
Overview
In the realm of distributed messaging systems, Apache Kafka and Apache Pulsar stand out as popular choices for high-throughput, real-time data streaming. While both platforms excel in their respective capabilities, Pulsar has garnered attention for its remarkable speed.
This may be surprising given that the architecture of Pulsar is more sophisticated, notably involving the presence of an extra network hop between multiple layers. And yet, despite the presence of a network, Pulsar can outperform Kafka in terms of performance. This article explains how this is possible.
Understanding the Architectural Differences
To comprehend the disparities in performance, it is crucial to examine the architectural variances between Pulsar and Kafka.
Kafka Architecture
Apache Kafka operates on a three-tier architecture with the presence of Application Clients, Kafka Brokers and ZooKeeper.
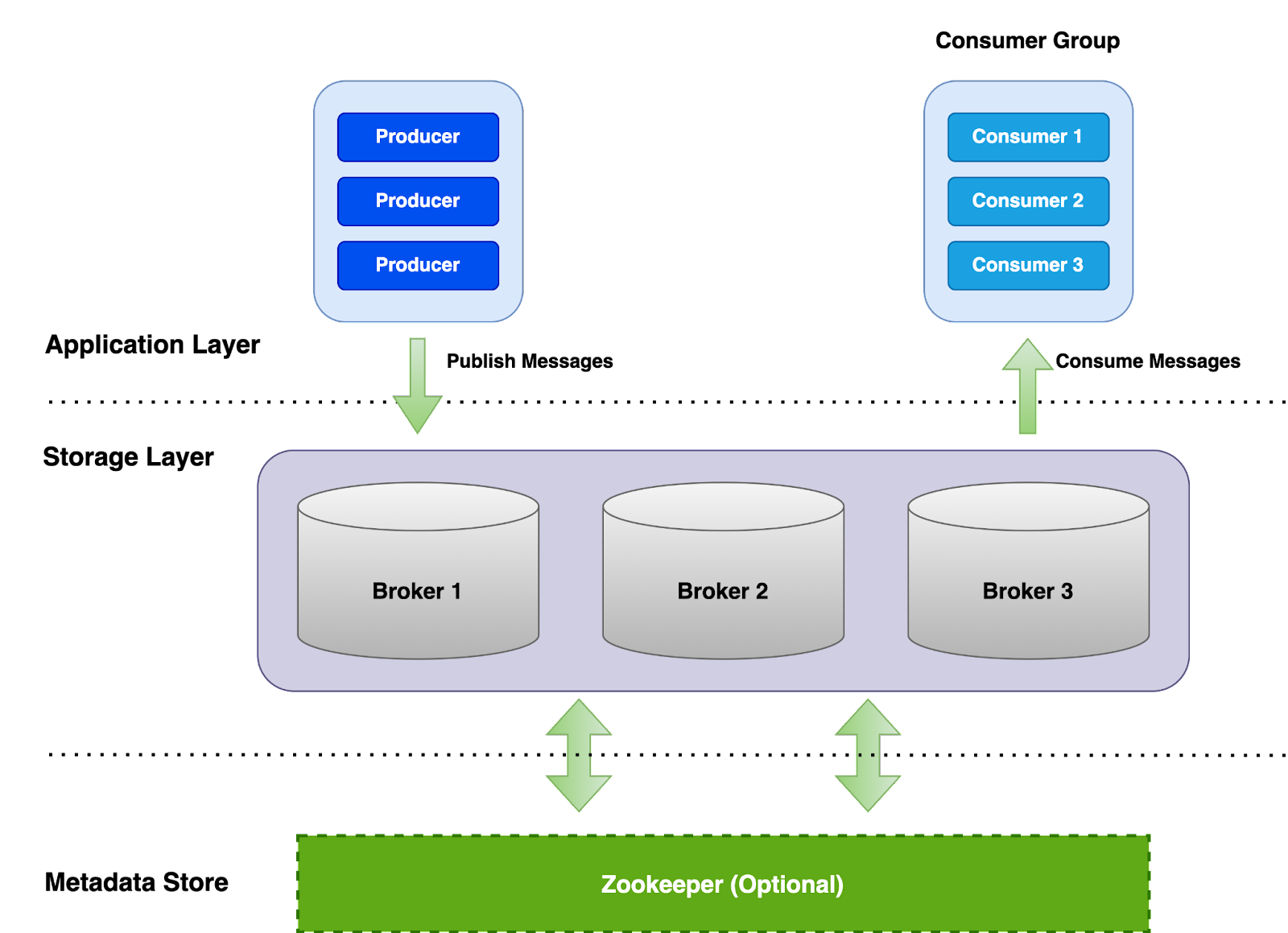
Kafka Producer and Consumer clients connect directly to Kafka brokers for reads and writes. Zookeeper serves as the metadata layer providing partition ownership and leader election, which doesn’t directly serve in the critical read or write path.
Additionally, by utilizing Kraft in a Kafka cluster, the traditional need for Zookeeper nodes could be eliminated in Kafka, resulting in a two-tier architecture.
Pulsar Architecture
In comparison, Apache Pulsar adopts a four-tier architecture comprising Clients, Pulsar Brokers, Apache Bookkeeper, and a configurable Metadata Store(e.g ZooKeeper, Etcd, RocksDB or Oxia). In some cases, we would even need a five-tier architecture with a Pulsar Proxy.
