
Apache Pulsar, a distributed streaming and messaging platform, is inherently designed to excel in cloud-native environments. It offers Pulsar Functions, a serverless computing framework that enables users to create functions that utilize one topic as an input and another topic as an output. However, leveraging Pulsar Functions in a cloud-native setting may present challenges for users. In this blog post, I will discuss the following topics:
- Why individuals and organizations use Pulsar;
- The challenges of running Pulsar Functions;
- What is Function Mesh and how does it deal with the challenges;
- New capabilities and extensions brought to Pulsar Functions on Kubernetes with Function Mesh;
- Future plans for Function Mesh.
Pulsar overview
In recent years, an increasing number of individuals and organizations have chosen to use Pulsar for various reasons, such as:
- High throughput and low latency: According to the Apache Pulsar vs. Apache Kafka 2022 Benchmark report and the 2023 Messaging Benchmark Report: Apache Pulsar vs. RabbitMQ vs. NATS JetStream, Pulsar can achieve high throughput and low latency even with tens of thousands of topics or partitions in a cluster, while ensuring message persistence. It outperformed other messaging systems in the reports.
- Excellent scalability: Pulsar’s exceptional scalability is another attractive feature. When users scale a cluster by adding new nodes, both Pulsar brokers and BookKeeper can immediately allocate new workloads to them without waiting for existing data to be redistributed. This operator-friendly feature significantly reduces the complexity and risks of scaling.
- High availability for large-scale distributed data storage: Pulsar natively supports features like multi-tenancy, asynchronous geo-replication, and tiered storage. It is suitable for long-term persistent storage of large-scale streaming messages.
- A thriving ecosystem: The StreamNative Hub lists a variety of tools integrated into Pulsar’s ecosystem, such as IO connectors, protocol handlers, and offloaders. They allow for easy integration of Pulsar with other systems for data migration and processing.
Although Pulsar offers these open-source features natively, deploying a production-grade Pulsar cluster in a private environment and fully utilizing its capabilities is still a challenging task. As shown in Figure 1, a minimal Pulsar cluster includes a ZooKeeper cluster for metadata storage, a BookKeeper cluster as a distributed storage system, and a broker cluster for messaging and streaming capabilities. If you want to expose Pulsar externally, you need an additional proxy layer to route traffic.
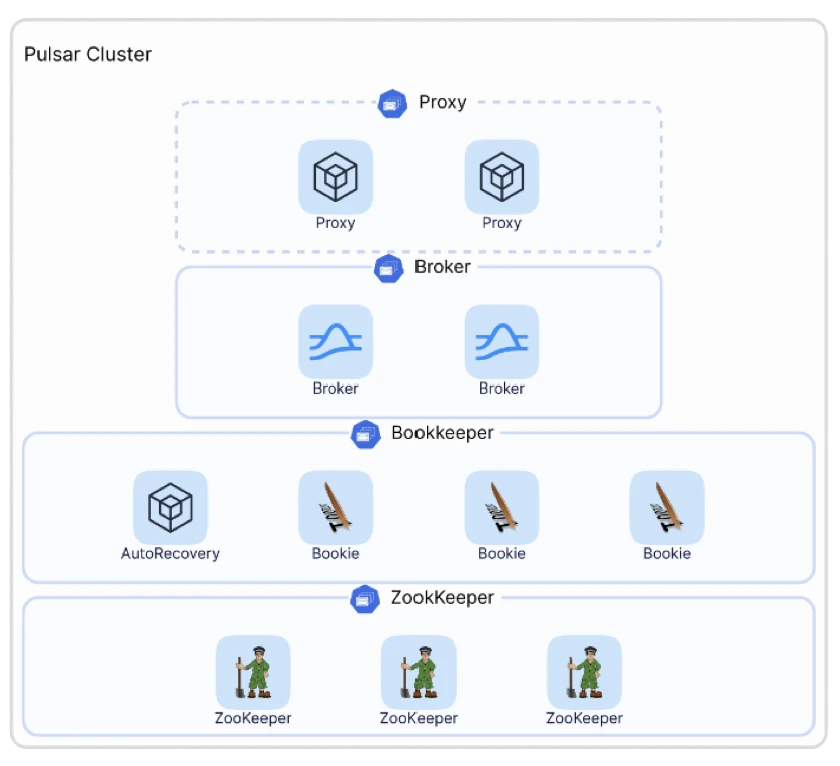
For easier deployment and operation, more users may opt to use Pulsar in cloud-native environments such as Kubernetes. In this connection, the ability to efficiently utilize Pulsar's native features on Kubernetes is a crucial factor when making containerization decisions, with Pulsar Functions being a prominent example.
Understanding Pulsar Functions
Before I talk about using Pulsar Functions on Kubernetes, let me briefly explain its concept. We know that big data computing typically falls into three categories:
- Interactive queries: Common computing scenarios are based on Presto.
- Batch/stream processing: Frequently used systems include Apache Flink and Apache Spark.
