
Introduction
Pulsar Functions are now available on StreamNative Cloud. Leverage the full power of Pulsar Functions to build real-time data pipelines. This means you can quickly cover various messaging and streaming use cases, such as ETL pipelines, event-driven applications, and simple data analytics applications.
Simplify the creation and deployment of real-time data pipelines on StreamNative Cloud by using Pulsar's built-in framework, which requires less expertise and complexity to using an external stream processing engine.
In this blog, we look at what Pulsar Functions on StreamNative Cloud are, why you should use them, and how to get started.
What are Pulsar Functions?
Pulsar Functions are the computing infrastructure of the Pulsar messaging system. They are lightweight, Pulsar-native, Lambda-style functions that can:
- consume messages from one or more Topics.
- apply user-defined processing logic to each message.
- publish computation results to other Topics.
Pulsar Functions provide three delivery semantics, including at-most-once, at-least-once, and effectively-once. And Pulsar Functions support multiple programming languages, including Java, Python, and Go.
What are the use cases and patterns?
Pulsar Functions provide a highly flexible and modular architecture, similar to that of microservices. By breaking down your pipeline into smaller, more manageable pieces, teams can rapidly and frequently deliver new functionality, making it easier to evolve and adapt your technology stack.
Additionally, Pulsar Functions enable teams to focus on developing core business logic by abstracting away the interactions between the Pulsar cluster and user applications. You can achieve seamless integration of applications without requiring any changes to the applications themselves, by creating pipelines to adapt data flow between them. This also enables teams to move logic into these pipelines, which can then generate more valuable insights from the data.
In terms of use cases, Functions can be used to implement simple to complex messaging/streaming patterns, real-time data pipelines, IoT systems, and analytics.
For example:
- Real-time data analytics based on incoming Pulsar data: Fraud detection, data aggregation, monitoring, and robot recommendation.
- Real-time data integration and transformation: AI feature extraction and machine learning model scoring.
- Event-driven pipelines based on Pulsar messages: Processing, verification, and notifications.
Here are some example patterns of how functions (f) can be implemented to perform basic yet essential message processing tasks. As depicted in these diagrams, functions are shown to have subscriptions (s) to input topics. To increase scalability, a shared subscription may also be used, allowing for an increase in the number of instances.
Content Filtering Pattern
In a content filtering pattern, messages are received from an input topic, and then processed by a function. The function filters out any unwanted data or extracts relevant features and only passes on the relevant data to the output topic.
 Figure1: Content filtering pattern, where (F) is a function and (s) is a subscription.
Figure1: Content filtering pattern, where (F) is a function and (s) is a subscription.
Message Filtering Pattern
In a message filtering pattern, messages are received from an input topic, and then evaluated by a function. Only messages that meet certain criteria are passed on to the output topic.
 Figure 2. Message filtering pattern, where (f) is a function and (s) is a subscription.
Figure 2. Message filtering pattern, where (f) is a function and (s) is a subscription.
Enrichment Pattern
In an enrichment pattern, messages are received from an input topic, and then processed by a function. The function sends requests to an external service to augment the data in each message, and then passes the enriched messages on to the output topic.
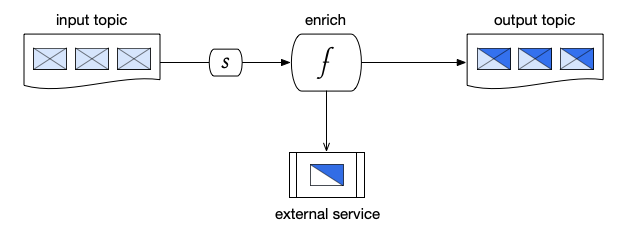 Figure 3. Enrichment pattern, where (f) is a function and (s) is a subscription.
Figure 3. Enrichment pattern, where (f) is a function and (s) is a subscription.
Routing Pattern
In a routing pattern, a function processes messages received from an input topic and routes them to other topics based on the specified routing criteria. The routing pattern is utilized in event auditing to record the processing and routing of events for monitoring system behavior.
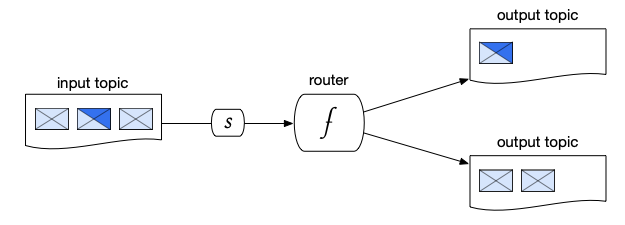 Figure 4. Routing pattern, where (f) is a function and (s) is a subscription.
Figure 4. Routing pattern, where (f) is a function and (s) is a subscription.
