
In our first post, we highlighted how fragmented AI agents struggle to work together and argued that a real-time event bus is crucial for shared awareness and coordination. In the second post, we explore the emerging Model Context Protocol (MCP) as a standard that gives AI agents structured access to tools and data. That leaves a missing piece in between – a runtime to execute these agents and orchestrate their logic in real time. In this 3rd post of the series, we'll journey through the evolution of data processing, from traditional batch jobs to real-time streaming and lightweight compute, and see how it culminates in AI Agents. Along the way, we'll outline what a platform for realtime AI agents needs (a shared event bus, an agent registry, and a runtime for agents) and how developers organically arrive at these requirements. Finally, we'll discuss why Pulsar Functions is a natural starting point for building an agent runtime on real-time infrastructure.
From Batch to Streaming to Agents: A Data Processing Evolution
To understand why we need a new kind of runtime for AI agents, it helps to look at how data processing paradigms have evolved over time. Each stage in this evolution addressed new requirements for timeliness and interactivity:
- Batch Jobs: The earliest big data processing was done in batches. Systems would accumulate data over hours or days, then run heavy jobs (think Hadoop MapReduce or daily ETL scripts) to process the data. This model is high-throughput but high-latency – results arrive only after the batch completes. Batch frameworks like MapReduce and early Spark were great for large-scale offline analytics but too slow for reacting to events in real time. In the context of AI, batch processing means your model or logic only updates periodically, which introduces delays and stale data. Agentic AI systems that need to act on up-to-the-moment information can’t afford to wait hours for the next batch run, however they can use the results generated by these batch jobs.
- Real-Time Stream Processors: To reduce latency, stream processing frameworks emerged. Apache Storm (circa 2010), Apache Flink, Apache Spark Streaming, and others enabled continuous processing of events as they arrive, often with sub-second or milliseconds latency. These systems run long-lived jobs that ingest event streams (from message brokers like Kafka or Pulsar) and update results continuously. Streaming processors brought near-real-time responsiveness and complex event processing capabilities. Developers could write code to, say, detect fraud or update metrics on the fly instead of waiting for a batch. This was a huge step for reactive systems. However, standing up a Flink or Spark streaming job is still a heavy-weight effort – you need to manage clusters, write your logic in a specific framework API, and deploy it as a separate service. The logic is typically fixed (compiled code or queries) and scaling may require careful tuning. Still, this era proved that processing data in-motion leads to timely insights and actions.
- Lightweight Streaming Compute: In recent years, we’ve seen a push toward simplifying stream processing and embedding it within the messaging layer itself. Apache Pulsar Functions is a prime example – instead of running a separate Flink cluster, you can write a small function that consumes from one or more Pulsar topics, processes each message, and publishes results to another topic. Pulsar Functions bring a serverless feel to streaming: you focus on the per-message logic, and the Pulsar cluster handles the rest (scaling, fault tolerance, routing). Similarly, technologies like Kafka Streams (a library for building stream processing in Java apps) and cloud serverless services (like AWS Lambda triggered by Kinesis or EventBridge events) make it easier to deploy event-driven microservices. This lightweight approach drastically lowers the barrier to processing streams – no separate clusters or complex APIs, just write a simple function. The trade-off is that these functions typically handle more focused tasks (filtering, transformations, simple aggregations) and you might deploy many of them for different purposes. Still, they set the stage for dynamic logic attached directly to data streams.
- Agentic Compute: Now we arrive at the cutting edge. Instead of pre-defining every step of logic, what if the “compute” on the stream could perceive, reason, and act based on events? This is the idea of agentic compute: embedding AI agents into the stream processing. An AI agent (for example, powered by an LLM or other AI models) can subscribe to events, maintain some understanding of context, and decide on actions to take – possibly generating new events or calling external tools. This represents a major shift from traditional if/else code to more autonomous, adaptive behavior. In essence, each agent is like a microservice with a brain: it doesn’t just execute a static function; it can interpret events, make decisions, and coordinate with other agents. Agentic compute opens the door to systems that are autonomous and goal-driven, not just reactive pipelines. However, it also introduces new challenges: these agents need fast, fresh data (which streaming provides), and they need a way to share state or knowledge with each other. It’s clear that simply running one agent in isolation won’t unlock the full potential – we will need a fleet of agents that work together, which brings new infrastructure requirements.
Developer Story: From One Agent to an Ecosystem
To illustrate the need for an agentic platform, let’s walk through a scenario that a developer (let’s call her Alice) might experience:
- Building the First Agent: Alice creates an AI agent that monitors a stream of user activity events (clicks, page views, etc.) and looks for anomalies. The agent is powered by an LLM and some custom logic. It consumes events and, when it detects something unusual (say a sudden spike in errors), it can send an alert email. With just one agent, this is straightforward – she hardcodes it to listen to the event source and perform the action. It runs in a loop, reading events and reacting. Problem solved, right?
