
Today, we are excited to introduce Function Mesh, a serverless framework purpose-built for event streaming applications. It brings powerful event-streaming capabilities to your applications by orchestrating multiple Pulsar Functions and Pulsar IO connector for complex event streaming jobs on Kubernetes.
What is Function Mesh
Function Mesh is a Kubernetes operator that enables users to run Pulsar Functions and connectors natively on Kubernetes, unlocking the full power of Kubernetes’ application deployment, scaling, and management. For example, Function Mesh relies on Kubernetes’ scheduling functionality, which ensures that functions are resilient to failures and can be scheduled properly at any time.
Function Mesh is also a serverless framework to orchestrate multiple Pulsar Functions and I/O connectors for complex streaming jobs in a simple way. If you’re seeking cloud-native serverless streaming solutions, Function Mesh is an ideal tool for you. The key benefits of Function Mesh include:
- Eases the management of Pulsar Functions and connectors when you run multiple instances of Functions and connectors together.
- Utilizes the full power of Kubernetes Scheduler, including deployment, scaling and management, to manage and scale Pulsar Functions and connectors.
- Makes Pulsar Functions and connectors run natively in the cloud environment, which leads to greater possibilities when more resources become available in the cloud.
- Enables Pulsar Functions to work with different messaging systems and to integrate with existing tools in the cloud environment (Function Mesh runs Pulsar Functions and connectors independently from Pulsar).
Function Mesh is well-suited for common, lightweight streaming use cases, such as ETL jobs, and is not intended to be used as a full-power streaming engine.
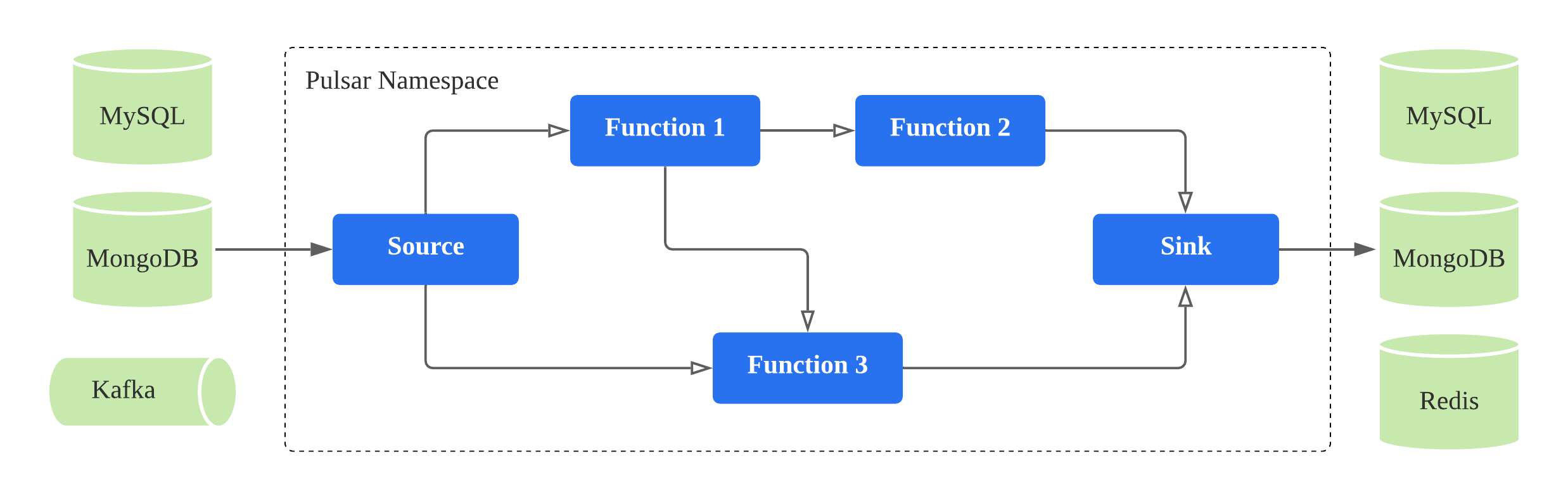
Why Function Mesh
Pulsar introduces Pulsar Functions and Pulsar I/O since its 2.0 release.
