Introduction
The shift from stateless serverless functions to persistent, event-driven agents represents a major evolution in how we build and run cloud applications. Traditional serverless functions (FaaS) are short-lived and stateless – they execute on demand and terminate, treating each invocation in isolation. In contrast, agents are long-running, context-aware event processors that stay alive to continuously react, reason, and learn from streaming data. In this post (part 2 of our series), we explore how runtime responsibilities change when moving from functions to agents. We’ll clarify what an “agent runtime” needs to provide and how modern streaming platforms support this shift.
From Stateless Functions to Persistent Agents
Stateless serverless functions excel at executing discrete logic in response to events or requests. A function runs with no memory of past invocations – it processes the input and produces an output, then ends. This simplicity makes functions easy to scale horizontally and manage, since each event can be handled by a fresh instance without worrying about prior state. Frameworks like AWS Lambda or Apache Pulsar Functions brought a serverless feel to event processing: you write a small function for each message and let the platform handle scaling and fault tolerance. This lightweight approach drastically lowered the barrier to processing streams – no clusters to manage, just write your function and deploy. The trade-off, however, is that each function handles a narrow task in isolation, without context from previous events. If you need to maintain state or memory (say, to track a running average or user session), a purely stateless function must rely on external storage or context passed in every time.
Persistent event-driven agents take a different approach. An agent is more like a continuously running microservice with a brain – it doesn’t spin up every time for each event, but instead subscribes to streams of events and maintains context over time. Agents can perceive incoming events, remember what happened before, and make decisions or trigger actions based on both current and past data. This means an agent can implement more autonomous, adaptive behavior, not just a fixed input-output transformation. For example, imagine an IoT sensor application: a stateless function could process each temperature reading independently, but an agent could continuously update a running average and detect anomalies over time. Using an agent with state, you can update a counter and average with each reading (as shown in the Pulsar Functions example below), enabling continuous monitoring in-context. In essence, while a function might be a single if/else check, an agent is an ongoing control loop that learns and reacts. This opens the door to systems that are more autonomous and goal-driven, not just static event processors.
Why make this change? Certain problems simply cannot be solved elegantly with ephemeral, stateless logic. Consider an AI-driven support bot: a stateless version would treat every user query independently, leading to repetitive or generic answers. A stateful agent can carry on a conversation, remembering the user’s context and refining answers. Or consider fraud detection on a stream of transactions: a stateless function might flag one transaction at a time, whereas an agent can notice patterns across many events (maintaining a sliding window of behavior). By evolving from functions to agents, we enable contextual awareness – the runtime can persist data, patterns, or ML model state between events. The result is more intelligent responses and the ability to handle complex, long-lived tasks.
That said, agents introduce new challenges. They need to run continuously (not just for milliseconds), hold state safely, and coordinate with other agents. Running one agent in isolation is only the beginning – true agentic systems will involve a fleet of agents working together, which brings new infrastructure requirements. We next examine how the runtime’s responsibilities shift to meet these needs.
Shifting Runtime Responsibilities: Ephemeral vs. Always-On
Moving from functions to agents shifts a lot of work from the application logic to the runtime platform. A serverless function runtime (like a FaaS platform) is responsible for quickly scheduling function instances on-demand, passing in an event, then tearing down the instance. In an agent-based system, the runtime must provide a richer, always-on environment. Key shifts in runtime responsibilities include:
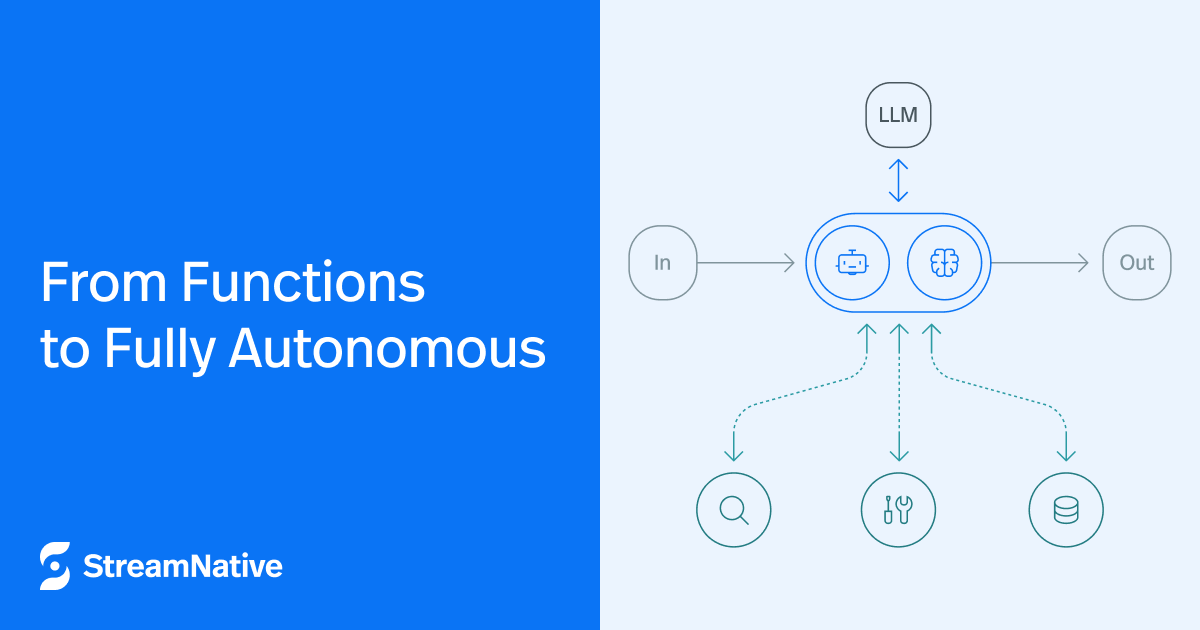
