
In an era where cost optimization and efficiency are more crucial than ever due to rising interest rates, surging inflation, and the threat of a recession, businesses are being forced to scrutinize expenses that have gone unchecked for years. Among these, the cost of data streaming, a vital component of modern cloud infrastructure, stands out as a significant and complex challenge.
Having worked with numerous customers, users, and prospects across our fully managed cloud offerings and private cloud software, we at StreamNative have gained a profound understanding of the factors determining and optimizing costs associated with data streaming. Our experience, coupled with managing costs in operating our own StreamNative Hosted Cloud, has provided insights into the key cost drivers and optimization levers for Pulsar and other data streaming platforms.
However, assessing the true cost of operating a data streaming platform is a complex task. Traditional analyses often fall short, focusing predominantly on compute and storage requirements while neglecting the substantial costs associated with networking—the often overlooked yet largest infrastructure cost factor. Our previous discussions, such as in the blog post “The New CAP Theorem for Data Streaming: Understanding the Trade-offs Between Cost, Availability, and Performance”, highlight these overlooked aspects and the significant, albeit less tangible, costs associated with development and operations personnel.
This blog series aims to shed light on the critical cost components of data streaming platforms, including infrastructure, operational, and downtime costs. These are pivotal due to their direct financial implications and potential to affect an organization's reputation and compliance standing. We are excited to launch this multi-part series to guide you through understanding and managing the costs associated with Apache Pulsar and Apache Kafka, providing insights that will help optimize your data streaming budget.
- Part 1: A Guide to Evaluating Infrastructure Costs of Apache Pulsar vs. Apache Kafka
Our first blog examines how much it costs to run Pulsar and Kafka. We'll compare the cost of compute, storage, networking, and extra tools they need to work well all the time.
Define a performance profile for cost consideration
As we compare infrastructure costs across various data streaming technologies, setting a standard performance benchmark is crucial to evaluate all technologies under equivalent conditions. This blog post focuses on selecting a low and stable end-to-end latency performance profile for cost analysis. We conducted "Maximum Sustainable Throughput" tests using the Open Messaging Benchmark to gauge how different systems maintain throughput alongside consistent end-to-end latency. Our 2022 benchmark report highlighted that Apache Pulsar achieved a throughput 2.5 times greater than Apache Kafka on an identical hardware setup consisting of three i3en.6xlarge nodes.
Employing an identical machine profile across the board negates the impact of various external factors, enabling a balanced comparison. Nonetheless, it's pertinent to acknowledge that adjustments in several parameters—such as the number of topics, producers, consumers, message size, and message batching efficiency—can influence performance and cost outcomes.
In preparation for a deeper analytical dive and comparison, we must also mention that numerous infrastructure elements are excluded from this preliminary discussion for brevity. These essential components, including load balancers, NAT gateways, Kubernetes clusters, and the observability stack, are integral to forging a production-grade data streaming setup and contribute to the overall infrastructure expenses. Additionally, this initial analysis focuses on the costs associated with managing a single cluster, though many organizations will likely operate multiple clusters across various setups.
Hence, while this comparative analysis provides a foundational framework that may underrepresent the total costs of independently running and supporting Pulsar or Kafka, it introduces a standardized method for facilitating cost comparisons among a broad spectrum of data streaming technologies.
Compute Costs
The journey towards cost efficiency often begins with compute resources, which, while forming a minor part of the overall infrastructure expenses, are traditionally the first target for savings. This mindset refers to a time before cloud computing, when scaling compute resources was a significant challenge, largely due to their tight integration with storage solutions.