Gathering Pattern
In a gathering pattern, a function merges messages received from multiple input topics and publishes them to a common output topic for downstream processing. This pattern is a critical component in machine learning workflows, as it collects and prepares data for model scoring.
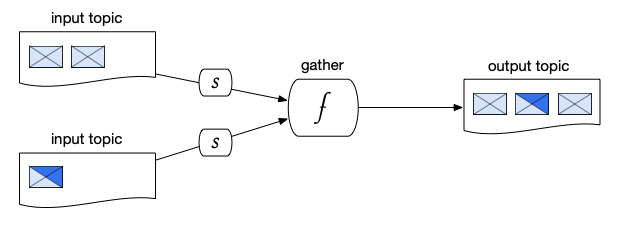 Figure 5. Gathering Pattern, where (f) is a function and (s) is a subscription.
Figure 5. Gathering Pattern, where (f) is a function and (s) is a subscription.
Transformation Pattern
In a transformation pattern, a function receives messages from an input topic, converts them into a different format, and then publishes them to an output topic.
![]() Figure 6. Transformation Pattern, where (f) is a function and (s) is a subscription.
Figure 6. Transformation Pattern, where (f) is a function and (s) is a subscription.
Comparing Functions in Open-Source Pulsar vs StreamNative Cloud
When self-managing Pulsar Functions in open-source, function workers must be used for scheduling and running Pulsar Functions in production.
However, this approach has drawbacks:
- Function workers are embedded in brokers, and function metadata is also stored in brokers. This can lead to a “noisy neighbor” effect on the brokers, and if the brokers become unavailable, the functions will fail to start. The recovery process will be manual, with a risk of losing function metadata.
- To ensure reliable deployment of open-source Pulsar Functions, a visual tool to match topics and confirm connections must be built. Functions can then be deployed and managed individually through CLI or API.
- There is no built-in autoscaling capability, meaning that managing loads of many Functions can be demanding as it requires manual workload distribution.
- While it is possible to run Function Workers on Kubernetes, the Kubernetes runtime for Function Workers does not fully utilize cloud-native capabilities. All provisioning and scheduling responsibilities remain within the Function Worker, and the created Kubernetes resources such as StatefulSets, Services, and Secrets are not managed under a Kubernetes native abstraction. Additionally, this approach poses the risk of losing function metadata.
StreamNative Cloud addresses the limitations of using function workers in open-source Pulsar with its built-in, cloud-native Kubernetes operator, Function Mesh. This allows you to easily submit and manage Pulsar Functions using Kubernetes’ powerful deployment, scaling, and management capabilities.
The benefits of this improved workflow include:
- Enhanced reliability and stability: Function Mesh-based scheduling eliminates the function workers’ noisy impact on brokers, ensuring broker availability at all times and increasing the availability and security of metadata for all Pulsar Functions.
- Autoscaling: Function Mesh can support horizontally or vertically scaling the Function pods to meet the use case requirements with very few configurations, coming soon.
- Streamlined management: Easily manage user-submitted functions across all namespaces.
In addition to the above benefits, using Pulsar Functions on StreamNative Cloud also offers:
- Flexible user experience: Use all the familiar tools such as CLI (pulsar-admin, pulsarct), RESTful API, and UI to manage and update Pulsar Functions.
- Reduced infrastructure and operations burden: Manage and implement lightweight computing operations with a standardized interface; avoid adding complexity with a larger overhead solution like Flink and Spark.
- Enhanced security: with built-in OAuth2 authentication/authorization to run Functions in a cloud environment.
- Enhanced visibility: The UI allows you to quickly identify and address issues, with the option to leverage StreamNative’s expertise to accelerate debugging.
Get started with Functions on StreamNative Cloud
StreamNative Cloud simplifies running Pulsar Functions in the cloud. Deploy your functions using the command line on your StreamNative Cloud cluster just as you would normally. Monitor all your functions in one place using the StreamNative Cloud Console, which provides a visual display of the current state of all of your functions.
Check out what you can do with Functions:
More resources
- Make an inquiry: Interested in a fully-managed Pulsar offering built by the original creators of Pulsar? Contact us now.
- Pulsar Summit Europe 2023 is taking place virtually on May 23rd. Engage with the community by submitting a CFP or becoming a community sponsor (no fee required).
- Learn the Pulsar Fundamentals: Sign up for StreamNative Academy, developed by the original creators of Pulsar, and learn at your own pace with on-demand courses and hands-on labs.
- Documentation: Read more about Pulsar Functions on StreamNative Cloud here.







![Product updates for StreamNative Cloud [Apr 2023]: Google Cloud Marketplace, and more!](/_vercel/image?url=%2Fimgs%2Fblogs%2F644c3bdb7cee1e7875ca33aa_StreamNative-Cloud.jpg&w=1536&q=100)