Mobile payment has achieved great success in China. These days, transactions can be completed within seconds simply by scanning a QR code. While that undoubtedly brings convenience to our daily lives, mobile payment also brings huge challenges to the risk control infrastructure. In September 2019, I gave a talk at the O’Reilly Strata Data Conference in New York and shared how our company leveraged Apache Pulsar to boost the efficiency of risk indicator development within Orange Financial.
About Orange Financial
Orange Financial (also known as China Telecom Bestpay Co., Ltd), is an affiliate company of China Telecom. Established in March 2011, Orange Financial quickly received a “payment business license” issued by the People’s Bank of China. The subsidiaries of Orange Financial include Bestpay, Orange Wealth, Orange Insurance, Orange Credit, Orange Financial Cloud, and others. Bestpay, in particular, has become the third-largest payment provider in China, closely following Alipay and WeChat Payment. With 500 million registered users and 41.9 million active users, Orange Financial’s transaction volume reached 1.13 trillion CNY ($18.37 billion USD) in 2018.

Mobile payment in China
China currently has the largest mobile payment market in the world and it continues to grow year after year. According to data from a research institute, China had 462 million mobile payment users in 2016. That number reached 733 million in 2019. In 2020 and beyond, it will grow larger still. The total value of mobile payment transactions was $22 trillion (USD) in 2016. By the end of 2019, it was expected to hit $45 trillion USD.
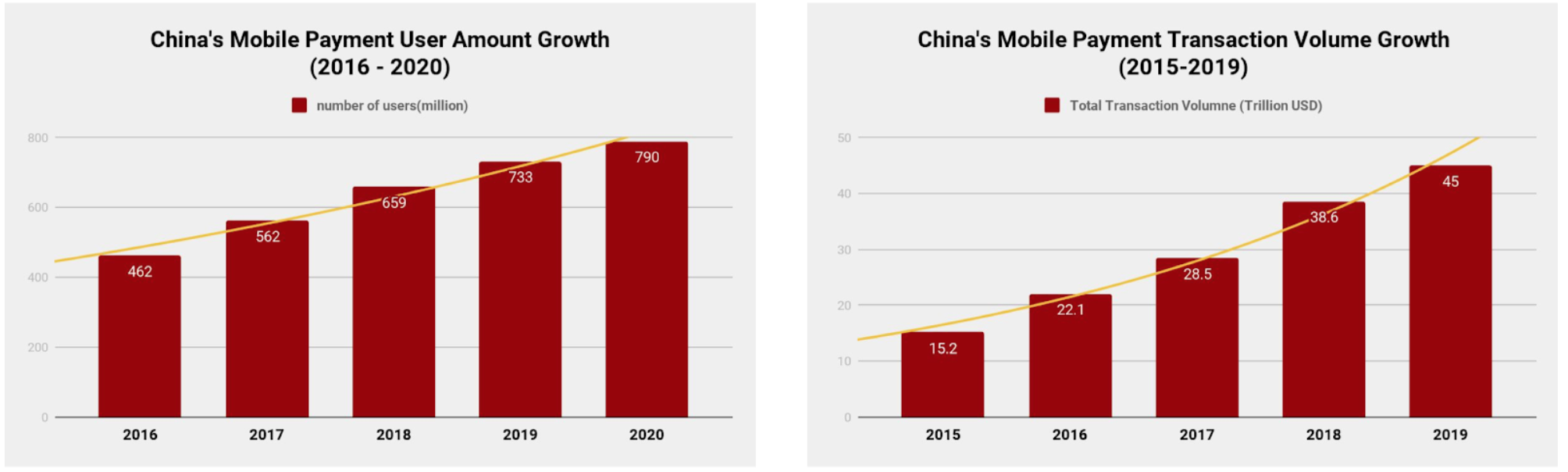
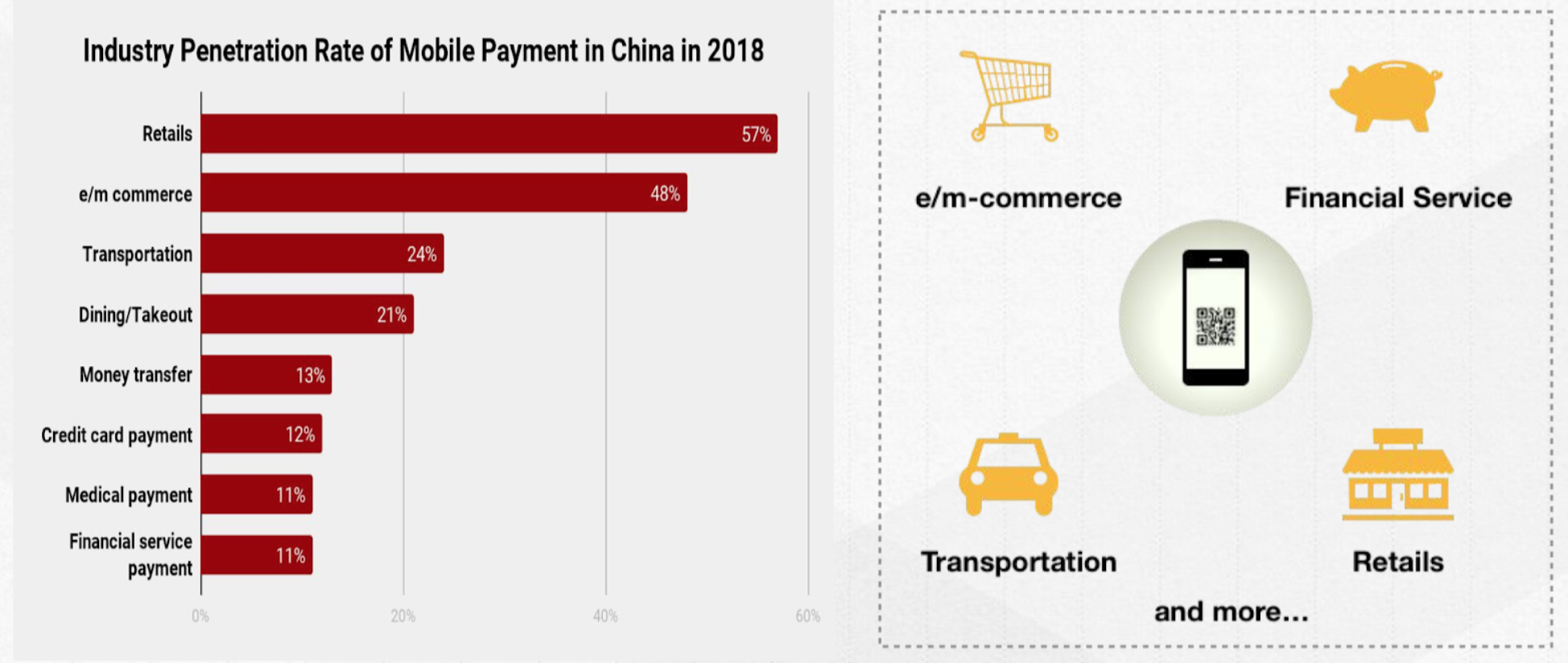
