
You already know more about Apache Pulsar than you realize
Today we’ll bootstrap your Apache Pulsar knowledge by translating your existing Apache Kafka experience. We’ll show you how fundamental Apache Kafka concepts appear in Apache Pulsar. You will then be able to use your pre-existing Kafka knowledge to deliver comparable use cases with Pulsar rapidly.
Apache Pulsar presents an attractive alternative to the well-established Apache Kafka ecosystem. Pulsar’s differentiating feature set and architectural differences can overcome fundamental Kafka limitations. While Kafka and Pulsar are both highly scalable and durable distributed event streaming platforms, they have many differences. For example, Pulsar offers flexible subscriptions, unified streaming and messaging, and disaggregated storage.
I’ve been fortunate enough to have worked with Apache Kafka for several years, offering it as a platform in enterprises for Data Scientists, Engineers, and Analysts. Consequently, I’ve experienced a broad range of Kafka use cases and have been exposed to many facets of its ecosystem. When I joined the team at StreamNative to work with Pulsar, I wanted to see how my Kafka experiences would look in a Pulsar setting. I’m going to assume you have a reasonable understanding of Kafka — I won’t describe basic concepts like topics from the ground up. I’ll avoid differentiating platform features and focus on how open-source Pulsar can perform the role of open-source Kafka from the producer and consumer perspectives.
Clarifying note: I will not address Pulsar’s Kafka Protocol handler (KoP), which has Pulsar appear to clients as a set of Kafka brokers; using KoP will not further our knowledge of Pulsar.
Topics
Let’s begin with topics — a fundamental concept in Kafka and Pulsar. You can think of a Pulsar topic as a single Kafka topic partition. At this point, you might be wondering about performance, as multiple partitions are what give Kafka its horizontal scalability. However, worry not, because Pulsar builds on its topic primitive to provide an equivalent concept, the explicitly named ‘partitioned topic’. In this case, a set of Pulsar topics are logically grouped and form something functionally equivalent to a Kafka partitioned topic. This distinction exists because there are additional messaging architectures — beyond the streaming use cases that Kafka targets — supported by Pulsar and use unpartitioned topics as an elementary component. As we are focusing on Kafka use cases, we will, for the rest of this article, assume that the term topic relates to a Pulsar partitioned topic or, equivalently, a Kafka topic.
PulsarAdmin admin = ...;
admin.topics().createPartitionedTopic(topic, partitions);
Retention
When compared to Kafka, Pulsar has greater flexibility regarding the lifecycle of messages. By default, Pulsar will keep all unacknowledged messages forever, and delete acknowledged messages immediately. We can adjust both behaviors, using message retention to preserve acknowledged messages and message expiry to purge unacknowledged messages.
In Kafka, retention policies are unaware of consumer activity — a message is persisted or purged irrespective of whether consumers have read it. This Kafka behavior is perhaps one that you won’t want to replicate in Pulsar because you’ll need to go out of your way to create something less useful. However, in the interest of learning, let’s see how this would look. First let’s retain messages that are acknowledged by all consumers:
PulsarAdmin admin = ...;
admin.topicPolicies().setRetention(
“topic-name”,
new RetentionPolicies(sizeInMins, sizeInMB)
);
Now let’s expire unacknowledged messages:
admin.topicPolicies().setMessageTTL(
“topic-name”,
messageTTLInSeconds
);
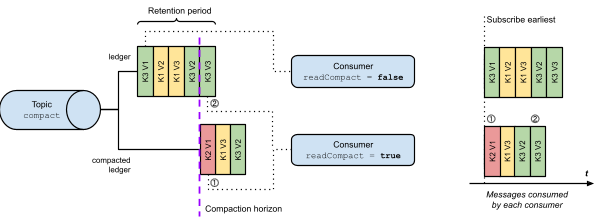
Compaction
Like Kafka, Pulsar is able to perform compaction on topics. However, the internal implementation is slightly different as Pulsar maintains both uncompacted and compacted forms of data concurrently. A new compacted ledger is generated during compaction, and the previous one is discarded.
Consumer compactedTopicConsumer = client.newConsumer()
.topic("some-compacted-topic")
...
.readCompacted(true)
.subscribe();
Pulsar also has similar message deletion semantics to Kafka. The publishing of a keyed message with a null value acts as a tombstone that removes the value on the next compaction cycle. Along with key-based deletion, Kafka also allows retention to be specified on compact topics. You can for example specify unlimited retention, which would always keep at least the latest message for all keys, providing similar storage semantics to a key-value store. Alternatively, you can specify a retention period so that messages are aged out with a TTL.
Pulsar is slightly less flexible in this regard. Messages can only be removed from the compact ledger via explicit deletion by key, otherwise, you can expect to store at least the latest message for all keys. Retention can be set on the compact topic, but this only applies to the non-compact ledger — i.e. the uncompacted messages. Given this constraint, due care must be taken when considering the cardinality of keys, and, if a message TTL is required in the compacted ledger, then it would be necessary to create a manual process to mark and delete messages.
Schemas
Within the Kafka ecosystem, schema validation of messages can be applied by using Confluent’s Schema Registry and producer/consumer SerDes. Clients must be configured by application developers so that they integrate with the registry service and can discover and publish their schema. With a suitably configured client, published messages will be validated on the client side.