Pulsar Functions is a turnkey serverless event streaming framework built natively for Apache Pulsar. Pulsar Functions enables users to create event processing logic on a per message basis and bring simplicity and serverless concepts to event streaming, thus eliminating the need to deploy a separate system. Popular use cases of Pulsar Functions include ETL jobs, real-time aggregation, microservices, reactive services, event routing, and more.
Pulsar IO connector is a framework that allows you to ingress or egress data from and to Pulsar using the existing Pulsar Functions framework. Pulsar IO consist of source and sink connectors. A source is an event processor that ingests data from an external system into Pulsar, and a sink is an event processor that egresses data from Pulsar to an external system.
Both Pulsar Functions and Pulsar I/O have made building event streaming applications become simpler. Pulsar Functions supports running functions and connectors on Kubernetes. However the existing implementation has a few drawbacks:
- The function metadata is stored in Pulsar and the function running state is managed by Kubernetes. This results in inconsistency between metadata and running state, which makes the management become complicated and problematic. For example, the StatefulSet running Pulsar Functions can be deleted from Kubernetes while Pulsar isn’t aware of it.
- The existing implementation uses Pulsar topics for storing function metadata. It can cause broker crash loops if the function metadata topics are temperaily not available.
- Functions are tied to a specific Pulsar cluster, making it difficult to use functions across multiple Pulsar clusters.
- The existing implementation makes it hard for users deploying Pulsar Functions on Kubernetes to implement certain features, such as auto-scaling.
Additionally, with the increased adoption of Pulsar Functions and Pulsar I/O connectors for building serverless event streaming applications, people are looking for orchestrating multiple functions into a single streaming job to achieve complex event streaming capabilities. Without Function Mesh, there is a lot of manual work to organize and manage multiple functions to process events.
To solve the pain points and make Pulsar Functions Kubernetes-native, we developed Function Mesh -- a serverless framework purpose-built for running Pulsar Functions and connectors natively on Kubernetes, and for simplifying building complex event streaming jobs.
Core Concepts
Function Mesh enables you to build event streaming applications leveraging your familiarity with Apache Pulsar and modern stream processing technologies. Three concepts are foundational to build an event streaming applications: streams, functions, and connectors.
Stream
A stream is a partitioned, immutable, append-only sequence for events that represents a series of historical facts. For example, the events of a stream could model a sequence of financial transactions, like “Jack sent $100 to Alice”, followed by “Alice sent $50 to Bob”. A stream is used for connecting functions and connectors. The streams in Function Mesh are implemented by using topics in Apache Pulsar.
Function
A function is a lightweight event processor that consumes messages from one or more input streams, applies a user-supplied processing logic to one or multiple messages, and produces the results of the processing logic to another stream. The functions in Function Mesh are implemented based on Pulsar Functions.
Connector
A connector is an event processor that ingresses or egresses events from and to streams. There are two types of connectors in Functions Mesh:
- Source Connector (aka Source): an event processor that ingests events from an external data system into a stream.
- Sink Connector (aka Sink): an event processor that egresses events from streams to an external data system.
The connectors in Function Mesh are implemented based on Pulsar IO connectors. The available Pulsar IO connectors can be found at StreamNative Hub.
FunctionMesh
A FunctionMesh (aka Mesh) is a collection (can be either a Directed Acyclic Graph (DAG) or a cyclic graph) of functions and connectors connected by streams that are orchestrated together for achieving powerful stream processing logics. All the functions and connectors in a Mesh share the same lifecycle. They are started when a Mesh is created and terminated when the mesh is destroyed. All the functions and connectors are long running processes. They are auto-scaled based on the workload by Function Mesh.
