
Background
Tencent Cloud is a secure, reliable, and high-performance cloud computing service provided by Tencent, one of the largest Internet companies in China and beyond. With a worldwide network of data centers, Tencent Cloud is committed to offering industry-leading solutions that integrate its cloud computing, big data, artificial intelligence, Internet of Things, security, and other advanced technologies to support the digital transformation of enterprises around the world. Tencent Cloud has 70 availability zones in 26 geographical regions, serving millions of customers from more than 100 countries and regions.
Currently, a Pulsar cluster at Tencent Cloud can serve around 600,000 topics in production with cost controlled at a relatively low level for different use cases. In this blog post, I will share some of our practices of optimizing Apache Pulsar for better stability and performance over the past year.
How to avoid acknowledgment holes
Different from other messaging systems, Pulsar supports both individual acknowledgments and cumulative acknowledgments (the latter is similar to Kafka offsets). Although individual message acknowledgments provide solutions to some online business scenarios, they also lead to acknowledgment holes.
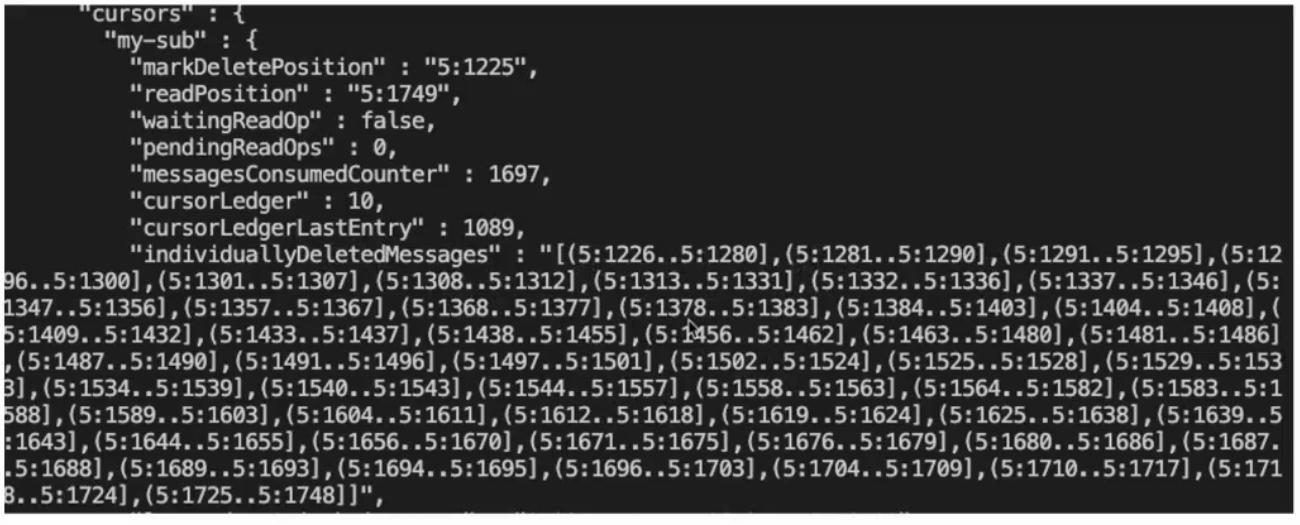
Acknowledgment holes refer to the gaps between ranges, which result in fragmented acknowledgments. They are very common when you use shared subscriptions or choose to acknowledge messages individually. Pulsar uses an abstraction called individuallyDeletedMessages to track fragmented acknowledgments in the form of ranges (intervals). Essentially, this attribute is a collection of open and closed intervals. A square bracket means the message has been processed while a parenthesis indicates an acknowledgment hole.
In Figure 1, for example, in the first interval (5:1226..5:1280], 5 is the Ledger ID and 1226 and 1280 are the Entry IDs. As the interval is left-open and right-closed, it means 5:1280 is acknowledged and that 5:1226 is not.
There are many factors that can cause fragmented acknowledgments, such as the broker’s failure to process messages. In the early versions of Pulsar, there were no returns for acknowledgments, so we couldn’t ensure the acknowledgment request was correctly handled. In Apache Pulsar 2.8.0 and later versions, AckResponse was introduced for transaction messages to support returns. Another major cause is the client’s failure to call acknowledgments for some reason, which is very common in production.