- IO connectors: Pulsar provides sink and source connectors, allowing different engines to understand Pulsar schemas and treat Pulsar topics as tables to read data.
Different from the above-mentioned tools, which are used for complex computing scenarios, Pulsar Functions are lightweight computing processes that
- Consume messages from Pulsar topics;
- Apply a user-supplied processing approach to each message;
- Publish results to another Pulsar topic.
Figure 2 illustrates this process. Internally, Pulsar Functions offer simplified message processing with a function abstraction, which allows users to use basic features like creation, management, and replica scheduling.
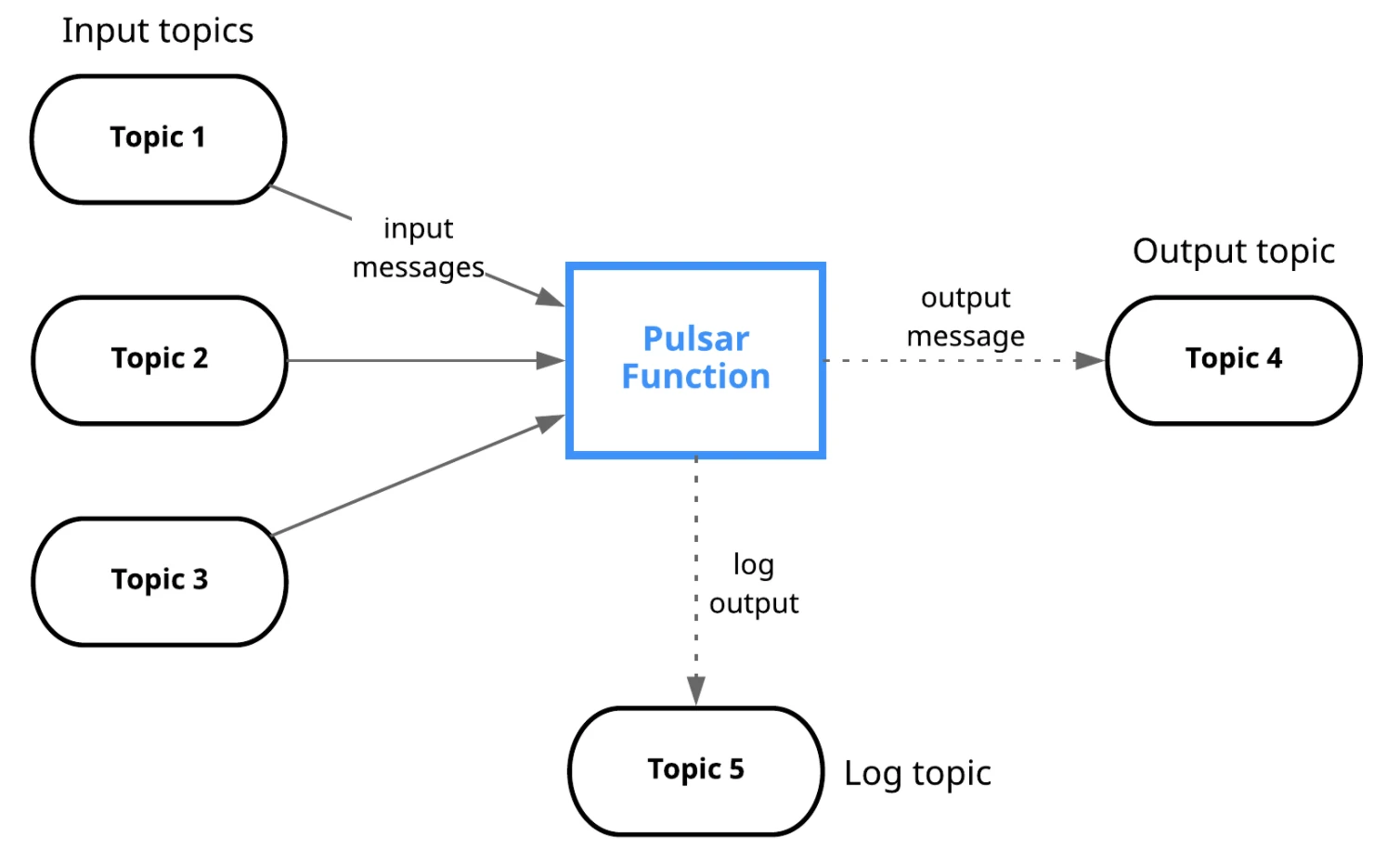
Pulsar Functions are not designed to provide a complex computing engine but to integrate serverless technologies with Pulsar. Common use cases such as ETL and real-time aggregation account for approximately 60%-70% of overall scenarios and about 80%-90% of IoT scenarios. With Pulsar Functions, users can perform basic data processing at Pulsar’s messaging end without building complex clusters, saving on data transmission and computing resources.