In China, the number of economic activities carried out through mobile payment is surging, as people are less likely to use cash or credit cards than ever before. The high industry penetration rate of mobile payment in China indicates that mobile payment is closely related to our daily life. You can do almost everything with a QR code on your smartphone -- order food, take taxi and metro, rent a bike, buy coffee and so on.
Mobile payment has achieved great success in China because it is convenient and fast. A transaction can be completed within seconds simply by scanning the QR code. That speed and convenience accelerates the adoption of mobile payments in e-commerce, financial services, transport, retail, and other businesses.
Our challenges
With greater ease of use comes greater threats. While mobile payment brings convenience to our daily lives, it also brings huge challenges to the risk control infrastructure. An instant transaction involves thousands of rules running against the transaction to prevent potential financial frauds. RSA reports that the top fraud types include phishing, rogue applications, Trojan attack, and brand abuse. Financial threats in the mobile payment era are more than that. They include account or identity theft, merchant frauds, and money laundering, just to name a few. According to a survey from China UnionPay, 60% of the 105,000 interviewees reported that they had encountered mobile-payment security threats.
We have a robust risk management system that helps us detect and prevent these attacks. Yet, even though we have been doing quite well in protecting the assets of our customers in recent years, we still face many challenges:
- High concurrency: our system deals with over 50 million transactions and 1 billion events every day. The peak traffic can reach 35 thousand transactions per second.
- Low latency demand: we require our system to respond to a transaction within 200 milliseconds.
- A large number of batch jobs and streaming jobs.