To avoid acknowledgment holes, I listed the following two solutions that we tried at Tencent Cloud for your reference.
First, carefully configure the backlog size. In Pulsar, a message can be either a batch message or a single message. For a batch message, you don’t know the exact number of entries contained in it. Note that Pulsar parses batch messages on the consumer side instead of the broker side. In practice, however, it is rather difficult to precisely calculate the backlog size.
Second, create a broker compensatory mechanism for unacknowledged messages. As individuallyDeletedMessages contains information on unacknowledged messages, we can let the broker redeliver them to the client to fill the gaps.
Before I explain the details of the second solution, let’s take a look at the different stages in which messages can be in a topic. In Figure 2, a producer publishes messages on a topic, which are then received by a consumer. Messages in different states are marked in three colors.
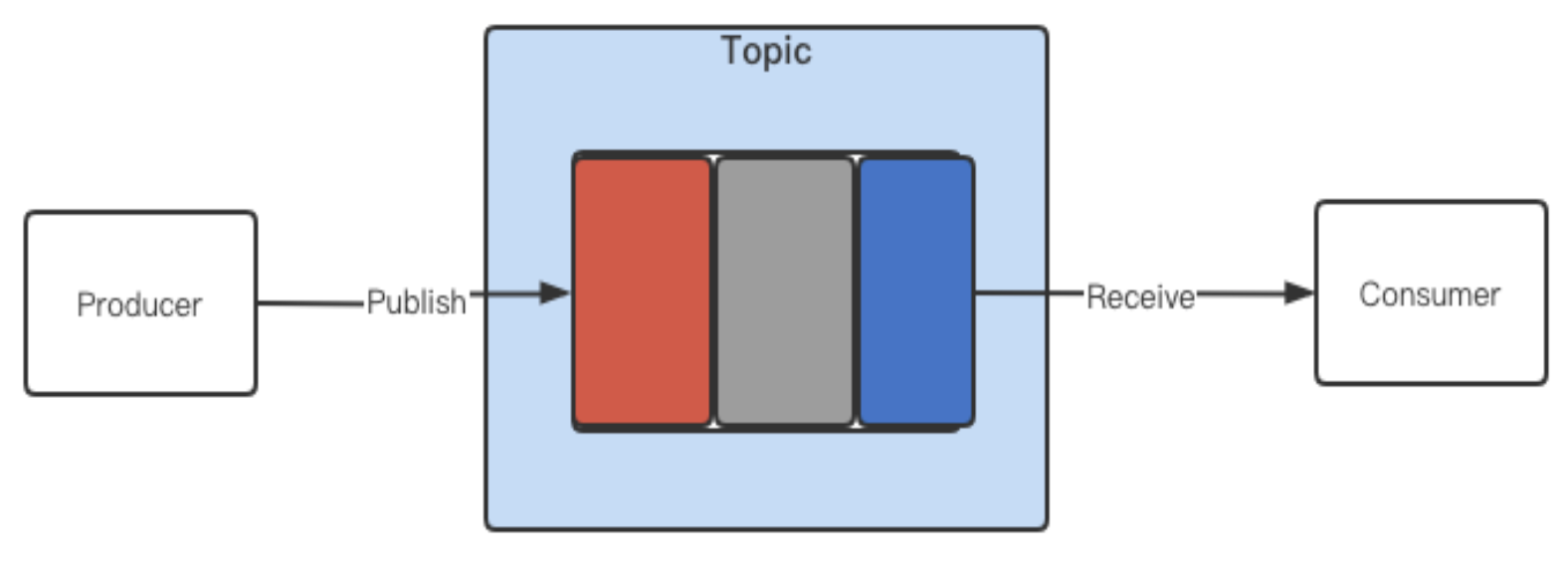
- Red: The latest messages sent to the topic.
- Gray: The messages sent to the topic but not consumed by the consumer.
- Blue: The messages already consumed and acknowledged.