Function workers
We know that Pulsar brokers provide messaging and streaming services, but how do they schedule and manage functions and offer the corresponding APIs? Pulsar relies on function workers to monitor, orchestrate, and execute individual functions in the cluster-mode deployment. Function workers provide a complete set of RESTful APIs for full lifecycle management of functions, which are integrated into tools like pulsar-admin.
When using Pulsar Functions, function workers run together with brokers, which is the default behavior set in the Helm chart provided by the Pulsar community. This is easy for deployment and management, suitable for scenarios with limited resources and non-intensive function usage.
If you require higher isolation and want to prevent function workers from impacting your cluster (intensive function usage), you can choose to run function workers as a separate cluster for functions. That said, this approach still needs more best practices for cloud-native deployment and management, so you may need to invest more time and effort in configuration and maintenance.
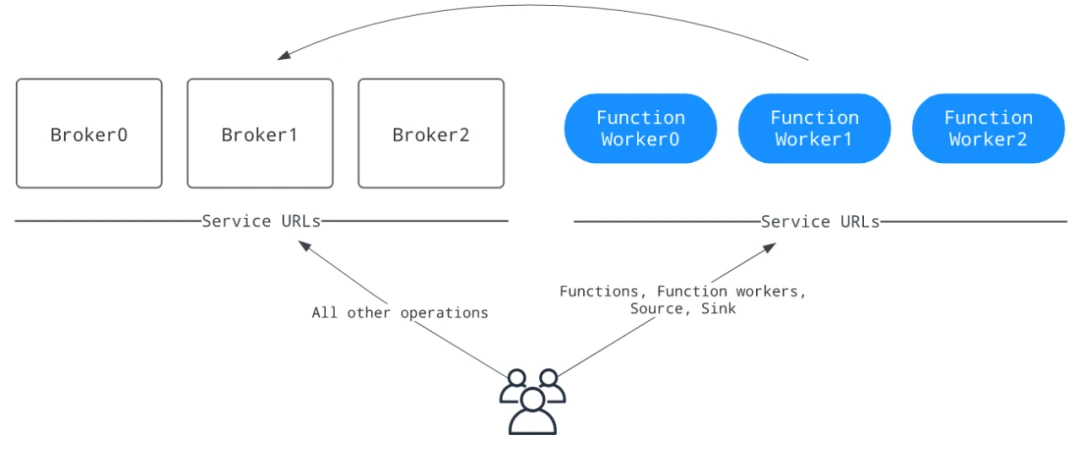
Note: The StreamNative team has validated this mode, and we will share our experience later in the article.
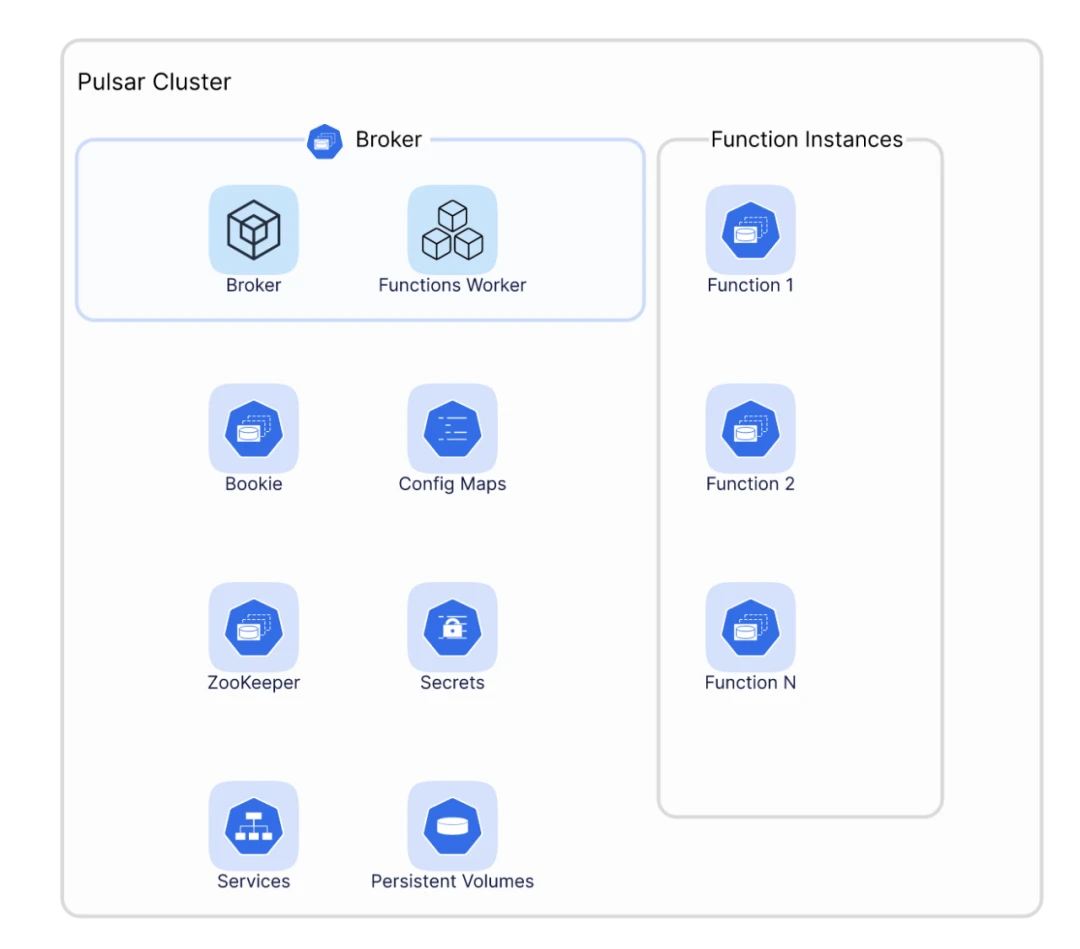
Function workers support running functions in different ways. Generally, they can run functions on their own or together with brokers; in other words, you can invoke function threads in function workers or in processes forked by function workers. As function workers include a Kubernetes runtime implementation, you can package functions as StatefulSets and deploy them on Kubernetes.
