
Migrate to Serverless with Pulsar Functions


Pulsar Functions, introduced in Pulsar 2.0, provide a smooth path enabling Pulsar users to migrate easily to serverless technology. In this article, I discuss what Pulsar Functions are and how to develop them. I also provide a checklist of important points to consider when migrating your existing application onto this exciting new technology.
A Simple Scenario
First, let’s start with a use case. Assume that we run an e-commerce company. A critical element of our business is processing invoices for payment. In Pulsar, this is a three-step process:
- Import the invoices into an Order topic
- Execute some code to split the invoice values by comma into individual fields
- Insert the invoice values into PostgreSQL
Today, we’re going to focus on that second bullet point. Usually, the code we execute is either a serverless function we create in AWS Lambda or a full-fledged microservice. But there are significant drawbacks to this approach.
First, we’re developing a full service for what is fundamentally a small and simple piece of code. The complexity this introduces can require up to two weeks of work to implement correctly.
Second, it’s hard to maintain over time as the schema of our source data changes. This requires a full versioning and re-deployment of our service and the underlying PostGreSQL tables - a task that can require a full day of work (or more).
And third, our AWS Lambda function needs to authenticate into and out of Pulsar. This negatively impacts performance, as Pulsar has to call a Lambda function that then itself has to authenticate into Pulsar. Lambda functions, in other words, introduce a lot of unnecessary round-tripping.
Introducing Pulsar Functions
Pulsar Functions are lightweight computing processes that process data between topics. Since they run in Pulsar, they eliminate the need to deploy a separate microservice. This not only saves time - it also simplifies troubleshooting.
Pulsar Functions can be simple or complex. Besides transforming and moving data from one topic to another, we can send data to multiple topics, engage in complex routing, and batch requests.
Pulsar Functions are also easy to debug. A Function can be deployed in debugging mode, which enables us to connect to the code and debug it as it’s executing in real-time.
Developing Pulsar Functions
Creating a Pulsar Function is as easy as implementing a Pulsar Functions subclass in your preferred programming language. In the example below, I’m using Java, but you can also write Pulsar Functions in Python and Go.
Once you’ve compiled and packaged your code, you can deploy it to your Pulsar instance using the functions create command. The command takes a handful of parameters: our packaged code, as well as the input and output topics for the function.
Developing and deploying our Pulsar Function is at most two days of work. This drastically simplifies our workload and reduces our time to release. We can deploy any number of Pulsar Functions that take data from multiple topics and send them to other topics. We can also easily write status messages to the Pulsar logs. Using Pulsar Functions, our Pulsar deployment becomes increasingly more flexible and capable.
Developing a Fully-Fledged Pulsar Function
How do we take advantage of all of the rich functionality of Pulsar Functions that I described earlier?
Developing a fully-fledged Pulsar Function is as easy as implementing the Function interface in our class. We then implement a single method, called Process(). Process() gives us a context object that acts as our gateway into Pulsar. Using the context, we can access the logger, trace our output, and send messages to topics, among other tasks.
In the code below, you can see how we use Pulsar Functions to take our data input and extract the price of the invoice from it. We then use the context object to send this data to another output topic. (If we wanted to send the data to the output topic we specified when we deployed our Function, we’d just return it as the return value of the function. Here, I elected to send the data to a different topic showing how we can use Pulsar Functions for Routing and just return null from the Function.)
More Affordable Than AWS Lambda
You may be wondering why we would use Pulsar Functions when AWS Lambda can already do this for us. As I stated above, Pulsar Functions have multiple advantages over AWS Lambda, including ease of debugging and the elimination of round-trip authentication between Pulsar and Lambda.
But let’s also consider the cost of using AWS Lambda by looking at a common use case: implementing a real-time bidding system for online auctions. Let’s assume 10k bids/second (26 billion requests/month) comes out to $5k but that doesn't include compute hours, just the request charges. Assuming each request takes 100 ms and a 2048 GB VM, that would be $86k in compute charges. This doesn’t even include AWS data transfer costs!
AWS Lambda is an excellent tool for serverless functions. But it’s only excellent for small-scale use cases. The cost of Lambda makes it prohibitively expensive for any data pipeline handling billions of transactions.