Pulsar allows you to configure backlog policies to manage unacknowledged messages when the backlog size is exceeded.
- producer_exception: The broker disconnects from the client by throwing an exception. This tells the producer to stop sending new messages. It is the major policy that we are using in production at Tencent Cloud.
- producer_request_hold: The broker holds and does not persist the producer's request payload. The producer will stop sending new messages.
- consumer_backlog_eviction: The broker discards the oldest unacknowledged messages in the backlog to make sure the consumer can receive new messages. As messages are lost in this way, we haven’t used the policy in production.
So, how does Pulsar define the backlog size? In Figure 3, all messages in the stream have been consumed but not all of them have been acknowledged by the consumer.
The Pulsar community merged some code to fix the leak issue in Pulsar 2.8+. If you are using earlier versions, you might have some dirty data in your cluster. To clean up the data, we proposed the following solution.
- Get a topic list through the ZooKeeper client (You can use it to read these paths and form topic names in a set format).
- Use pulsar-admin to check whether these topics exist in the cluster. If they do not exist, the associated data must be dirty and should be deleted.
- Keep in mind that you need to back up the data before the clean-up so that you can recover topics in case of any unexpected deletion.
Bookie ledger leaks
In production, all our retention policies are no more than 15 days. Even if we add the TTL period (for example, also 15 days), the maximum message lifecycle should be 30 days. However, we found that some ledgers which were created 2 years ago still existed and could not be deleted (We are using an internal monitoring service that checks all ledger files on a regular basis).
One possible reason for orphan ledgers could be the bookie CLI commands. For example, when we use some CLI commands to check the status of a cluster, it may create a ledger on the bookie. However, the retention policy is not applicable to such ledgers.