How Function Mesh works
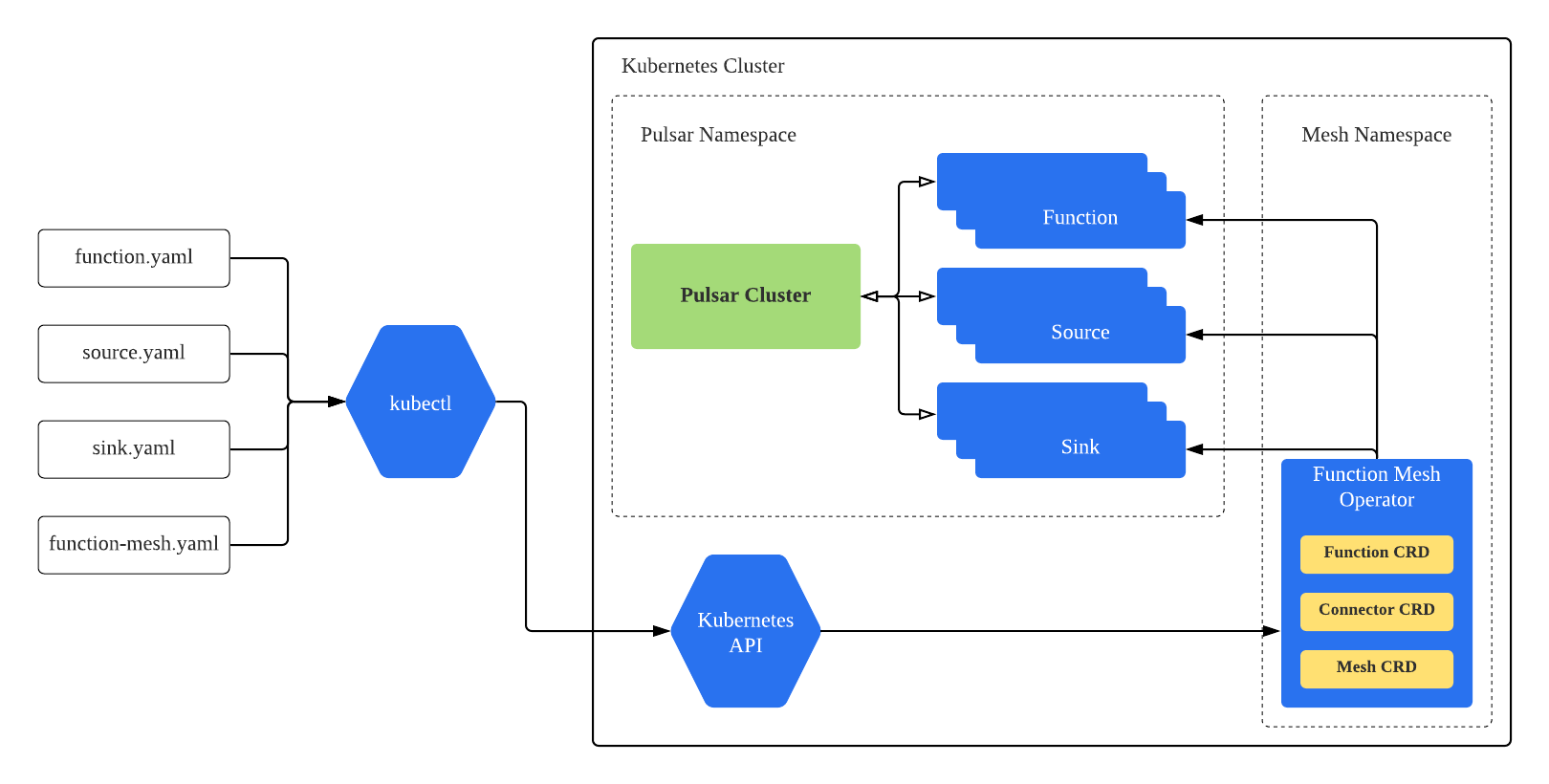
Function Mesh APIs build on existing Kubernetes APIs, so that Function Mesh resources are compatible with other Kubernetes-native resources, and can be managed by cluster administrators using existing Kubernetes tools. The foundational concepts are delivered as Kubernetes Custom Resource Definitions (CRDs), which can be configured by a cluster administrator for developing event streaming applications.
Instead of using the Pulsar admin CLI tool to send function admin requests to Pulsar clusters, you now can use kubectl to submit a Function Mesh CRD manifest directly to Kubernetes clusters. The Function Mesh controller watches the CRD and creates Kubernetes resources to run the defined Function/Source/Sink, or Mesh. The benefit of this approach is both the function metadata and function running state are directly stored and managed by Kubernetes to avoid the inconsistency problem that was seen in Pulsar’s existing approach.
The following diagram illustrates a typical user flow of Function Mesh.
