

The shift to real-time streaming technologies has bolstered the adoption of Pulsar and there has been a marked increase in both the interest and adoption of Pulsar. With Pulsar being sought out by companies developing messaging and event-streaming applications — from Fortune 100 companies to forward-thinking start-ups — and so much growth around the Pulsar project, it has garnered a lot of recent press and attention.
For the most part, the recent press and articles have helped to provide valuable education and transparency into Pulsar’s use cases and capabilities. Companies such as Verizon Media, Iterable, Nutanix, and Overstock.com, are just a handful of companies who have recently presented their Pulsar use cases and shared insights into how they are leveraging Pulsar to achieve their business goals.
However, not all recent press has been entirely accurate and we have received a number of requests from the Pulsar community to address a recent Confluent blog comparing Kafka, Pulsar, and RabbitMQ. We appreciate that Pulsar is a quickly growing and evolving technology and we would like to take this opportunity to provide a deep dive into Pulsar’s capabilities.
In today’s post, we will leverage in-depth knowledge of the Pulsar technology, community, and ecosystem to provide a more balanced and holistic picture of the event-streaming landscape. This post will be the first in a two-part series and here we will concentrate on the differences between Pulsar and Kafka in terms of performance, architecture, and features. In the second post, we focus on adoption, use cases, support, and community.
Note Given that Kafka is more widely-known and has widespread documentation available, we will focus our efforts on providing education and transparency into the lesser-known Pulsar technology.
Pulsar Fundamentals
Components of a Pulsar Cluster
Pulsar is composed of 3 main components: a broker, which is a stateless service that clients connect to for core messaging, and two stateful services, Apache BookKeeper and Apache ZooKeeper. BookKeeper nodes (bookies) store the actual messages and cursor positions while ZooKeeper is used strictly for metadata storage by both brokers and bookies. Additionally, BookKeeper leverages RocksDB as an embedded database, which is used to store internal indices, but it is not managed independently of BookKeeper.