- Continuous Execution & Event Streaming: Instead of invoking code only per event, an agent runtime keeps agents alive and fed with events. The runtime must connect each agent to event sources (e.g. subscription to a message topic) so it can receive a continuous stream of messages. This is fundamentally different from a function that wakes up with a single event – an agent’s event loop never really stops. The platform needs to handle event subscriptions, backpressure, and delivery of events to agents in real-time. In practice, this means treating a streaming event bus as the default I/O for agents. Each agent listens on certain topics or event types and reacts as events arrive, rather than being invoked via direct calls. This decoupled, publish/subscribe model provides a “nervous system” for agents to sense the world and communicate with each other.
- State Management and Context: In a stateless function model, any persistence (counters, caches, DB lookups) is external to the function. But an agent runtime is expected to give agents a way to remember information between events. This could be in-memory state that the agent process holds, or more robustly, state backed by a distributed store for durability. For example, Pulsar Functions allow storing key-value state that is persisted in a distributed storage tier, which an agent can use as “memory”. The runtime should expose easy APIs for an agent to put/get state, counters, or context data. Moreover, this state should be checkpointed or replicated so that if the agent is restarted on another node, it can resume with its prior context. Providing streaming memory in the runtime makes agents context-aware by design – they don’t start from scratch on each event. As a bonus, because agents’ state changes can be logged as events, we gain an audit trail of an agent’s thinking process, which improves observability and debugging. (By contrast, a stateless function’s internal variables vanish after each invocation, making it hard to trace how a decision was made.)
- Long-Lived Compute & Resource Management: Running dozens of always-on agents is more akin to running a microservice cluster than executing isolated lambdas. The agent runtime must therefore take on concerns like scheduling agents across a cluster, managing their lifecycles, and handling failures. If an agent crashes or a node running it goes down, the runtime should automatically restart that agent elsewhere to keep the system running. It should also manage scaling: for example, if an agent is consuming a high-volume stream, the platform might spawn multiple instances (or partitions) of that agent to handle the load – akin to how stream processing jobs scale by partitioning data. This is tricky when state is involved, but techniques like sharding by key or using consumer group semantics can distribute events among agent instances while keeping each instance’s state separate. In essence, the runtime needs to provide the same reliability mechanisms that distributed stream processors or message consumers use – e.g. horizontal scaling, work partitioning, and fault recovery – but now applied to AI agents. One industry guide notes that traditional FaaS platforms fall short for stateful, long-running services, and combining stream processing with functions is needed to get correct, resilient behavior under failures. An agent runtime fulfills that by marrying the elastic scheduling of serverless with the durable state management of streaming systems.
- Inter-Agent Communication & Composition: In a non-trivial agent system, agents will talk to other agents. We want to avoid tightly coupling agents (like one agent calling another directly), since that creates brittle dependencies. Instead, the runtime should encourage event-driven composition – agents emitting events that other agents consume, forming an indirect cooperation. This was illustrated in our example of Agent A raising an “anomaly.alert” event that Agent B listens for, rather than calling B’s API directly. The runtime’s role here is to provide a common event hub and possibly higher-level orchestration. By having all agents communicate via the event bus, the platform enables loose coupling and dynamic workflows (similar to how microservices communicate via an event broker). Complex sequences can be achieved by chaining events through multiple agents, rather than one monolithic function. In fact, breaking a complex task into multiple smaller event-driven agents is a recommended pattern – it allows independent scaling and updates of each piece. The runtime may also maintain an Agent Registry as a directory of all active agents and the event types they handle (so you can discover producers/consumers of certain events). While the registry concept is beyond basic runtime, it highlights that in an agent system the platform, not the individual code, must handle discoverability and coordination at scale.