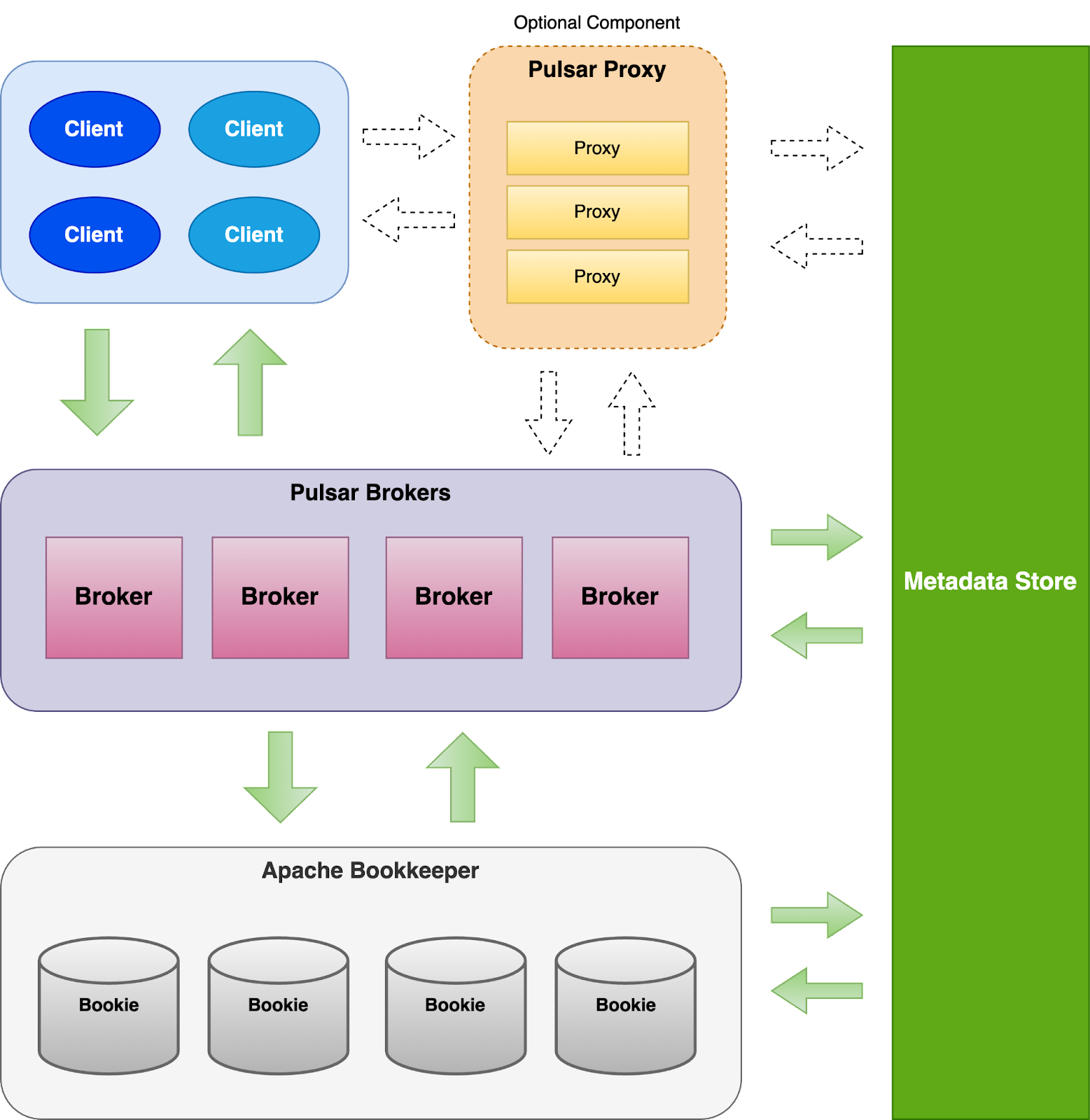
Pulsar Client can connect directly to Brokers to produce and consume messages as well as for topic lookup.
Pulsar proxy is an optional gateway component, which can be used when direct connections between Clients and Pulsar brokers are either infeasible or undesirable. For example, StreamNative Cloud adopts Istio in place of Pulsar Proxy to achieve high availability and performance.
Pulsar Brokers is a stateless component which serves mainly for two purposes:
- Topic lookup, which tells you which topic partition is owned by which broker
- Dispatcher, which transfers data and dispatch them via managed ledger by talking to Bookkeeper
Bookkeeper is simply the storage layer, similar to Kafka brokers in the sense where it persists all the data and serves reads and writes.
Pulsar supports configurable Metadata Store (e.g ZooKeeper, Etcd, RocksDB, Oxia). Historically, Apache ZooKeeper has been the most popular primary Pulsar metadata store. StreamNative recently invented Oxia, a better scalable metadata store. This metadata store is very critical to Pulsar since it is being used for coordination, and storing key metadata information such as topic partition ownership, Bookkeeper ledger metadata, etc.
When comparing the architectures of Pulsar and Kafka, it's noticeable that Pulsar assigns more granular roles to its components. However, intriguingly, Pulsar still manages to outperform Kafka in most scenarios. In the upcoming sections, we'll explore the factors contributing to Pulsar's impressive performance despite this architectural difference.
Kafka - Lack of Isolation
One prominent factor contributing to Kafka's relatively slower performance lies in its design.
Kafka does not inherently provide good IO isolation, leading to substantial interference between read and write traffic.
- Read and writes can impact each other: Kafka brokers do not have separate dedicated IO threads exclusively for read and write requests. Besides, high write throughput can lead to increased disk and I/O pressure on Kafka brokers which can affect read performance, and vice versa, high read rates from consumers can potentially impact write performance as well.
- Lack of Isolation among different topics or partitions: There is no hard separation or resource isolation between topics or partitions, and they can all compete with each other for disk and network IO. This means one hot topic/partition can impact its local neighbors' performance a lot in a persistent manner, which makes Kafka difficult to be maintained in a multi-tenant environment
- Lack of isolation between disks, cpu and network resources: Kafka brokers act as both a serving layer and the persistence storage layer. You can not scale them out independently, which means you will always hit the bottleneck for one of the resources first, either the disk first or the cpu/network first. For on-prem users, it’s fairly difficult to tune resource allocation to perfectly fit the use case or traffic pattern. For cloud users, unfortunately, Kafka itself is not very cloud friendly, e.g. running Kafka on K8S is still a challenge in terms of operation.
- Tightly coupled partitioning model: Kafka partitions need to be scaled accordingly for the consumer jobs based on the data processing speed. However, having too many partitions at the same time will hurt batch efficiency as well as compression rate. So it is sometimes hard to tune the number of partitions for a kafka topic.
Pulsar - Better Isolation
Apache Pulsar has been designed with a focus on achieving strong IO isolation, which is one of its key architectural strengths.
Separating Compute from Storage
Pulsar’s architecture allows for independent scaling of Brokers for compute and network, and scaling Bookies for disk space or IO, which provides a much better isolation and decoupling between disk and network throughput limitation.
This would be beneficial for certain scenarios, such as:
- Read heavy or high fan-out, but write throughput is low: You can independently scale out Brokers to handle more reads
- Extremely short or long retention: You can dynamically scale in or out bookies based on disk usage you need
- Write heavy or high fan-in, but reads are small: You can independently scale out bookies to handle more write throughput
Segmented Storage
Writes to a topic partition are split into segments, which are then stripped across multiple bookie nodes, instead of a single bookie.
This provides a better isolation between topics and partitions so that one hot topic or partition will not keep impacting other topics living on the same node.