Lambda Architecture
The core of any risk management system is the decision. A decision is a combination of one or more indicators, such as geographic coordinates of a user’s login or the transaction volume of a retailer. Suspicions are raised, for example, if the geographic coordinates of a user’s recent logins are always the same. This tells us the transactions are likely being initiated by a bot or simulator. Similarly, if the transaction volume of a fruit stall is around $300 a day, when the volume suddenly rises up to $3000, our alert system is triggered.
Developing risk control indicators requires both historical data and real-time data. For example, when we sum up the total transaction volume of a merchant for the past month (30 days), we have to calculate the volume of the last 29 days in batch mode, and then sum up with the value returned by a streaming task on data collected on the current day since 12 am.
Most internet companies deploy a Lambda Architecture to solve similar challenges. Lambda is effective and keeps a good balance of speed and reliability. Previously, we also adopted the Lambda Architecture, which has three layers: (1) the batch layer, (2) the streaming layer, and (3) the serving layer.
The batch layer is for historical data computation, with data stored in Hive. Spark is the predominant batch computation engine. The streaming layer is for real-time computation, with Flink is the computing engine consuming data persisted in Kafka. The serving layer retrieves the final result for serving.
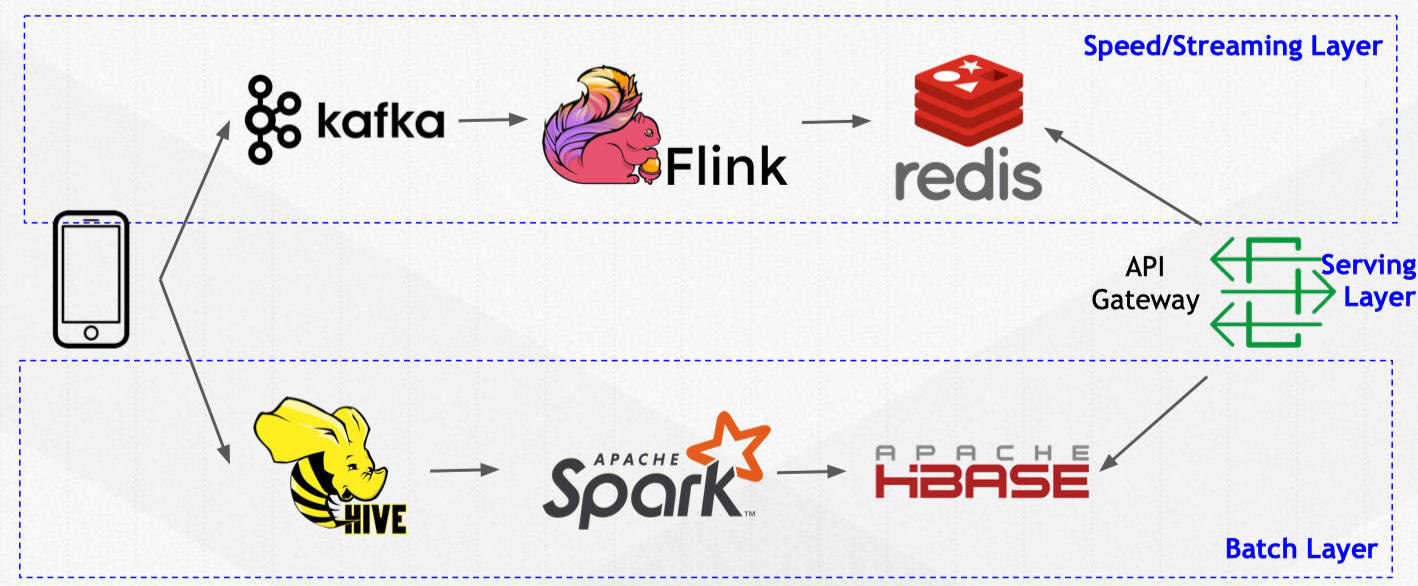
The problems with Lambda Architecture
Our experience has shown, however, that Lambda Architecture is problematic because it is complex and hard to maintain. First of all, we have to split our business logic into many segments. This increases our communication overhead and creates maintenance difficulties. Secondly, the data is duplicated in two different systems, requiring that we move data among different systems for processing.
