
The Very Large Data Bases (VLDB) conference — the flagship annual conference for databases and data management—highlights breakthroughs that advance our field. This year, our paper, “Ursa: A Lakehouse-Native Data Streaming Engine for Kafka”, received the Best Industry Paper award at VLDB 2025. Chosen from a highly competitive set of industry submissions from leading tech companies like Databricks, Meta, Alibaba, the recognition is both humbling and energizing. We’re grateful to the community and excited to share what we’ve built.
This paper introduces Ursa, our next-generation data streaming engine that is fully Kafka-compatible yet fundamentally different under the hood. Ursa is the first and only “lakehouse-native” streaming engine – built to write data directly to lakehouse table formats like Apache Iceberg and Delta Lake instead of using traditional broker disks. By eliminating Kafka’s usual leader-based replication and external connector jobs, Ursa slashes streaming infrastructure costs by up to 10× while maintaining seamless compatibility with the Kafka API. Its design meets modern cloud requirements for elasticity, high availability, and efficiency: users get the same Kafka experience, but backed by an architecture that leverages cloud object storage and shared metadata services to decouple compute from storage. The result is a system that lets you think in terms of data and workloads – not low-level infrastructure – and delivers consistent performance across cloud environments with dramatically lower operational overhead.
What the VLDB Best Industry Paper Means
The Very Large Data Bases (VLDB) conference is the database community’s flagship annual gathering. Each year, its program committee runs a rigorous, multi-stage review to surface standout research and industrial system papers that pair technical originality with real-world impact. From the industry track, only one paper is selected for the Best Industry Paper award—recognizing work that advances production systems with novel, practical techniques. In 2025, our Ursa paper received this distinction, underscoring the significance of our leaderless, lakehouse-native approach to modern cloud data streaming.
Ursa: A Lakehouse-Native Data Streaming Engine for Kafka
We launched Ursa a year ago to answer a clear gap: teams want Kafka’s developer experience without inheriting the cost and operational weight of legacy, leader-based & disk-centric designs. Rather than lift-and-shift Kafka onto cloud VMs or ask customers to run everything in their own account, we took the harder route—rethinking the engine from first principles. Ursa keeps full Kafka compatibility while rebuilding the core around three ideas: leaderless architecture, lakehouse-native storage, and cloud-native elasticity. The result is a platform designed for today’s data stacks: no leader/follower bottlenecks, no hard dependency on expensive disks, and a direct path from streams to tables.
Ursa architecture at a glance: Over the course of developing the Ursa engine, our team faced numerous technical hurdles and achieved a series of breakthroughs to realize this new design. You can read all the details in the paper itself. Below are a few of the key innovations that define Ursa’s architecture:
- Leaderless architecture with zone-local brokers – Ursa gets rid of the single-leader-per-partition model entirely. Every broker is an equal peer that can accept writes, and data is replicated implicitly via a shared durable storage layer rather than broker-to-broker copying. This means there are no leader elections and no inter-zone replication traffic bogging down the system. Thanks to built-in zone affinity, producers and consumers connect to local brokers in their nearest availability zone, eliminating cross-AZ network hops while still ensuring data durability and high availability across zones. In short, Ursa’s brokers are leaderless and stateless – which greatly simplifies operations and improves resiliency by removing a whole class of failure scenarios and network overhead.
- Lakehouse-native storage – Unlike conventional streaming engines that store logs on local disks and later copy data via connectors into analytic data lakes, Ursa writes data directly to cloud object storage in open table formats (e.g. Iceberg, Delta Lake) in real time. This lakehouse-native design means your streaming data is immediately available as table-formatted files in the data lake, eliminating the need for separate ETL pipelines or sink connectors to get data into analytics systems. Long-term data is stored in highly durable, cost-effective object storage instead of expensive replicated local disks, which cuts storage costs massively and enables easy integration with tools like Spark, Trino, or Snowflake for batch queries. By leveraging the cloud’s built-in durability and scalability, Ursa avoids the 3× data duplication of traditional triple replication and instead stores the data durably in the lakehouse.