To delete orphan ledgers, you can try the following ways:
- Obtain the metadata of the ledger. Each ledger has its own LedgerInfo, which stores its metadata, such as the creation time and the bookies that store the ledger data. If the ledger metadata are already missing, you can delete their corresponding ledgers directly.
- As a Pulsar topic represents a sequence of ledgers, you can check whether a ledger still exists in the ledger list of the topic. If it does not exist, you can delete it.
When you try to delete orphan ledgers, you need to:
- Pay special attention to the schema, which is mapped to a ledger in Pulsar. The schema ledger is stored on the bookie and the information about the schema itself is stored in ZooKeeper. If you delete the schema by accident, you need to delete the schema information on the broker first and try to recreate it from the producer side.
- Back up your data first before you delete them.
For more information about how to deal with orphan ledgers, see A Deep Dive into the Topic Data Lifecycle in Apache Pulsar.
Cache optimization
Pulsar uses caches at different levels. Topics have their own caches on the broker side. Write caches and read caches in BookKeeper are allocated based on JVM direct memory (25% of direct memory). For hot data, generally, these caches can be hit and there is no need to read the actual data.
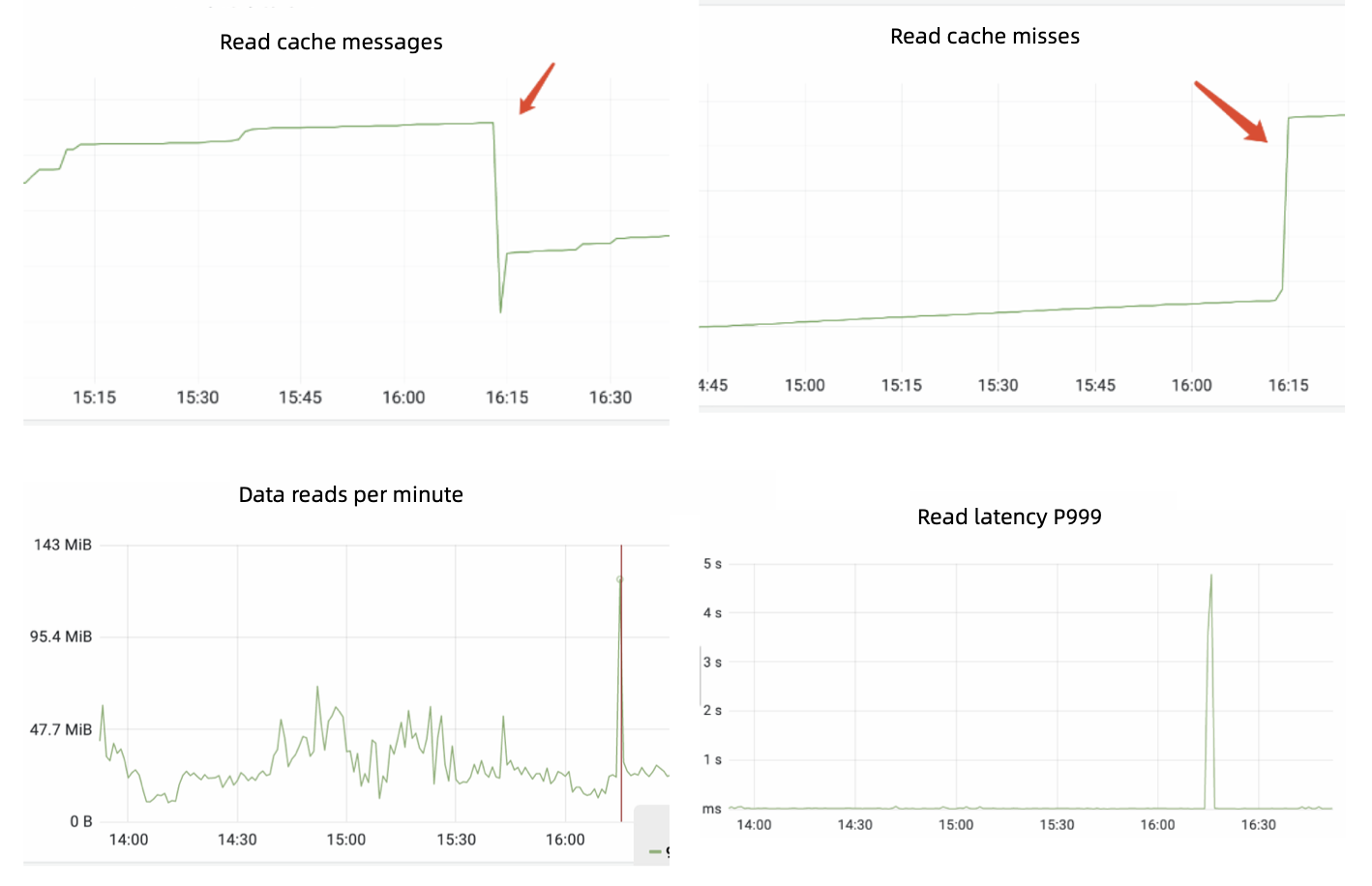
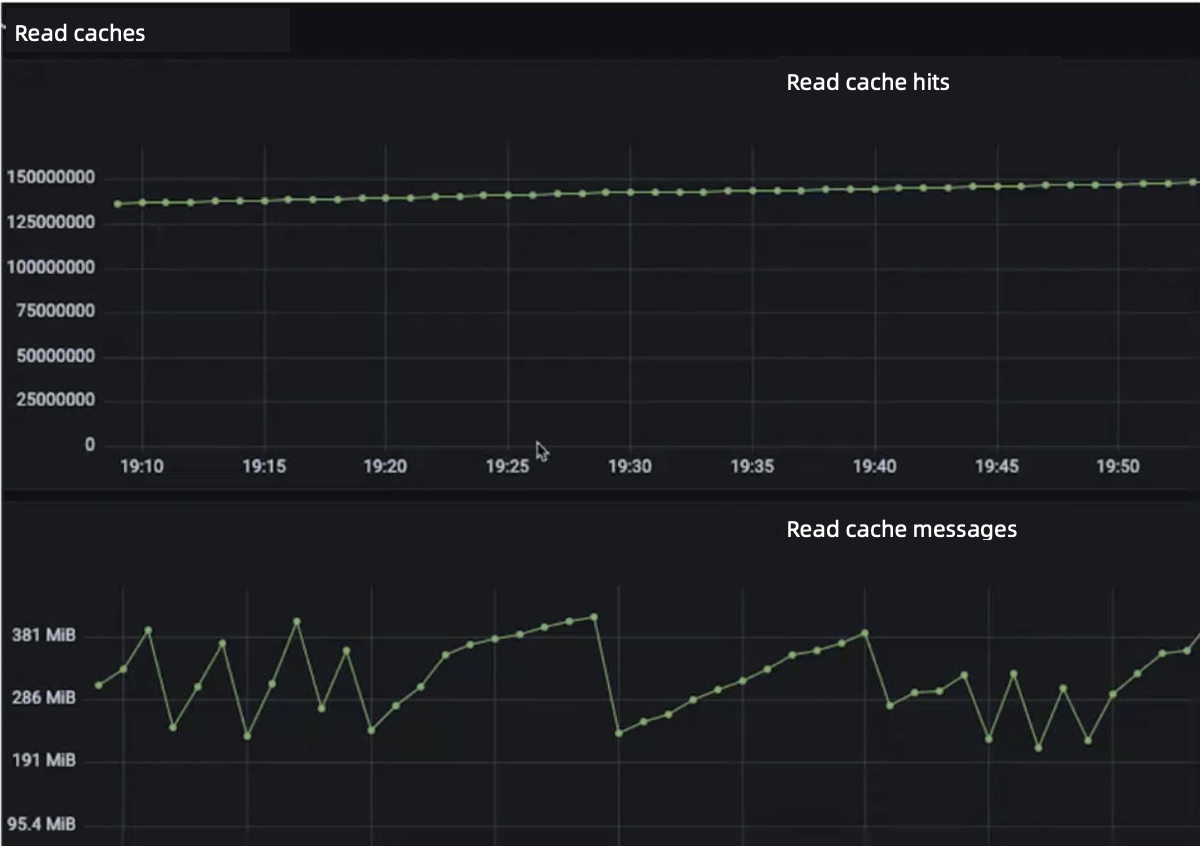
Figure 6 shows some cache metrics we observed in one of our production cases. There was a sharp decrease of read cache size, which led to the sudden increase of read cache misses. As a result, the reads on bookies saw a peak at 16:15 with the latency increasing to nearly 5 seconds. In fact, we noticed that this sudden peak happened periodically.
Let’s take a look at the following two source code snippets to analyze the reason for the above scenario.
try {
// We need to check all the segments, starting from the current