As the business grows, our data processing stack becomes very complex because we constantly have to maintain all three software stacks (batch layer, streaming layer and serving layer). It also means we have to maintain multiple clusters: Kafka, Hive, Spark, Flink, and HBase, as well as a diverse engineering team with different skill sets. This makes the cost of maintaining that data-processing stack prohibitively expensive.
In seeking more efficient alternatives, we found Apache Pulsar. With Apache Pulsar, we made a bold attempt to re-factor our data processing stack. The goal is to simplify the stack, improve production efficiency, reduce cost, and accelerate decision-making in our risk management system.
Why Apache Pulsar works best
Recognizing the unique challenges of simplifying business processes and keeping good control of financial risks, we began to investigate Apache Pulsar.
Apache Pulsar is an open-source distributed pub-sub messaging system originally created at Yahoo!. Today, it is a part of the Apache Software Foundation. After thorough investigation, we determined that Pulsar is the best fit for our businesses. We have summarized the reasons for this conclusion below:
- Cloud-native architecture and segment-centric storage
- Apache Pulsar adopts layered architecture and segment based storage (using Apache BookKeeper). An Apache Pulsar cluster is composed of two layers: (a) a stateless serving layer, comprised of a set of brokers that receive and deliver messages; and (b) a stateful persistence layer, comprised of a set of Apache BookKeeper storage nodes (called “bookies”) that store messages durably. Apache Pulsar is enabled with high availability, strong consistency, and low latency features.
- Pulsar stores messages based on topic partitions. Each topic partition is assigned to one of the living brokers within the system (called the “owner broker” of that topic partition). The owner broker serves message-reads from the partition and message-writes to the partition. If a broker fails, Pulsar automatically moves the topic partitions that were owned by it to the remaining available brokers in the cluster. Since brokers are “stateless”, Pulsar only transfers ownership from one broker to another during node failure or broker cluster expansion. Importantly, no data copying occurs during this process.
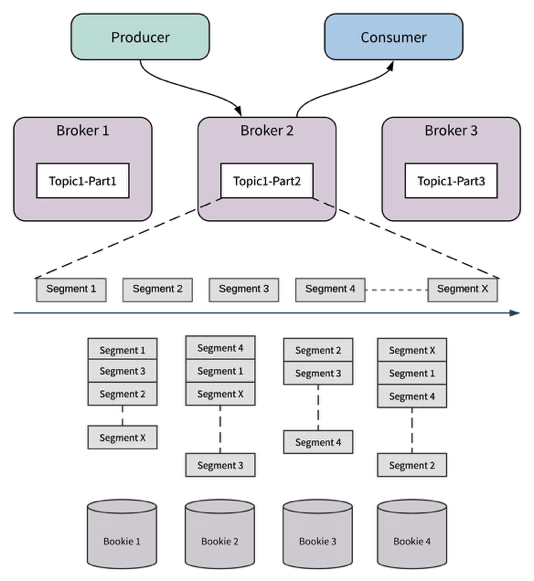
- Messages on a Pulsar topic partition are stored in a distributed log. That log is further divided into segments. Each segment is stored as an Apache BookKeeper ledger that is distributed and stored in multiple bookies within the cluster. A new segment is created in one of three situations: (1) after a previous segment has been written for longer than a configured interval (time-based rolling); (2) if the size of the previous segment has reached a configured threshold (size-based rolling); or (3) whenever the ownership of topic partition is changed.
- With segmentation, the messages in a topic partition can be evenly distributed and balanced across all the bookies in the cluster. This means the capacity of a topic partition is not solely limited by the capacity of one node. Instead, it can scale up to the total capacity of the whole BookKeeper cluster.
- Layered architecture and segment-centric storage (with Apache BookKeeper) are two key design philosophies. These attributes provide Apache Pulsar with several significant benefits, including unlimited topic partition storage, instant scaling without data rebalancing, and independent scalability of serving and storage clusters.