In Figure 4, functions are not running within broker or function worker Pods. They are deployed in a separate StatefulSet to avoid the security risks of running together with brokers or function workers.
Challenges of running Pulsar Functions on Kubernetes
As the number of Pulsar Functions users increases, we have started to see the limitations of running Pulsar Functions on Kubernetes.
One major issue is the potential crash loop when launching functions on Kubernetes. As each broker has a function worker, all management and maintenance interfaces are aggregated for the corresponding function. When you submit a function to a function worker, its metadata information and related resources are stored in a topic. During scheduling, Kubernetes must access the topic to retrieve the function’s metadata (for example, replica count) before deploying it as a StatefulSet. If the broker is not started or is unavailable, a crash loop may occur. The function will not begin to run until the broker is back online.
Another challenge in the process is metadata management. This process contains metadata in two separate places: the function’s metadata stored in a Pulsar topic and the StatefulSet submitted to Kubernetes. This complicates metadata management. For example, when you use kubectl to manage a function StatefulSet, there is no mechanism to synchronize the data stored in the Pulsar topic, leaving the change unknown to the function worker.
In addition to the two major issues, Pulsar Functions have the following problems when running on Kubernetes:
- Non-cloud-native: Kubernetes provides powerful capabilities like dynamic scaling and management. However, it is very difficult to leverage these cloud-native features for Pulsar Functions.
- Token expiration: Due to the limitations of the current Kubernetes runtime implementation, tokens are the only available method for authentication and authorization with Pulsar brokers when submitting functions. As a result, function instances may fail to start once the token expires. To address this issue, the Pulsar community added the --update-auth-data option for pulsar-admin to help update tokens. However, it requires you to manually run the command to maintain token validity.
- Complex task handling: In many scenarios, you may need to use multiple functions for a single task, or even combine functions with source and sink tools as a whole. Additionally, you need to use multiple commands to operate each function with different topics. All of these contribute to higher management and operation pressure.
In light of these challenges, the community was looking for a more efficient and compatible way to bring Pulsar Functions to cloud-native environments, enabling users to better leverage Kubernetes capabilities to manage and use Pulsar Functions for complex use cases.
This is where Function Mesh comes to play.
Function Mesh: Rising to the challenges
The primary goal of Function Mesh is not to support more complex, universally applicable computing frameworks, but to help users manage and use Pulsar Functions in a cloud-native way.
In 2020, the StreamNative team submitted a PIP in the Pulsar community, as we looked to provide a unified component allowing users to easily describe the relations between functions (like which function serves as the input/output of another function). By combining this mindset with features such as scheduling and scaling in Kubernetes, we might be able to provide a better user experience of Pulsar Functions. As such, StreamNative proposed the open-source Function Mesh Operator built with the Kubernetes operator framework.
Function Mesh is an open-source Kubernetes operator for:
- Running Pulsar Functions natively on Kubernetes;
- Utilizing Kubernetes native resources and scheduling capabilities;
- Integrating separate functions together to process data.
Let’s look at some core concepts of Function Mesh.
Kubernetes operator
Generally, deploying a Kubernetes operator involves creating the associated custom resource definition (CRD) and the custom controller. I will explain these two concepts in more detail in the context of Function Mesh.
