
We are excited to announce the launch of Flink SQL on StreamNative Cloud. Flink SQL on StreamNative Cloud (aka “Flink SQL”) provides an intuitive and interactive SQL interface that reduces the complexity of building real-time data queries on Apache Pulsar. StreamNative is Cloud Partners with Ververica, the original developers of and the company behind Apache Flink. This partnership has enabled a close collaboration and integration and has helped us to create a powerful, turnkey platform for real time data insights.
Why Apache Flink and Flink SQL?
Apache Flink is a distributed, stream data processing engine that provides high throughput, low latency data processing, powerful abstractions and operational flexibility. With Apache Flink, users can easily develop and deploy event-driven applications, data analytics jobs, and data pipelines to handle real-time and historical data in complex distributed systems. Because of its powerful functionality and mature community, Apache Flink is widely adopted globally by some of the largest and most successful data-driven enterprises, including Alibaba, Netflix, and Uber.
Flink SQL provides relational abstractions of events stored in Apache Pulsar. It supports SQL standards for unified stream and batch processing. With Flink SQL, users can write SQL queries and access key insights from their real-time data, without having to write a line of Java or Python.
With a powerful execution engine and simple abstraction layer, Apache Flink and Flink SQL provide a distributed, real-time data processing solution with low development and maintenance costs. With Pulsar and Flink, StreamNative offers both stream storage and stream compute for a complete streaming solution.
Flink + Pulsar: A cloud-native streaming platform for infinite data streams
The need for real-time data insights has never been more critical. But data insights aren’t limited to real-time data. Companies also need to integrate and understand large amounts of historical data in order to gain a complete picture of their business. This requires the ability to capture, store and compute both real-time and historical data.
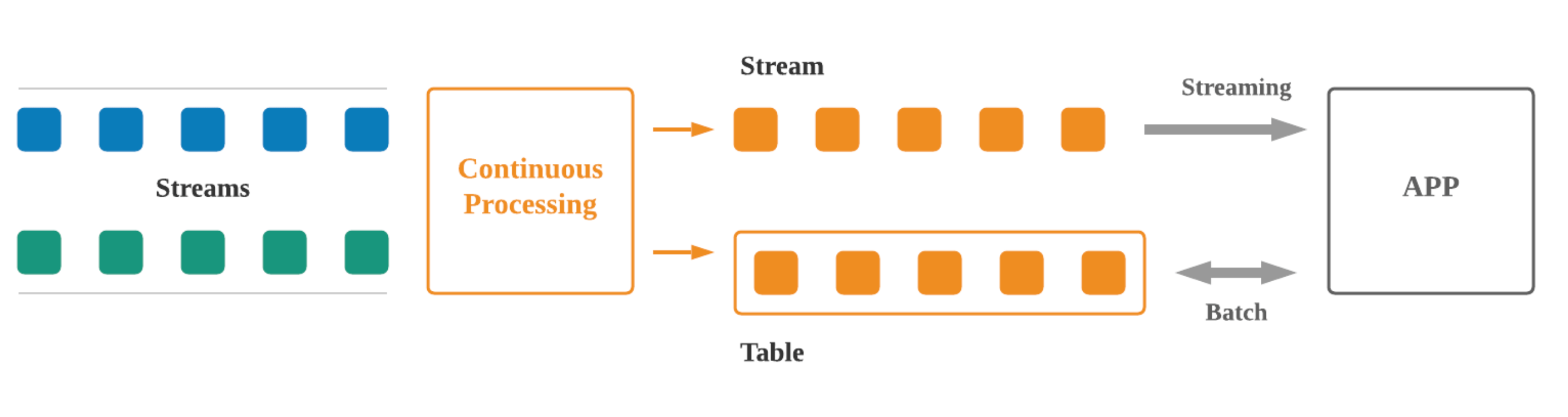
Pulsar’s tiered storage model provides the storage capabilities required for both batch and stream processing, enabling StreamNative Cloud to offer unified storage. Integrating Apache Flink and Flink SQL enables us to offer unified batch and stream processing, and Flink SQL simplifies the execution.