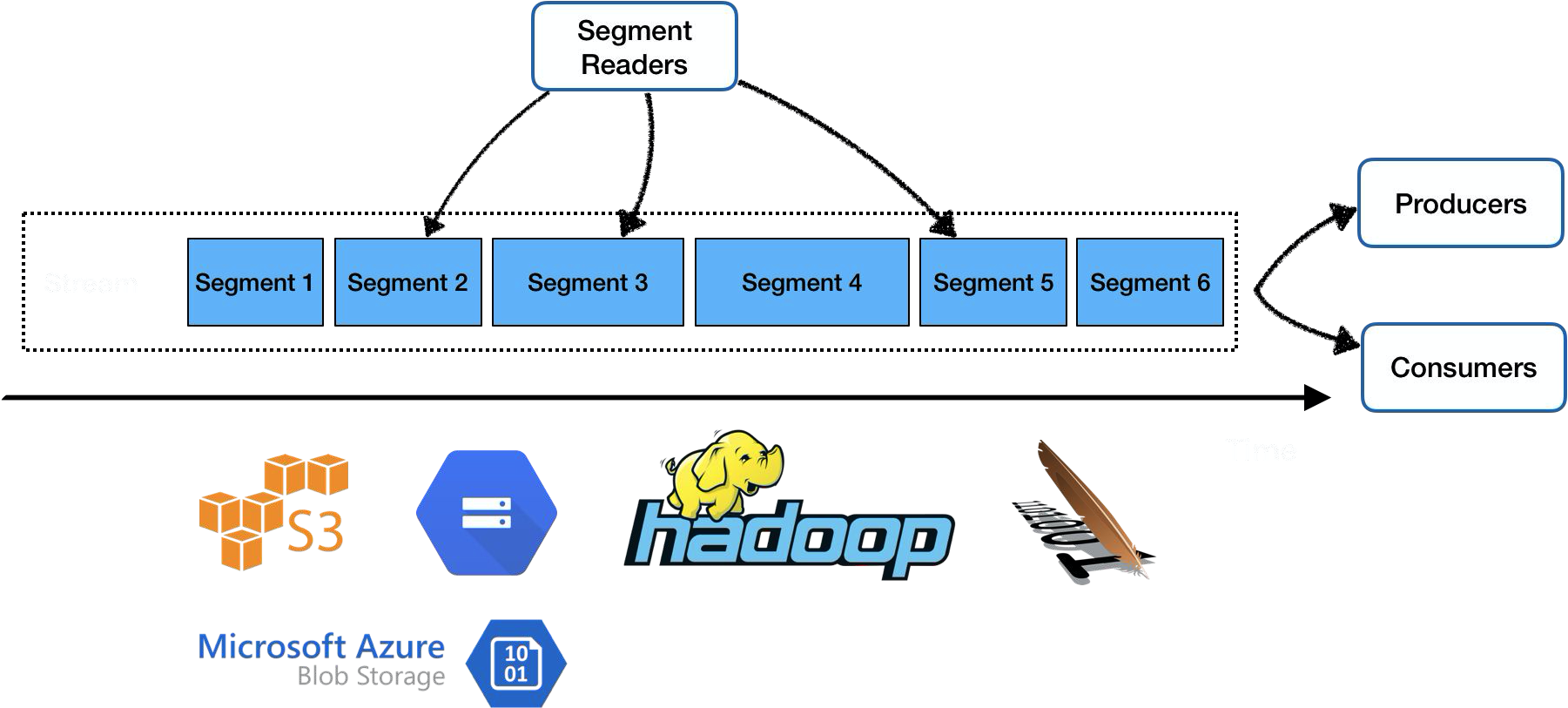
- Apache Pulsar provides two types of read API: pub-sub for streaming and segment for batch processing
- Apache Pulsar follows the general pub-sub pattern. (a) a producer publishes a message to a topic; and (b) a consumer subscribes to the topic, processes a received message, and sends a confirmation after the message is processed (Ack).
- A subscription is a named configuration rule that determines how messages are delivered to consumers. Pulsar enables four types of subscriptions that can coexist on the same topic, distinguished by subscription name:
- Exclusive subscriptions: only a single consumer is allowed to attach to the subscription.
- Shared subscriptions: multiple consumers can subscribe and each consumer receives a portion of the messages.
- Failover subscriptions: multiple consumers can attach to the same subscription, but only one consumer can receive messages. Only when the current consumer fails, the next consumer in line begins to receive messages.
- Key-shared subscriptions: multiple consumers can attach to the same subscription, and messages with the same key or same ordering key are delivered to only one consumer.
- In a batch process, Pulsar adopts segment-centric storage and reads data from the storage layer (BookKeeper or tiered storage).
- Building a unified data processing stack using Pulsar and Spark
- Once we understood Apache Pulsar, we chose that product to build a new unified data processing stack using Pulsar as the unified data store and Spark as the unified computing engine.