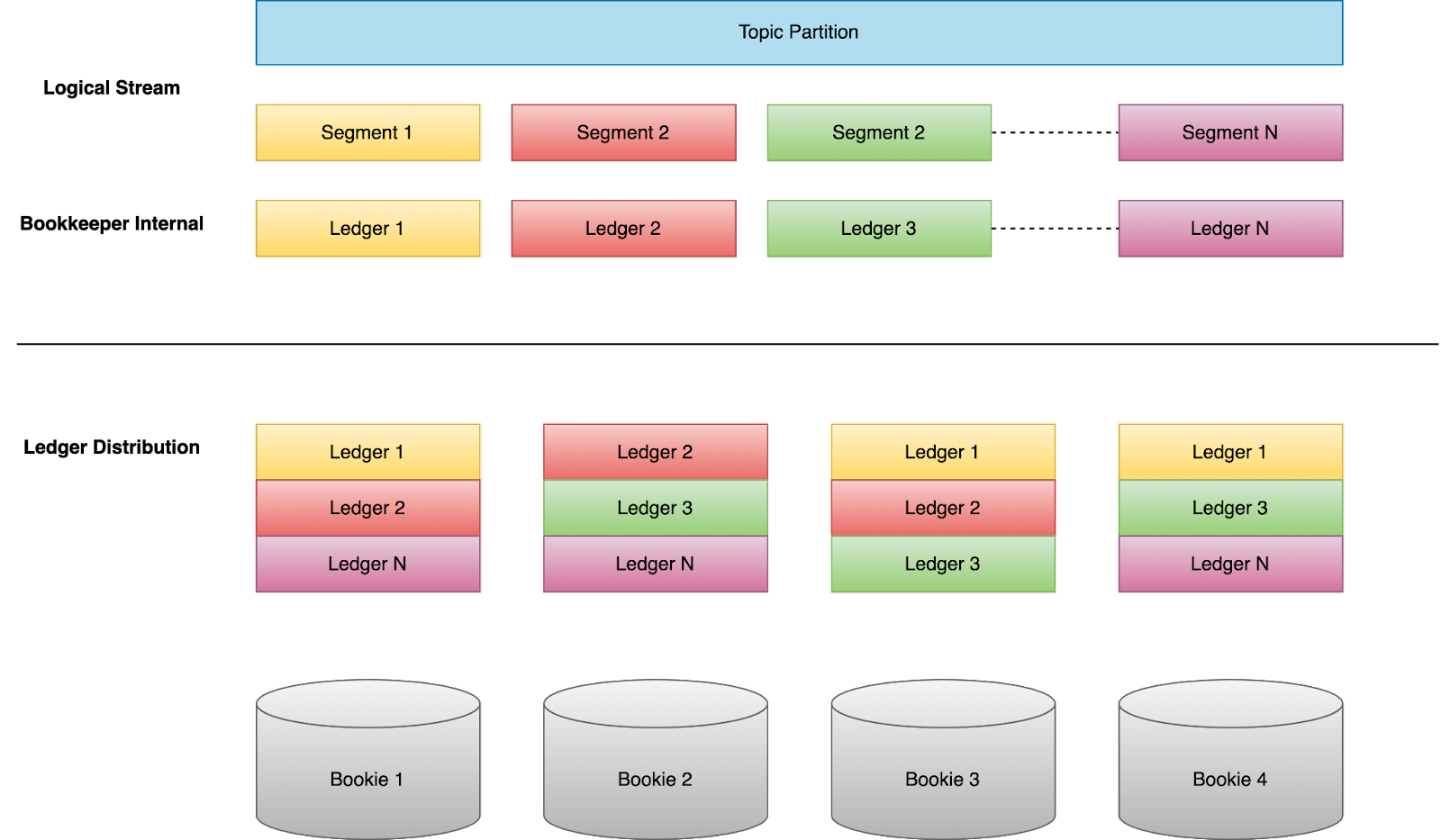
To be more specific, the data of any Pulsar partition will be spread across the whole bookkeeper cluster, unlike Kafka, all of the data of a single partition always stays on the same set of brokers. The benefit of this is that, if a single partition becomes really hot or overloaded, it’s not an issue for Pulsar because load will be spread evenly to all Bookies, but it’s a big problem for Kafka because it will overload the three Kafka brokers which own that partition, and thus cause issues for other topics owned by the same set of brokers.
Bookkeeper IO Isolation
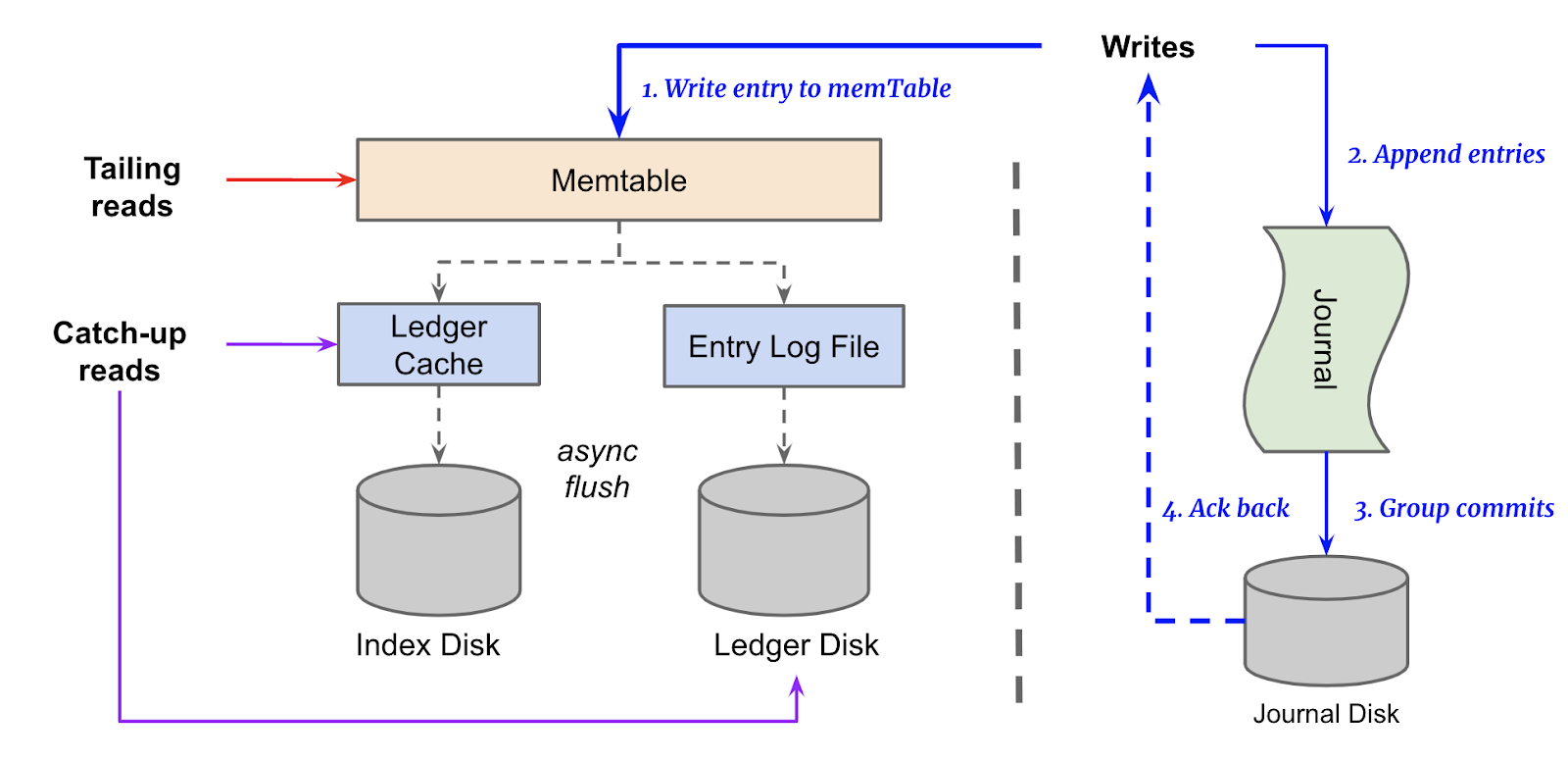
Write Ahead Log (Journal)
BookKeeper uses a write-ahead log mechanism for durability. Data is first written to the Journal in sequential order and append-only manner before being persisted to the main ledger disk.
