In our previous blog post, we were excited to announce the public preview release of the Ursa Engine, now available on StreamNative Cloud. At its core, the Ursa Engine features a headless, multi-modal storage layer called Ursa Stream Storage, which leverages object storage (S3) for both replication and storage to achieve cost-effective data streaming. Now, we're taking this principle even further by introducing Universal Linking—a solution designed to address the challenges of migration and data replication across diverse environments while reducing network costs.
Built on top of Ursa Stream Storage, Universal Linking is available as a Private Preview feature on StreamNative Cloud for our early access partners. This innovative solution redefines how independent data streaming clusters—whether Kafka or Pulsar—can be connected and migrated, enabling seamless data replication between clusters and management of "mirrored" data streams, even when different protocols are involved. We’re excited to share the possibilities Universal Linking opens up, enhancing interoperability between data streaming platforms and potentially transforming the future of data streaming.
Topic Mirroring in Apache Kafka and Geo-replication in Apache Pulsar
Data replication tools are commonly used to replicate data between clusters for various purposes, such as active-passive setups for disaster recovery, active-active configurations for high availability, and geo-replication for data locality. However, existing solutions have their limitations.
In the Kafka ecosystem, several tools are used for data replication, including Kafka MirrorMaker (open source), Uber’s uReplicator (a fork of Kafka MirrorMaker, open source), Confluent Replicator (commercial), and Confluent Cluster Linking (commercial). While MirrorMaker and uReplicator are open-source tools that provide basic data replication between Kafka clusters, they have limitations in offset management, schema replication, and operational complexity. Confluent Replicator builds on MirrorMaker with enterprise-grade features like schema integration, data filtering, and enhanced monitoring but requires adopting Confluent's platform. Confluent Cluster Linking offers native, real-time replication between clusters with minimal operational overhead but is proprietary and requires licensing.
On the other hand, Apache Pulsar offers a built-in geo-replication feature that enables policy-based replication across clusters within a single Pulsar instance. Despite its power and flexibility, this feature is limited to Pulsar clusters using the Pulsar protocol.
While these tools use different frameworks—some leveraging Kafka Connect as external tools, others being built directly into brokers—they share some commonalities. All these tools use a wire protocol to replicate data over the network and are restricted to a single protocol. As discussed in previous blog posts, networking is one of the most expensive components when operating a data streaming platform in the public cloud, making traditional approaches costly for replicating data within the same region.
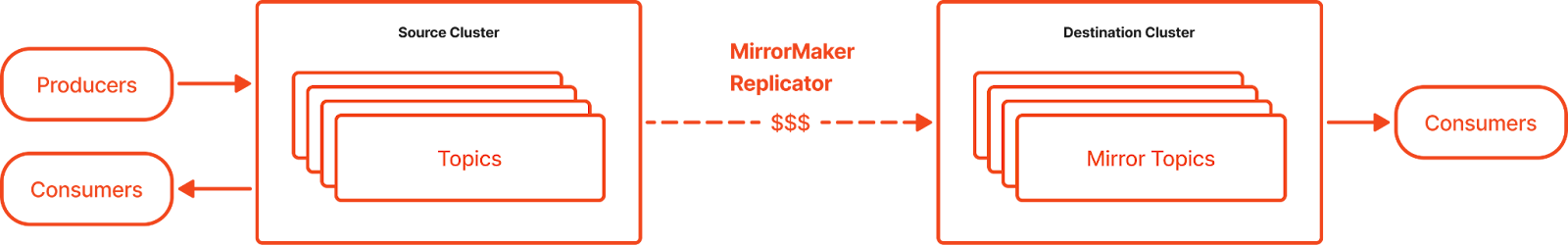
Introducing Universal Linking: Reimagining Data Replication Between Data Streaming Systems
At StreamNative, we envision democratizing data streaming to make it accessible, affordable, and scalable for organizations of all sizes. Cost-effectiveness and interoperability are two guiding principles of our vision. We have already achieved significant progress with single-cluster deployments through the introduction of the Ursa Engine on StreamNative Cloud. However, to enable global data streaming while maintaining these goals, we needed to rethink how existing platforms and clusters could interoperate and redefine what cross-cluster and cross-platform data replication should look like. Today, we are proud to unveil Universal Linking—our vision for seamless, cost-effective, interoperable data replication across different data streaming platforms.