- Adding Another Agent: Next, Alice builds a second agent that responds to these anomalies. This new agent’s job is to automatically create a Jira ticket whenever an anomaly alert is raised, including context about the issue. Now she has two agents: one detecting, one responding. But how should they communicate? Initially, she might be tempted to call Agent B (ticket creator) directly from Agent A’s code when an anomaly is found. That quickly becomes a tight coupling – Agent A needs to know about Agent B. Instead, Alice decides to use an event-driven approach: Agent A simply emits an “anomaly.alert” event when it finds an issue, and Agent B listens for that event and reacts by creating a ticket. This decouples the two agents. They don’t call each other directly; they communicate through an event bus (for example, a Pulsar or Kafka topic). This way, Agent A just announces what it found, and any interested agent can listen in.
- Scaling Out with More Agents: Over time, Alice’s system grows. She introduces an Agent C that tries to diagnose the root cause of an anomaly by correlating it with recent deployments, an Agent D that notifies the on-call engineer via SMS, and perhaps an Agent E that attempts an automatic remediation if possible. All of these agents produce and consume events. For instance, Agent C might publish a “diagnosis” event that Agent E listens to before taking action. Very soon, the web of events becomes complex – in a good way (flexible), but also in a challenging way. Alice has essentially built a distributed system of AI agents, where events are the lingua franca connecting them. This loosely coupled design is exactly what we want for scalability and flexibility. Each agent can do its job independently, and as long as they agree on event schemas and topics, new agents can join in without breaking others.
- Discoverability and Coordination Challenges: With many agents in play, Alice encounters new questions. How does she keep track of what agents exist and what events they handle? If she adds a new agent into the system, how do others know about it or know that, say, two different agents are both handling the same type of event? This is where an Agent Registry starts to sound useful – a centralized (or distributed) directory where each agent can register itself (name, capabilities, event types it handles). Using a registry, Agent B could look up “Is there an agent that handles anomaly alerts? Ah yes, Agent A is the anomaly detector.” In practice the agents might not query the registry at runtime frequently, but the platform (or developers) uses it to manage the ecosystem. Alice also realizes that she needs to coordinate multi-step workflows: e.g., ensure Agent E (remediation) only runs after Agent C (diagnosis) has provided info. Rather than hard-coding those sequences inside the agents (which would reintroduce tight coupling), she wants the runtime to orchestrate these interactions. For example, one way is to have a workflow engine listening for events and invoking agents in order, but a more elegant way in an agentic system is to let the agents themselves carry state and conversations through events, which requires careful design of event protocols and perhaps a bit of higher-level orchestration logic.
- Operational Considerations: As her agent system grows, Alice confronts operational issues: What if an agent crashes or runs slowly? We need monitoring and fault tolerance for agents similar to any microservice. What if an agent produces too many events and overwhelms others? We might need backpressure or rate limiting. Also, how to deploy and scale these agents? Running each as a separate process is an option, but could be heavy with dozens of agents. Alice wonders if they can be hosted in a common runtime that takes care of scaling (much like how serverless functions scale out automatically). All these concerns point toward the need for a more structured platform to manage agent execution.
- Security and Auditability: As Alice’s fleet of agents grows and begins to touch customer data, production systems, and third-party tools, she quickly realizes that who did what, when, and with what permissions is no longer a nice-to-have—it’s critical. Each agent must authenticate to the event bus and external APIs with scoped, rotating credentials. Just as important, every action an agent takes (from reading an event to opening a Jira ticket or triggering a rollback) needs to be immutably logged with rich context: the exact input event, the LLM prompt/response pair (or model version), and the downstream side effects. These signed, tamper-evident logs become the basis for auditing, incident forensics, and compliance reporting. At scale, Alice wants the runtime to enforce least-privilege policies automatically (e.g., “only Agent E may modify deployment configs”) and to surface any deviations as security events on the same bus the agents use—closing the loop so other watchdog agents can respond. In short, an agentic platform must embed zero-trust principles and end-to-end observability from day one, or the very autonomy that makes agents powerful becomes a liability.
By the end of this journey, Alice has essentially re-discovered the requirements for an agentic platform. Her initial hacky solution grew into a complex network of intelligent components, and to keep it manageable she needs the same kind of support that past generations of compute had (like job schedulers for batch, resource managers for streaming jobs, etc.), adapted to AI agents.