Storage Separation
BookKeeper separates the storage device used for the journal from the main ledger storage and the journal is usually stored on faster and more durable storage (e.g., SSDs) to handle the write-intensive workload effectively.
Tailing reads are always served from the memTable, and only catch up reads will be served from the Ledger Disk and Index Disk. As a result, heavy reads in Bookkeeper will not impact incoming write performance because they are served from different physical disks, and have pretty good isolation.
Summary
In summary, even though Kafka requires one or two less network hops than Pulsar, the latency overhead brought by read-write interference could potentially be a few magnitudes higher than network hop latency. Therefore, Kafka's performance can be influenced a lot by inefficiencies in other areas rather than the number of network hops.
Network Hops
Compared to disk performance, network latency is always a bigger concern since the network can become unreliable and thus network latency can go extremely high. A frequent concern raised by Pulsar users revolves around the network could potentially act as a bottleneck in Pulsar's multi-tier architecture.
Now let’s deep dive into this topic and see whether network hops are a real concern for Pulsar or not
Network Hop Latency can be very Low
Network hop latency can be optimized and tuned to a very low level if machines are close to each other or sharing the same network. For example, servers in the same datacenter or region can achieve a ping latency with less than 1ms. EC2 instances on AWS within the same region typically have a ping latency with less than 1ms as well even for hosts in different AZs, and similar for GCP.
With this data in mind, as long as Pulsar components are all deployed within the same region, one or two extra hops would just mean a few extra milliseconds of latency overhead, which can be almost ignorable.
Write Path
Just with the fact that Pulsar has a more complicated multi-layer architecture doesn’t mean it has more hops in its read and write critical paths. The actual end to end latency for publishing and consuming depends mainly on how it works under the hood.
So let’s dive more into how Kafka and Pulsar write paths look like.
Assuming the below replication settings being used:
Kafka Broker:
- ack=all
- replication.factor=3
- min.insync.replicas=2
Pulsar:
- write quorum size=3
- ack quorum size=2
Kafka: Leader Follower Replication
Kafka relies on a poll model, where write requests are sent to the leader broker first. The leader broker then has to wait for ALL of its ISR followers to fetch and replicate data, and acknowledge them back. This is more error prone because one slow follower Broker in the ISR can cause write operations to become significantly slower or even time out, impacting overall performance. And if the Leader Broker is experiencing some slowness, writes will also be impacted.
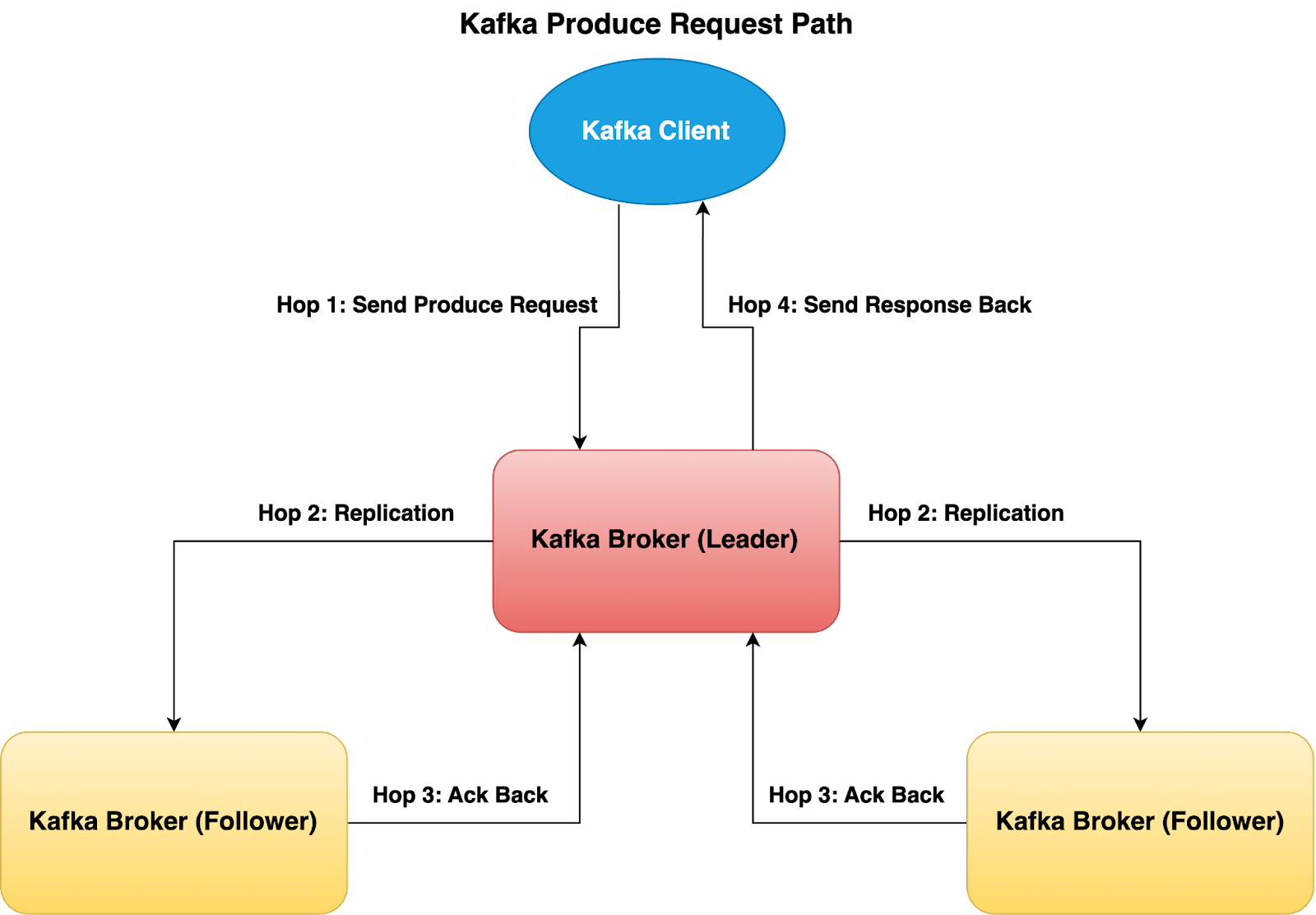
Of course, we can choose to reduce replica.lag.time.max.ms config so that if the follower broker becomes too slow, it will drop out of ISR and then we will be able to satisfy the write requests faster with only 2 brokers. However it also means that you will observe under replicated partitions and constant ISR expand/shrink operations, which impacts overall durability and reliability.
Pulsar: Parallel Replication
In contrast, when writing to BookKeeper, Pulsar leverages a parallel replication strategy, where it sends the writes to all 3 bookies at the same time waiting for 2 acknowledgments.