Function Mesh Internals
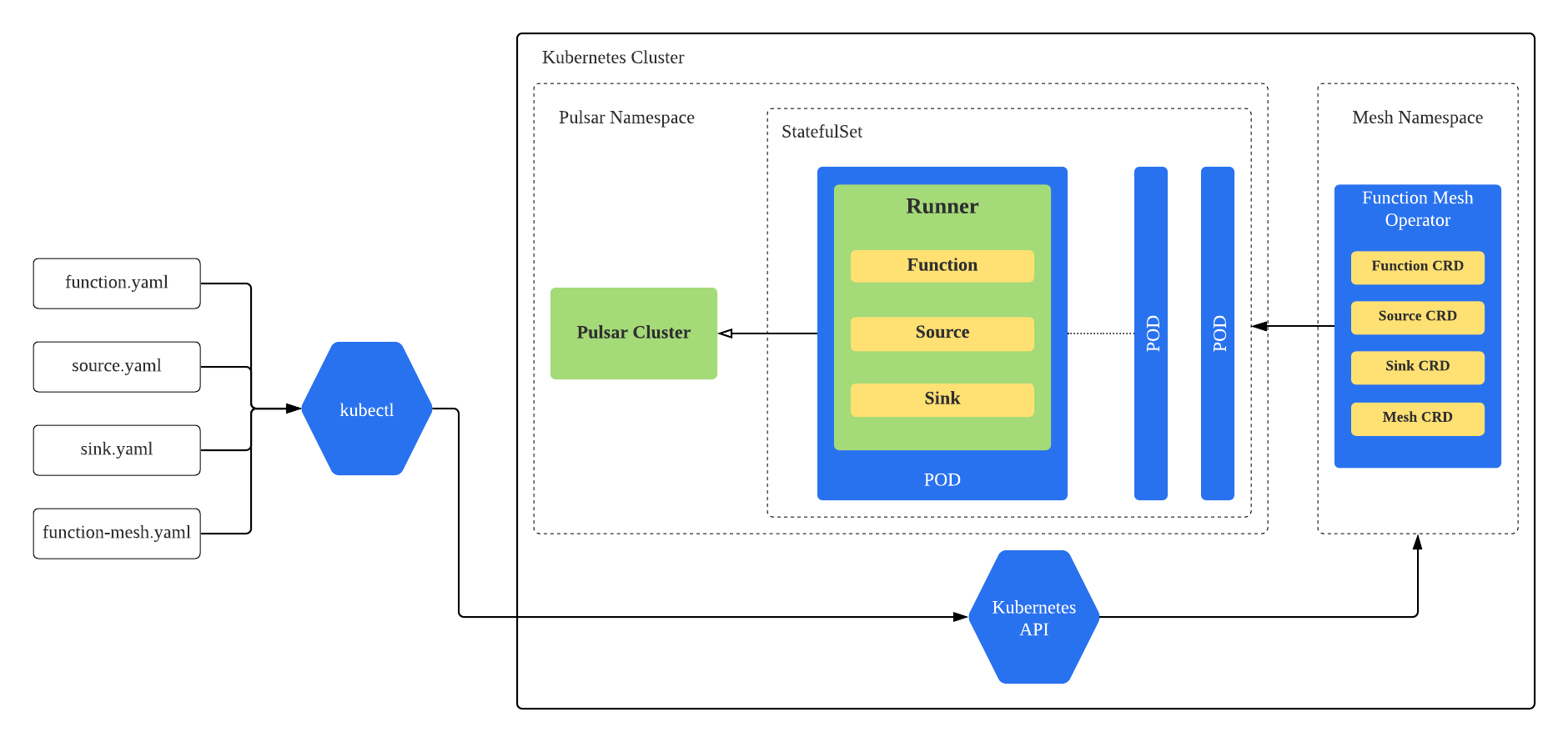
Function Mesh mainly consists of two components. One is a Kubernetes operator that watches Function Mesh CRDs and creates Kubernetes resources (i.e. StatefulSet) to run functions, connectors, and meshes on Kubernetes; while the other one is a Function Runner that invokes the functions and connectors logic when receiving events from input streams and produces the results to output streams. The Runner is currently implemented using Pulsar Functions runner.
The below diagram illustrates the overall architecture of Function Mesh. When a user creates a Function Mesh CRD, the controller receives the submitted CRD from Kubernetes API server. The controller processes the CRD and generates the corresponding Kubernetes resources. For example, when the controller processes the Function CRD, it creates a StatefulSet to run the function. Each pod of this function StatefulSet launches a Runner to invoke the function logic.
How to use Function Mesh
To use Function Mesh, you need to install Function Mesh operator and CRD into the Kubernetes cluster first. For more details about installation, refer to installation guide.