Custom resource definitions
With CRDs, the Kubernetes operator can solve two major problems when using Pulsar Functions: describing and submitting functions, and scheduling functions. All function, sink, and source configurations can be described using CRDs, such as parallelism, input and output topics, autoscaling, and resource quotas. The following code snippet displays some function CRD specifications.
type FunctionSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
Name string `json:"name,omitempty"`
ClassName string `json:"className,omitempty"`
Tenant string `json:"tenant,omitempty"`
ClusterName string `json:"clusterName,omitempty"`
Replicas *int32 `json:"replicas,omitempty"`
MaxReplicas *int32 `json:"maxReplicas,omitempty"`
Input InputConf `json:"input,omitempty"`
Output OutputConf `json:"output,omitempty"`
LogTopic string `json:"logTopic,omitempty"`
FuncConfig map[string]string `json:"funcConfig,omitempty"`
Resources corev1.ResourceRequirements `json:"resources,omitempty"`
SecretsMap map[string]SecretRef `json:"secretsMap,omitempty"`
VolumeMounts []corev1.VolumeMount `json:"volumeMounts,omitempty"`
}
Additionally, we provide the FunctionMesh CRD that allows users to configure functions and sources/sinks in complex computing scenarios. See the Function Mesh specifications below.
type FunctionMeshSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
Sources []SourceSpec `json:"sources,omitempty"`
Sinks []SinkSpec `json:"sinks,omitempty"`
Functions []FunctionSpec `json:"functions,omitempty"`
}
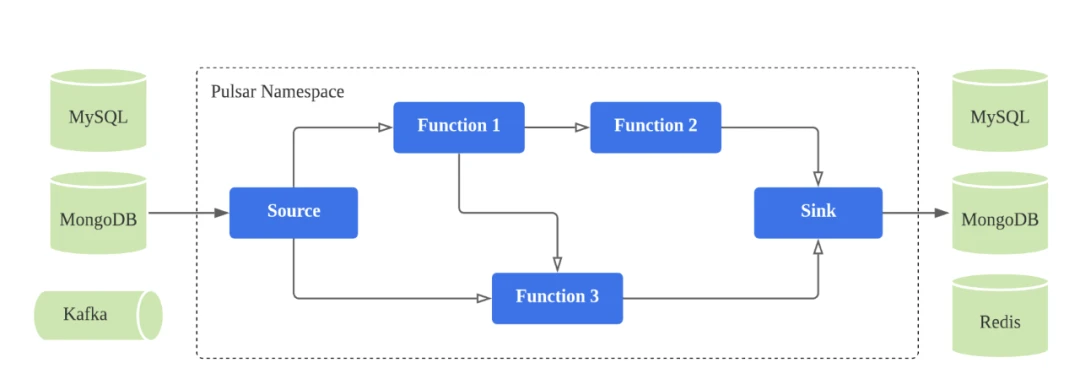
Figure 5 depicts a typical use case of Function Mesh and let’s assume this is a CDC scenario. You may want to use a source connector to ingest data from MongoDB, configure ETL, filtering, and routing, and then deliver messages to MySQL through a sink connector. With the Function Mesh CRD, you can describe the entire process in YAML and run the corresponding custom resource (CR) on Kubernetes.
Custom controller
After you create the CR on Kubernetes, the custom controller enables and manages functions. The controller is an extension of the Kubernetes control plane and interacts directly with the Kubernetes API. It maps CRD configurations to corresponding Kubernetes resources and manages them throughout their lifecycle. The controller converts operational knowledge into a program that performs certain operations on the Kubernetes cluster when needed (making sure resources are in their desired state). It acts like an engineer but with greater efficiency and speed.
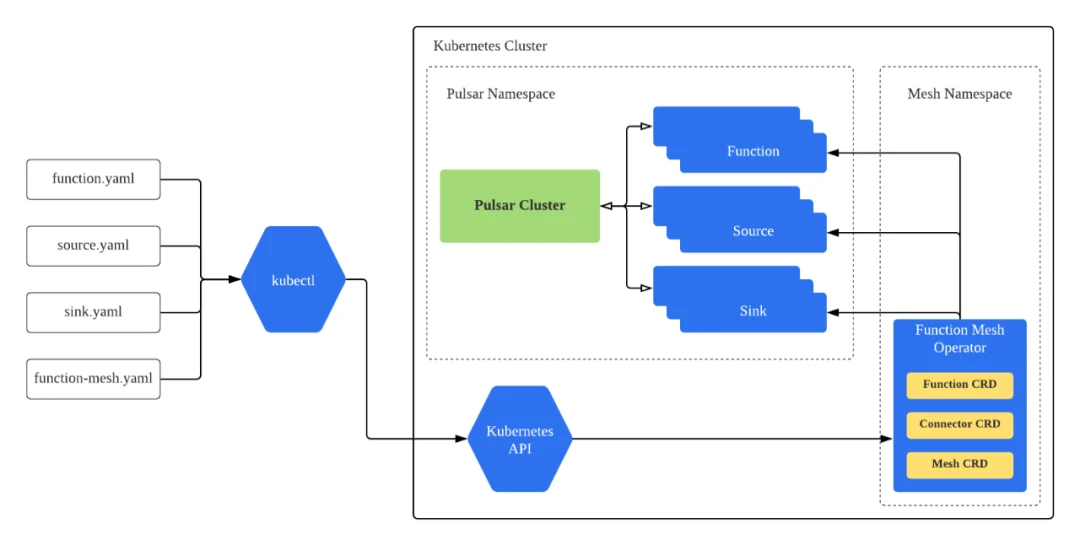
As shown in Figure 6, you can create CRs using kubectl based on their associated CRDs. With the help of custom controllers, the Kubernetes API schedules internal resources and monitors the status of the CRs. If CRDs are updated, CRs will be changed accordingly. Note that the Pulsar cluster only provides data pipeline services and that it does not store any function metadata.
