Why redesign Pulsar Flink connector
In our previous post, we presented Apache Pulsar as a cloud-native messaging system that is designed for streaming performance and scalability, analyzed the integration status with Apache Flink 1.6, and looked forward to possible future integrations.
Recently, as Apache Flink just released version 1.9.0 with many notable features, we've reconsidered the previous integration and decided to redesign it from the ground up. In the rework, we followed these two principles:
- Regard Table API as first-class citizens, ease its use without compromising expressiveness.
- Resilient to failures with exactly-once source and at-least-once sink.
In the next sections, we would present the use and the design of the new Pulsar Flink connector.
Register a Pulsar table with a minimum number of taps
For messages sent to Pulsar, we know everything about them:
- The schema of the data, whether it is a primitive type or a record with multiple fields.
- The storage format of messages in Pulsar, whether it's AVRO, JSON or Protobuf.
- Your desired metadata, such as event time and publish time.
Therefore, users are supposed to concern less on these storage details and concentrate more on their business logic. A Pulsar streaming table could be instantly composed:
val prop = new Properties()
prop.setProperty("service.url", "pulsar://....")
prop.setProperty("admin.urrl", "http://....")
prop.setProperty("topicsPattern", "topic-*")
tableEnv
.connect(new Pulsar().properties(prop))
.inAppendMode()
.registerTableSource("table1")
From now on, you could print the schema of the table1, select desired fields, and build analysis based on the table1. Behind the scenes, we do several tedious works for you:
- Find all matching topics currently available and keep an eye on any changes while the streaming job is running.
- Fetch schemas for each topic, make sure they all share one same schema; otherwise, it is meaningless to go on with analytics.
- Build a scheme-specific deserializer on the initializing phase for each read thread. The deserializer knows the format of messages and converts to one Flink Row for each message.
The figure below provides some implementation details of a source task:
At-least-once Pulsar sink
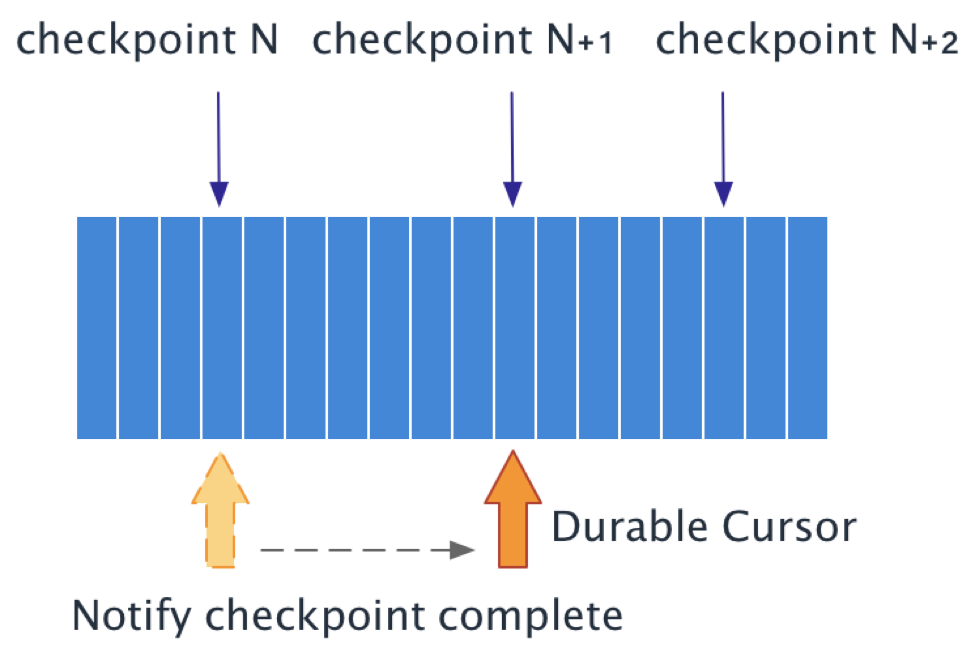
When you send a message to Pulsar using sendAsync, your message will be buffered in a pendingMessages queue, and you will get a CompletableFuture handle. You can register a callback with the handle and get notified once the sending is complete. Another Pulsar producer API flush sends all messages buffered in the client directly and wait until all messages have been successfully persisted.
We use these two APIs in our Pulsar sink implementation to guarantee its at-least-once semantic. For each record we receive in the sink, we send it to Pulsar with sendAsync and maintain a count pendingRecords that has not been persistent.
On each checkpoint, we call flush() manually and wait for message acknowledgments from Pulsar brokers. The checkpoint is considered complete when we get all acknowledgments and pendingRecords decreases to 0, and the checkpoint is regarded as a failure if an exception occurs while persisting messages.
By default, a failing checkpoint in Flink causes an exception that results in an application restart; therefore, messages are guaranteed to be persisted at least once.
Future directions
We have the following plans under our belts.
Unified source API for both batch and streaming execution
FLIP-27 is brought up again recently since Flink community starts to prepare its 1.10 features. We would stay tuned to its status and bring our new connector to batch/streaming compatible.
Pulsar as a state backend
Since Pulsar has a layered architecture (Streams and Segmented Streams, powered by Apache Bookkeeper), it becomes natural to use Pulsar as a storage layer and store Flink state.
Scale-out source parallelism
Currently, source parallelism has an upper limit to the number of topic partitions. For the upcoming Pulsar 2.5.0, key-shared subscription and sticky consumer enables us to scale-out source parallelism while maintaining the semantics of exact-once.
End-to-end exactly-once
One of the vital features in Pulsar 2.5.0 is transaction support. Once transactional produce is enabled, we could achieve end-to-end exactly-once with Flink two-phase commit sink.