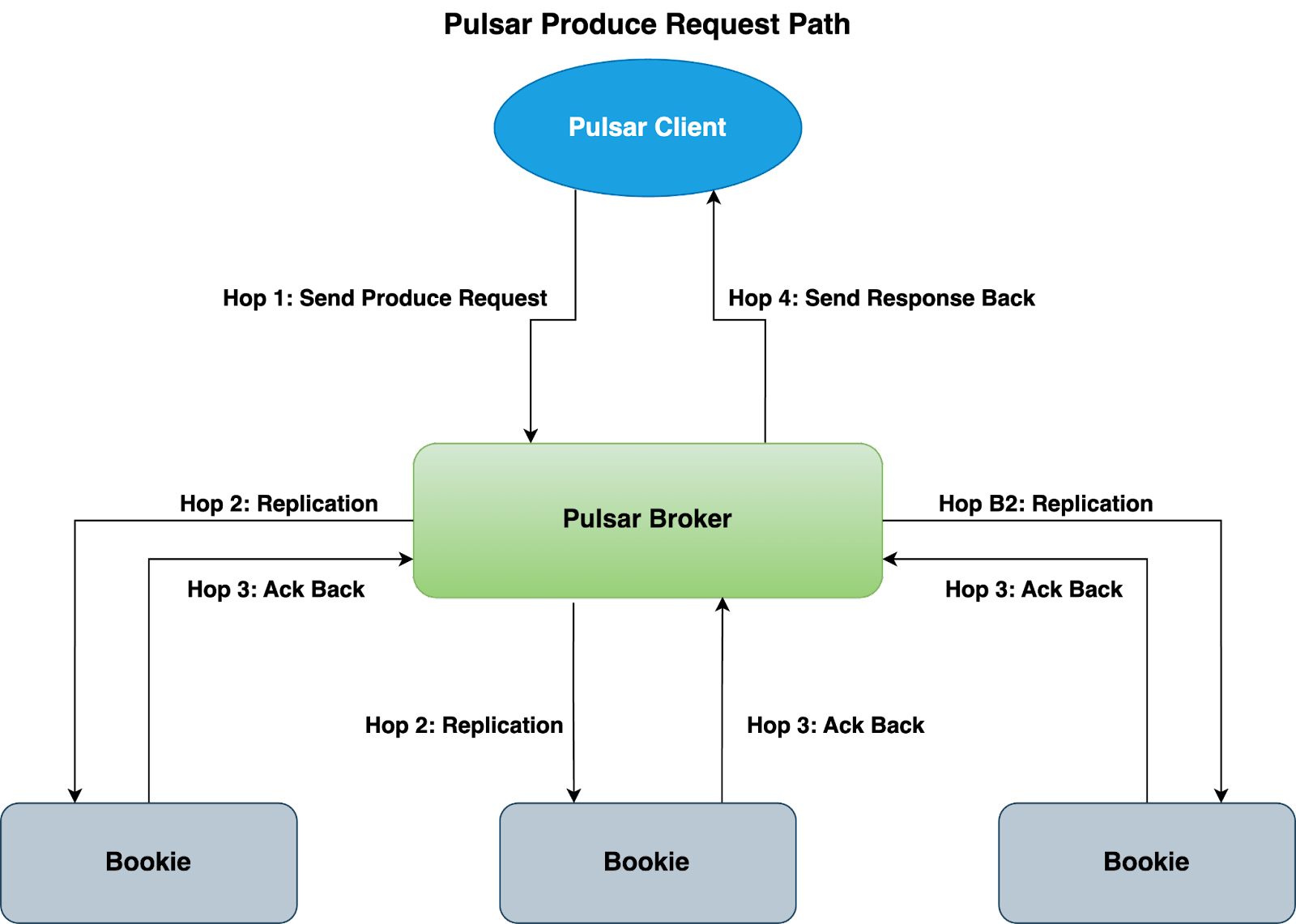
Since writes happen in parallel, with regards to write operations, both Pulsar and Kafka have to go through four hops end to end as shown in the above diagrams. Those hops on high level are:
- Client send a produce request to Kafka/Pulsar broker
- Kafka/Pulsar Broker replicate data by talking to the other replicas
- Kafka/Pulsar Broker get the acknowledgement response from other replicas
- Kafka/Pulsar Broker send the write response back to the client
In conclusion, the major difference between Kafka and Pulsar for writes path is how the underline replication works, and the end to end number of hops are actually the same for both.
Read Path
Kafka: Read from Leader
Let’s first look at how Kafka fetch requests are being served.
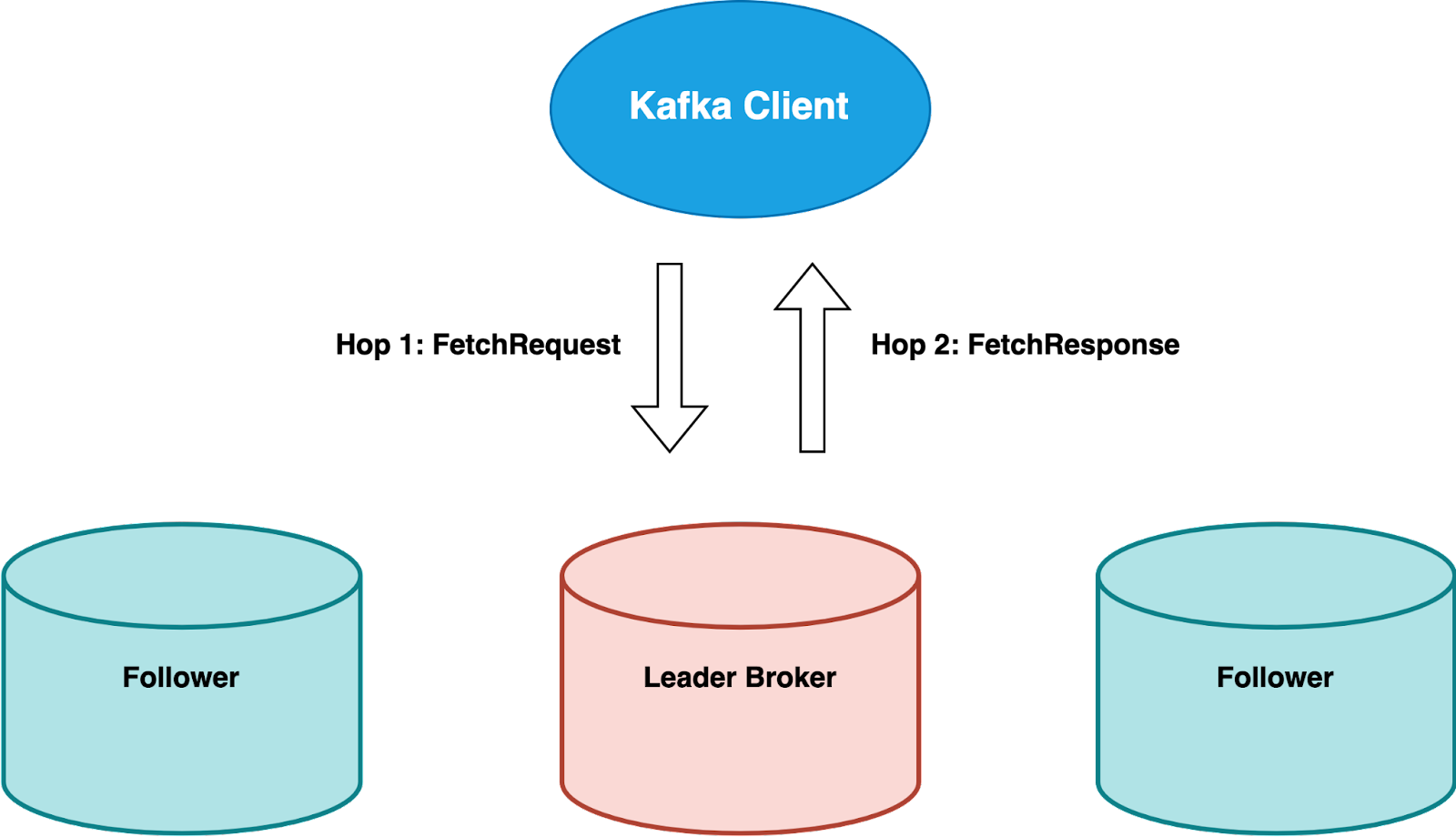
For fetch requests, the Kafka client will send it to the leader broker and just wait for the leader to send the response back, so there are only 2 hops which is extremely simple.