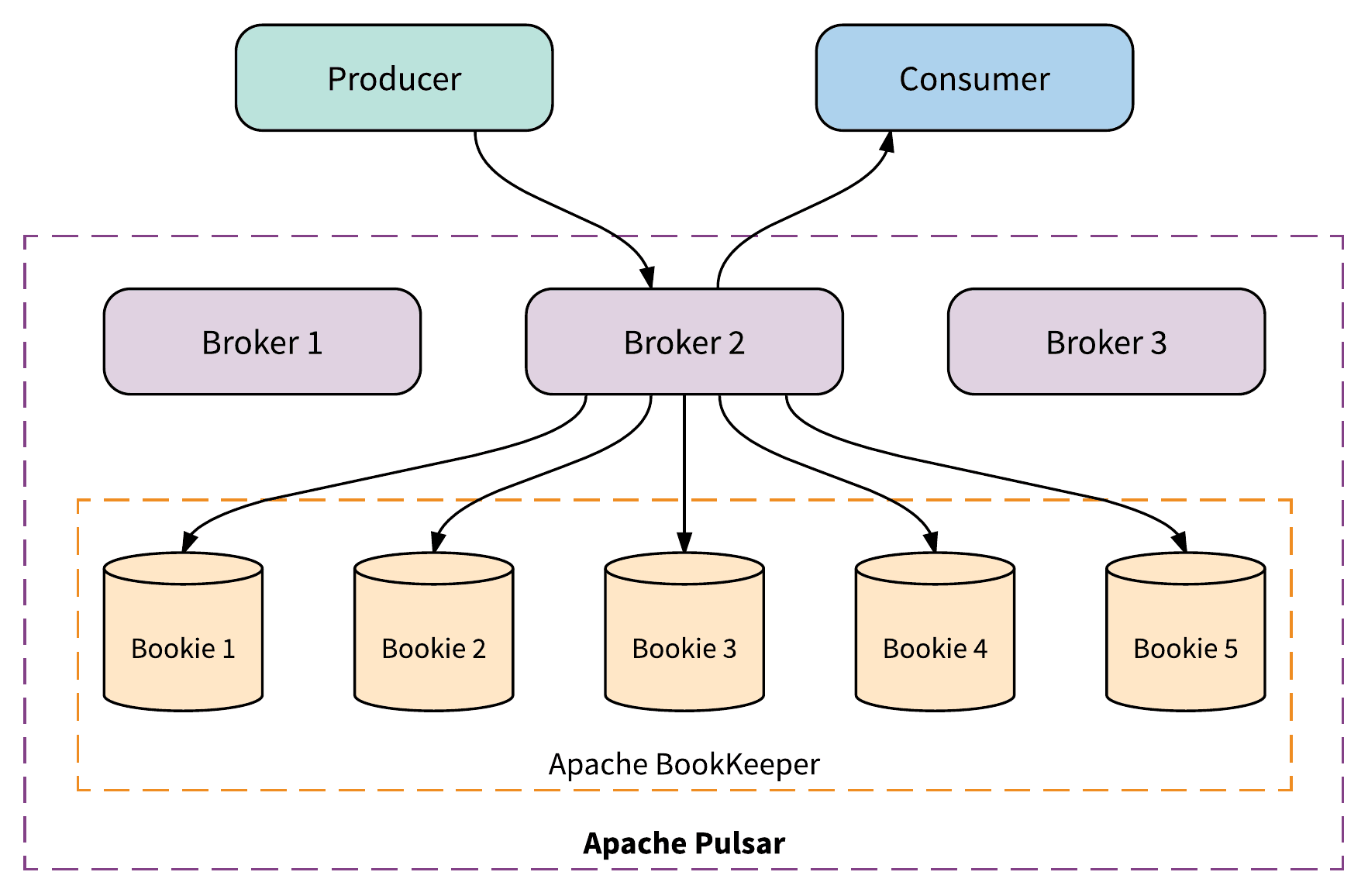
Unlike Kafka, which employs a monolithic architecture model that tightly couples serving and storage, Pulsar leverages a multi-layer design which allows it to manage these functions in separate layers. Pulsar’s broker performs computing on one layer and the bookie manages stateful storage on another.
While, on the surface, it may seem like Pulsar’s architecture is more complicated compared with Kafka’s, the reality is more nuanced. Architectural decisions come with trade-offs and Pulsar’s inclusion of BookKeeper enables it to provide more flexible scalability, lower operational burden, faster, and more consistent performance. We will talk in more detail about each of these benefits later on.
Pulsar's Storage Architecture
The architectural differences in Pulsar also extend to how Pulsar stores data. Pulsar breaks topic partitions into segments and then distributes the segments across the storage nodes in Apache BookKeeper to get better performance, scalability, and availability.
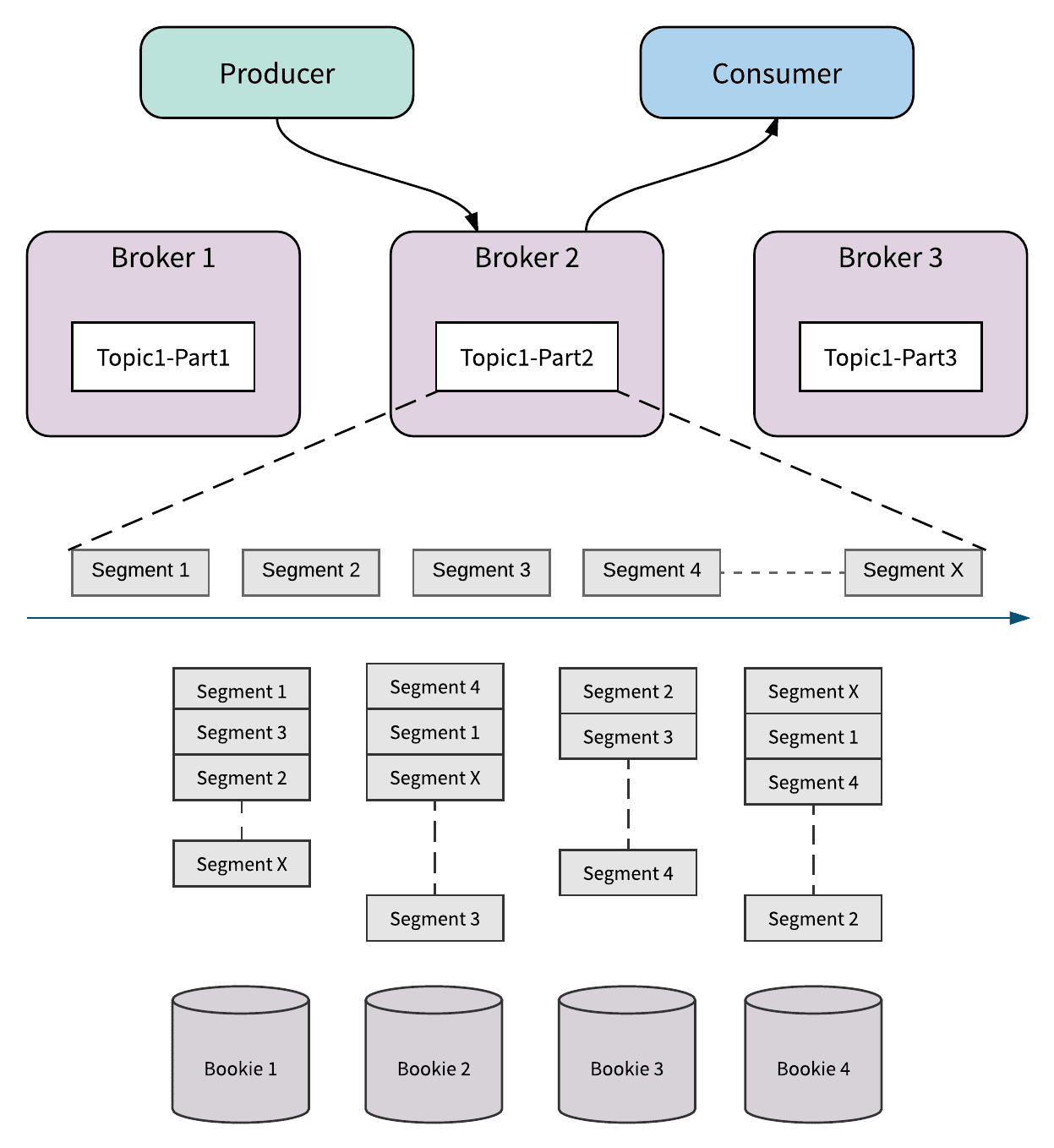
Pulsar’s infinite distributed log is segment centric and implemented by leveraging scale-out log storage (via Apache BookKeeper) with built-in tiered storage support which enables segments to be distributed evenly across storage nodes. Because the data associated with any given topic is not tied to any specific storage node, it is easy to replace nodes and to scale up or down. Moreover, the smallest or slowest node in the cluster cannot impose any storage or bandwidth limitations.
Pulsar’s partition-rebalance-free architecture ensures instant scalability and higher availability. Both of these factors are extremely important and make Pulsar well-suited for building mission-critical services such as billing platforms for financial use cases, transaction processing systems for e-commerce and retailers, and real-time risk control systems for financial institutions.
By leveraging the powerful Netty framework, data is zero-copied when it is transferred from producers to brokers to bookies. This works extremely well for all streaming use cases because the data is transferred directly over the network or to disk without any performance penalties.
Message Consumption on Pulsar