After installing the Function Mesh operator and deploying a Pulsar cluster, you need to package your functions/connectors, define CRDs for functions, connectors and Function Mesh, and then submit the CRDs to the Kubernetes cluster with the following command.
$ kubectl apply -f /path/to/custom-crd.yaml
Once your Kubernetes cluster receives the CRD, the Function Mesh operator will schedule individual parts and run the functions as a stateful set with other necessary resource objects.
Below we illustrate how to run Functions, Connectors and Meshes respectively with some examples.
How to run functions using Function Mesh
Function Mesh does not change how you develop Pulsar Functions to run in the cloud. The submission process just switches from a pulsar-admin client tool to a yaml file. Behind the scenes, we developed the CRD resources for Pulsar Function and the controller to handle it properly.
After developing and testing your function, you need to package it and then submit it to a Pulsar cluster or build it as a Docker image and upload it to the image registry. For details, refer to run Pulsar Functions using Function Mesh.
This following example for Function CRD launches an ExclamationFunction inside Kubernetes and enables auto-scaling, and it uses a Java runtime to talk to the Pulsar messaging system.
apiVersion: compute.functionmesh.io/v1alpha1
kind: Function
metadata:
name: function-sample
namespace: default
spec:
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
replicas: 1
maxReplicas: 5
image: streamnative/function-mesh-example:latest
logTopic: persistent://public/default/logging-function-logs
input:
topics:
- persistent://public/default/source-topic
typeClassName: java.lang.String
output:
topic: persistent://public/default/sink-topic
typeClassName: java.lang.String
resources:
requests:
cpu: "0.1"
memory: 1G
limits:
cpu: "0.2"
memory: 1.1G
pulsar:
pulsarConfig: "test-pulsar"
java:
jar: "/pulsar/examples/api-examples.jar"
How to run connectors using Function Mesh
Source and sink are specialized functions. If you use Pulsar built-in or StreamNative-managed connectors, you can create them by specifying the Docker image in the source or sink CRDs. These Docker images are public at the Docker Hub, with the image name in a format of streamnative/pulsar-io-CONNECTOR-NAME:TAG, such as streamnative/pulsar-io-hbase:2.7.1. You can check all supported connectors in the StreamNative Hub.
If you use self-built connectors, you can package them to an external package or to a docker image, upload the package and then submit the connectors through CDRs. For details, refer to run Pulsar connectors using Function Mesh.
In the following CRD YAML files for source and sink, the connectors receive the input from DebeziumMongoDB and send the output to ElasticSearch.
Define the CRD yaml file for source:
apiVersion: compute.functionmesh.io/v1alpha1
kind: Source
metadata:
name: source-sample
spec:
image: streamnative/pulsar-io-debezium-mongodb:2.7.1
className: org.apache.pulsar.io.debezium.mongodb.DebeziumMongoDbSource
replicas: 1
output:
topic: persistent://public/default/destination
typeClassName: org.apache.pulsar.common.schema.KeyValue
sourceConfig:
mongodb.hosts: rs0/mongo-dbz-0.mongo.default.svc.cluster.local:27017,rs0/mongo-dbz-1.mongo.default.svc.cluster.local:27017,rs0/mongo-dbz-2.mongo.default.svc.cluster.local:27017
mongodb.name: dbserver1
mongodb.user: debezium
mongodb.password: dbz
mongodb.task.id: "1"
database.whitelist: inventory
pulsar.service.url: pulsar://test-pulsar-broker.default.svc.cluster.local:6650
pulsar:
pulsarConfig: "test-source"
java:
jar: connectors/pulsar-io-debezium-mongodb-2.7.1.nar
jarLocation: "" # use pulsar provided connectors
Define the CRD yaml file for sink:
apiVersion: compute.functionmesh.io/v1alpha1
kind: Sink
metadata:
name: sink-sample
spec:
image: streamnative/pulsar-io-elastic-search:2.7.1
className: org.apache.pulsar.io.elasticsearch.ElasticSearchSink
replicas: 1
input:
topics:
- persistent://public/default/input
typeClassName: "[B"
sinkConfig:
elasticSearchUrl: "http://quickstart-es-http.default.svc.cluster.local:9200"
indexName: "my_index"
typeName: "doc"
username: "elastic"
password: "X2Mq33FMWMnqlhvw598Z8562"
pulsar:
pulsarConfig: "test-sink"
java:
jar: connectors/pulsar-io-elastic-search-2.7.1.nar
jarLocation: "" # use pulsar provided connectors
How to Run Function Mesh on Kubernetes
A FunctionMesh orchestrates functions, sources and sinks together and manages them as a whole. The FunctionMesh CRD has a list of fields for functions, sources and sinks and you can connect them together through the topics field. Once the YAML file is submitted, the FunctionMesh controller will reconcile it into multiple function/source/sink resources and delegate each of them to corresponding controllers. The function/source/sink controllers reconcile each task and launch corresponding sub-components. The FunctionMesh controller collects the status of each component from the system and aggregates them in its own status field.
