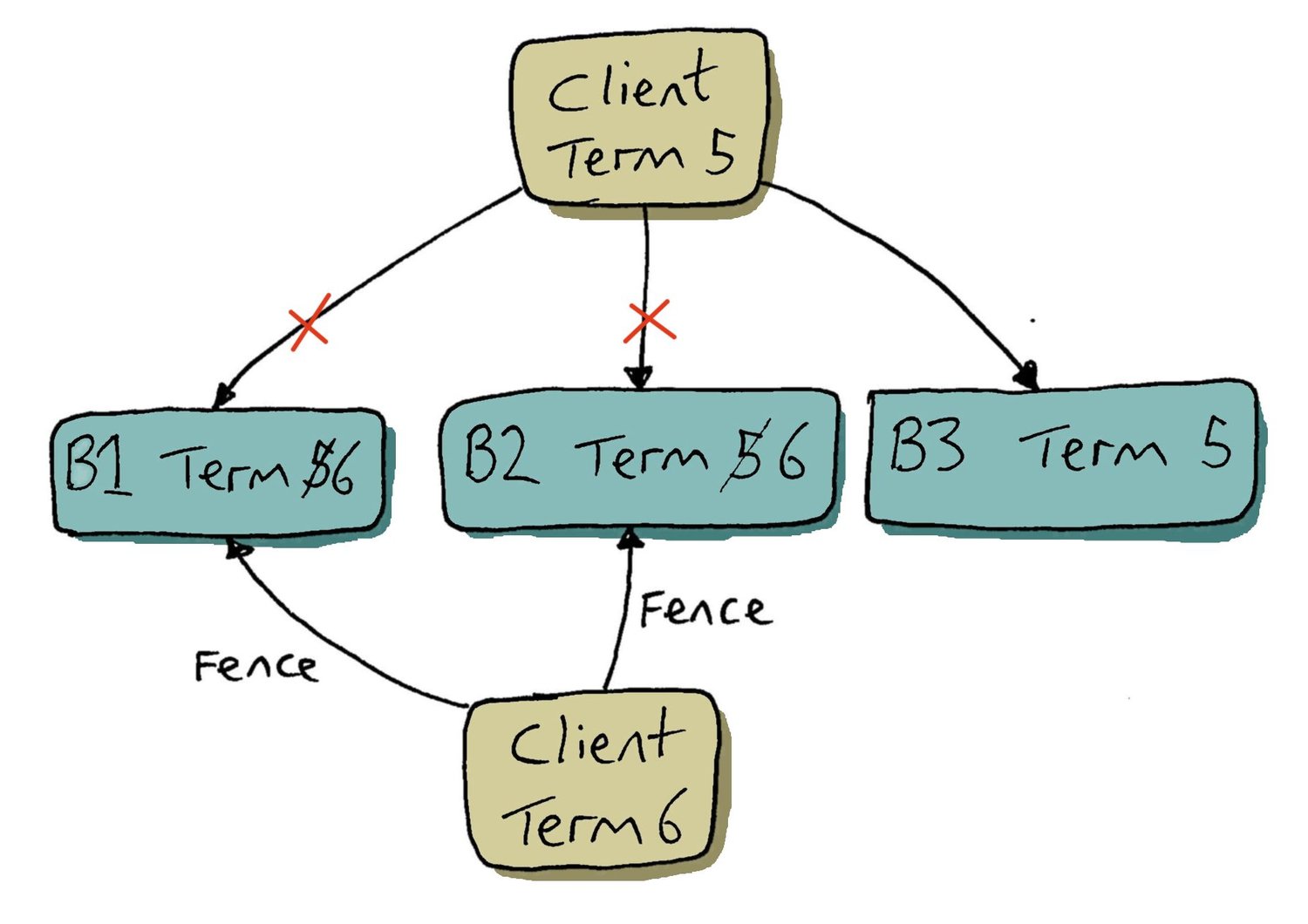
If a bookie has a ledger term that is lower than or equal to the ledger term of a request, it accepts the request and updates its ledger term. If a bookie has a higher term, it rejects the request with an InvalidTerm response.