Understanding the compute costs associated with Apache Pulsar and Apache Kafka necessitates a look into their architectural foundations. Kafka employs a monolithic design that integrates serving and storage capabilities within the same node. Conversely, Pulsar opts for a more flexible two-layer architecture, allowing for the separation of serving and storage functions. Establishing a standardized cost measure is essential to accurately comparing computing costs between these two technologies.
To standardize compute cost evaluation, we introduce the concept of a Compute Unit (CU), defined by the capacity of 1 CPU and 8 GB of memory, as a baseline for comparison. This allows us to evaluate a) the cost per compute unit and b) the throughput each technology can achieve per compute unit.
Our analysis used three i3en.12xlarge machines, totaling 72 CUs, costing $0.11 per hour for each CU. Our benchmark report revealed that Kafka could support 280 MB/s for both ingress and egress traffic, equating to 3.89 MB/s for both ingress and egress per CU. Pulsar, benefiting from its two-layer architecture, supports 700 MB/s for both ingress and egress. In this benchmark for Apache Pulsar, each node runs one broker and one bookie. One-third of the computing power is allocated for running brokers, while the remaining two-thirds is allocated for running bookies. This allocation translates to 24 CUs for brokers and 48 CUs for bookies, with a Broker Compute Unit supporting 29.17 MB/s and a Bookie Compute Unit supporting 14.58 MB/s for both ingress and egress.
So, the throughput efficiency per compute unit stands as follows between Pulsar and Kafka:

This standardization aids in estimating the total compute cost for different workloads, revealing significant differences in compute unit requirements and the associated costs for various ingress and egress scenarios.
Compute Costs among different workloads.
With this standardization, we compare the compute costs of Pulsar and Kafka under three different workloads and evaluate how costs change when the fanout ratio is changed:
- Low Fanout: 100 MBps Ingress, 100 MBps Egress
- Moderate Fanout: 100 MBps Ingress, 500 MBps Egress
- High Fanout: 100 MBps Ingress, 1000 MBps Egress
- 100 MBps Ingress, 100 MBps Egress Example Workload
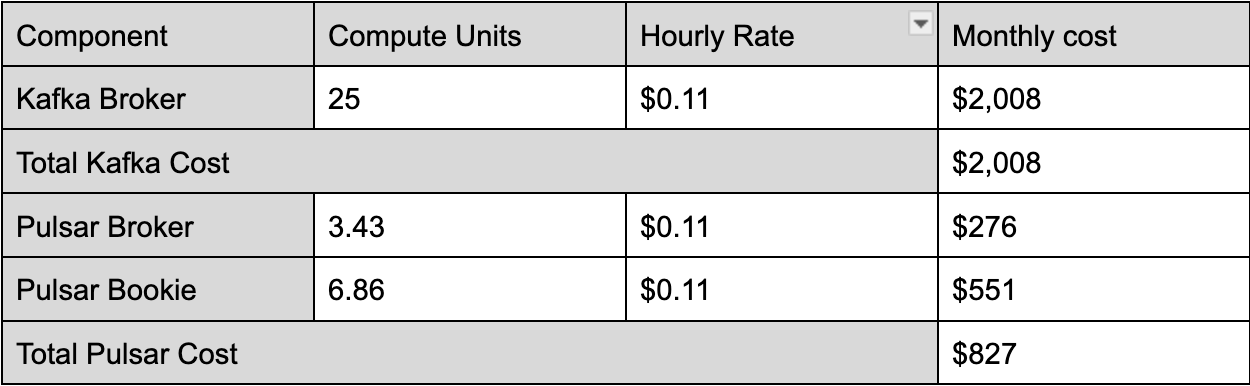
- 100 MBps Ingress, 300 MBps Egress Example Workload
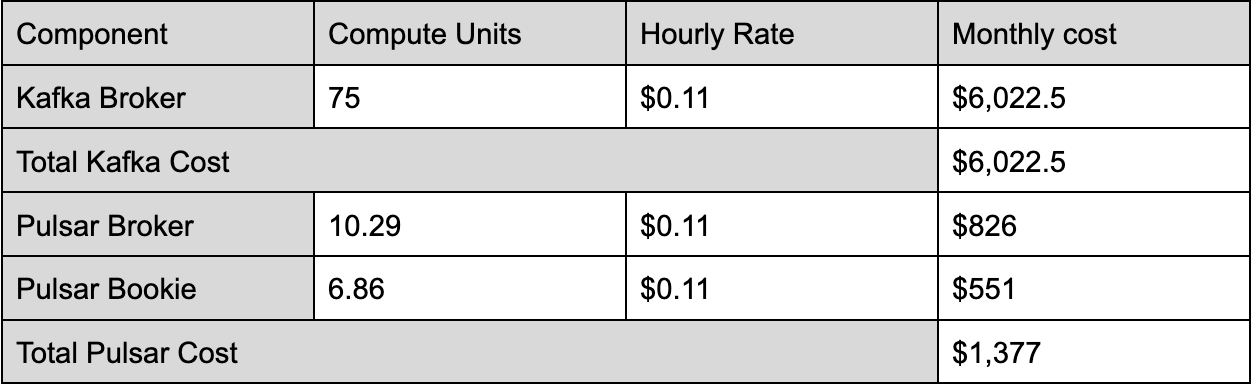
- 100 MBps Ingress, 500 MBps Egress Example Workload
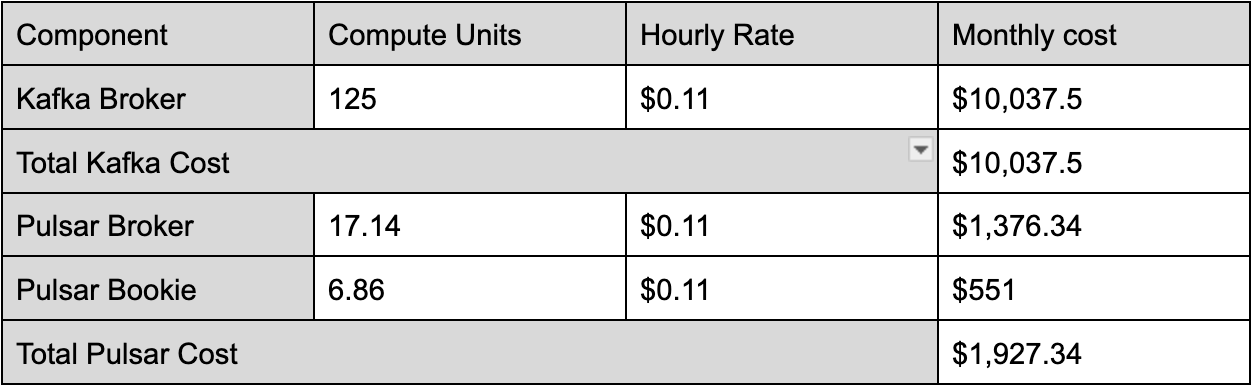
- 100 MBps Ingress, 1000 MBps Egress Example Workload
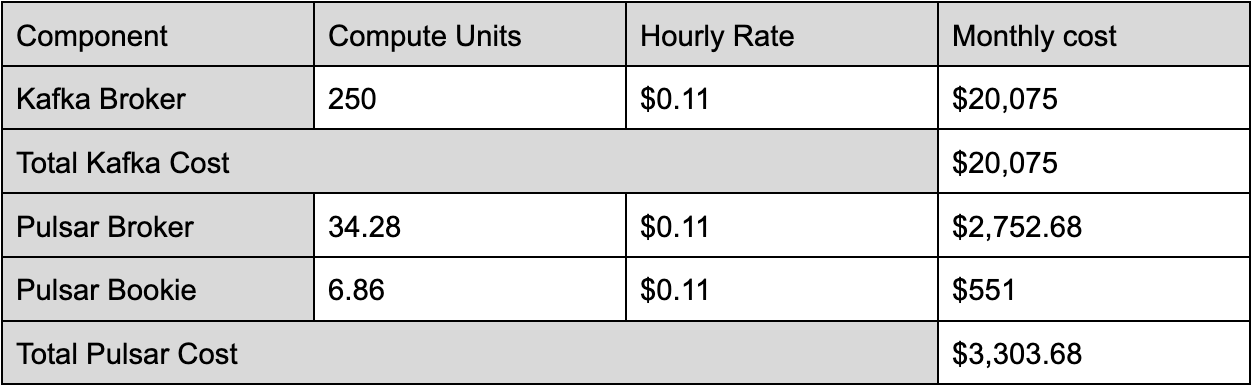
Compiling the data from various workload scenarios highlights the significant difference in computing costs between Apache Pulsar and Apache Kafka. Notably, Pulsar offers a compute cost advantage, being 2.5 times more cost-effective than Kafka. The costs of Apache Kafka increase linearly as the egress rate increases because Kafka has to provision resources to meet egress requirements, which results in the unnecessary overprovisioning of ingress and the processing power of storage components.
In contrast, as the fanout ratio increases, Pulsar's cost efficiency becomes even more pronounced, reaching a point where it is six times more economical than Kafka with a tenfold increase in fanout. This superior cost efficiency stems from Pulsar's dual-layer architecture, allowing for scaling of resources as needed – for example, adding more brokers to increase serving capacity without necessarily increasing the processing power of storage components – which becomes increasingly advantageous as the fanout number grows.
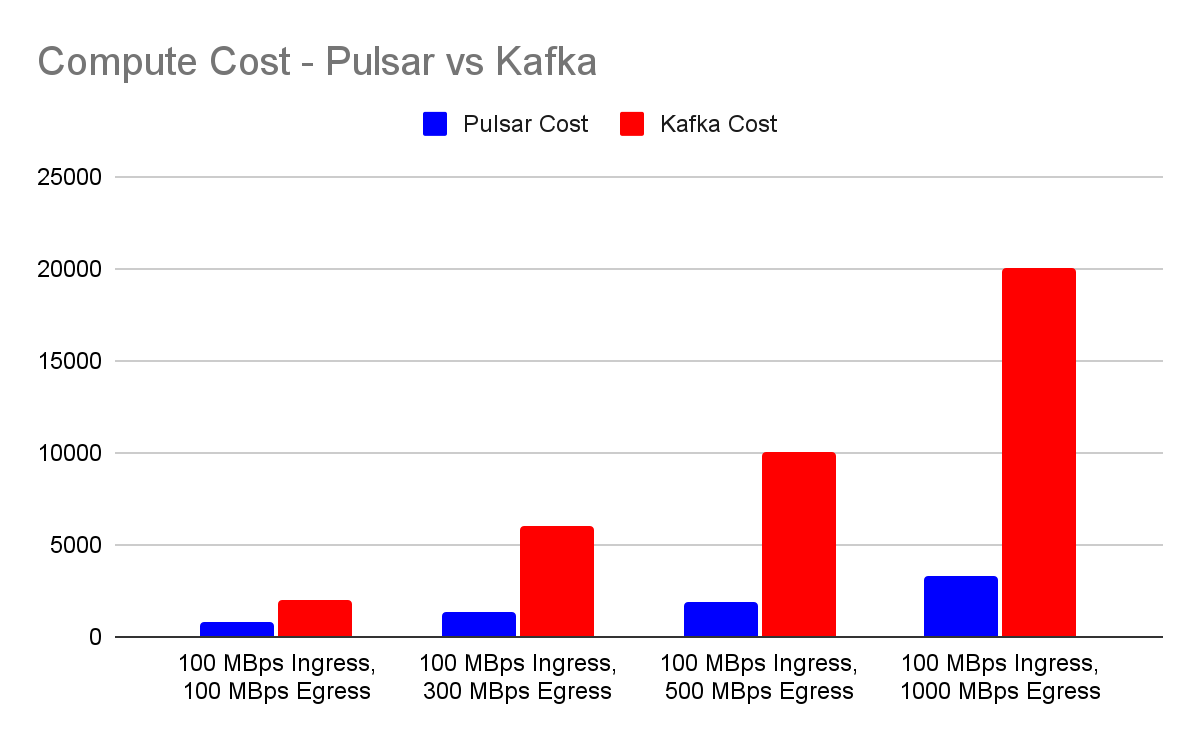
While this analysis offers a clear framework for comparing compute costs between Pulsar and Kafka, it's important to note that real-world scenarios involve more complexity. Decisions regarding the optimal machine type for specific components, the appropriate number of these components, and how to best optimize machine types for each workload are nuanced and require careful consideration. The examples provided serve as a basis for illustration, emphasizing that the practical application of these findings can be as complex as the technologies themselves.
Storage Costs
Calculating storage costs for data streaming platforms like Apache Pulsar and Apache Kafka can be complex, especially with factors such as IOPs and throughput influencing pricing. For simplicity, this analysis will focus solely on local EBS storage costs. However, it's crucial to consider additional IOPs and throughput expenses for clusters experiencing significant vertical scaling or high throughput demands.