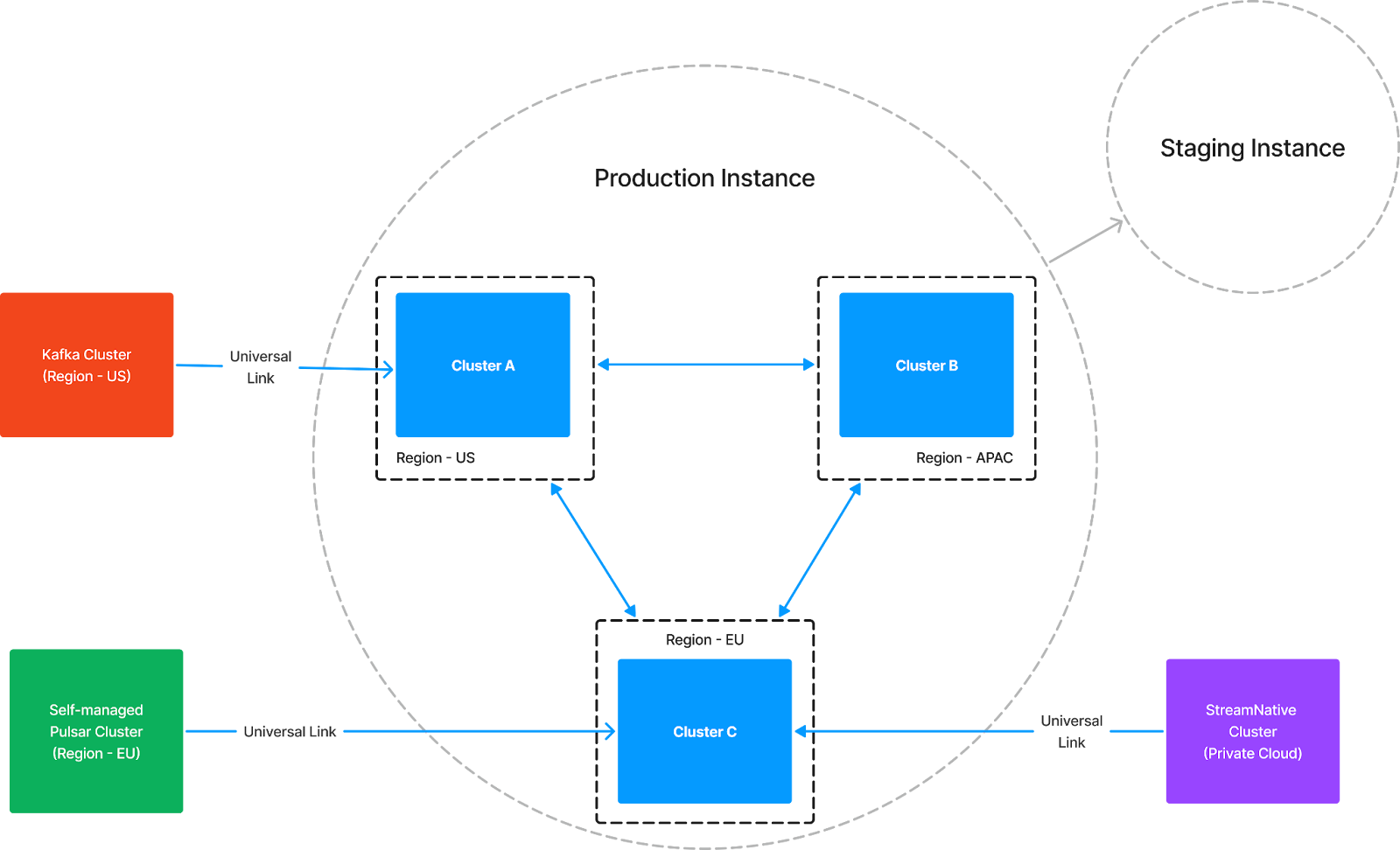
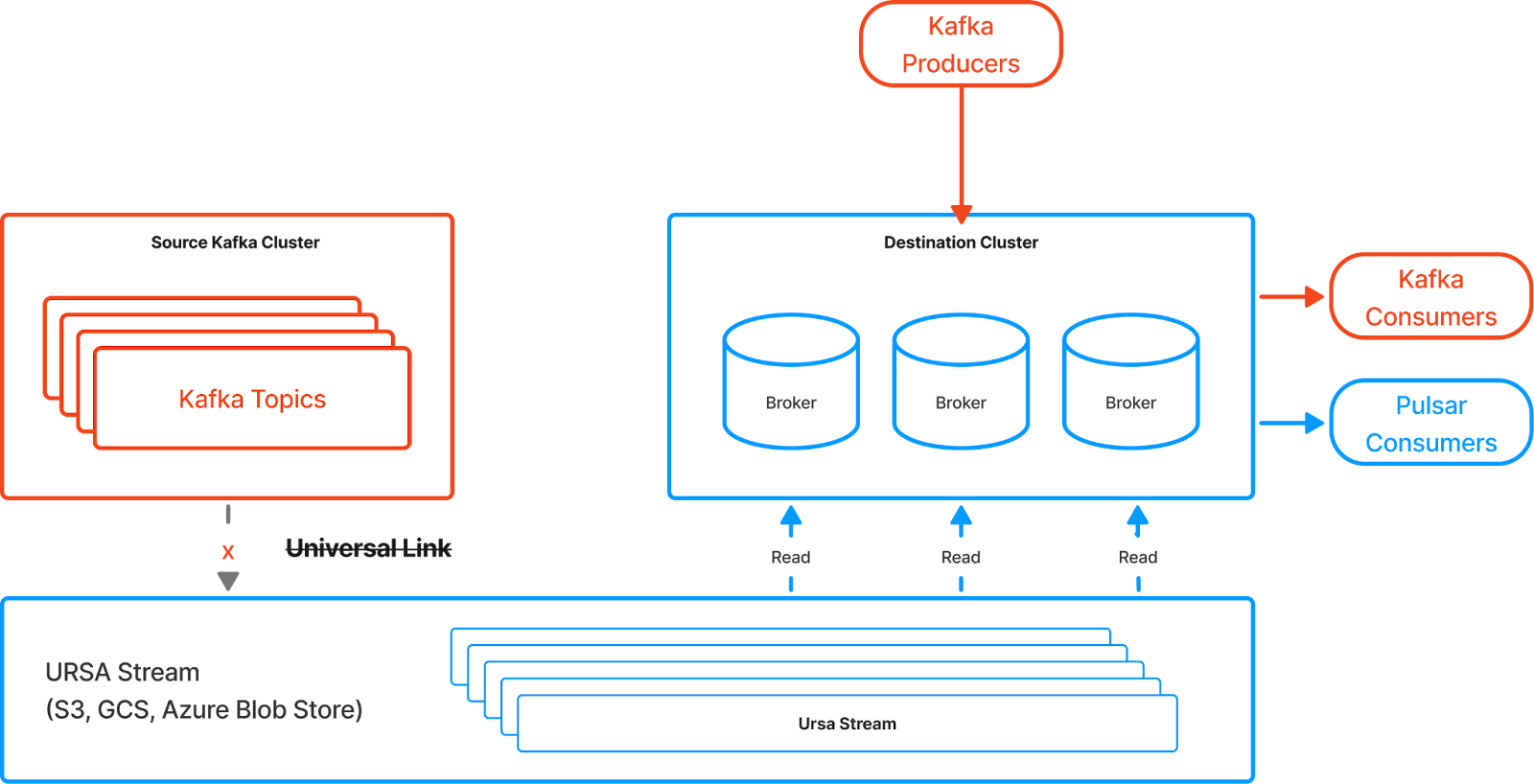
Universal Linking is a data replication service that replicates data from an external data streaming cluster—whether it's a self-managed Kafka cluster, a fully-managed Kafka cluster, a self-managed Pulsar cluster, or a StreamNative Private Cloud cluster—to clusters within a StreamNative instance (as illustrated below). Programmatically, it creates perfect copies of topics from the external cluster and keeps the data in sync with your StreamNative instance.