Function Runner
The second concept you need to know is the runtime, or the containers that run functions submitted by users (also known as the Function Runner). Pulsar Functions support multiple programming languages for runtime, including Java, Python, and Go. Generally, they are packaged together with Pulsar images. However, it is not practical to use Pulsar’s image for each function container in Function Mesh. Additionally, as functions may come from third-party programs, there are security risks in Pulsar images as root privileges are used by default prior to version 2.10.
For a more secure experience of using Pulsar Functions, the StreamNative team provides separate runner images for different languages, including Java, Python, and Go. The Java runner image is integrated with StreamNative Sink and Source Connectors, which can be used directly in Function Mesh.
With runner images, you can choose either of the following ways to submit functions.
- Use a runner image to package the function and dependencies into a new image and submit it to Function Mesh;
- Interact with Pulsar’s package management service by uploading the package to Pulsar. Function Mesh will schedule and download functions, and then run them in runner Pods.
Function Mesh Worker Service
The Function Mesh Worker Service1 is similar to the Pulsar Function Worker Service, while it uses the Function Mesh Operator to schedule and run functions. When using Pulsar Functions, you use Function Worker REST APIs to access data. In the case of Function Mesh, the Function Mesh Worker Service also allows you to manage functions on Kubernetes with CLI tools like pulsar-admin and pulsarctl, providing a consistent user experience. See Figure 7 for details.
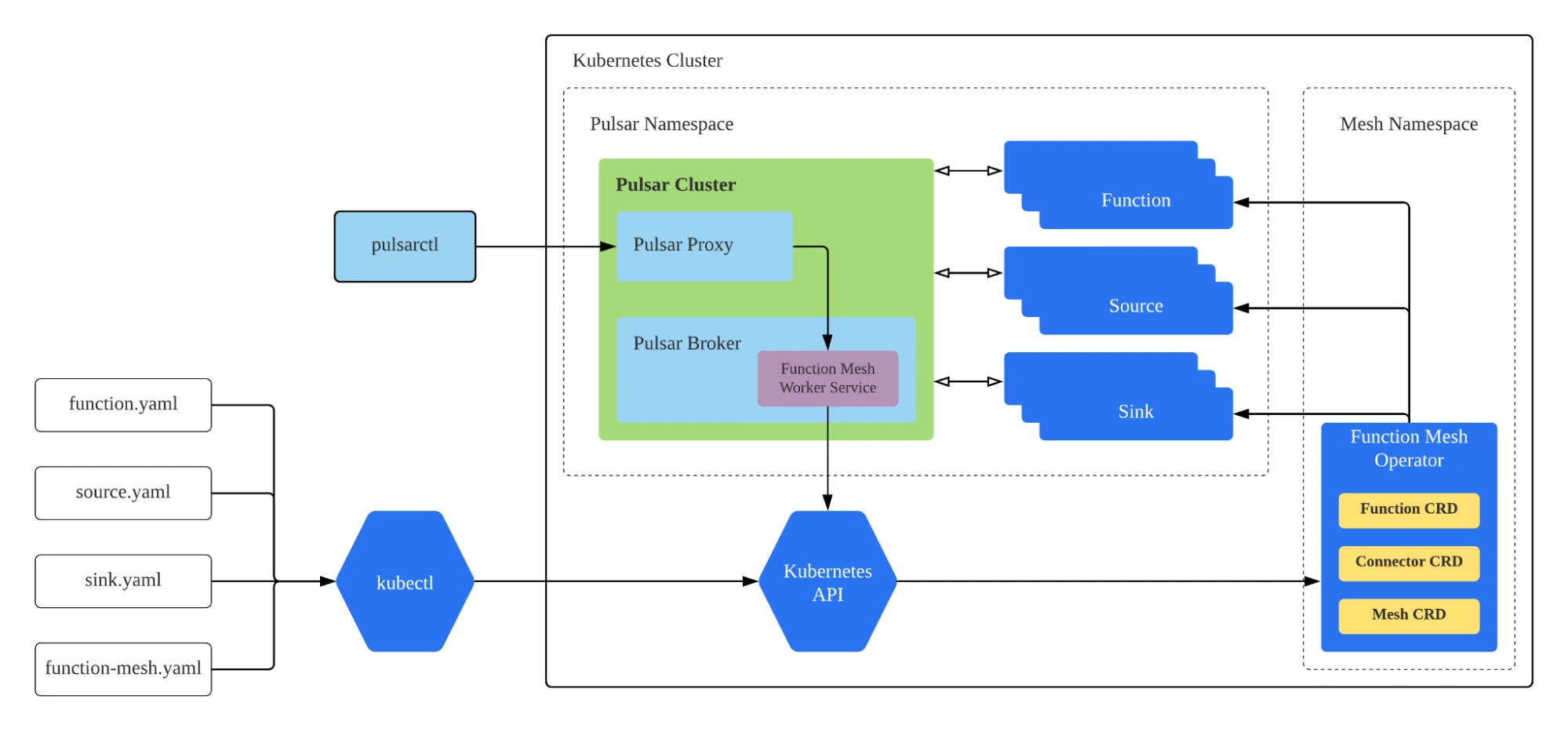
The StreamNative team proposed a plan to abstract the Function Mesh Worker Service as an interface in Pulsar 2.8. Based on the interface, the Kubernetes API can be used as an independent Worker Service implementation. This way, users only need to deploy the new Worker Service to the cluster in the same way as the Function Worker, and they can continue using pulsar-admin and pulsarctl to manage the functions in Function Mesh. To allow users to better utilize Kubernetes’ native capabilities, we added some customizable configurations in the Mesh Worker Service.