Before we examine cost estimations, it's crucial to understand the distinct storage models utilized by Pulsar and Kafka. Kafka combines serving and storage functions within a single node, typically using general-purpose SSDs (e.g., gp3) to support a range of workloads. This configuration leads to a storage cost of $0.08 per GB-month for Kafka.
In contrast, Pulsar adopts a different approach by separating serving from storage, which involves a dual-disk system on its storage nodes to handle write and read operations efficiently. BookKeeper, Pulsar’s storage component, uses separate storage devices for its journal and main ledger.
The journal, which requires fast and durable storage to manage write-heavy loads effectively, is usually stored on SSDs. For read operations, tailing reads are sourced directly from the memTable, while catch-up reads come from the Ledger Disk and Index Disk. This separation ensures that intense read activities do not affect the performance of incoming writes due to their isolation on different physical disks.
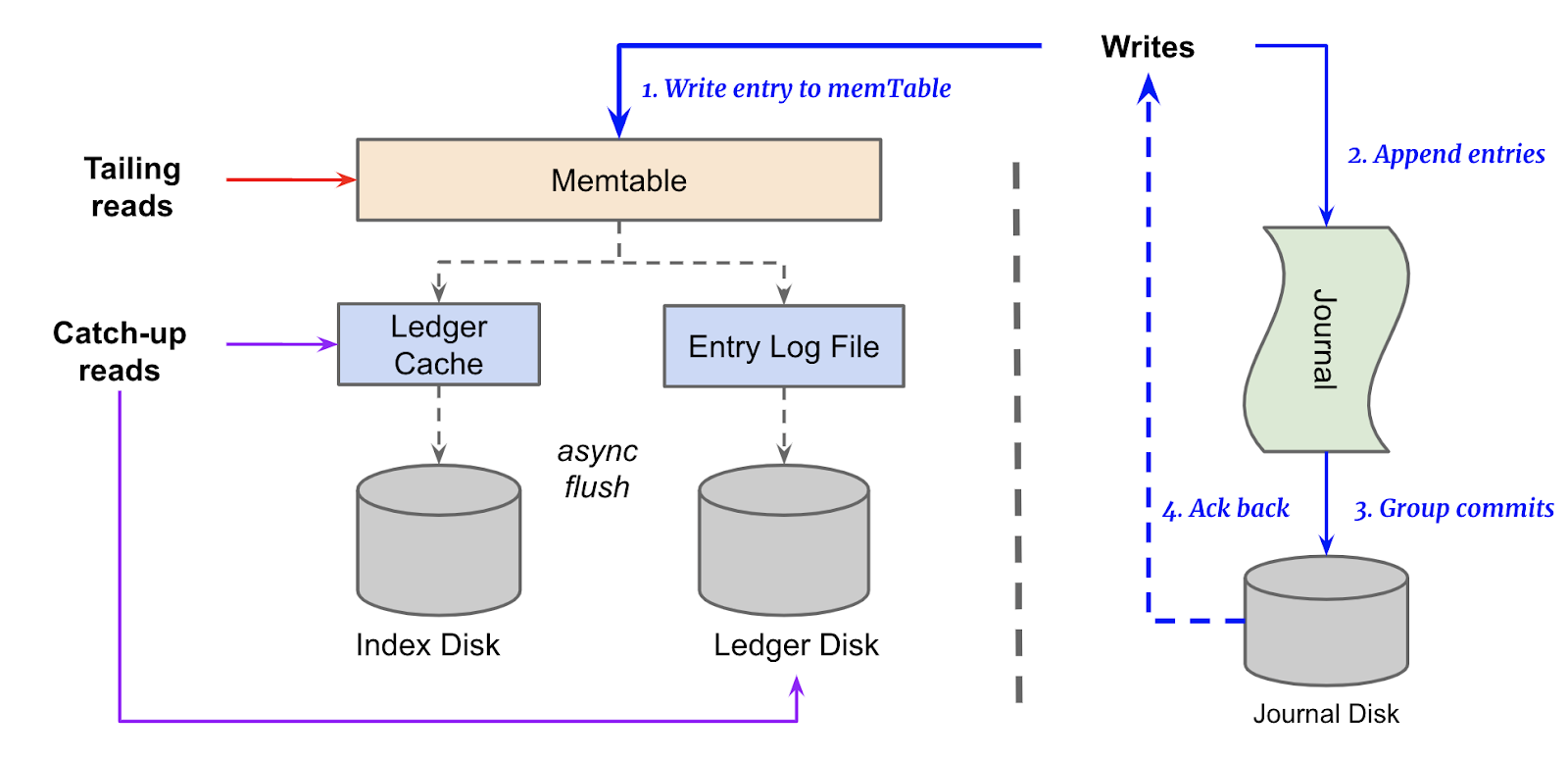