In a streaming-first world, the core abstraction of data is the infinite stream. The tables are derived from the stream and updated continuously as new data arrives in the stream. Apache Pulsar is the storage for infinite streams and Apache Flink is the engine that creates the materialized views in the form of streaming tables. You can then run streaming queries to perform continuous transformations, or run batch queries against streaming tables to get the latest value for every key in the stream in real time.
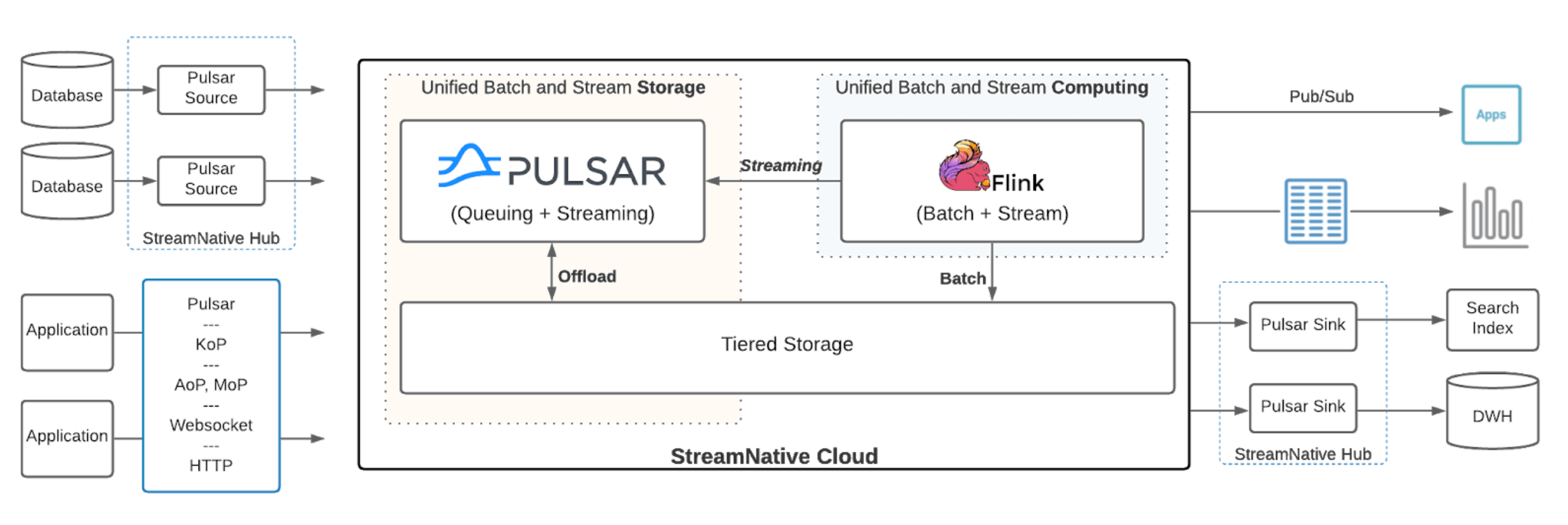
Integrating Apache Flink with Apache Pulsar enables companies to represent and process streaming data in new ways. The Pulsar infinite stream is the core storage abstraction for streaming data and everything else is a materialized view over the infinite stream, including databases, search indexes, or other data serving systems in the company. All the data enrichment and ETL needed to create these derived views can now be created in a streaming fashion using Apache Flink. Monitoring, security, anomaly and threat detection, analytics, and response to failures can be done in real-time by combining historical context with real-time data analytics.
When to use Flink SQL
With Flink SQL on StreamNative Cloud, Pulsar clusters are treated as Flink catalogs. Users can query infinite streams of events in Apache Pulsar using Flink SQL. Below are some top use cases for utilizing the streaming SQL queries over Pulsar streams:
1. Real-time monitoring
We often think of monitoring as tracking low-level performance statistics using counters and gauges. While these metrics can tell you that your CPU usage is high, they can’t tell you if your application is doing what it’s supposed to. Flink SQL allows you to define custom metrics from streams of messages that applications generate, whether they are logging events, captured change data, or any other kind. For example, a cloud service might need to check that every time a new user signs up, a welcome email is sent, a new user record is created, and their credit card is billed. These functions might be spread over multiple different services or applications, and you want to monitor that each thing happened for each new customer within a certain SLA.