A similar capability exists in Pulsar — the server-side schema strategy. But note that the ‘server-side’ reference relates to the integration of the schema registry functionality into Pulsar’s brokers instead of an uncoupled tertiary service. This integration is then expressed directly within Pulsar client APIs, so additional configuration of Kafka schema registry endpoints, SerDes, and subject name strategies is unneeded. Pulsar also has parity with Kafka regarding supported schema flavors (Avro, Protobuf, etc.) and evolution guarantees.
Producer producer = client.newProducer(JSONSchema.of(User.class))
.topic(topic)
.create();
User user = new User("Tom", 28);
producer.send(user);
Producers
Multiple producers can concurrently connect and send messages to a Kafka topic. These topic access semantics are also provided by Pulsar using the default producer Access Mode of Shared. Therefore we can expect that for most use cases, no effort is required to obtain equivalent behavior. Note that whereas a single Kafka producer instance can write to multiple topics, the Pulsar idiom is to have one Producer instance per topic.
Partitioning
Partitioning is the process by which Producers distribute messages across the partitions in a topic. In Kafka, we can control the distribution by setting a key on each message and also providing a Partitioner implementation to the producing client. Pulsar adopts a very similar approach, but its terminology is slightly different. In Pulsar, we may also guide partitioning by setting a message key — although this must be of type string whereas Kafka supports a byte key. Partitioning is further controlled by providing the Producer client with a MessageRoutingMode. Pulsar’s default routing mode is RoundRobinPartition, which importantly uses the message key hash to allocate messages to partitions, and round-robin allocates messages with no key. Conveniently, these are the same partitioning semantics as Kafka’s default partitioner, and so we can expect that for most use cases, no effort is required to obtain equivalent behavior. Additionally, for custom behaviors, Pulsar’s routing modes deliver the same partitioner flexibility as Kafka.
Replicas
Like Kafka, Apache Pulsar can make multiple replica copies of the messages it receives and in fact offers some interesting flexibility in this area. Unlike Kafka, the storage of Pulsar messages is disaggregated from the brokers — it is not constrained by storage locality. What this means in practice is that we can independently specify the number of message replicas and the number of storage nodes. Whereas messages for a given Kafka partition replica get written on a specific node, in Pulsar messages are distributed across a set of Bookies (aka an “ensemble”). Jack Vanlightly describes this nicely in his blog: “Kafka topics are like sticks of Toblerone, … Pulsar topics are like a gas expanding to fill the available space”. Consider the following example where we persist messages M1-M3 on 5 node Pulsar and Kafka clusters with a replication count of 3:
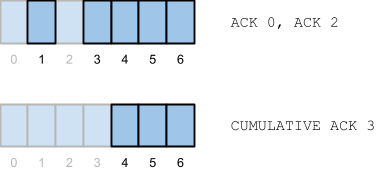
Fortunately, Pulsar consumer API includes an equivalent operation that cumulatively acknowledges the referenced message and all messages before it, and you can do this synchronously or asynchronously. Ultimately, the semantics are equivalent to Kafka’s auto-commit as Pulsar’s ACKs are flushed to brokers periodically to be persisted.
try (PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build());
Consumer consumer = client.newConsumer(schema)
.subscriptionName("subscription")
.subscriptionType(SubscriptionType.Failover)
.topic(topic)
.subscribe()) {
while(true) {
Message message = consumer.receive();
// Process message
consumer.acknowledgeCumulative(message);
}
}
Recap
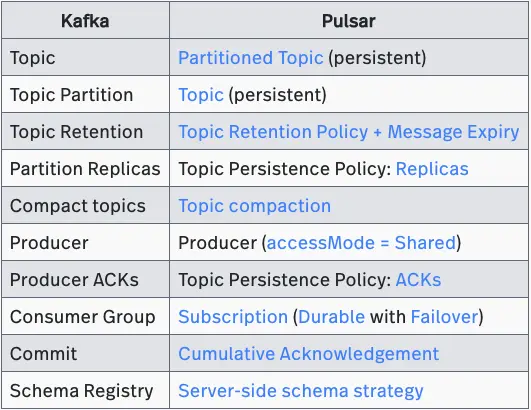
Before we wrap up, let’s summarize the mappings between Pulsar and Kafka concepts that we’ve just covered. Notice that each Kafka concept often translates to a particular configuration of a Pulsar concept. This pattern arises because Pulsar offers highly flexible primitives that can be used to create a broad range of messaging architectures beyond the streaming use case provided by Kafka. Importantly, it shows that Pulsar can replicate Kafka’s behaviors if so desired, and this should not be surprising given that a Kafka-compatible protocol handler has been created for Pulsar.
Next steps
You’ve learned how to apply your knowledge of Kafka concepts using Apache Pulsar. If you want to put this into practice, head over to the StreamNative Cloud where you can get a free Pulsar cluster up and running in minutes. Remember that we only covered features that exist in Kafka — we didn’t touch on the additional Pulsar capabilities or performance characteristics. If you’re interested in going beyond Kafka, then take a look at free training at the StreamNative Academy or have a read of our Pulsar vs Kafka benchmark.