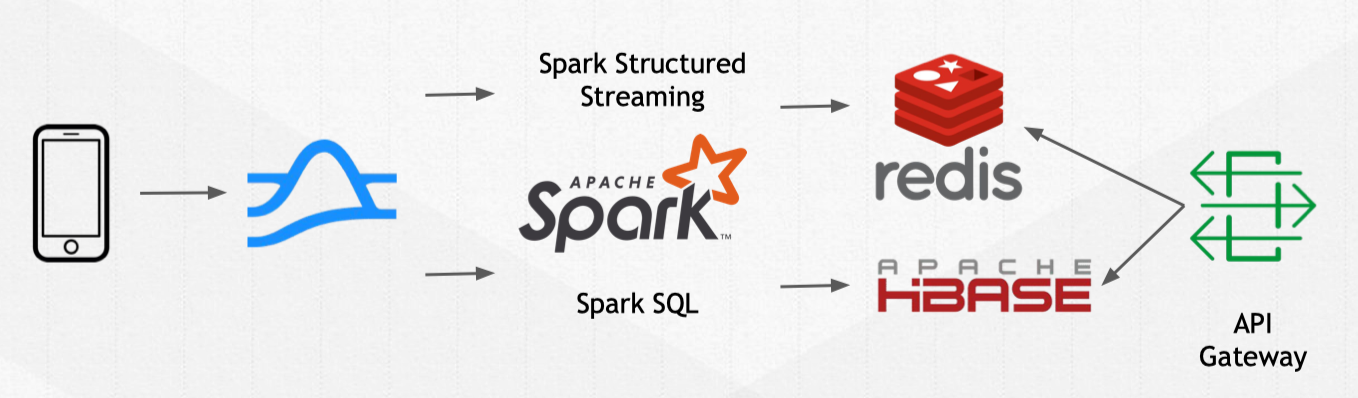
- Spark 2.2.0 Structured Streaming provides a solid foundation for batch and streaming processes. You can read data in Pulsar through Spark Structured Streaming, and query historical data in Pulsar through Spark SQL.
- Apache Pulsar addresses the messy operational problems of other systems by storing data in segmented streams. The data is appended to topics (streams) as they arrive, then segmented and stored in scalable log storage, Apache BookKeeper. Since data is stored as only one copy (the “source of truth”), it solves the inconsistency problems in Lambda Architecture. Meanwhile, we can access data in streams via unified pub-sub messaging and segments for elastic parallel batch processing. Together with a unified computing engine like Spark, Apache Pulsar is a perfect unified messaging and storage solution for building the unified data processing stack. In light of all this, we decided to adopt Apache Pulsar to re-architect our stack for our business.
Migrating to Apache Pulsar
To enable Apache Pulsar for our business, we need to upgrade our data processing stack. The upgrading is done with two steps.
First, import data from the old Lambda based data processing stack. Our data is comprised of historic data and real-time streaming data. For real-time streaming data, we leverage pulsar-io-kafka to read data from Kafka and then write to Pulsar while keeping schema information unchanged. For historic data, we use pulsar-spark to query data stored in Hive by Spark, and store the results with Schema (AVRO) format into Pulsar. Both pulsar-io-kafka and pulsar-spark are already open-sourced by StreamNative.
Second, move our computation jobs to process the records stored in Pulsar. We use Spark Structured Streaming for real-time processing, and Spark SQL for batch processing and interactive queries.
The new Apache Pulsar based solution unifies the computing engine, data storage, and programming language. Compared with Lambda Architecture, the new solution reduces complexity dramatically:
- Reduce complexity by 33% (the number of clusters is reduced from six to four);
- Save storage space by 8.7% (expected: 28%);
- Improve production efficiency by 11 times (support SQL);
- Higher stability due to the unified architecture.
Conclusion
Apache Pulsar is a cloud-native messaging system with layered architecture and segment-centric storage. Pulsar is a perfect choice for building our unified data processing stack. Together with a unified computing engine like Spark, Apache Pulsar is able to boost the efficiency of our risk-control decision deployment. Thus, we are able to provide merchants and consumers with safe, convenient, and efficient services.
Pulsar is a young and promising project and the Apache Pulsar community is growing fast. We have invested heavily in the new Pulsar based unified data stack. We’d like to contribute our practices back to the Pulsar community and help companies with similar challenges to solve their problems.