How It Works
Universal Linking allows you to replicate or migrate topics from an external Kafka or Pulsar cluster—replicating data partition by partition, byte by byte, along with all relevant metadata into a designated cluster within your StreamNative instance. Establishing a Universal Link (UniLink) is as simple as configuring geo-replication between Pulsar clusters. You can do this by creating a UniLink—a named object that defines the properties of the source and destination clusters. That's all you need to set up this link.
snctl create unilink sfo-nyc
–source-cluster-name <name-to-identify-source-cluster>
–source-cluster-server <source-cluster-server>:9092
–source-cluster-config ‘{..}’
–destination-instance <streamnative-instance>
–destination-cluster <streamnative-cluster-to-link>
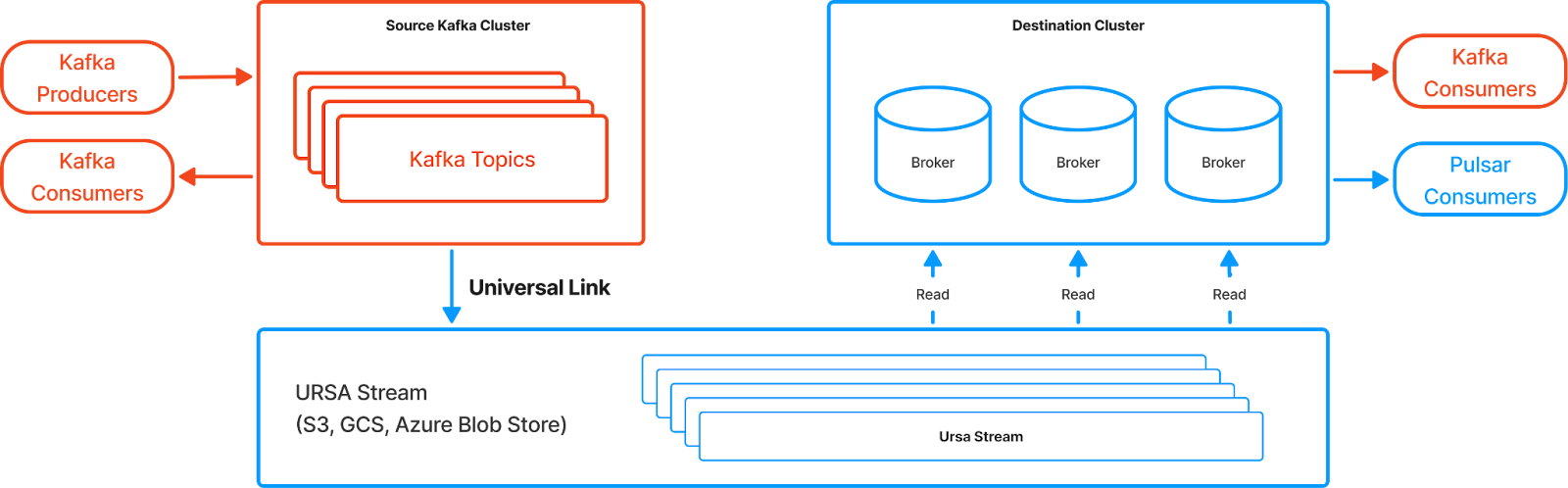
Once a Universal Link is created, a background UniLink job starts. Topics from the source cluster are copied and saved into a storage bucket, with data written in the Ursa Stream format. The storage bucket is then mounted by the destination cluster, allowing the brokers powered by the Ursa Engine to read the data and serve it using the Pulsar or Kafka protocol, making the mirrored topic nearly indistinguishable from the original source topic from the consumer's perspective.
The replication is real-time, continuous, and asynchronous, minimizing the impact on the source topic and avoiding strict latency requirements between clusters—enabling global replication. Importantly, Universal Linking operates independently of the internal replication within the source and destination clusters, ensuring no coupling between them. In a steady state, a mirrored topic will lag behind its source by only a few seconds, ensuring low recovery point objectives.