The architecture employs general-purpose SSDs (at $0.08/GB-month, plus additional throughput charges of $0.040 per MB/s for usage above 125MB/s) for the journal disk and throughput-optimized HDDs (at $0.045/GB-month) for ledger disks. This dual-disk strategy allows for the optimization of both cost and performance.
To estimate storage costs, consider factors like ingress rate, replication factor, and retention period, which determine the required storage capacity. The cost can then be calculated based on the specific unit prices of the storage solutions employed.
Storage Costs among different workloads
We compare the storage costs of Pulsar and Kafka with different ingress and data retention.
100 MB Ingress, 7 days retention
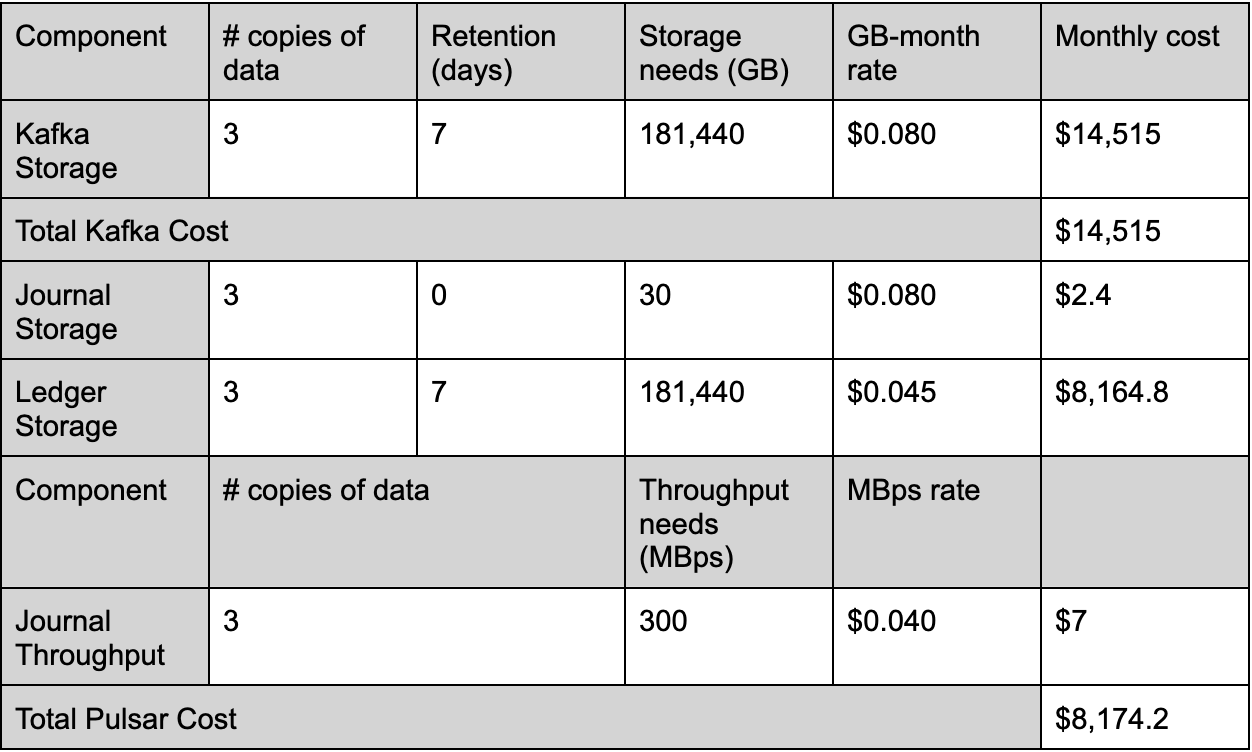
100 MB Ingress, 30 days retention
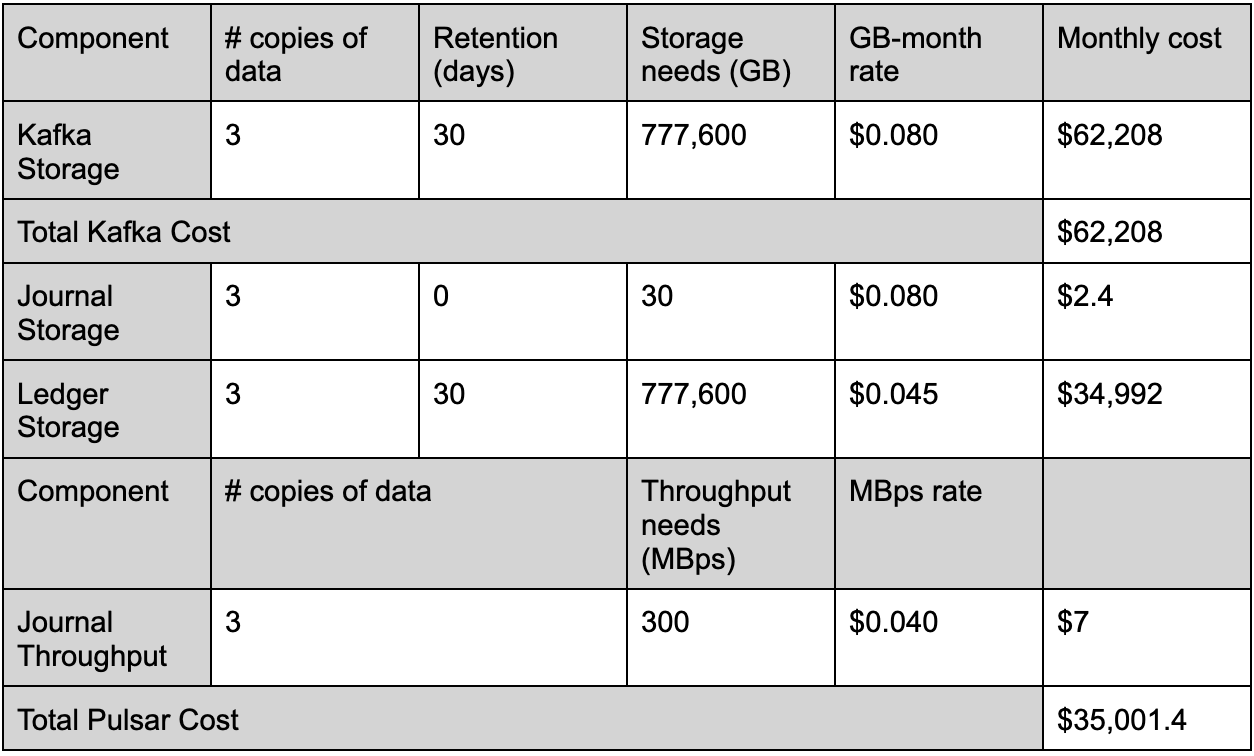
1000 MB Ingress, 7 days retention
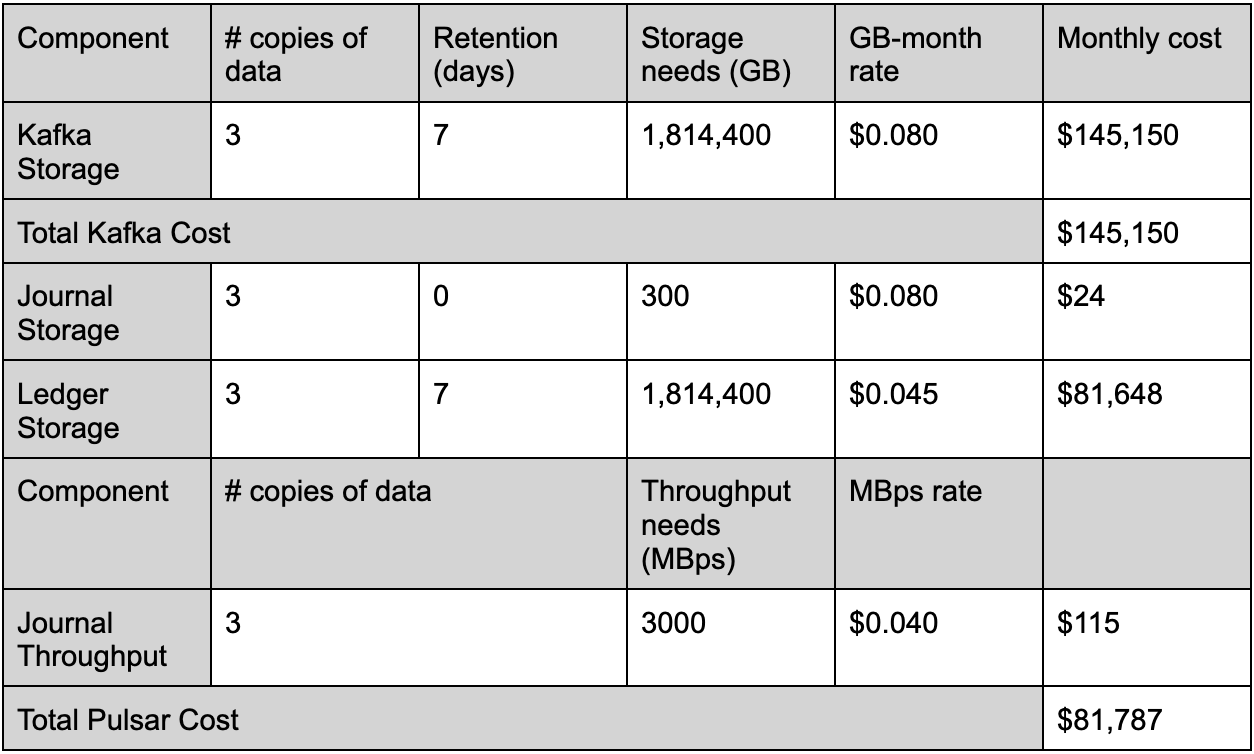
Compiling the data from various workload scenarios highlights the significant difference in storage costs between Apache Pulsar and Apache Kafka. Notably, Pulsar offers a storage cost advantage, being 1.7 times more cost-effective than Kafka.