Pulsar’s consumption model takes a streaming-pull approach. This is an enhanced version of long-polling as it eliminates the wait time between individual calls and requests and provides bi-directional message streaming. The streaming-pull model enables Pulsar to achieve lower end-to-end latency than any other existing long-polling-based messaging solutions, such as Kafka.
Ease of Use
Operational Simplicity
When evaluating the operational simplicity for a given technology, it’s important to consider not only the initial set-up but also its long-term maintenance and scalability. Helpful questions to consider include:
- How quickly and simply can you scale your cluster to keep up with your business growth?
- Does your cluster provide out-of-the-box features for multi-tenancy that map well to multiple teams and users?
- Will the operational tasks, such as replacing hardware, require maintenance that potentially can impact the availability and reliability of your business?
- Can your system easily replicate data for geographic redundancy or different access patterns?
Long-time Kafka users will know these are not easy questions to answer when operating Kafka. Most of these tasks require a suite of tools external to Kafka, such as cruise control for managing rebalancing of clusters and Kafka mirror-maker/replicator for any replication needs.
Many organizations also develop tooling for provisioning and managing multiple distinct clusters as Kafka can be difficult to share across teams. These types of tools are critical to run Kafka at scale successfully but also add to its complexity. The most capable tools for managing Kafka clusters have been developed as proprietary, closed source tooling. It is no surprise that Kafka’s complex overhead and operations have pushed many businesses to use Confluent.
By contrast, Pulsar’s goal is to streamline operations and scalability. Below we respond to the same questions with respect to Pulsar’s capabilities:
- How quickly and simply can you scale your cluster to keep up with your business growth?
- New compute and storage capacity is automatically and immediately utilized with Pulsar’s automatic load balancing. This allows migrating topics to equalize load among brokers and new bookie nodes immediately receiving write traffic for new segments, with no manual rebalancing or broker management required.