Below is a streaming SQL query to monitor error counts over a stream of error codes.
INSERT INTO error_counts
SELECT error_code, count(*) FROM monitoring_stream
GROUP BY TUMBLE(ts, INTERVAL '1' MINUTE), error_code
HAVING type = ‘ERROR’;
2. Real-time anomaly detection
Security use cases often look a lot like monitoring and analytics. Rather than monitoring application behavior or business behavior, application developers are looking for patterns of fraud, abuse, spam, intrusion, or other bad behavior. Flink SQL provides a simple and real-time way of defining these patterns and querying real-time Pulsar streams.
Below is a streaming SQL query to detect frauds over a stream of transactions.
INSERT INTO possible_fraud
SELECT card_number, count(*)
FROM transactions
GROUP BY TUMBLE(ts, INTERVAL '1' MINUTE), card_number
HAVING count(*) > 3;
3. Real-time data pipelines
Companies build real-time data pipelines for data enrichment. These data pipelines capture data changes coming out of several databases, transform them, join them together, and store them in a key-value database, search index, cache, or other data serving systems.
For a long time, ETL pipelines were built as periodic batch jobs. For example, they ingest the raw data in realtime, and then transform it every few hours to enable efficient queries. For many real-time use cases, such as transaction or payment processing, this delay is unacceptable. Flink SQL together with Pulsar I/O connectors enables real-time data integration between different systems.
Now you can enrich streams of events with metadata stored in a different table using joins, or perform simple filtering of Personally Identifiable Information (PII) data before loading the stream into another system.
The streaming SQL query below shows an example enriching a click stream using a users table.
INSERT INTO vip_users
SELECT user_id, page, action
FROM clickstream c
LEFT JOIN users u ON c.user_id = u.user_id
WHERE u.level = ‘Platinum’;
Pulsar Abstractions in Flink SQL
The integration of Flink SQL and Apache Pulsar utilizes Flink's catalog API to reference existing Pulsar metadata and automatically map them to Flink’s corresponding metadata. There are a few core abstractions in this integration that map to the core abstractions in Pulsar and allow you to manipulate Pulsar topics using SQL.
- Catalog: A catalog is a collection of databases. It is mapped to an existing Pulsar cluster.
- Database: A database is a collection of tables. It is mapped to a namespace in Apache Pulsar. All the namespaces within a Pulsar cluster will automatically be converted to Flink databases in a Pulsar catalog. Databases can also be created or deleted via Data Definition Language (DDL) queries, where the underlying Pulsar namespaces will be created or deleted.
CREATE DATABASE userdb;
- Table: A Pulsar topic can be presented as a STREAMING table or an UPSERT table.
- Schema: The schema of a Pulsar topic will be automatically mapped as Flink table schema if the topic already exists with a schema. If a Pulsar topic doesn’t exist, creating a table via DDL queries will convert the Flink table schema to a Pulsar schema for creating a Pulsar topic.
- Metadata Columns: The message metadata and properties of a Pulsar message will be mapped into the metadata columns of a Flink table. These metadata columns are: - messageId: the message ID of a Pulsar message. (read-only) - sequenceId: the sequence ID of a Pulsar message. (read-only) - publishTime: the publish timestamp of a Pulsar message. (read-only) - eventTime: the event timestamp of a Pulsar message. (readable/writable) - properties: the message properties of a Pulsar message. (readable/writable)
A Pulsar topic can be presented as a STREAMING table or an UPSERT table in Flink.