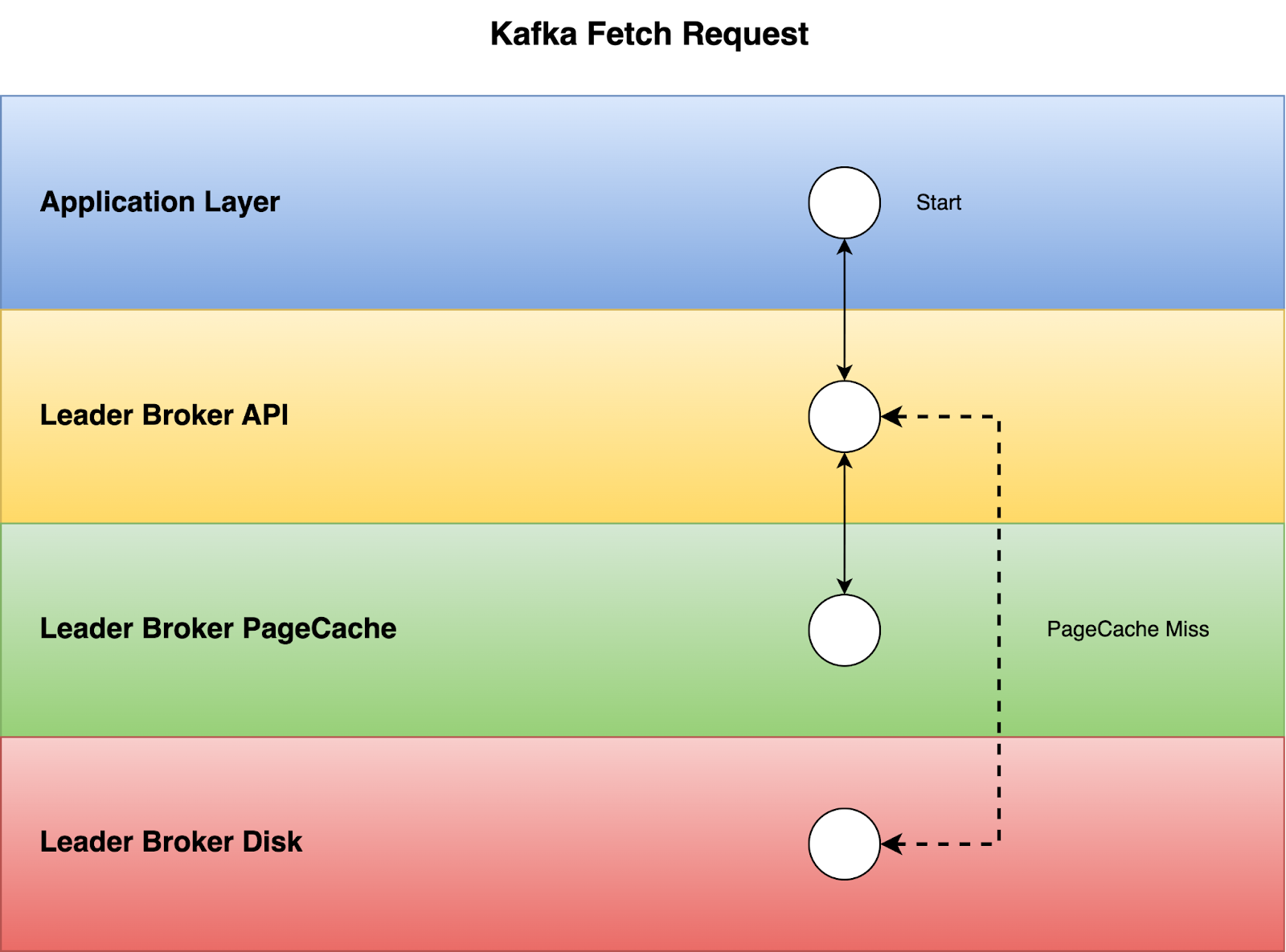
If we look into what happens inside the leader broker, when the leader broker receives the FetchRequest, it will first try to fetch the batch of records from PageCache, and if it can’t find the data from PageCache, then it will start seeking the data from the disks.
This overall process looks simple, but one critical drawback for this approach is that it has a very tight dependency on the leader broker being healthy and responsive, not being overloaded or having some network issues.
As we know that leader election will only happen when the leader becomes totally unresponsive, but not being slow. Kafka by default doesn’t allow you to read from any follower replicas, so if the leader encounters any failures or becomes slow, it will slow down all the fetch requests by a lot and consumers will start falling behind. Although this can be improved by adopting a specific cross-region replica distribution model such as KIP-392, it is not straightforward to configure and thus it is not very widely adopted by most Kafka users.
Pulsar: Speculative Read
Now let’s take a look at how Pulsar serves read requests.