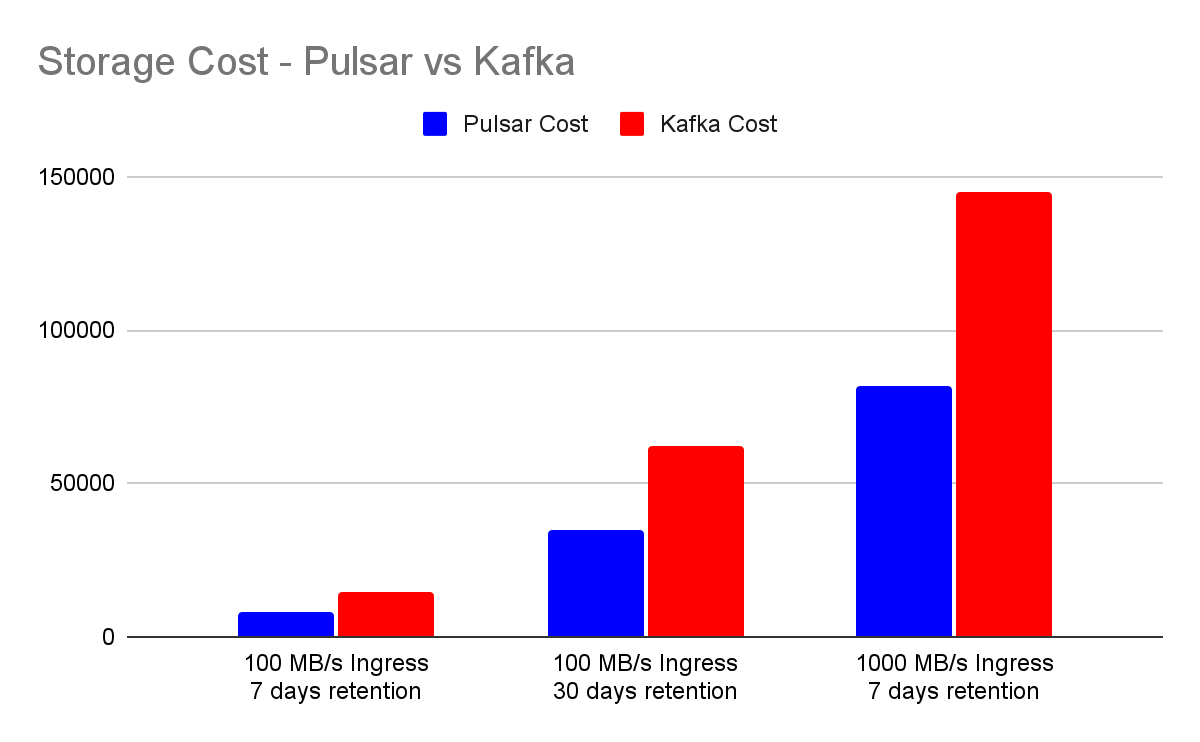
Cost Efficiency from Tiered Storage Solutions
Pulsar's adoption of a tiered storage system in 2018 marks a significant step forward in reducing storage costs. By offloading older data to cheaper cloud-based object storage, such as Amazon S3, Pulsar reduces local storage needs and cuts costs dramatically, potentially by over 90%, depending on the distribution between local and object storage. This system also offers the benefit of lowering compute costs for high-retention scenarios by negating the need for additional storage nodes.
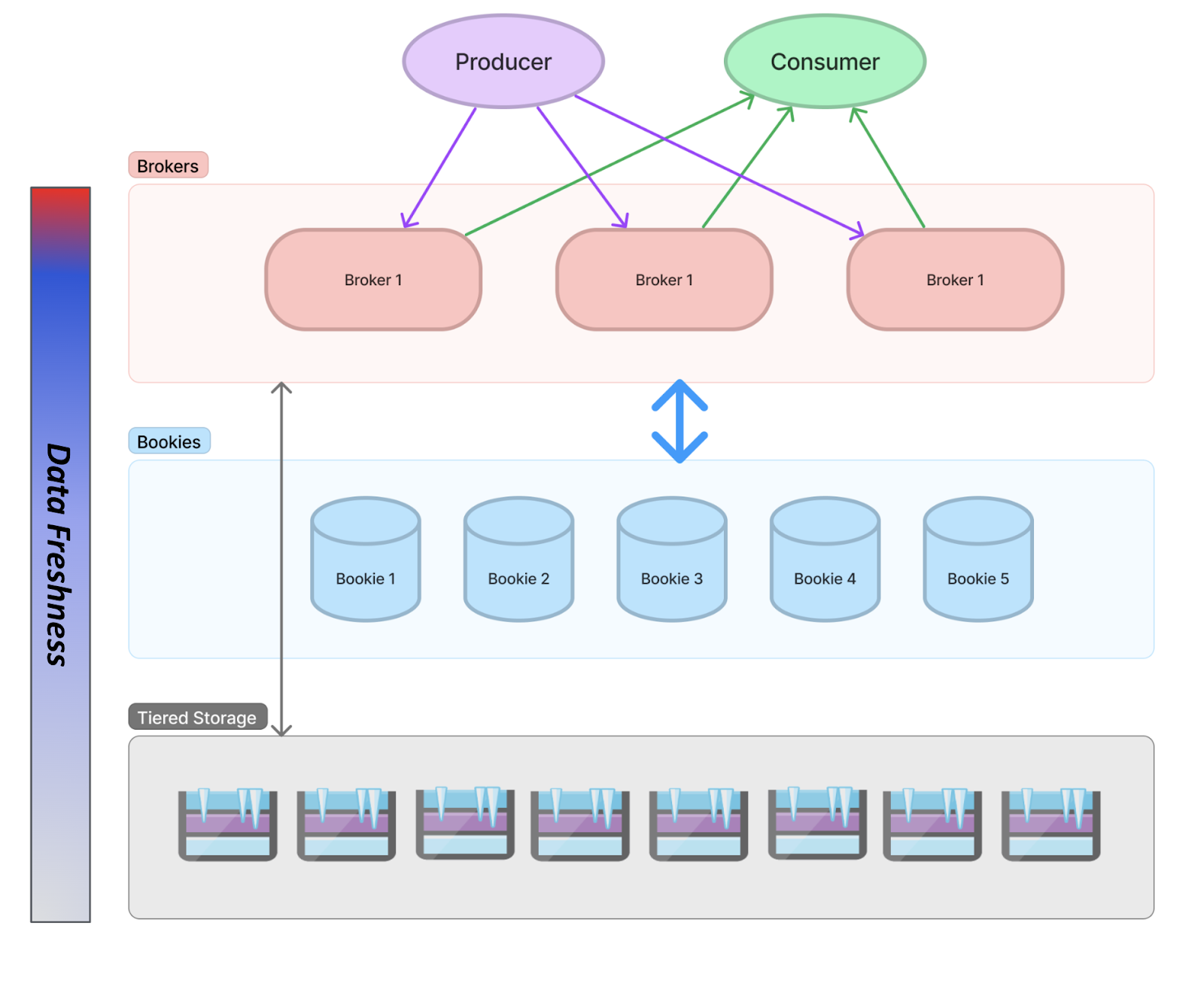
Kafka is evolving to incorporate tiered storage solutions as well, though with a notable difference: while Pulsar can directly serve data from tiered storage without reloading it to local disks, Kafka's model necessitates data reloading, requiring additional local storage planning and potentially incurring higher costs.
From Tiered Storage to Lakehouse Storage
StreamNative's introduction of Lakehouse tiered storage further enhances Pulsar's storage efficiency. By leveraging columnar data formats aligned with Pulsar's schema, this feature significantly reduces the volume of data stored in S3 and the operational costs associated with data access, offering savings of up to 3-6 times depending on retention policies and schema specifics. This innovation represents a critical advancement in optimizing storage costs and efficiency for Pulsar users.
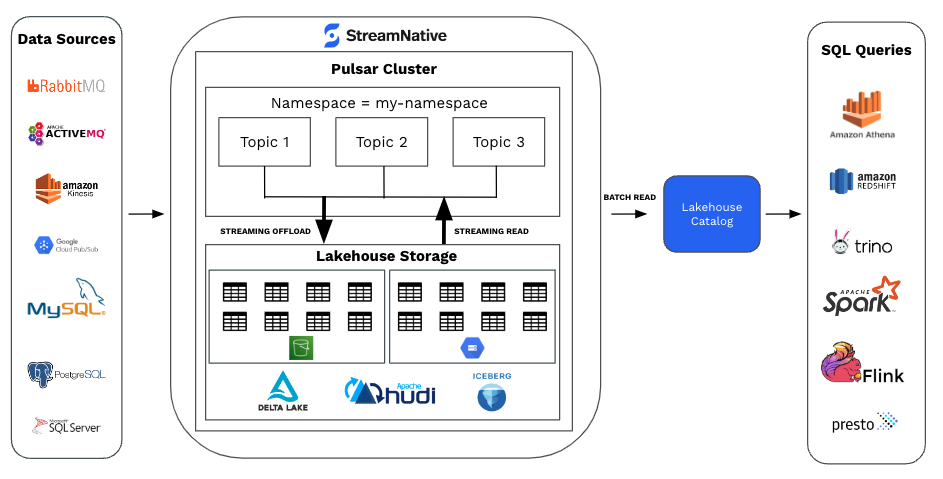
Comparing and Optimizing Resource Utilization
At this juncture, we've temporarily moved past the necessity of overprovisioning resources to accommodate your workload variations. Nevertheless, to maintain reliability and optimal performance, it's crucial to overprovision computing resources to safeguard against unforeseen spikes in throughput and to overprovision storage resources to prevent the risk of depleting disk space. In this section below, we will look into the resource utilization between Pulsar and Kafka in handling workload changes.