STREAMING table
A streaming table represents an unbounded sequence of structured data (“facts”). For example, we could have a stream of financial transactions such as “Jack sent $100 to Kate, then Alice sent $200 to Kate”. Facts in a table are immutable, which means new events can be inserted into a table, but existing events can never be updated or deleted. All the topics within a Pulsar namespace will automatically be mapped to streaming tables in a catalog configured to use a pulsar connector. Streaming tables can also be created or deleted via DDL queries, where the underlying Pulsar topics will be created or deleted.
CREATE TABLE pageviews (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP,
user_region STRING,
WATERMARK FOR viewtime AS viewtime - INTERVAL '2' SECOND
);
UPSERT table
An upsert table represents a collection of evolving facts. For example, we could have a table that contains the latest financial information such as “Kate’s current account balance is $300”. It is the equivalent of a traditional database table but enriched by streaming semantics such as windowing. Facts in a UPSERT table are mutable, which means new facts can be inserted into the table, and existing facts can be updated or deleted. Upsert tables can be created by specifying connector to be upsert-pulsar.
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED
) with (
“connector” = “upsert-pulsar”
};
By integrating the concepts of streaming tables and upsert tables, FlinkSQL allows joining upsert tables that represent the current state of the world with streaming tables that represent events that are happening right now. A topic in Pulsar can be represented as either a streaming table or an upsert table in Flink SQL, depending on the intended semantics of the processing on the topic.