- “Stream–table” duality through built-in compaction – Ursa introduces the powerful concept of stream-table duality, unifying real-time streams and batch tables on the same underlying data. To achieve this, Ursa’s storage engine continuously compacts the append-only log data into columnar files in the background. Incoming records are first written to a row-based write-ahead log (WAL) on object storage for low-latency streaming. Then a background compaction service aggregates and converts these raw log segments into compressed Parquet files, organizing them into Apache Iceberg/Delta Lake table formats. The result is that each Kafka topic is simultaneously a live event stream and an up-to-date analytics table. Applications can consume recent data via the Kafka API with minimal latency, or query historical data via SQL on the lakehouse – all from a single storage source without needing to maintain dual pipelines. This duality not only simplifies data architecture but also improves efficiency, since one storage tier serves both streaming and analytic use cases.
- Pluggable write-ahead log for cost/latency tradeoffs – A one-size-fits-all approach doesn’t work for every workload, so Ursa’s design allows choosing different WAL storage modes per use case. For latency-relaxed workloads that can tolerate slightly higher tail latency, Ursa can use cloud object storage as the WAL (i.e. writing events directly to S3, GCS, etc.), which eliminates virtually all cross-AZ network costs and offers unbeatable durability at the expense of a bit more write latency. Meanwhile, for latency-sensitive topics that demand single-digit millisecond persistence, Ursa supports a latency-optimized WAL (for example, using Apache BookKeeper - a fast distributed log service with replication) to ensure quicker acknowledgments. This pluggable WAL architecture lets you optimize each stream for what matters most – cost or latency – or even run hybrid modes. Thanks to multi-tenant storage profiles, each tenant or topic can select the ideal storage policy (object-storage WAL vs. low-latency WAL), balancing throughput, latency, and cost requirements as needed. In practice, this flexibility means Ursa can handle a wide spectrum of use cases, from cost-efficient data ingestion, to mission-critical low-latency streams, all within one platform.
In addition to the above, Ursa’s cloud-native architecture cleanly separates compute from storage. Brokers are effectively stateless processors that can be scaled up or down independently of storage capacity – no more overprovisioning large disks on every broker “just in case.” This makes elasticity trivial and allows deploying Ursa in multi-cloud and Bring-Your-Own-Cloud (BYOC) environments with ease. In fact, Ursa is designed to run natively in your own cloud account (on AWS, GCP, Azure, etc.), with the streaming service leveraging your cloud’s object store for data persistence. You only pay for the throughput and storage you actually use, not idle capacity. All of these innovations contribute to Ursa’s dramatic cost savings and operational simplicity: by eliminating inter-zone data transfer, local disks, external connectors, and duplicate data copies, Ursa can deliver the same or better streaming performance at a fraction of the cost of traditional Kafka deployments.