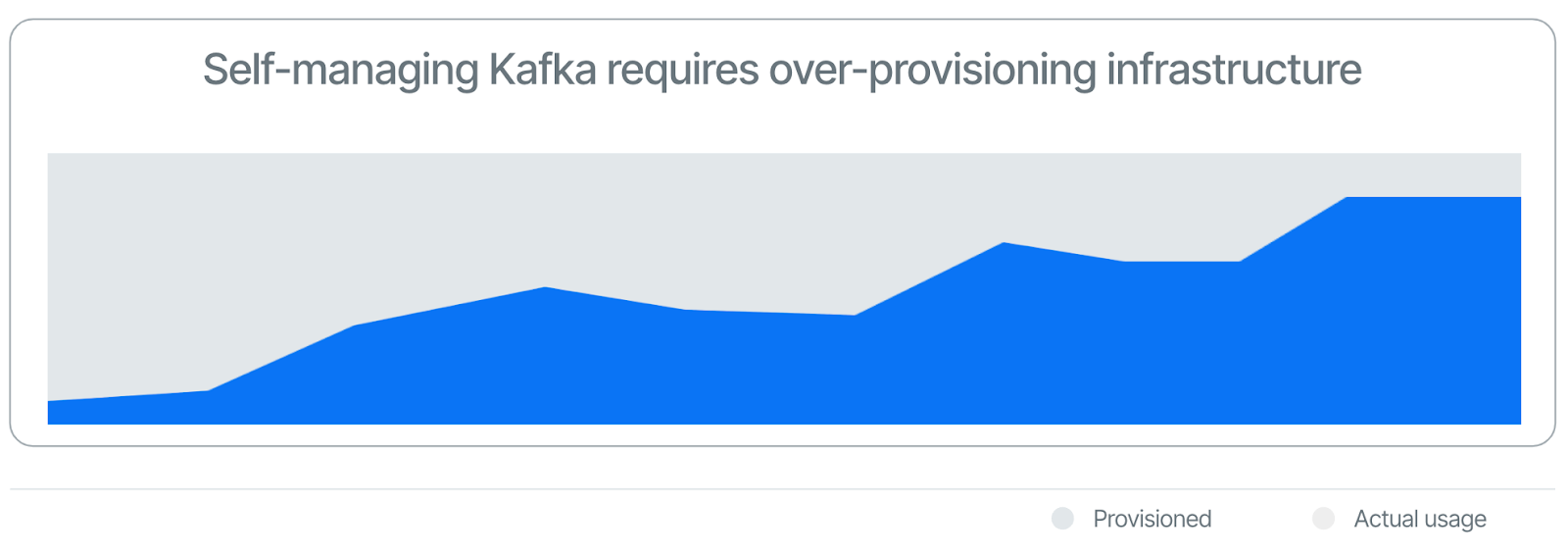
In modern cloud-native environments, organizations frequently utilize Kubernetes and the inherent elasticity of cloud resources for scaling nodes in response to real-time traffic demands. However, Apache Kafka's design, which integrates serving and storage functions, presents a scalability challenge. Kafka necessitates a proportional increase in storage capacity to enhance serving capabilities and vice versa. Scaling operations in Kafka involve partition rebalancing, leading to potential service disruptions and significant data transfer over the network, thus impacting both performance and network-related costs.
This scenario often forces Kafka users to operate their clusters in a state of chronic overprovisioning, maintaining resource utilization levels well below optimal (sometimes below 20%). Despite the low usage, the financial implications of maintaining these additional resources are reflected in their cloud billing.
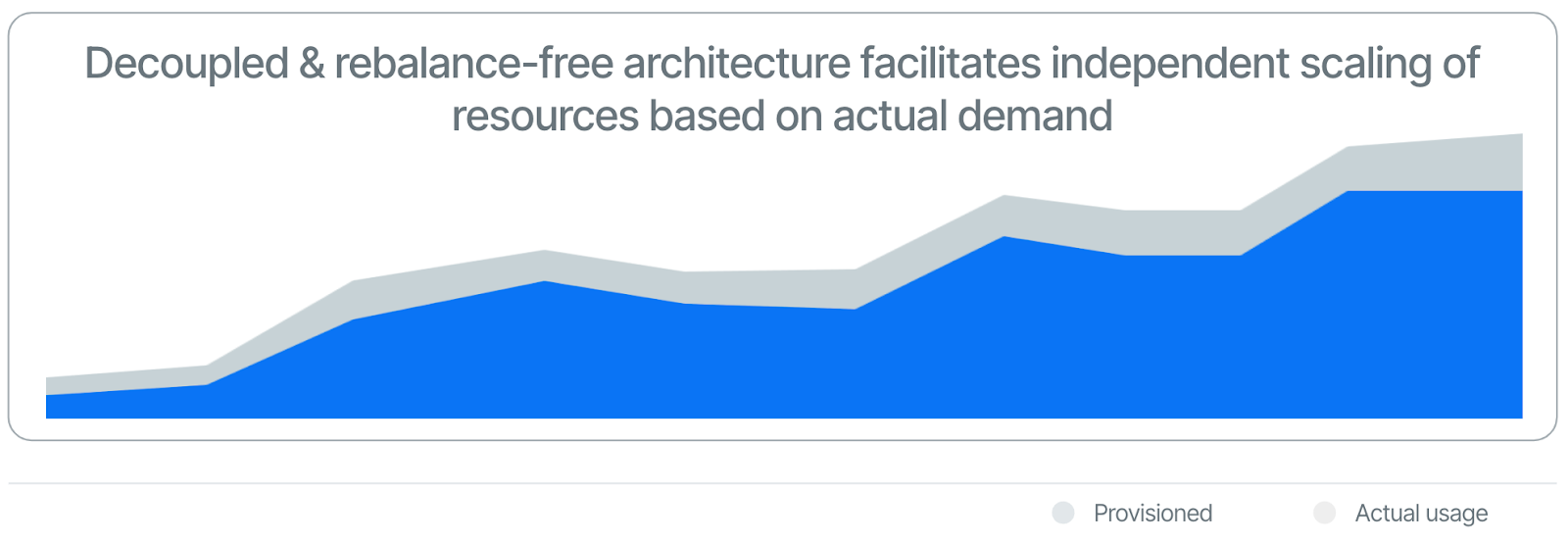
In contrast, engineered with the cloud-native landscape in mind, Apache Pulsar introduces an innovative approach to resource management, enabling precise optimization of compute and storage usage to control infrastructure expenses efficiently. Several key features distinguish Pulsar's architecture:
- Two-Layered Architecture: By decoupling message serving from storage, Pulsar facilitates independent scaling of resources based on actual demand. This flexibility allows for the addition of storage capabilities to extend data retention or the enhancement of serving nodes to increase consumption capacity without the need for proportional scaling.
- Rebalance-Free Storage: Pulsar's design minimizes the network load associated with scaling by eliminating the need for partition rebalancing. This approach prevents service degradation during scaling events and curtails spikes in networking costs.
- Quota Management and Resource Limits: With built-in support for multi-tenancy, Pulsar enables effective quota management and the imposition of resource limits, safeguarding high availability and scalability across diverse operational scenarios.
A Note on Multi-Tenancy in Data Streaming Platforms
This blog post primarily addresses assessing infrastructure costs associated with one cluster. However, it is crucial to highlight the significant advantages of adopting a multi-tenant platform, particularly how multi-tenancy can decrease the total cost of ownership for such data streaming platforms. Here are several reasons why your business stands to benefit from multi-tenancy.