For instance, if you want to read the data in a topic as a series of independent values, you would treat a Pulsar topic as a streaming table. An example of such a streaming table is a topic that captures page view events where each page view event is unrelated and independent of another. On the other hand, if you want to read the data in a topic as an evolving collection of updatable values, you would treat the topic as an upsert topic. An example of a topic that should be read as an UPSERT table in Flink is one that captures user metadata where each event represents the latest metadata for a particular user id including its user name, address or preferences.
A dive into Flink SQL on StreamNative Cloud
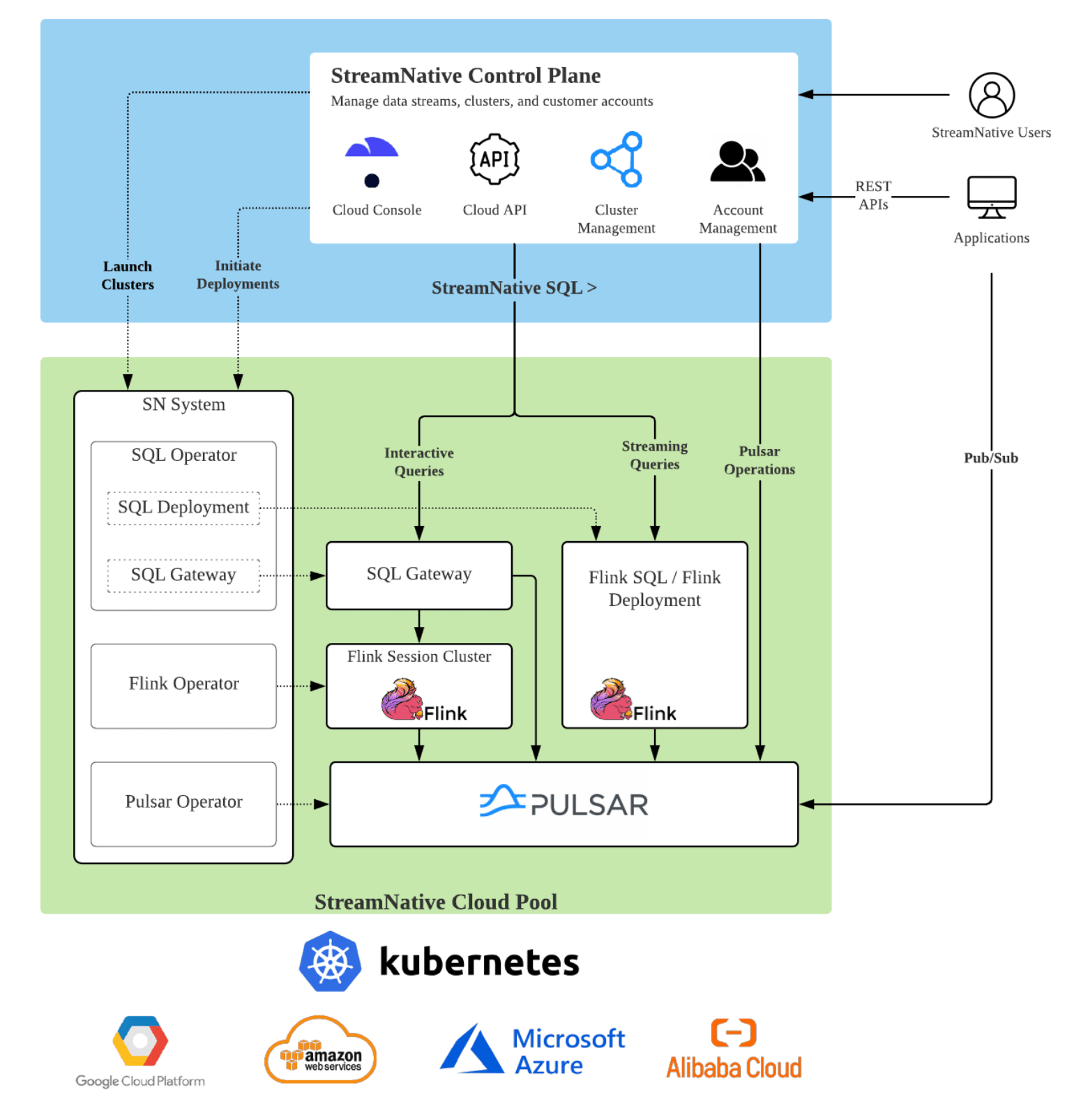
StreamNative Cloud operates out of a control plane and cloud pools.
The control plane includes the backend services that StreamNative manages in its own cloud account. The backend services mainly include a Cloud API service and a Cloud console. Users can interact with StreamNative Cloud via the Cloud console, and applications can interact with it via the Cloud API service.
The cloud pools can be managed by StreamNative in its own cloud account or in the customers’ cloud accounts. Pulsar clusters are run inside the cloud pools. The SQL queries are also run on the cloud pools.
The diagram below demonstrates how the authentication/authorization is implemented in our system. Here it assumes that data has already been ingested into the Pulsar clusters on StreamNative Cloud, but you can ingest data from external data sources, such as events data, streaming data, IoT data, and more, using Pulsar’s pub/sub messaging API.
Users or applications can interact with the StreamNative control plane to create a Pulsar cluster. Once the Pulsar cluster is ready, users can either create a Flink session cluster and use the SQL editor in StreamNative’s Cloud console to initiate interactive queries, or create long-running deployments to continuously process data streams in the Pulsar cluster.