Three Pillars of an Agentic Platform: Runtime, Event Bus, Registry
The story above highlights three essential components that a robust agentic platform should provide:
- Agent Execution Runtime: This is the engine that actually runs the agents’ code and orchestrates their execution. It’s analogous to a stream processing engine or an application server, but tailored for AI agents. The runtime should handle starting and stopping agents, scheduling them to handle incoming events, scaling them out (running multiple instances) if needed, and ensuring fault tolerance (if an agent instance crashes, restart it). The runtime is what keeps the whole system alive and responsive. It might also manage agent lifecycle concerns like state management (for agents that need to store context between events), version upgrades, and security isolation (running untrusted agent code safely). Orchestration is a key responsibility – not in the sense of a static pipeline, but ensuring that, for example, when an event comes in, the relevant agent(s) get invoked, possibly in parallel or in a certain order if there are dependencies. The runtime can also implement workflow logic if some agent interactions need to be coordinated beyond just pub/sub events. In summary, it’s the environment that hosts the agents and lets them do their jobs reliably.
- Shared Event Bus: At the heart of the system is a high-throughput, low-latency event bus that all agents connect to. This is typically a publish/subscribe messaging system (e.g., Apache Pulsar or Kafka topics) that delivers events to any agent that subscribes. The event bus decouples senders and receivers — agents produce events without knowing who will consume them, and agents consume events without tight coupling to producers. This loose coupling via events is what enables agents to coordinate and share context in real time. The event bus should support persistent, replayable streams (for durability and to allow new agents to catch up on past events if needed), and it becomes the communication backbone for the agents.
- Agent Registry: Just as microservice architectures often use service registries or API gateways, a multi-agent system benefits from an agent registry. This registry is a directory of all agents available in the system, along with metadata about each agent (its name/ID, what events or topics it listens to, what events it emits, maybe its purpose or health status). The agent registry allows both developers and the system itself to discover what agents exist. For example, a UI could query the registry to list all running agents. Or, if an agent wants to delegate a task, it could (programmatically) find if there's another agent capable of handling a certain event or query (though such dynamic lookup might be abstracted by the platform). The registry also helps avoid duplication and coordinate updates – if you deploy a new version of an agent, the registry gets updated. In Alice’s story, the registry was the missing piece to easily add new agents and have others be aware of them. Essentially, it provides shared knowledge of the agents.
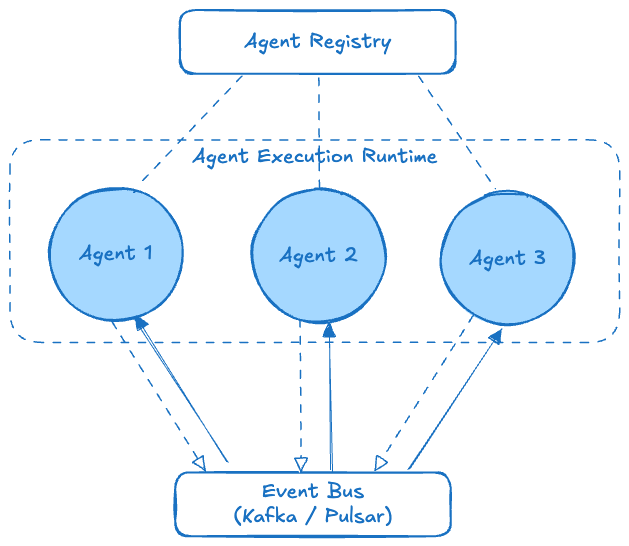
With these pieces in place, we solve the problems Alice encountered. Agents remain autonomous in their logic, but the platform provides connective tissue and governance. It’s worth noting that such an architecture aligns with broader trends in software: event-driven microservices, serverless computing, and now event-driven agents. In fact, others in the industry are converging on this idea. For example, recent discussions of “agent meshes” and event-driven agent systems echo the need for shared context and communication. In practice, an agentic platform could be built by stitching together existing tools – or, as we’ll discuss next, by extending an existing streaming system to natively support it.
Pulsar Functions – A Launchpad for Agentic Runtime
Now, how can we implement an agentic platform in reality? We have a strong hint from the evolution above: Apache Pulsar already offers two of the three components out-of-the-box (the event bus and a lightweight compute runtime). Pulsar’s messaging model provides the event bus, and Pulsar Functions serve as a built-in stream compute framework. By leveraging and extending Pulsar Functions, we can kickstart an Agent Engine and Agent Registry with relatively little new infrastructure. Let’s break down why Pulsar is a natural fit:
- Shared Event Bus: Pulsar is a cloud-native event streaming platform with a pub/sub message model. Pulsar topics can act as the channels through which agents communicate. In our architecture diagram, the gray bus could be implemented as a set of Pulsar topics (e.g., a topic per event type or a few topics for different categories of events). Pulsar’s design of decoupling producers and consumers, and allowing multiple subscriptions on a topic, fits perfectly for agents listening to the same stream. It also supports message retention and replay, which can be useful if an agent goes down and needs to catch up. In Part 1 of this series, we argued for exactly this: a real-time event stream as the backbone for AI agents. Pulsar gives us a proven, scalable backbone. StreamNative Cloud (including both Classic and Ursa engines) also natively support Kaka protocol which can be used for this backbone.