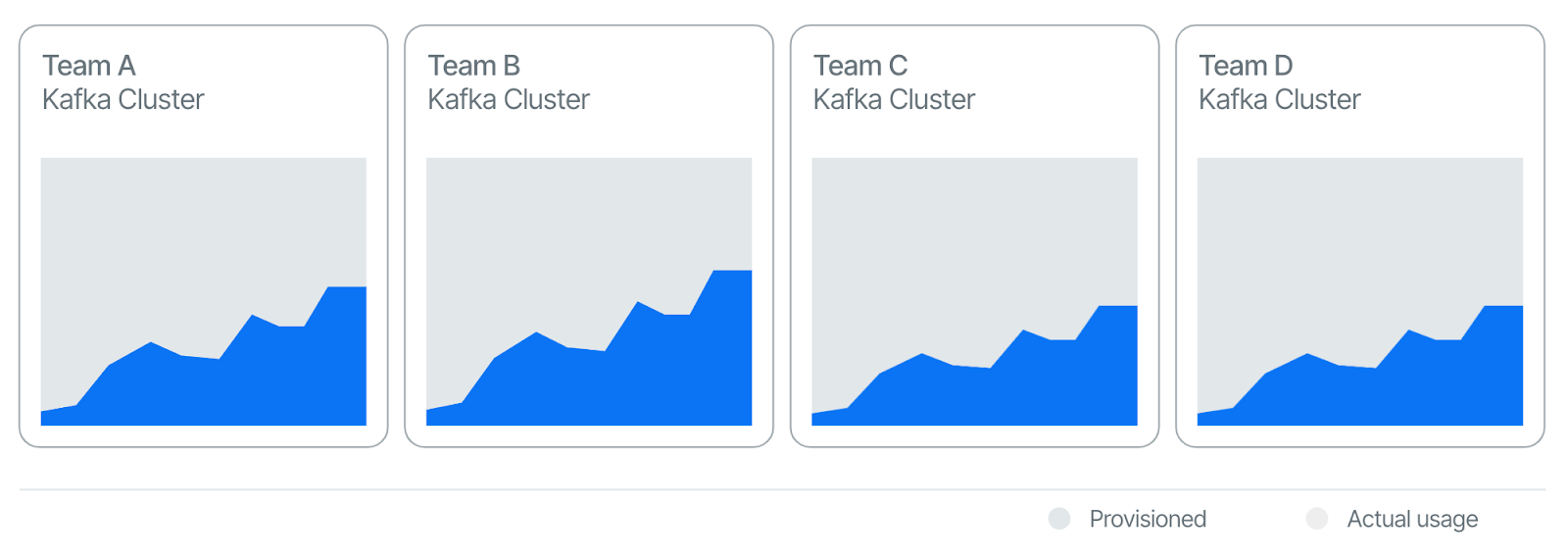
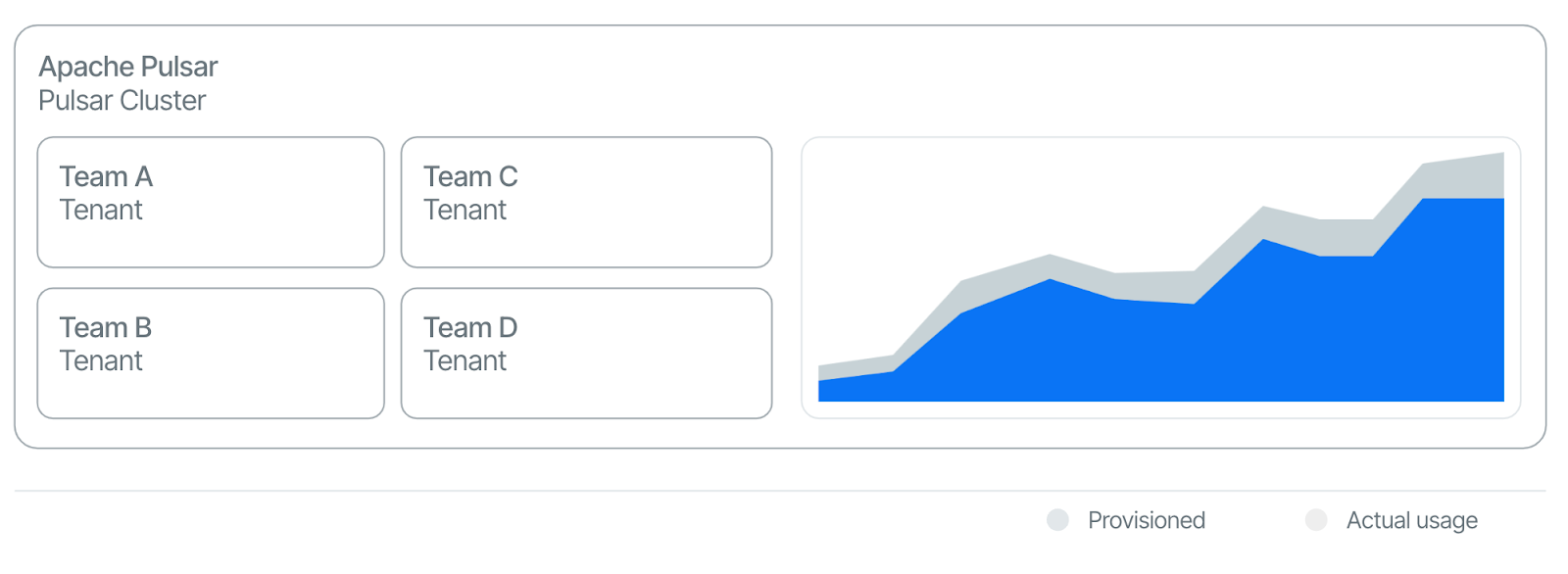
- Lower cost: Companies adopting Apache Kafka often require multiple Kafka clusters to cater to different teams within an organization, primarily due to the inherent limitations in Kafka’ architecture (See Figure 8). This scenario typically leads to each cluster operating at less than 30% capacity. Conversely, Apache Pulsar allows for the use of a single, multi-tenant cluster. Such deployment facilitates cost-sharing across various teams and enhances overall resource utilization. By pooling resources, organizations can significantly diminish the fixed costs and reduce the total cost of ownership, as resources are more efficiently allocated and used (See Figure 9).
- Simpler operations: Managing a single multi-tenant cluster simplifies operations compared to maintaining multiple single-tenant clusters. With fewer clusters, there’s less complexity in managing access controls, credentials, networking configurations, schema registries, roles, etc. Moreover, the challenge of tracking and upgrading different software versions across various clusters can become an operational quagmire. By centralizing on a multi-tenant platform, organizations can drastically cut operational burdens and associated costs, streamlining the management process and reducing the likelihood of errors.
- Greater reuse: When all teams utilize a common cluster, reusing existing data becomes significantly more straightforward. A simple adjustment in access controls can enable different teams to leverage topics and events created by others, thereby accelerating the delivery of new projects and value creation. Furthermore, minimizing data duplication between clusters can lead to substantial savings. In data streaming platforms, where networking often constitutes a major portion of the expenses, a multi-tenant solution that reduces the need for data copying can markedly decrease the total network costs. This optimizes infrastructure cost and enhances the speed and efficiency of data-driven initiatives within the organization.
By embracing a multi-tenant data streaming technology like Apache Pulsar, businesses can achieve a more cost-effective, streamlined, and scalable data streaming environment, thereby enhancing operational efficiency and reducing operational overheads.
Looking ahead, our future blog posts will delve deeper into these aspects, exploring how Pulsar's cloud-native capabilities can be leveraged to achieve optimal resource utilization and cost efficiency in data streaming applications.
Network Costs
Networking is often the most significant expense in integrating operational business applications with analytical data services through data streaming platforms. Unraveling networking costs is challenging, as cloud providers typically bundle these expenses with other organizational network usage without distinguishing between costs for specific technologies like Kafka and Pulsar.
To tackle this, we can construct a model to estimate these costs more accurately. In AP (Availability and Performance) data streaming systems such as Kafka and Pulsar, cross-AZ (Availability Zone) traffic incurs substantial costs due to the necessity for cross-AZ replication to ensure high availability and reliability. For robustness, operating in a multi-zone cluster is recommended, avoiding single-zone deployments that risk downtime during zonal outages. Pulsar's two-layer architecture offers a strategic advantage, allowing storage nodes to span multiple zones for durability while consolidating broker nodes within a single zone to expedite failover processes.