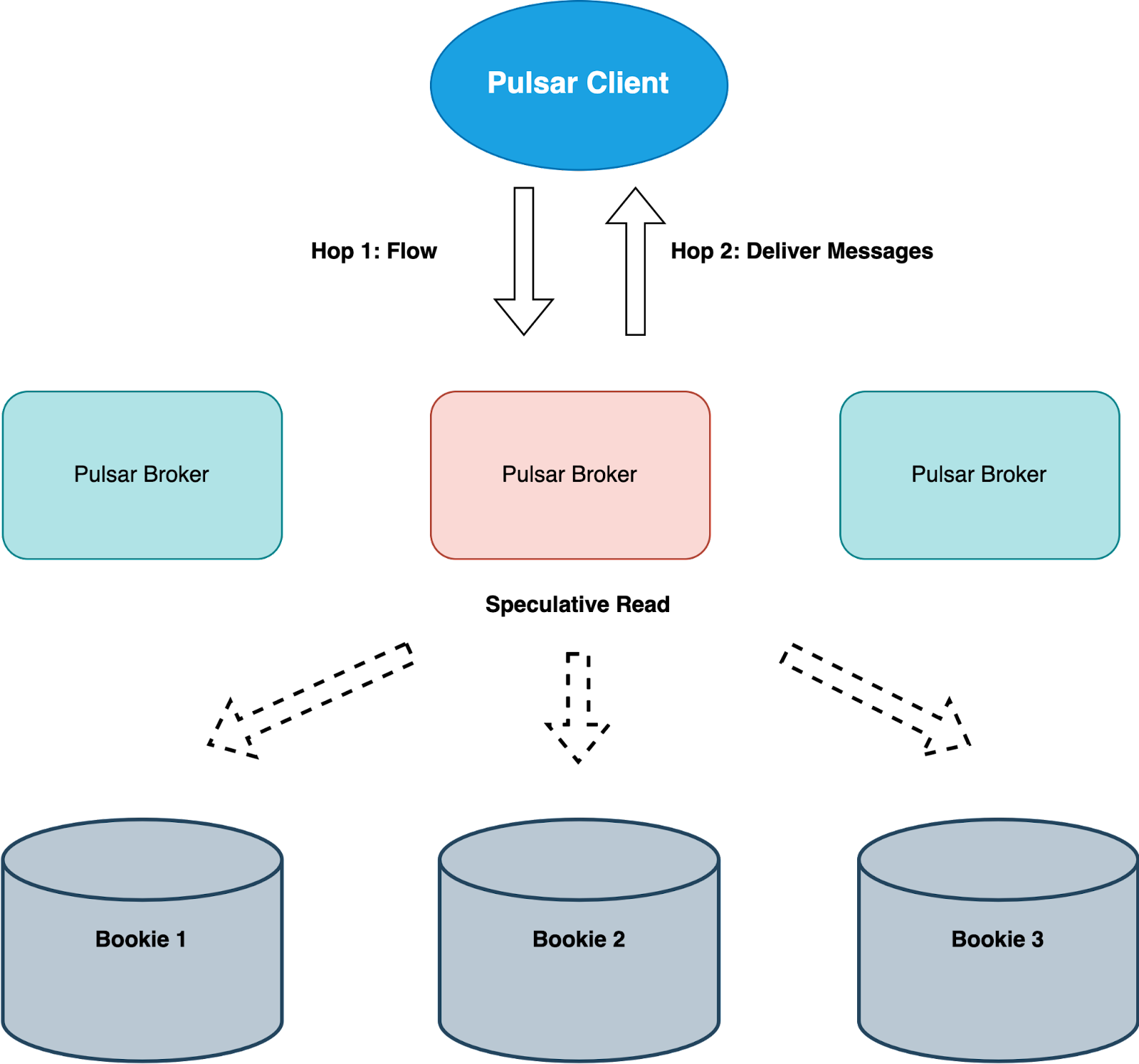
Similar to the leader concept in Kafka, Pulsar also has an ownership concept for its brokers, so one of the Pulsar brokers will own the partition which the client is trying to consume from. Tailing reads would be served from the Pulsar Broker managed ledger cache, but in case of cache miss, Pulsar Broker will get the data from the Bookies via speculative read.
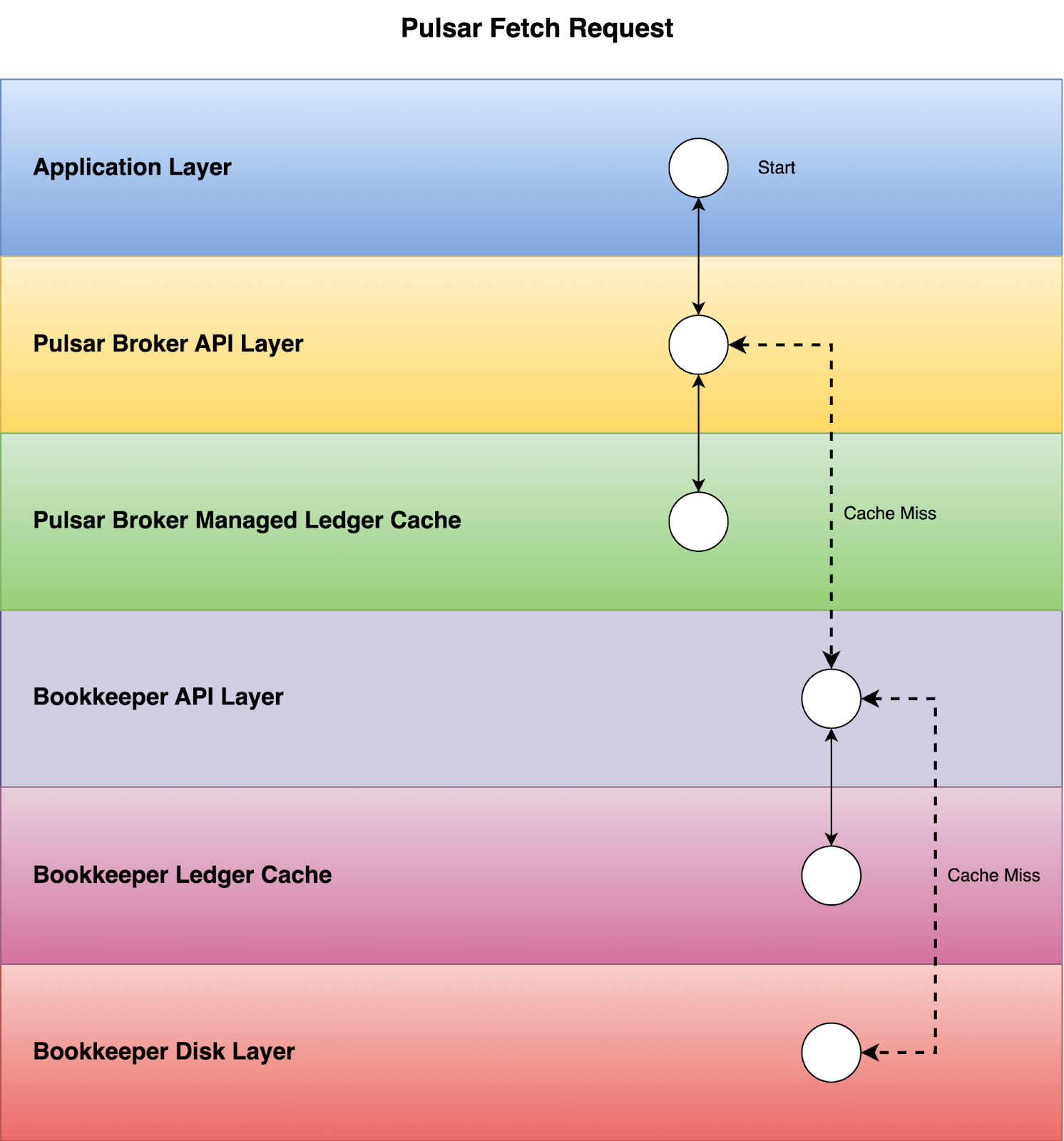
As shown in the above graph, Bookies also have their own ledger cache to serve tailing reads, so most tailing read requests still won’t incur any disk read IOPs.
While Pulsar entails one potential additional network hop from the read perspective, it does not necessarily result in slower performance. This is because tailing read requests in Pulsar are primarily served from the Pulsar Broker managed ledger cache, rather than from Bookie storage layer. Thus, the extra network hop does not really impose a significant performance penalty for read operations.