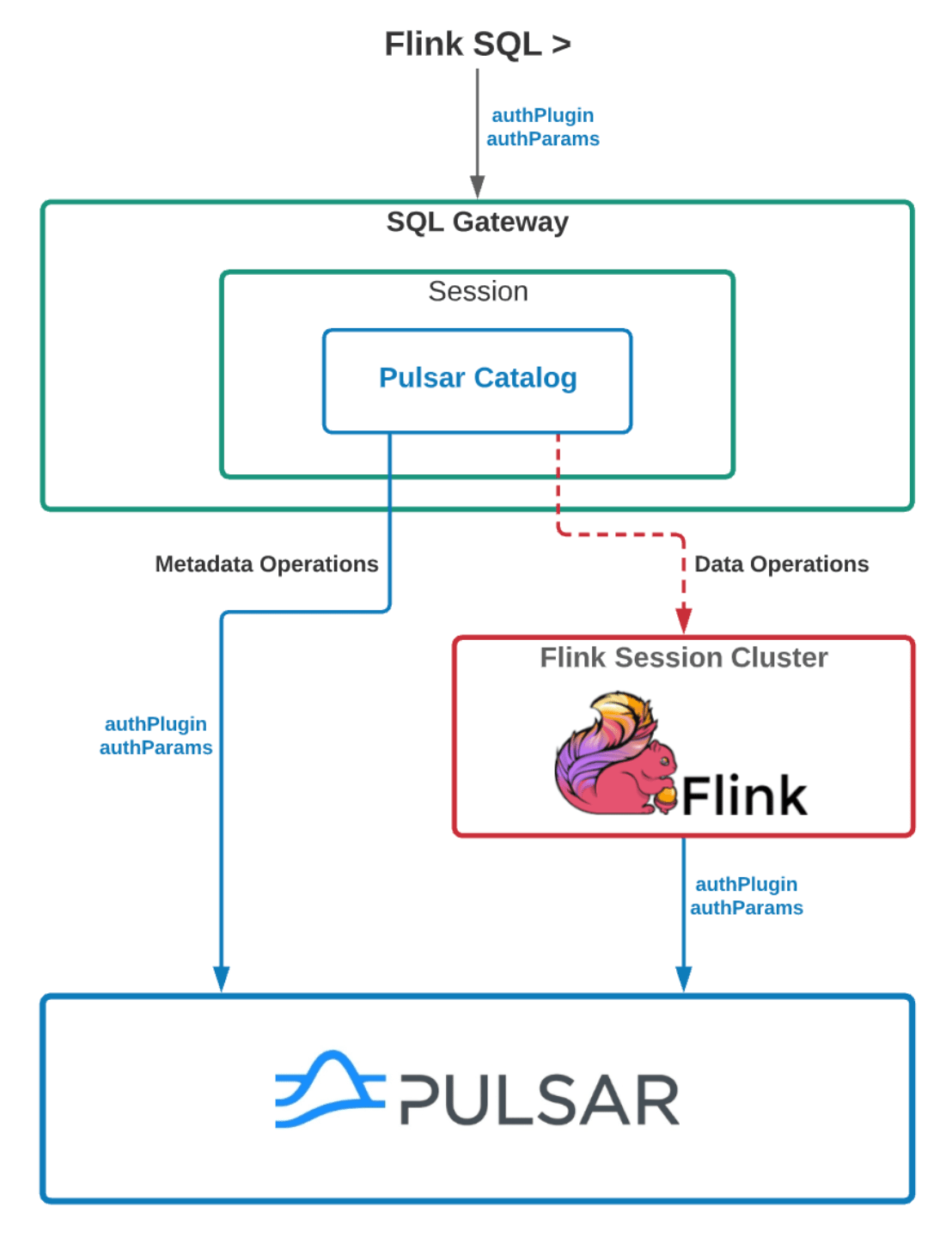
For each Flink session cluster, there is a SQL Gateway process which parses SQL queries and executes queries locally or submits queries to the Flink cluster. Each SQL session in the SQL Gateway will initiate Pulsar catalogs, with each catalog representing one existing Pulsar cluster. The catalog contains all the necessary information needed to securely access the Pulsar cluster. For DDL queries, they are directly executed in the SQL gateway, while all the DML queries will be submitted to the Flink session cluster to execute. All the SQL queries are impersonated as the actual user who submits them for security purposes.
What’s Next for Flink + Pulsar integration on StreamNative Cloud?
We are releasing Flink SQL on StreamNative Cloud as a developer preview feature to gather feedback. We plan to add several more capabilities such as running Flink SQL as continuous deployments, providing the ability to run arbitrary Flink jobs, and more, as we work with both the Pulsar and Flink communities to build a robust, unified batch and streaming solution.
How Do I Access Flink SQL on StreamNative Cloud?
You can get started by watching the quick start tutorial for Flink SQL on StreamNative Cloud. We’d love to hear about any ideas you have for improvement and to work closely with early adopters. Note, the Flink SQL offering is only available on paid clusters for now. We will give free cloud credits to our early adopters. If you are interested in trying out, please email us at info@streamnative.io.
To learn more about Flink SQL, you can:
- Watch the intro video.
- Read about Flink SQL here.
- Get started with Flink SQL in StreamNative Cloud.
Finally, if you’re interested in messaging and event streaming, and want to help build Pulsar and Flink, we are hiring.