When a client receives an InvalidTerm response it should disengage. It can check it is still the supposed leader (external to this protocol) and if it is still the leader then reengage refreshing its ledger metadata first.
One additional modification to ledger recovery is that it can’t leave any dirty entries left by the previous term in the last fragment. These entries must be removed and this is done by including a new “truncate” flag in the last entry written back during recovery. We must guarantee that this last entry is written to all bookies of the last fragment and so we must utilize some of the logic from the “guaranteed write quorum” to achieve that.
The scope of a term
There are two main designs that have occurred to me so far and each use the term in a different way.
Terms for fencing only
The one documented in this post does not include the term as part of an entry identifier or even a fragment identifier, it is for fencing alone. However, for that to be safe it requires at least a subset of the “guaranteed write quorum” changes detailed in the last post and also a final truncate no-op entry as the last entry to be written back during recovery. To understand why see the following:
- c1 writes entries {Id: 0, value: A} and {Id: 1, value: B} to b1, b2, b3.
- Entry 0 is persisted to b1, b2 and b3. But entry 1 only persisted to b1.
- c2 takes over, completes recovery assessing that the last recoverable entry is entry 0, writes it back to b1, b2, b3. Then changes the ledger to OPEN.
- c2 writes the entry {id: 1, value: C} to b1, b2, b3.
- b2 and b3 acknowledge it making the entry committed. b1 was unreachable in that moment but as the entry is already committed, c2 ignores the timeout response.
- We now have log divergence where different bookies have different values for entry 1.
This is avoided by adding a no-op entry with a new “truncate” flag as the last entry to be recovered. When a bookie receives an entry with the truncate flag, it deletes all entries with a higher entry id. This truncation combined with guaranteeing the write quorum ensures that no bookie in the last fragment has not truncated any dirty entries. This does mean that BookKeeper clients will need to be aware of these no-op entries and discard them.
The benefits of this approach is that the term is simply one extra field in ledger metadata and bookies only need to store the term in the ledger index as it does with fencing right now. The term does not need to get stored alongside every entry.
The downside is introducing these no-op entries.
We only require “guaranteed write quorum” for recovery writes and so normal writes can continue to use existing behaviour.
Terms are also entry identifiers
An alternative solution is to make the term a more integrated role in the protocol, where it actually forms part of an entry identifier. This prevents the above log divergence scenario as the uncommitted entry 1 written by c1 could not be confused with entry 1 written by c2 as they would have different terms.
The metadata would need to include the entry range of each term so that the client can include the correct term when performing a read of a given entry.
We don’t need fragments and terms to line up, but it makes sense as it would make the metadata more compact. I haven’t explored that too far yet.
The benefit of this approach is that we do not need “guaranteed write quorum” on recovery writes. The downside of this approach is that the term has to be stored with every entry.
I may produce an unbounded ledger design that includes terms as part of the entry identifier sometime soon.
Formal Verification
I have formally verified the unbounded ledgers protocol changes in TLA+, building on the specification for guaranteed write quorum.
You can find the TLA+ specification in my GitHub BookKeeper TLA+ repo.
Final Thoughts
This is all just mental gymnastics at this point as at Splunk we have no pressing need for unbounded ledgers right now. But I do think it could make a valuable addition to BookKeeper in the future and may enable new use cases.
The protocol changes to make a stream API out of a modified LedgerHandle interface are not too major, the issue is the wider impact. There are many secondary impacts such as how it affects auto recovery and garbage collection so it is by no means a trivial change.
In any case, exploring protocol changes is fun and it sheds light on some of the reasons why the protocol is the way it is and the trade-off decisions that were made. I also think it shows how valuable TLA+ is for these kinds of systems as it makes testing out ideas so much easier.
There are also potentially a few varying designs that could be chosen and it might be interesting to explore those, looking at the trade-offs.
UPDATE 1: My original design did not include truncation. When using a larger model the TLA+ spec discovered a counterexample for log divergence. To avoid this a new “truncate” flag is required for the last entry being recovered during the recovery phase of a new term.