The following FunctionMesh job example launches two functions and streams the input through the two functions to append exclamation marks.
apiVersion: compute.functionmesh.io/v1alpha1
kind: FunctionMesh
metadata:
name: mesh-sample
spec:
functions:
- name: ex1
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
replicas: 1
maxReplicas: 5
input:
topics:
- persistent://public/default/source-topic
typeClassName: java.lang.String
output:
topic: persistent://public/default/mid-topic
typeClassName: java.lang.String
pulsar:
pulsarConfig: "mesh-test-pulsar"
java:
jar: pulsar-functions-api-examples.jar
jarLocation: public/default/test
- name: ex2
className: org.apache.pulsar.functions.api.examples.ExclamationFunction
replicas: 1
maxReplicas: 3
input:
topics:
- persistent://public/default/mid-topic
typeClassName: java.lang.String
output:
topic: persistent://public/default/sink-topic
typeClassName: java.lang.String
pulsar:
pulsarConfig: "mesh-test-pulsar"
java:
jar: pulsar-functions-api-examples.jar
jarLocation: public/default/test
The output topic and input topic of the two functions are the same, so that one can publish the result into this topic and the other can fetch the data from that topic.
Work with pulsar-admin CLI tool
If you want to use Function Mesh and do not want to change the way you create and submit functions, you can use Function Mesh worker service. It is similar to Pulsar Functions worker service but uses Function Mesh to schedule and run functions. Function Mesh worker service enables you to use the pulsar-admin CLI tool to manage Pulsar Functions and connectors in Function Mesh. The following figure illustrates how Function Mesh worker service works with Pulsar proxy, converts and forwards requests to the Kubernetes cluster.
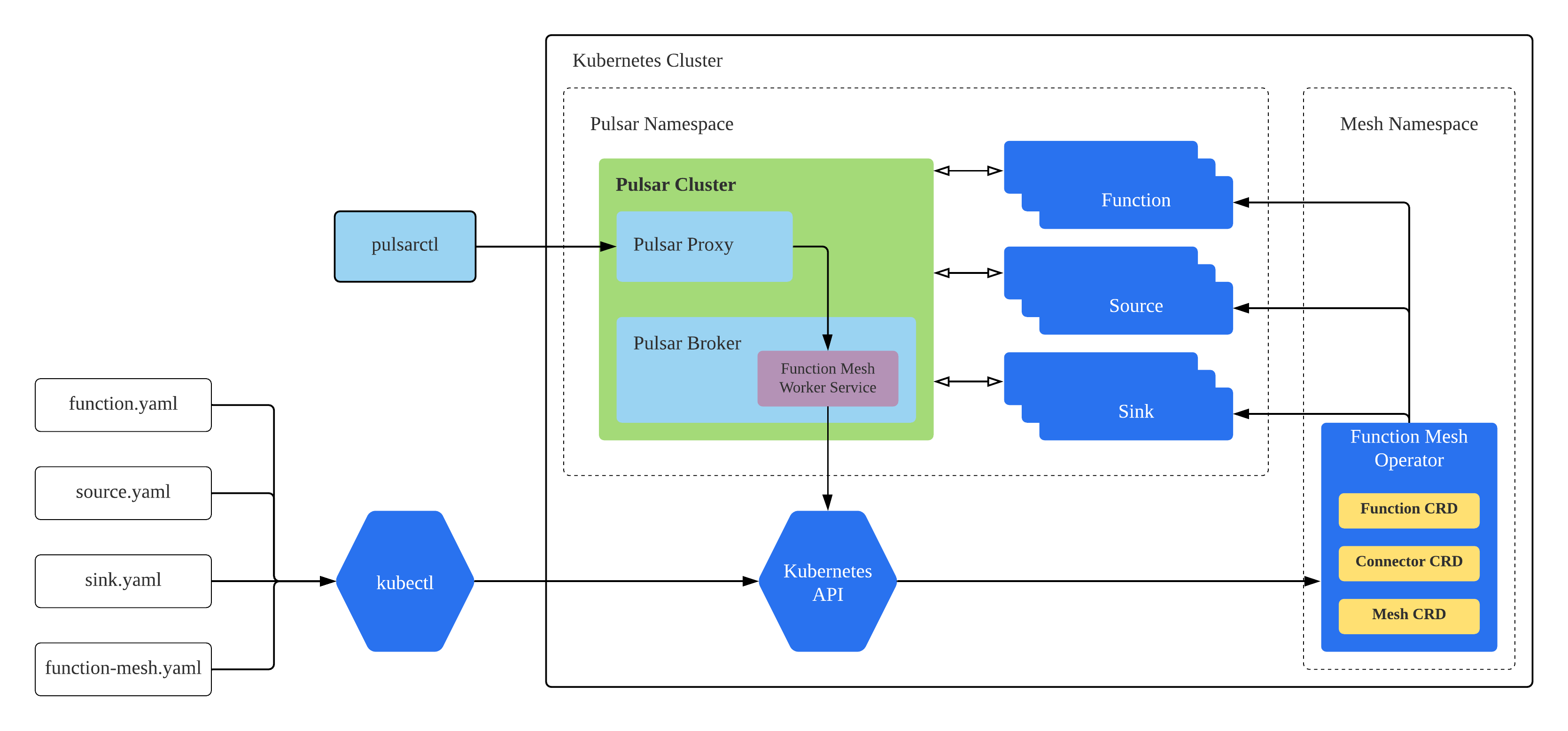
For details about the usage, you can refer to work with pulsar-admin CLI tool.
Migrate Pulsar Functions to Function Mesh
If you run Pulsar Functions using the existing Kubernetes runtime and want to migrate them to Function Mesh, Function Mesh provides you a tool to generate a list of CRDs of your existing functions. You can then apply these CRDs to ask Function Mesh to take over the ownership of managing the running Pulsar Functions on Kubernetes. For details, refer to migration Pulsar Functions guide.