Moving to Pulsar Functions can generate tremendous cost savings. When I arrived at my own company, JAMPP, the team was using Lambda exclusively and paying upwards of $30,000/month for just a small part of our pipeline. When we moved off of AWS Lambda and onto Pulsar Functions, our cost dropped to a couple hundred dollars per month - basically, the cost of hosting Pulsar on Amazon EC2 instances.
Migrating to Pulsar Functions
So let’s look at our revised architecture. In our use case, you’ll remember that we had a Java function in AWS Lambda processing data between topics. Pulsar Functions takes the place of Lambda in our architecture, simplifying both development and deployment.
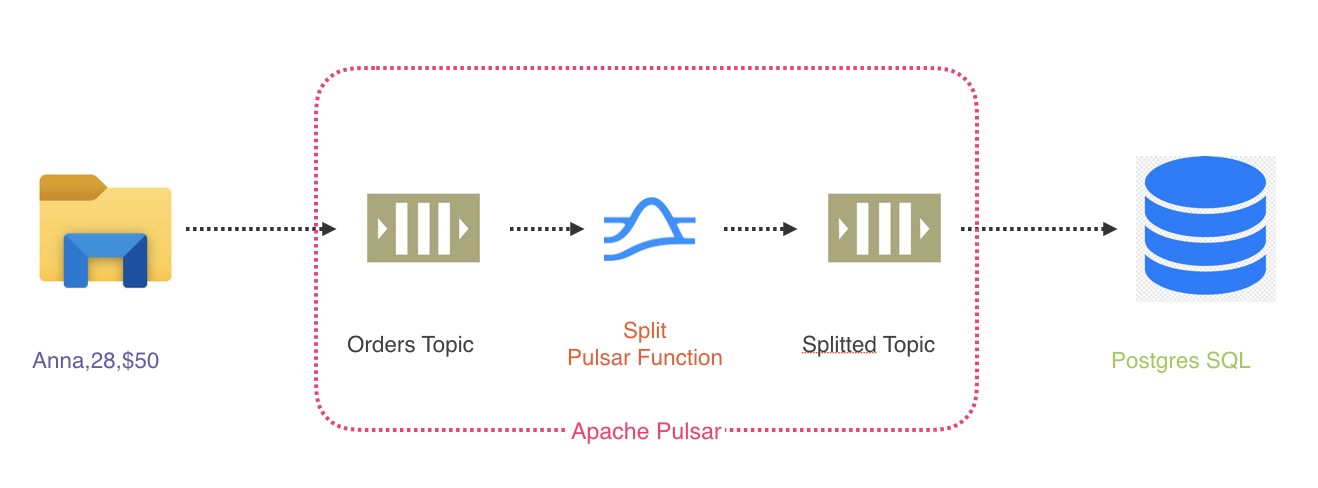
Once we have deployed our Pulsar Functions, the only thing we have left to do is to create import and dump scripts for our data. Pulsar simplifies this process with Pulsar IO. Pulsar IO enables us to define external data sources and sinks easily within Pulsar. Pulsar IO sources and sinks are themselves implemented as Pulsar Functions, which means we can create our own custom sources and sinks that we can easily debug within Pulsar.
So our migration path to Pulsar Functions is:
- Migrate all processing logic into one or more Pulsar Functions
- Switch I/O logic to using Pulsar IO sources and sinks
- Use log topics for logging data
And that’s it! At that point, you’ve fully migrated to a serverless application running completely within Pulsar.
What if you’re currently running on Kafka? No problem - Kafka-on-Pulsar enables a no-code transition from Kafka to Pulsar.
Conclusion
I’ve only touched the surface of what you can do with Pulsar Functions. Besides the features I discussed here, new and exciting additions are being developed even as we speak. For example, StreamNative recently announced Pulsar Function Mesh, which enables you to deploy a cluster of Pulsar Function services in a coordinated manner.
For now, I hope I’ve shown you how easy it is to develop Pulsar Functions and migrate your application to a serverless application running on Pulsar.
Happy migrating!
Newsletter
Our strategies and tactics delivered right to your inbox