- Does your cluster provide out-of-the-box features for multi-tenancy that map well to multiple teams and users?
- Pulsar provides a hierarchical structure of tenants and namespaces which map logically to organizations and teams, with these same constructs allowing for simple ACLs, quotas, self-service controls, and even resources isolation to allow cluster operators to confidently manage shared clusters.
- Will the operational tasks, such as replacing hardware, require maintenance that potentially can impact the availability and reliability of your business?
- The stateless broker of Pulsar is able to be replaced easily, as there is no risk of data loss. Bookie nodes will automatically replicate any under-replicated segments of data and tools for decommissioning and replacing nodes is built-in and easily automatable.
- Can your system easily replicate data for geographic redundancy or different access patterns?
- Pulsar has built-in replication, which can be used to seamlessly span geographic regions or replicate data to additional clusters for other purposes (disaster recovery, analytics, and so on.)
In comparison to Kafka, Pulsar’s batteries included approach provides a more complete solution to the real-world problems of streaming data. With this added perspective, the overall simplicity of use favors Pulsar as it offers a more complete core feature set and allows operators and developers to focus on the core needs of their business.
Documentation and Learning
Pulsar has been rapidly building out its documentation and training resources. Here are some of the most notable accomplishments:
- 7 Pulsar Summits across North America, Asia, and Europe, featured hundreds of sessions with speakers from top companies such as Google, AWS, Intuit, and Databricks, attracting thousands of attendees sign-ups.
- On-demand Pulsar courses, tutorials, and hands-on labs for developers, operators, and business leaders.
- Instructor-led, hands-on Pulsar training for developers and operators.
- Meetups and webinars featuring speakers from adjacent communities like Flink and Nifi and companies including Splunk, Uber, and Elastic.
- eBooks, whitepapers, and case studies from Iterable, Tencent, Weibo, Tuya, and more.
- Documentation portal that holds a variety of topics, tutorials, guides, and reference material to help you work with Pulsar.
Enterprise Support
Kafka and Pulsar both have enterprise-grade support offerings. Kafka has enterprise-grade support offerings from multiple large vendors, including Confluent. Pulsar has enterprise-grade support from StreamNative, a newer entrant on the scene. StreamNative offers fully managed Pulsar services for enterprises as well as enterprise-grade support for Pulsar.
StreamNative has a fast-growing and highly-experienced team with deep roots in the messaging and event-streaming space. StreamNative was founded by the core team of Pulsar and BookKeeper. In just a few short years, StreamNative has helped to significantly grow the Pulsar ecosystem — more on this in our next post — including garnering the support of committed strategic partners who are helping to further Pulsar development to meet the needs of a wide number of use cases.
Some major recent developments include the launch of Kafka-on-Pulsar, or KoP, which was launched in March 2020 by OVHCloud and StreamNative. By adding the KoP protocol handler to an existing Pulsar cluster, you can now migrate existing Kafka applications and services to Pulsar without modifying the code. In June 2020, China Mobile and StreamNative announced the launch of another major platform upgrade, AMQP on Pulsar (AoP). This enables RabbitMQ applications to leverage Pulsar’s powerful features, such as infinite event stream retention with Apache BookKeeper and tiered storage. We will talk about each of these in more detail in our next post.
Integrations
Alongside the rapid growth in the number of Pulsar adoptions, we have seen the Pulsar community develop into a large, highly-engaged, and global user community. This active Pulsar community has played a key role in driving growth in the number of integrations in the ecosystem. In just the past six months, the number of officially supported connectors in the Pulsar ecosystem has grown tremendously.
To further support this community effort, StreamNative recently launched StreamNative Hub, which provides a convenient central location where users can find and download integrations. This resource will help accelerate the growth of Pulsar’s connector and plug-in ecosystem.
The Pulsar community has also been actively working with other communities on integrating with their projects. For example, Pulsar has been working closely with the Flink community on developing the Pulsar-Flink Connector as part of FLIP-72. Pulsar-Spark Connector provides developers the capability of using Apache Spark to process events in Apache Pulsar. SkyWalking Pulsar Plugin integrates Apache SkyWalking with Apache Pulsar, allowing people to trace Pulsar messages using SkyWalking. These are just a few examples of a large collection of integrations the Pulsar community is currently working on.