In addition to data replication, Universal Linking mirrors source topics' configurations, consumer offsets, and ACLs to ensure full synchronization. Mirroring can be stopped at any time, promoting the mirrored topic to a normal, mutable topic on the destination.
A Paradigm Shift in Data Replication
Universal Linking represents a paradigm shift in data replication. Instead of relying on direct networking over streaming protocols like Pulsar or Kafka, Universal Linking leverages object storage (such as S3) for both networking and storage. This architecture enables cost-effective, robust, flexible, and scalable replication across heterogeneous environments.
Data is copied into object storage using the Ursa Stream format, where it is persisted in lakehouse tables. From there, it can be consumed via Kafka or Pulsar protocols through stateless brokers, allowing seamless interoperability without the complexity of managing multiple replication protocols.
Universal Linking operates on a pull-based replication model, where the destination cluster fetches data from the source. Rather than writing data directly to the destination, it first saves it into object storage in the Ursa Stream format. If both the source and destination clusters are running in the same region, the UniLink job minimizes the networking requirements for replication.
The UniLink object contains all the required configurations for the destination cluster to fetch, store, and retrieve data. Once established, UniLink functions similarly to Pulsar’s "Cluster" concept, enabling persistent links that can be referenced by name. The destination cluster can then create mirror topics that replicate the source topic's data, partitions, and configurations. Any changes in the source topic, such as new partitions, are automatically detected, ensuring accurate replication.
This approach fundamentally differentiates Universal Linking from other replication methods and offers several key advantages:
1. Byte-to-Byte Copying & Metadata Preservation
Universal Linking preserves data fidelity by performing byte-to-byte copying and retaining essential metadata like topic information, offsets, and more. Once data is persisted in S3, it is ready for consumption via the Ursa Engine as if it were still in the original Kafka cluster.
2. S3 for Networking and Storage Layers
By utilizing object storage like S3 for both replication and storage, Universal Linking reduces the complexity and cost of maintaining high-throughput networking layers. S3’s scalability, combined with the efficiency of the Ursa Stream format, ensures data is both accessible and durable.
3. Backup and Restore for Kafka Clusters
Universal Linking can also be used as a cost-effective backup-and-restore tool. Snapshot your Kafka cluster, store it in a lakehouse in one region, and restore it in another region with ease—making it an ideal solution for disaster recovery and multi-region management.
4. Interoperability Between Kafka and Pulsar
With multi-protocol support in the Ursa Engine, Universal Linking bridges the gap between Kafka and Pulsar, offering seamless data mobility and interoperability. This empowers organizations to integrate different data streaming platforms without sacrificing flexibility.
An Operational View of Universal Linking
From an operational standpoint, Universal Linking significantly simplifies the mobility of data streams across various data streaming clusters. Whether migrating from an open-source Kafka cluster to StreamNative's Ursa Engine or moving between on-premises infrastructure and the cloud, Universal Linking ensures a smooth transition. Once you've created a new StreamNative cluster powered by the Ursa Engine, you can easily establish a link between your existing and new environments.
After setting up the Universal Link, replication begins in the background, automatically preserving critical data attributes such as topic partitions and consumer offsets. Once replication is complete, Universal Linking's initial release provides the ability to "fail forward" your mirror topics, promoting them to fully independent, writable topics on the destination cluster. This means you can seamlessly move clients from your old cluster to the new one without complex data reconciliation, ensuring minimal downtime and operational disruption.