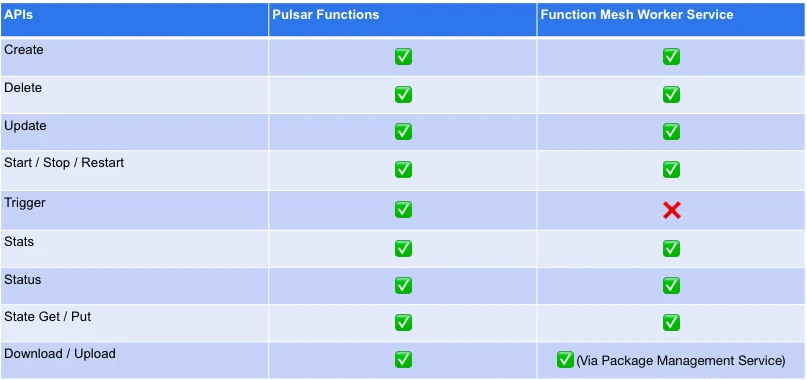
The following table lists the existing differences between the Pulsar Functions and Function Mesh Worker Service interfaces. The Function Mesh Worker Service has implemented most of the basic management interfaces, such as Create, Delete, and Update.
Getting started with Function Mesh
To install the Function Mesh Operator, you can use Operator Lifecycle Manager (OLM) or the Helm chart. As the Function Mesh Operator has been certified as a Red Hat OpenShift Operator, you can also deploy it on OpenShift. I will not demonstrate the installation steps in this post, as the deployment deserves a separate article to explain the details. For more information, see the Function Mesh documentation, and Function Mesh and Function Mesh Worker Service GitHub repositories.
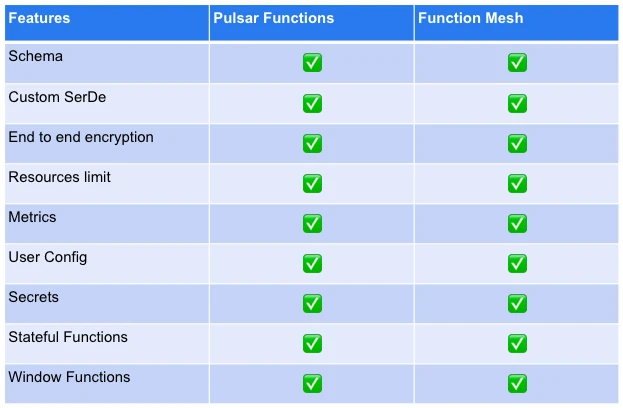
Note that all the key features in Pulsar Functions are now supported by Function Mesh as shown in Table 2, including end-to-end encryption, secret management, and stateful functions. You can see PIP 108 for details.
Using Pulsar Functions in cloud-native environments
Now that we have a basic understanding of Function Mesh, let’s explore what we can do with it for Pulsar Functions in cloud-native environments.
Automatic scaling
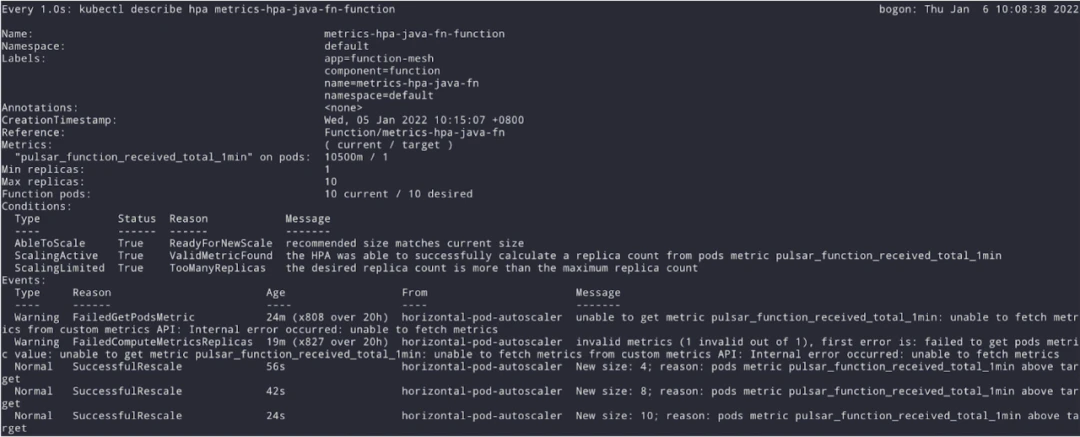
In Kubernetes, a HorizontalPodAutoscaler (HPA) supports scaling based on CPU, memory, or custom metrics. Function Mesh allows users to define CRD-level autoscaling policies. Using tools like Prometheus and Prometheus Metrics Adapter, we can use Pulsar topic metrics or function metrics for HPA references in response to varying workloads.