Client Library Diversity
Pulsar currently supports 7 languages officially, compared with Kafka’s 1 language. While the Confluent post reported that Kafka currently supports 22 languages, it is important to note that most of the 22 languages Confluent referred to are not official clients, and many are no longer actively maintained. At last count, the Apache Kafka project had only one officially released client, compared with the seven officially supported by Apache Pulsar:
- Java
- C
- C++
- Python
- Go
- .NET
- Node
Pulsar also supports a rapidly growing list of community developed clients, which includes the following:
- Rust
- Scala
- Ruby
- Erlang
Performance and Availability
Throughput, Latency, and Scale
Both Pulsar and Kafka have successfully been leveraged in a number of enterprise use cases and each system has its advantages, with both systems being capable of handling large amounts of traffic with similar amounts of hardware. One common misconception of Pulsar is that because it has more components, it must require more servers to achieve the same performance. While this may be true in some hardware configurations, in many configurations Pulsar can get more from the same resources.
As an example, Splunk recently shared that one of the reasons they choose Pulsar over Kafka is that Pulsar is 1.5x - 2x lower in CAPEX cost with 5x - 50x improvement in latency and 2x - 3x lower in OPEX due to layered architecture (from slide 34). They found this was due to Pulsar being better able to utilize disk IO with lower CPU utilization and better control over memory.
More generally, companies such as Tencent have chosen Pulsar in large part due to its performance attributes. As discussed in a recent whitepaper Tencent’s billing platform, which serves over a million merchants and manages 30 billion escrow accounts, is currently using Pulsar to process hundreds of millions of dollars in revenue per day. Tencent chose Pulsar over Kafka for its predictable low latency, stronger consistency, and durability guarantees.
Ordering Guarantees
Apache Pulsar offers four distinct subscription modes. The four modes and their associated ordering guarantees are described below. An individual application’s ordering and consumption scalability requirements determine which subscription mode is appropriate for that application.
- Both the Exclusive and Failover subscription modes provide very strong ordering guarantees at a partition level even when consuming a topic in parallel across many consumers.
- Shared mode allows you to scale the number of consumers beyond the number of partitions, thus making this mode well-suited for worker queue use cases.
- Key_Shared mode combines the advantages of the other subscription modes. It allows scaling the number of consumers beyond the number of partitions and provides a strong ordering guarantee at a key level.
For more information about Pulsar’s subscription types and their associated ordering guarantees, see subscriptions.
Feature
Built-In Stream Processing
Pulsar and Kafka have two different goals when it comes to built-in stream processing. Pulsar integrates with Flink and Spark, two mature, full-fledged stream processing frameworks, for more complex stream processing needs and developed Pulsar Functions to focus on lightweight computation. Kafka developed Kafka Streams with the goal of providing a full-fledged stream processing engine.
As a result, Kafka Streams is more complex. Users need to figure out where and how to run the KStreams application and it is unnecessarily complicated for most lightweight computing use cases.
Pulsar Functions, on the other hand, makes lightweight computing use cases easy to implement and enables developers to create complex processing logic without deploying a separate neighboring system. Additionally, it provides language-native and easy-to-use API. Developers don’t have to learn a complicated API in order to start writing event streaming applications.
A Pulsar Improvement Proposal (PIP) was recently submitted to the Pulsar project to introduce Function Mesh. Function Mesh is a serverless event-streaming framework that combines multiple Pulsar Functions together to facilitate building complex event-streaming applications.
Exactly-Once Processing
Pulsar currently supports exactly-once producers via broker-side deduplication and we are happy to share a major upgrade is presently in development and will be available soon!
Support for transactional message streaming started in PIP-31 and is currently in development. This feature will improve Pulsar’s message delivery semantics and processing guarantees. With transactional streaming, each message is written or processed exactly once with no duplication or data loss, even when a broker or function instance fails. Transactional messaging not only makes it easier to write applications using Pulsar or Pulsar Functions, but it also expands the scope of the use cases that Pulsar can support. We are making rapid progress on this feature and it will be included in Pulsar 2.7.0 which is scheduled for release in September 2020.
Topic (Log) Compaction
Pulsar was designed to provide users a choice of formats for consuming data. Applications can choose to consume either raw data or compacted data, as appropriate. By doing this, Pulsar allows for non-compacted data to have a retention policy, keeping control over unbounded growth, but still allowing periodic compaction to generate the most recent materialized view around. The built-in tiered storage feature also allows Pulsar to offload the non-compacted data from BookKeeper to cloud storage and makes it much cheaper to store events for a much longer period.
Unlike Pulsar, Kafka does not offer users the option to consume raw data. Kafka removes raw data immediately after it is compacted.