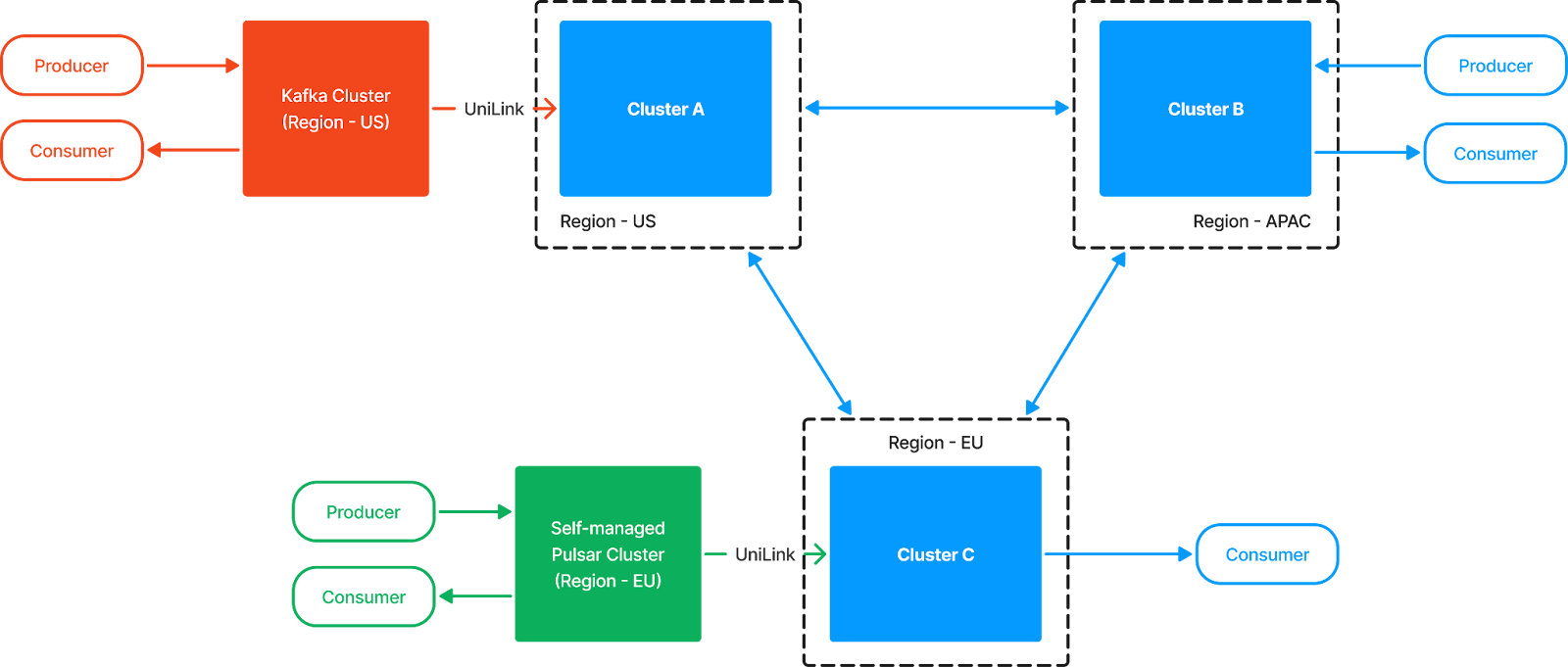
As organizations increasingly adopt hybrid cloud architectures, Universal Linking enables seamless data stream management across on-premises and cloud environments. Imagine having a hybrid cloud setup where your on-premises cluster contains critical topics that need to be used in the cloud—or vice versa. With Universal Linking, you can effortlessly connect (or migrate) your on-prem Kafka cluster to your StreamNative Cloud environment. This creates a reliable, cost-effective data highway that facilitates hybrid cloud applications, temporary cloud bursts, or full-scale migrations with minimal downtime and no data loss. Universal Linking ensures that your operations remain flexible and scalable, no matter where your data resides. This makes Universal Linking an excellent data replication solution for:
- Global data streaming architecture with multi-cloud and hybrid-cloud environments
- Data migration from a Pulsar or Kafka cluster to StreamNative Clusters powered by Ursa Engine
- Backing up your streaming data into a data lake for analytics

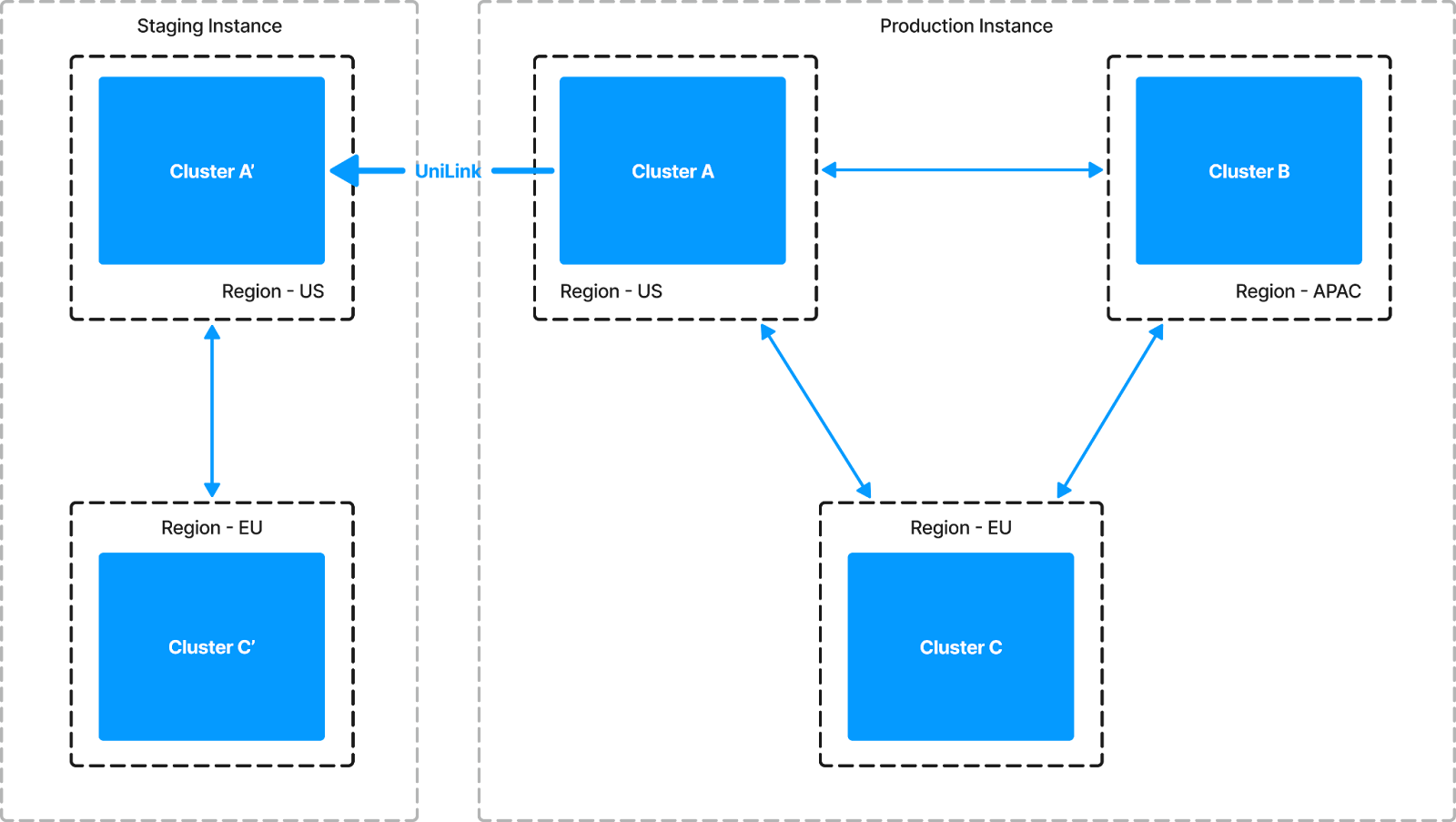
- Syncing data between production instances and staging or development instances
A New Beginning for Streaming Data Replication and Interoperability
Universal Linking transforms the way organizations approach data replication and bridges the gaps between different messaging protocols by making them interoperable through storing data in an open standard format. Whether you're managing multi-region Kafka clusters, migrating from various Kafka vendors to StreamNative, ensuring seamless interoperability between Kafka and Pulsar, or seeking a cost-effective disaster recovery solution, Universal Linking provides an efficient, scalable replication solution tailored for multi-cloud environments.
With this release, we are only scratching the surface of what the Ursa Stream Format can achieve. Exciting new features are on our roadmap, and we can't wait to share them with you.
Ready to Get Started?
Universal Linking is currently in private preview as part of our early access program, available for BYOC clusters. Join us and discover how Universal Linking can transform your data replication and migration strategy.