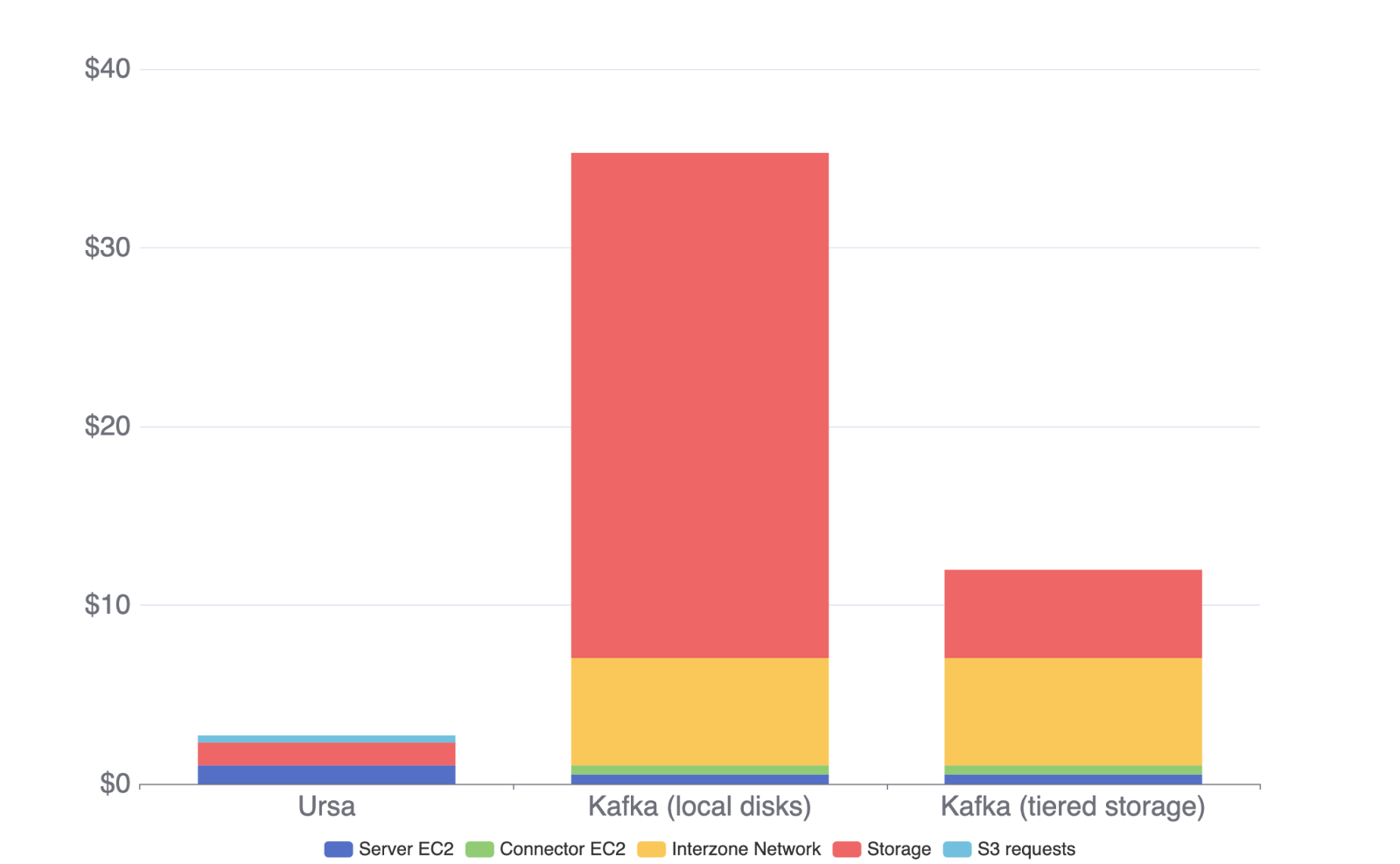
Figure 1. Data Streaming Cost Comparison: Ursa vs. Kafka (lower is better). For more details, read the Ursa paper.
Team & Community
Ursa is the result of an incredible team effort over multiple years. We want to thank our engineering team at StreamNative – both current and former members – who worked tirelessly to turn the vision of a truly lakehouse-native streaming engine into reality. This achievement is a testament to their technical skill, creativity, and perseverance in tackling hard distributed systems problems.
We are also deeply grateful to the open-source communities that laid the groundwork for Ursa. Apache Kafka® provided the ubiquitous protocol and community that we built upon, and Apache Pulsar® (along with its BookKeeper store) inspired many of the cloud-native ideas in Ursa’s design. Without the innovations in these projects and the feedback from their user communities, Ursa would not have been possible. We thank everyone in the Kafka, Pulsar, Iceberg & DeltaLake ecosystems for their contributions, as well as our customers and partners for continually pushing us with real-world requirements and feedback. This award is as much a recognition of the community’s progress as it is of our own work.
See Ursa in Action
As mentioned above, Ursa is not just an idea on paper or a prototype in a lab – it’s already running in production and proving its value. In fact, Ursa has been powering StreamNative’s managed cloud service, where it recently sustained 5 GB/s of Kafka throughput at only ~5% of the cost of other platforms. In real terms, that’s on the order of a 10× cost reduction for the same workload, validating Ursa’s cost-efficiency claims in practice. We invite you to experience Ursa for yourself.
For those interested in learning more, we encourage you to read the VLDB paper for a deep dive into Ursa’s design and internals. If you have any questions, feel free to reach out to ursa-paper@streamnative.io, or meet us in person. We are presenting our research at the VLDB conference in London this week and will also be sharing insights about Ursa and the future of streaming at the upcoming Data Streaming Summit 2025 in San Francisco on September 29–30, 2025. We look forward to seeing you there, and to continuing the conversation about the industry’s shift toward lakehouse-native, leaderless streaming architectures. The journey has only begun, and we’re excited about what’s next!