- Observability, Security, and Governance: An agent that runs continuously and makes autonomous decisions needs oversight. The runtime should therefore provide built-in logging, tracing, and monitoring of agents’ actions. When every input, output, and intermediate step can be captured as an event or logged with context, we get a transparent view of what the agent is doing and why. This is critical in enterprise settings – you need to answer “who did what, when?” even for AI-driven actions. The platform might tag events with agent IDs, maintain audit logs of tool calls (e.g. if an agent triggers an external API), and allow operators to set guardrails (like rate limits or circuit breakers if an agent goes haywire). Security is another runtime concern: agents must be authenticated and authorized when accessing the event bus or external systems, just like any microservice. The runtime may manage credentials or tokens for agents and ensure each agent only sees the event streams it’s permitted to. Overall, the agent runtime is responsible for providing production-grade controls around these always-on autonomous programs, akin to how Kubernetes or FaaS platforms provide monitoring and security for microservices. Without such support, running hundreds of agents could become unmanageable or risky. (Imagine debugging a bug in an AI agent if you had no trace of its decisions – not acceptable in most orgs!)
In summary, the move to agents shifts us from a world of fleeting stateless functions to one of persistent services that think and act. The runtime environment must evolve from merely executing code to hosting living, stateful processes. An often-cited analogy is that agents are like microservices that reason – they need the same infrastructure as microservices (for availability, scaling, communication), plus additional support for memory and intelligent behavior. This raises the question: how do we practically provide such an agent runtime? The good news is we don’t have to start from scratch – streaming platforms are stepping up to fill this role.
Building an Agent Runtime on Streaming Platforms
The capabilities described above might sound ambitious, but modern streaming data platforms (like Apache Pulsar or Apache Kafka ecosystems) already offer many of these pieces. In fact, an event streaming platform is a natural foundation for an agentic runtime, because it was designed to feed continuous streams of data to long-running consumers with scalability and fault-tolerance. Let’s break down how streaming infrastructure supports the shift from functions to agents:
- Unified Event Bus: At the heart of any streaming platform is a publish/subscribe log or message queue. This serves as the communication backbone for agents. All events that agents produce or consume flow through topics on this bus. Because topics support multiple subscribers and decouple senders from receivers, agents can easily form dynamic networks of interactions. For example, multiple anomaly-detection agents can all subscribe to the same “errors” topic, and multiple responder agents can act on an “alert” topic – without any of them explicitly calling each other. The platform ensures each agent gets the events it’s interested in (with filtering, partitioning, and backpressure handling under the hood). Importantly, stream brokers provide retention and replay of events. If an agent goes down for a minute, it can come back and replay missed events from the log, so no critical data is lost – something you’d have to build manually in a traditional RPC system. As one guide puts it, a data streaming platform acts as the “central nervous system” for agents, letting them collaborate in a loosely coupled but coordinated way. This real-time event backbone is a prerequisite for scalable, context-sharing agents.
- Embedded Computation (Stream Functions): Platforms like Pulsar and Kafka have introduced ways to run user code directly in the messaging layer. Pulsar Functions, for instance, are lightweight functions-as-a-service that consume topics and produce results to other topics. This is essentially the same pattern an agent follows (read events, do some processing, emit new events). By leveraging such frameworks, we can deploy agents onto the stream platform itself. In fact, the StreamNative Agent Engine (early access) does exactly this – it builds on Pulsar’s function runtime to host AI agents. Each agent is packaged like a serverless function and deployed to the cluster, automatically wired into the event bus and registered in a directory. Under the covers, the function runtime has been tweaked to handle long-lived AI workloads, but the core is standard and battle-tested. This means the heavy lifting of scaling and restarting instances is largely solved by the existing function scheduler. Apache Pulsar’s Function Worker, for example, can run many functions (now agents) across the cluster, track their status, and restart them on failure. Similarly, Kafka Streams and Kafka-based frameworks allow stateful stream processing in applications and could be extended to agent logic. The bottom line: streaming platforms give us a serverless execution environment where code can run near the data stream, continuously and with managed parallelism. Adapting that to agents is often a matter of adding the right libraries (for AI reasoning, etc.), not inventing a whole new orchestration system.