- Lightweight Compute Runtime: Pulsar Functions are essentially functions-as-a-service running inside the Pulsar ecosystem. You can deploy a snippet of code (Java, Python, Go) that subscribes to a topic, processes incoming messages, and publishes results to another topic. Under the hood, Pulsar’s Function Worker processes execute these functions and manage their lifecycle. We can view each AI agent as a more sophisticated Pulsar Function: instead of a simple transformation, its “processing logic” could involve prompting an LLM, doing some reasoning, and then emitting new events. The great thing is the scaffolding needed to run an agent is very similar to running a Pulsar Function – message in, do work, message out. Pulsar Functions already handle scaling (you can configure parallelism, and they’ll run on multiple nodes/threads as needed) and fault tolerance (failed function instances can be restarted, etc.). By using Pulsar Functions as the basis, an Agent Engine can inherit these capabilities rather than starting from scratch. The function runtime would need to be enhanced with AI-specific context handling, but the core event-driven execution model is there.
- Toward an Agent Registry: While Pulsar Functions today mainly focus on running code, the Pulsar Functions Worker service maintains metadata on all deployed functions (name, namespace, etc.). By augmenting it with agent‑specific attributes (capabilities, descriptions) and exposing it through MCP, the Functions Worker service can evolve into a full Agent Registry. Because Pulsar’s management API already treats connectors and functions as registry objects, every newly deployed function/agent could auto‑register, instantly appearing in a searchable directory of MCP tools. Other agents can then discover and invoke these tools at runtime, transforming the cluster into a dynamic, self‑describing agent ecosystem.
- Integrating External Tools via MCP: Another advantage of building on Pulsar is the ease of integrating with external systems. In Part 2 of this series, we introduce the Model Context Protocol (MCP) – an open standard that allows AI agents to access tools and data through a uniform interface. If our Agent Engine is running on Pulsar, each agent can include an MCP client or server as needed, and we can expose agents or other Pulsar Functions as MCP endpoints. In other words, the Pulsar Function could serve as a bridge between the event world and the tool APIs. MCP essentially standardizes how an agent might, for example, call a vector database or fetch information from a SaaS app. By supporting MCP within the runtime, agents can use tools or act as tools themselves in a structured way. Pulsar’s plugin architecture and function APIs could let us plug in this capability (for instance, giving functions access to an MCP context object).
- Unified Platform for Deterministic Workflows and Statistical Agents: Perhaps the most compelling reason to use Pulsar as the foundation is that many organizations already use Pulsar (or Kafka) as their central event bus for microservices and data streams. By extending that same platform to also host AI agent logic, we remove the need for a separate specialized agent orchestration system. Your AI agents become just another part of your real-time data infrastructure. They can tap into the same streams that feed your analytics and react immediately. This convergence of data and agents in one platform aligns with the idea of real-time AI. It also means ops teams have fewer systems to manage – the existing Pulsar ops (monitoring topics, throughput, etc.) now also covers agent execution metrics.
In short, we have outlined a solution for how enterprises can repurpose a battle-tested lightweight streaming compute framework (like Pulsar Function) to serve a new role in the age of AI. The agentic runtime will allow developers to deploy AI agents as easily as they deploy serverless functions, and have those agents automatically join a shared event bus and a registry of services. Each agent can then perceive events, reason (with the help of models and context), and act by emitting new events or invoking tools, all governed by the platform.
Conclusion and Next Steps
The progression from batch jobs to real-time streams to AI agents is a story of increasing immediacy and intelligence in our data systems. We started with periodic processing of static data, moved to continuous processing of streaming data, and now we’re enabling continuous reasoning and decision-making on streaming data. Building agentic AI systems on a real-time infrastructure requires rethinking the runtime environment – it’s not just about running code faster, it’s about hosting autonomous services that learn and interact. By providing a shared event bus, standard protocols like MCP for tool access, and an agent-oriented runtime, we can unlock a new class of applications that are dynamic, collaborative, and intelligent by design.
StreamNative is actively working on making this vision a reality. In the future posts, we will share more updates about how we do it to avoid reinventing the wheel. If you’re excited about the idea of AI agents seamlessly integrated with streaming data, stay tuned.
Call to Action: To learn more about this emerging technology and see it in action, join us at the Data Streaming Summit Virtual 2025 on May 28 - 29, 2025. It’s a chance to dive into the technical details, ask questions, and envision how your engineering team can build the next generation of real-time AI systems. Register for the summit, and be part of the conversation on the future of data streaming and agentic AI!