Use Case
Event Streaming
Pulsar was originally developed as a unified pub/sub messaging platform in Yahoo! (known as Cloud Messaging). However, Pulsar has grown beyond a messaging platform and become a unified messaging and event streaming platform. Pulsar includes a complete set of tools as part of the platform, to provide all the fundamentals necessary for building event streaming applications. Pulsar encompasses the following event streaming capabilities:
- Infinite event stream storage makes it possible to store events at scale by leveraging scale-out log storage (via Apache BookKeeper) with built-in tiered storage support to cost-effective systems like S3, HDFS, and so on.
- Unified pub/sub messaging model allows developers to add messaging to their applications easily. This model can be scaled both based on traffic and on the user’s needs.
- Protocol handler framework and protocol compatibility with Kafka (via Kafka-on-Pulsar) and AMQP (via AMQP-on-Pulsar) allow applications to produce and consume events from anywhere using any existing protocols.
- Pulsar IO provides a set of connectors integrating larger ecosystems, allowing users to ingest data from external systems without writing any code.
- Integration with Flink enables comprehensive event processing.
- Pulsar Functions offers a lightweight serverless framework for processing events as they arrive.
- Integration with Presto (Pulsar SQL) allows data scientists and developers to use ANSI-compliant SQL to gain insights into their data and business.
Message Routing
Pulsar provides comprehensive routing capabilities through Pulsar IO, Pulsar Functions, and Pulsar Protocol Handler. Pulsar’s routing capabilities include content-based routing, message transformation, and message enrichment.
Pulsar has more robust routing capabilities compared with Kafka. Pulsar provides a flexible deployment model for connectors and functions. These can be run within a broker, allowing for easy deployment. Alternatively, they can be run in a dedicated pool of nodes (similar to Kafka Streams) which allows for massive scale-out. Pulsar also integrates natively with Kubernetes. In addition, Pulsar can be configured to schedule function and connector workloads as pods, thus fully leveraging the elasticity of Kubernetes.
Message Queuing
As noted above, Pulsar was originally developed as a unified pub/sub messaging platform. The Pulsar team learned a lot of the pros and cons of operating existing open-source messaging systems and applied their experiences to designing Pulsar’s unified messaging model. The Pulsar messaging API combines both queueing and streaming capabilities. It not only allows implementing a worker queue that delivers messages round-robin to competing consumers (via Shared subscription) but also supports event streaming by delivering messages based on the order of messages in a partition (via Failover subscription) or a key range (via Key_Shared subscription). Developers are able to build both messaging and event streaming applications on the same set of data without duplicating it to different siloed systems.
Additionally, The Pulsar community is also working on bringing the native support of different messaging protocols (such as AoP and KoP) to Apache Pulsar to extend Pulsar’s messaging capabilities.
Conclusion
This is a very exhilarating time marked by tremendous growth and change in the Pulsar community. Pulsar’s ecosystem is developing and expanding as its technology continues to evolve and new use cases are added.
Pulsar offers many advantages that make it an attractive choice for companies seeking to adopt a unified messaging and event streaming platform. Compared with Kafka, Pulsar is more resilient and less complex to operate and scale.
Like any new technology, it can take time to roll-out and adopt, however, Pulsar provides a turnkey solution that is ready for production upon installation with lower ongoing maintenance costs. Pulsar covers all the fundamentals necessary for building event streaming applications and incorporates many built-in features, including a rich set of tools. Pulsar’s tools are available for immediate use and do not require additional installation steps.
At StreamNative, we are continuously working on developing new features and enhancements to strengthen Pulsar’s capabilities and grow the community.
Special Thanks
We would be remiss not to thank the many members across the Pulsar community who contributed to this article. Namely, Jerry Peng, Jesse Anderson, Joe Francis, Matteo Merli, Sanjeev Kulkarni, and Addison Higham.
More Resources
- Read the 2022 Pulsar vs. Kafka benchmark for a side-by-side comparison of Pulsar and Kafka performance, including tests on throughput, latency, and more.
- Watch sessions from Pulsar Summit San Francisco 2022 for best practices and the future of messaging and event streaming technologies.
- Join the Pulsar Slack Channel to connect with the community.
- Sign up for the monthly StreamNative Newsletter for Apache Pulsar.
- Learn Pulsar from the original creators of Pulsar. Watch on-demand videos, enroll in self-paced courses, and complete our certification program to demonstrate your Pulsar knowledge.