// backward to minimize the
// checks for recently inserted entries
int size = cacheSegments.size();
for (int i = 0; i
Iterate message
try { int offset = currentSegmentOffset.getAndAdd(entrySize); if (offset + entrySize > segmentSize) { // Rollover to next segment currentSegmentIdx = (currentSegmentIdx + 1) % cacheSegments.size(); currentSegment0ffset.set(alignedSize); cacheIndexes.get(currentSegmentIdx).clear(); offset = 0; }
offset + entrySize vs segmentSize
The first snippet uses a for loop to iterate messages for caches; in the second one, all caches will be cleared if the sum of offset and entrySize is larger than segmentSize. This explains the sudden decrease of read cache size. After that point, caches will be recreated.
Currently, we are using the LRU policy (OHC) to avoid sudden cache fluctuations. This is the result after our optimization:
## Summary
In this blog, we shared our experience of using and optimizing Apache Pulsar at Tencent Cloud for better performance and stability. Going forward, the Tencent Cloud team will continue to be an active player in the Pulsar community and work with other community members in the following aspects.
- Retry policies within the client timeout period. We are thinking about creating an internal mechanism featuring multiple retries (send requests) to avoid message delivery failures.
- Broker and bookie OOM optimization. Brokers may be out of memory when you have too many fragmented acknowledgments. For bookie OOM cases, they can be caused by different factors. For example, if one of the bookies in an ensemble has slow returns (Write Quorum =3, Ack Quorum = 2), the direct memory can never be released.
- Bookie AutoRecovery optimization. AutoRecovery can be deployed separately or on the same machines where bookies are running. When you deploy them together, the AutoRecovery process can’t be restarted if you have a ZooKeeper session timeout. This is because there is no retry logic between AutoRecovery and ZooKeeper. Hence, we want to add an internal retry mechanism for AutoRecovery.