- Stateful Stream Processing: One of the breakthroughs in stream processing has been the ability to maintain state with strong consistency (think of Apache Flink or Kafka Streams state stores). These same capabilities can back an agent’s memory. Pulsar Functions, for instance, offer a state API that stores state in a distributed storage, accessible across function restarts. Kafka Streams uses embedded RocksDB state stores for stateful processing. By tapping into these, an agent runtime lets agents store their context locally but durably. For the agent developer, it might be as simple as using a
context.putState("key", value) API(like in Pulsar Functions) or calling a state store in Kafka Streams. The streaming platform handles replication of that state behind the scenes. This fulfills the agent’s need for memory without introducing a separate database for developers to worry about. Additionally, because state is tied to event processing transactions in some frameworks, we can get exactly-once processing – meaning an event and the state update associated with it will be atomic. That guarantee is crucial when an agent, say, updates its knowledge base upon receiving an event; we wouldn’t want to lose or double-apply those updates if a failure happens. In short, streaming platforms have evolved to support stateful functions, and those are a perfect substrate for agents. We leverage the fact that stream processors already solved consistency, checkpointing, and scaling of stateful tasks. - Coordination via Consumer Groups: How to scale out multiple instances of an agent? Streaming platforms use consumer group protocols to divide partitions of a topic among consumers. This same mechanism can be used to run N instances of an agent in parallel (each handling a subset of events). For example, Kafka’s rebalance protocol or Pulsar’s subscription modes ensure that if you have, say, 3 instances of an agent and 10 partitions, each instance gets some partitions assigned. If one instance dies, its partitions are redistributed to the others. This provides automatic load balancing and failover for agents at the event ingestion level. The agent runtime can simply manage agent instances as consumers in a group. The result: dynamic scaling and recovery come “for free” from the streaming platform’s consumer infrastructure. Agents can increase or decrease in number, and the system will balance the work accordingly – much easier than having to manually orchestrate which agent handles what. This again shows how an agent runtime can repurpose proven components of stream processing.
- Built-in Observability and Governance: Streaming systems are designed for high-throughput, observable data flows. They often integrate with monitoring tools, and every message can carry metadata (timestamps, IDs, etc.). By running agents on the streaming platform, we inherit a lot of this observability. We can trace an event from its origin through the topics into the agent’s processing and out to the events the agent produces. In fact, because agents emit events for their actions, we can log those to a separate audit topic. For example, an agent’s decision or outcome might be published as an event that a monitoring service subscribes to, creating an audit log in real-time. The platform also provides central control: you can update or pause an agent by updating its subscription or deployment in the cluster, much as you would manage a streaming job. And since all agents run on a common substrate, things like security policies (who can publish/subscribe to which topic) uniformly apply to agent communication. This avoids the patchwork of ad-hoc integration you’d have if each agent were a standalone script with its own connections. In effect, the streaming platform serves as both the data layer and the control plane for your agents. This convergence is powerful – it means fewer moving parts and a single unified infrastructure for real-time data and AI agents.
It’s worth noting that both the open-source community and vendors are actively working on making streaming platforms more “agent-friendly.” For example, the concept of an Agent Registry can be built on top of the function metadata store (as noted with Pulsar’s function worker metadata being extended for agent descriptors). And the emerging Model Context Protocol (MCP) is being integrated so agents can call external tools/services in a standardized way – with streaming runtimes acting as the glue (this will be discussed in a later post). The trend is clear: we are repurposing battle-tested stream processing tech to serve AI agents. By doing so, we avoid reinventing wheels around messaging, state, and reliability, which not only reduces engineering overhead but also significantly accelerates time to market.
As one eBook put it, “agents leverage event streaming to collaborate without rigid dependencies,” and a streaming platform connects data sources, processes events in motion, and enforces governance – exactly what’s needed for a robust agent ecosystem.
Conclusion and Next Steps
The evolution from stateless functions to persistent agents is ultimately about bringing intelligence closer to the data. We began with simple functions triggered by events, which was great for modularizing logic but limited in context. Now, by running agents that live in the stream, we enable continuous reasoning on real-time data streams. This shift requires the runtime to take on new responsibilities – from managing state and long-lived processes to brokering rich inter-agent communication. Fortunately, streaming platforms like Pulsar and Kafka have grown into exactly the kind of always-on, scalable backbone that agents need. They provide the connective tissue (event bus), the muscle (compute runtime), and the memory (state stores) to support autonomous, event-driven agents at scale.
As we continue this series, we will delve into specific aspects like multi-agent coordination, open protocols for tool integration, and design patterns for agent systems. The journey from functions to agents is just one step toward a new paradigm of real-time, intelligent applications. Now is a great time to start experimenting with these concepts yourself. Sign up for the Data Streaming Summit (Training & Workshop on September 29 and Conference on September 30, 2025). These events will showcase cutting-edge developments in streaming and AI agents, and offer a hands-on chance to apply what we’ve discussed. Whether you’re a developer or an architect, embracing an agent-driven runtime could be the key to building the next generation of reactive, smart services. Come join us and be part of this real-time revolution! (We look forward to seeing the innovative agents you create.)