Supported Features
Currently, Function Mesh supports the following features:
- Running Pulsar Functions and connectors natively in Kubernetes.
- Orchestrating multiple Pulsar Functions and connectors as a streaming job.
- Compatibility with original Pulsar Admin API for submitting Functions and connectors.
- Auto-scaling instances for functions and connectors using Horizontal Pod Autoscaler.
- Authentication and authorization.
- Multiple runtimes with Java, Python, and Golang support.
- Schema and SerDe.
- Resource limitation.
Future Plans
We plan to enable the following features in the upcoming releases, if you have any ideas or would like to contribute to it, feel free to contact us.
- Improve the capability level of the Function Mesh operator.
- Feature parity with Pulsar Functions, such as stateful function.
- Support additional runtime based on self-contained function runtime, such as web-assembly.
- Develop better tools/frontend to manage and inspect Function Meshes.
- Group individual functions together to improve latency and reduce cost.
- Support advanced auto-scaling based on Pulsar metrics.
- Integrate function registry with Apache Pulsar Packages.
Try Function Mesh Now
- Function Mesh is now open source. Try it on your Kubernetes clusters.
- Function Mesh is also built in StreamNative Cloud. Read this blog for how you can quickly cover various messaging and streaming use cases, such as ETL pipelines, event-driven applications, and simple data analytics applications on StreamNative Cloud.
- To learn more about Function Mesh, read the docs and watch a live demo.
- If you have any feedback or suggestions for this project, feel free to contact us or open issues in the GitHub repo. Any feedback is highly appreciated.
More Resources
- Make an inquiry: Interested in a fully-managed Pulsar offering built by the original creators of Pulsar? Contact us now.
- Pulsar Summit Europe 2023 is taking place virtually on May 23rd. Engage with the community by submitting a CFP or becoming a community sponsor (no fee required).
- Learn the Pulsar Fundamentals: Sign up for StreamNative Academy, developed by the original creators of Pulsar, and learn at your own pace with on-demand courses and hands-on labs.