As shown in Figure 7, a single-copy function saw increasing workloads, and the HPA immediately scaled the number of replicas to 10 according to the corresponding metric. After the load decreased, the HPA instructed the resource to scale back down. Previously, implementing load-based autoscaling was challenging in Pulsar Functions, but it becomes much easier with Function Mesh.
Security
In a Kubernetes cluster, a Pod often needs to communicate with another Pod or even an external entity. When using Pulsar Functions, you need to run external code in many cases. If you can impose some network restrictions, you can greatly enhance cluster security. Therefore, we integrated Function Mesh with Istio, allowing users to leverage Istio’s capabilities to define Pod network rules through Istio Authorization Policy. As shown below, you can allow the function to only talk to the broker Pods, preventing it from accessing other services like BookKeeper.
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
...
spec:
rules:
- from:
- source:
principals:
- demo/ns/demo/sa/cluster-broker
selector:
matchLabels:
cloud.streamnative.io/pulsar-cluster: cluster
cloud.streamnative.io/role: pulsar-function
To further enhance security for functions, you can also use built-in security policies in Kubernetes. For example, you can define privileges and access control settings for files and users using a Security Context, or create a Secret a configure a Service Account for each function to prevent unauthorized access to the Kubernetes API.
Security has always been a top priority in our work and we have put great efforts into ensuring the security of each and every component. For example:
- Non-root images are introduced for runner images;
- The controller ensures that functions run with non-root privileges;
- Separate Service Accounts are used for functions;
- Users are able to configure authorization with the broker for each function.
Function Mesh allows users to run Pulsar Functions in a more cloud-native way, and more importantly, it is more secure, manageable, and controllable. This is another vision of the StreamNative team when developing Function Mesh.
Ecosystem integration
Function Mesh integrates Pulsar Functions into the Kubernetes ecosystem, which means users can take advantage of Kubernetes’ powerful capabilities and use Pulsar Functions with more ecosystem tools. For example, KEDA can help Pulsar Functions scale more efficiently; Buildpacks allow Function Mesh to build function images at runtime, letting users upload code directly or submit Pulsar Functions through GitHub repositories; it is even possible to integrate WebAssembly and Rust into Pulsar Functions using Krustlet. The Kubernetes ecosystem offers more possibilities, enabling Pulsar users to leverage functions in a wider range of use cases.
Conclusion and future plans
Function Mesh simplifies the management of Pulsar Functions and enables users to leverage more powerful features in Kubernetes like autoscaling. By bringing Pulsar Functions into the cloud-native world, functions can run as first-class citizens and benefit from the Kubernetes ecosystem. With Function Mesh, Pulsar Functions can run in a separate cluster (not in a Pulsar cluster, but in a compute-intensive cluster), which greatly improves resource scheduling and utilization.
Here are StreamNative’s future plans for Function Mesh:
- Improve the Function Mesh Operator, especially in terms of observability and autoscaling;
- Feature parity with Pulsar Functions to ensure a consistent user experience;
- Provide better tools to help users orchestrate Function Mesh resources and easily build complete workflows;
- Support package integration with cloud storage providers.
More on Apache Pulsar
Pulsar has become one of the most active Apache projects over the past few years, with a vibrant community driving innovation and improvements to the project. Check out the following resources to learn more about Pulsar, Pulsar Functions, and Function Mesh.
- Pulsar Virtual Summit Europe 2023 will take place on Tuesday, May 23rd, 2023! See the schedule and register now for free!
- Start your on-demand Pulsar training today with StreamNative Academy.
- Blog Using Cloud Native Buildpacks to Improve the Function Image Building Capability of Function Mesh
- Blog StreamNative’s Function Mesh Operator Certified as a Red Hat OpenShift Operator
- Doc What is Function Mesh?
Notes
1 The Function Mesh Worker Service is part of the StreamNative Cloud offering. It provides compatibility with the Pulsar Functions admin API, allowing you to submit functions using Pulsar's admin tools without altering your existing function deployment workflow.