Compared to Kafka, Pulsar's design has its own pros and cons.
Pros
- In most scenarios, serving tailing reads only need 2 hops for both Kafka and Pulsar
- Kafka requests are sticky to the leader, whereas Pulsar can easily unload a partition and switch owner
- Pulsar is resilient to single or multiple Bookie failures using speculative reads, where as Kafka can not serve reads when partition is offline
Cons
- When partition ownership change or catch up reads happens, Pulsar Broker will not have any cache in memory, so all reads will have to be served from Bookies, resulting in extra hops and network bandwidth usage
Latency Sensitivity
Kafka is actually much more network latency sensitive than Pulsar, which means when there’s a network degradation, e.g. a bad/slow link, you would more often see latency impact in Kafka than in Pulsar for read and write.
One reason behind this is due to Kafka’s tightly coupled partitioning model. When a single broker becomes slow due to a degraded network, it will impact a lot of topic partitions across multiple brokers in the cluster.
- As partition leader, its followers might have trouble fetching data for replication.
- As a follower, it might have trouble to keep up with other leaders
- Consumers can only fetch data from the partition leader, not the followers
- Producers can only publish data to the partition leader, not the followers
Pulsar on the other hand is more resilient than Kafka in terms of network failures or degradation, this is benefited from several factors
- Single slow bookie will have very minimum impact to the overall performance
- Parallel Replication
- Speculative Reads
- Ensemble Change on write failures
- Pulsar Broker and partitions are loosely coupled and topic partition can easily be unloaded
- Auto Rebalance
Pulsar brokers are stateless, the broker load balancer can easily rebalance the topic ownerships based on the broker's dynamic load. This is also helpful when a broker is unavailable(network-partitioned, down), since orphan topics will be immediately reassigned to the available brokers.
Connection Limitations
Kafka suffers from fan-in connection limitations since, without a proxy layer, all connections are strictly routed to the partition leader. This limitation leads to significant garbage collection problems and restricts scalability to support a high number of producer connections.
To test out the connection limitation for Kafka brokers, we have done some specific benchmarks, in which we keep sending a fixed amount of write traffic, around 300k events/second with average event size of 500 bytes per broker, but through a different number of producer clients.
The Kafka benchmark is performed using the following bare metal setup:
- CPU: Intel Xeon or AMD EPYC 2.1 GHz processor with 64 cores
- Storage: Two 4TB RPM NVMe SSD drives (JBOD)
- Memory: 512GB of RAM
- Network: 100Gb Nic bandwidth
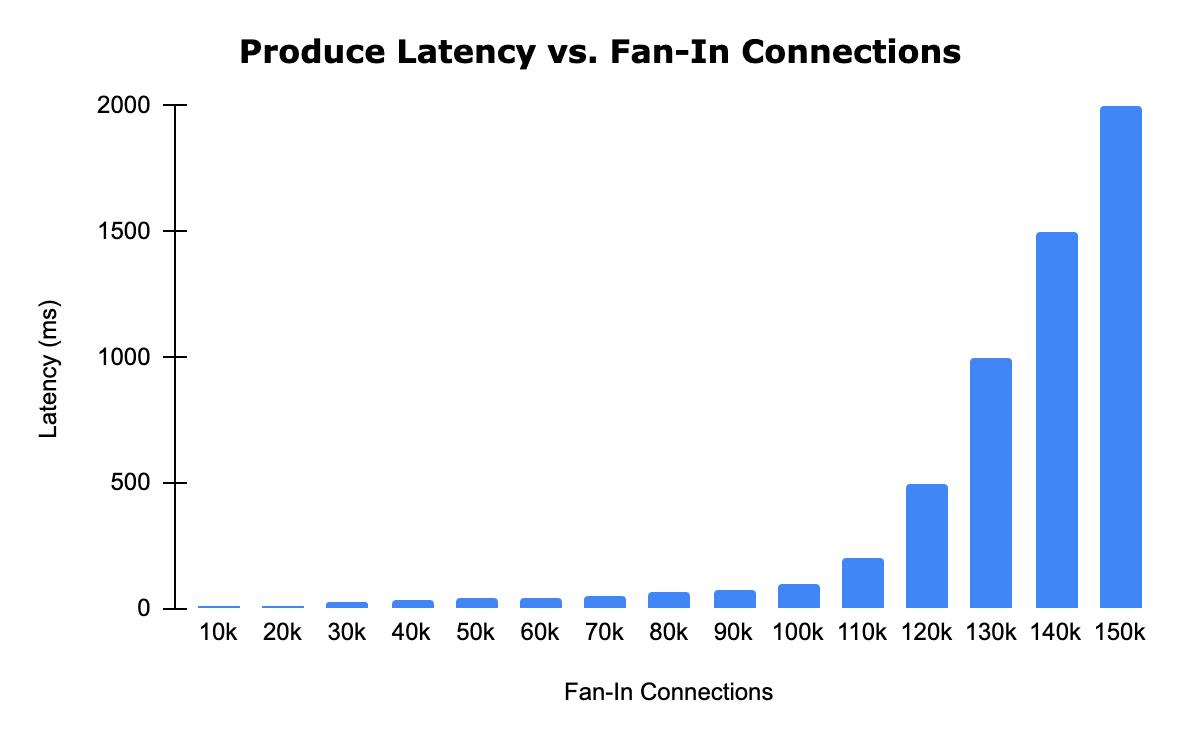
The above Kafka benchmark result shows that as the total number of fan-in connections for each Kafka broker crossed over 100k, we started to see performance degradation. When the number of connections got close to 150k, we started to see more produce failures as well as high GC time (around 20 to 40 seconds)
Scaling the number of Kafka brokers just for connections is expensive, and it does not help a lot because when using round robin partitioning, each single client instance will still create a dedicated connection to every single broker. So adding more brokers doesn’t change the fact that the whole Kafka cluster can still only support up to around 120k-150k clients. The major reason why performance starts to degrade when connections are high is due to the GC overhead brought by extra connections.
In contrast, Pulsar overcomes this challenge by having stateless Pulsar Brokers as a proxy layer between client and storage, which can be independently scalable to handle fan-in connections.
With Pulsar brokers' stateless characteristic, adding new brokers is relatively cheap, and Pulsar Broker Load Balancer would seamlessly rebalance partitions in a bundle to the new brokers without the need to move data at the bookie layer. As a result, a Pulsar cluster can easily handle many more connections than a Kafka cluster with its more sophisticated architecture.
Conclusion
Despite potential network bottlenecks in its architecture, Pulsar outperforms Kafka in terms of speed in a lot of scenarios. This advantage stems from efficient IO isolation, optimized read and write performance, expandable network bandwidth, and more scalable connection handling.
As both Pulsar and Kafka continue to evolve, it remains crucial for organizations to evaluate their strengths and weaknesses based on specific use cases and requirements. Understanding the nuances of their architectures empowers decision-makers to make informed choices when selecting the most suitable messaging system for their real-time data streaming needs.





.png&w=1536&q=100)