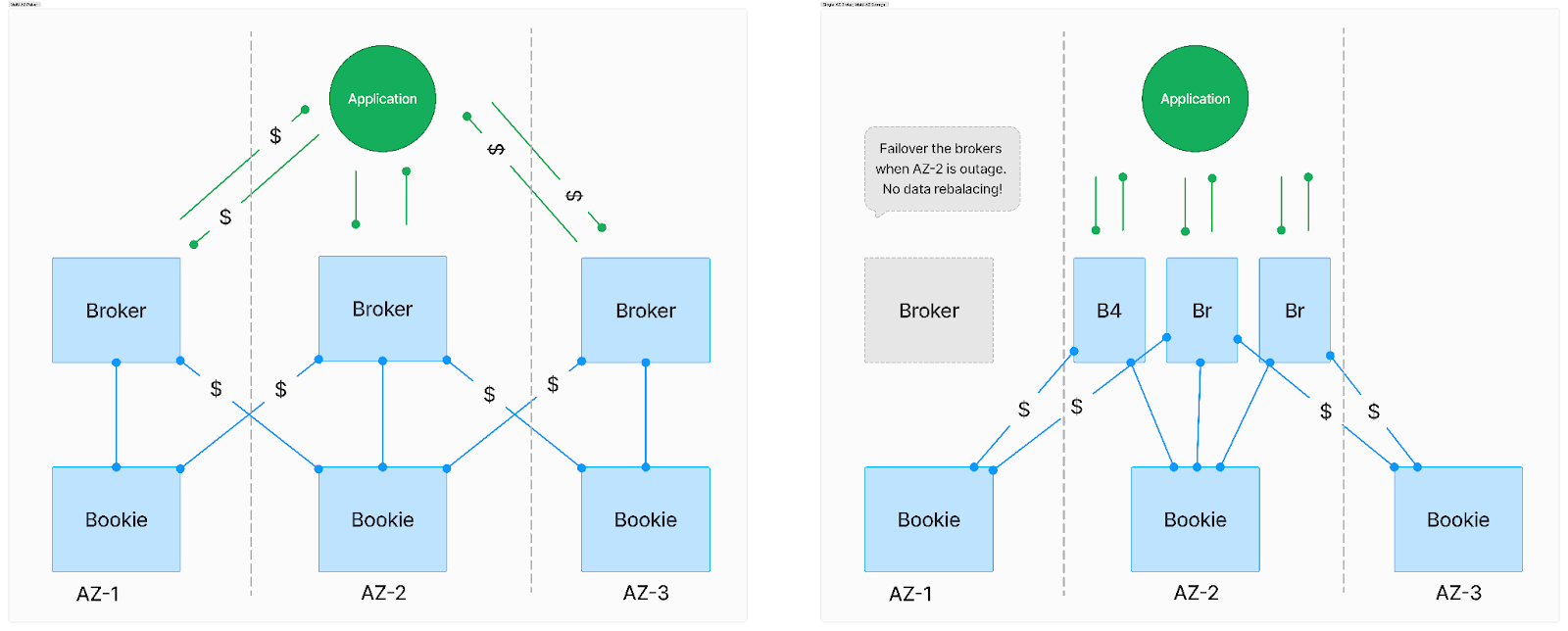
Networking Cost Models
Hence, we examine the following three deployment scenarios:
- Kafka (Multi-AZ): A Kafka cluster spans multiple availability zones.
- Pulsar (Multi-AZ): A Pulsar cluster's broker and storage nodes are distributed across multiple zones.
- Pulsar (Single-AZ Broker, Multi-AZ Storage): Storage nodes are multi-zone, but broker nodes are confined to a single zone for swift failover.
The primary driver for cross-AZ traffic for Kafka (Multi-AZ) and Pulsar (Multi-AZ) are similar.
- Producers: Typically, topic owners in Pulsar or partition leaders in Kafka are distributed across three zones, leading to about 2/3 of producer traffic crossing zones.
- Consumers: Similarly, consumers often fetch data from topic owners or partition leaders in a different zone, generating cross-zone traffic roughly 2/3 of the time.
- Data Replication: Both systems replicate data across two additional zones for resilience.
We calculate the cross-AZ traffic for Multi-AZ deployments using the following formula:
Cross-AZ throughput (MB / sec) = Producer cross-AZ throughput + Consumer cross-AZ throughput + Data replication cross-AZ throughput = (Ingress MBps * ⅔) + (Egress MBps * ⅔) + (Ingress MBps * 2)
Cross-AZ traffic from producers and consumers is eliminated for the unique Pulsar setup with Single-AZ Brokers and Multi-AZ Storage (see Figure 8), significantly reducing overall networking costs. So, we calculate only the data replication throughput across availability zones as the cross-AZ traffic.
Cross-AZ throughput (MB / sec) = Data replication cross-AZ throughput = Ingress MBps * 2
Networking Cost Calculation and Implications
We’ve modeled how much cross-AZ traffic results from our workload below, multiplied by the standard cross-AZ charge of two cents per GB in AWS.
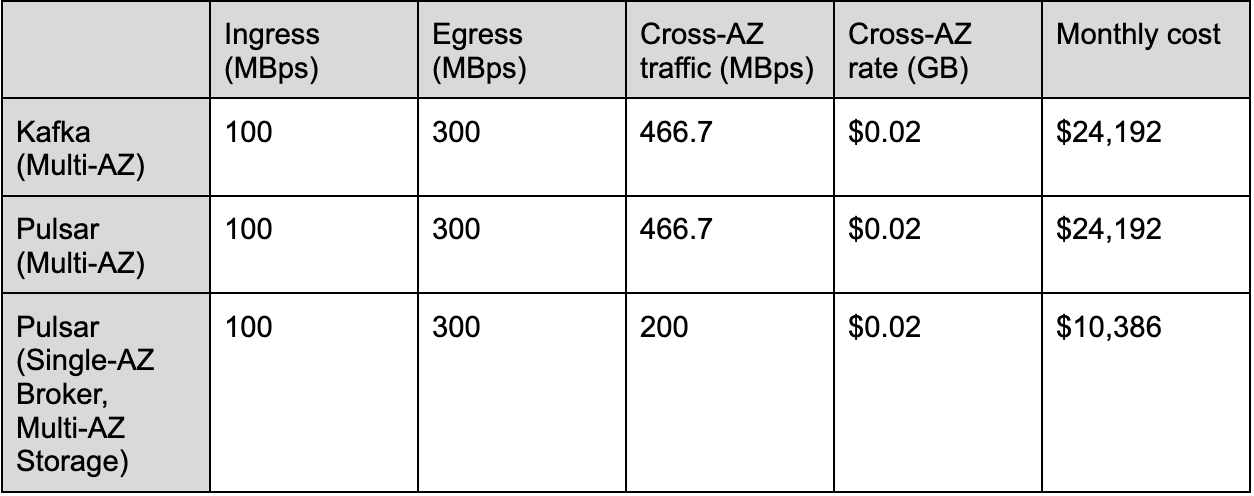
Reflecting on the data presented, it becomes evident that with the expansion of throughput and the increase in fanout, networking expenses swiftly become the predominant component of your infrastructure costs. Furthermore, while implementing Tiered Storage can significantly lower storage expenses, networking costs alone may still account for approximately 90% of total infrastructure expenditure. This underscores the importance of Apache Pulsar's dual-layer architecture, which is vital in minimizing networking fees while simultaneously upholding system reliability and availability.
Innovations in Reducing Networking Costs
The introduction of technologies like follower fetching in Kafka and ReadOnly Broker in Pulsar is pivotal in further reducing networking expenses. These allow consumers to read from a broker within the same zone, avoiding the costs associated with cross-zone data leader access. This approach ensures that cross-zone replication costs are incurred just once, irrespective of the number of consumers, offering a path to substantial savings on networking expenses. For example, in a cluster setup with 100 MBps ingress and 300 MBps egress, the cross-AZ traffic can be reduced from 466.7 MBps to 266.7 MBps, resulting in a 42.9% reduction in traffic.
Putting these together
We're consolidating compute, storage, and networking expenses to assess the overall infrastructure costs of Pulsar versus Kafka. In a standard deployment scenario with 100 MBps ingress, 300 MBps egress, and a 7-day data retention workload, Pulsar offers a 77% reduction in compute costs and nearly a 60% reduction in total infrastructure costs, including both storage and network expenses.
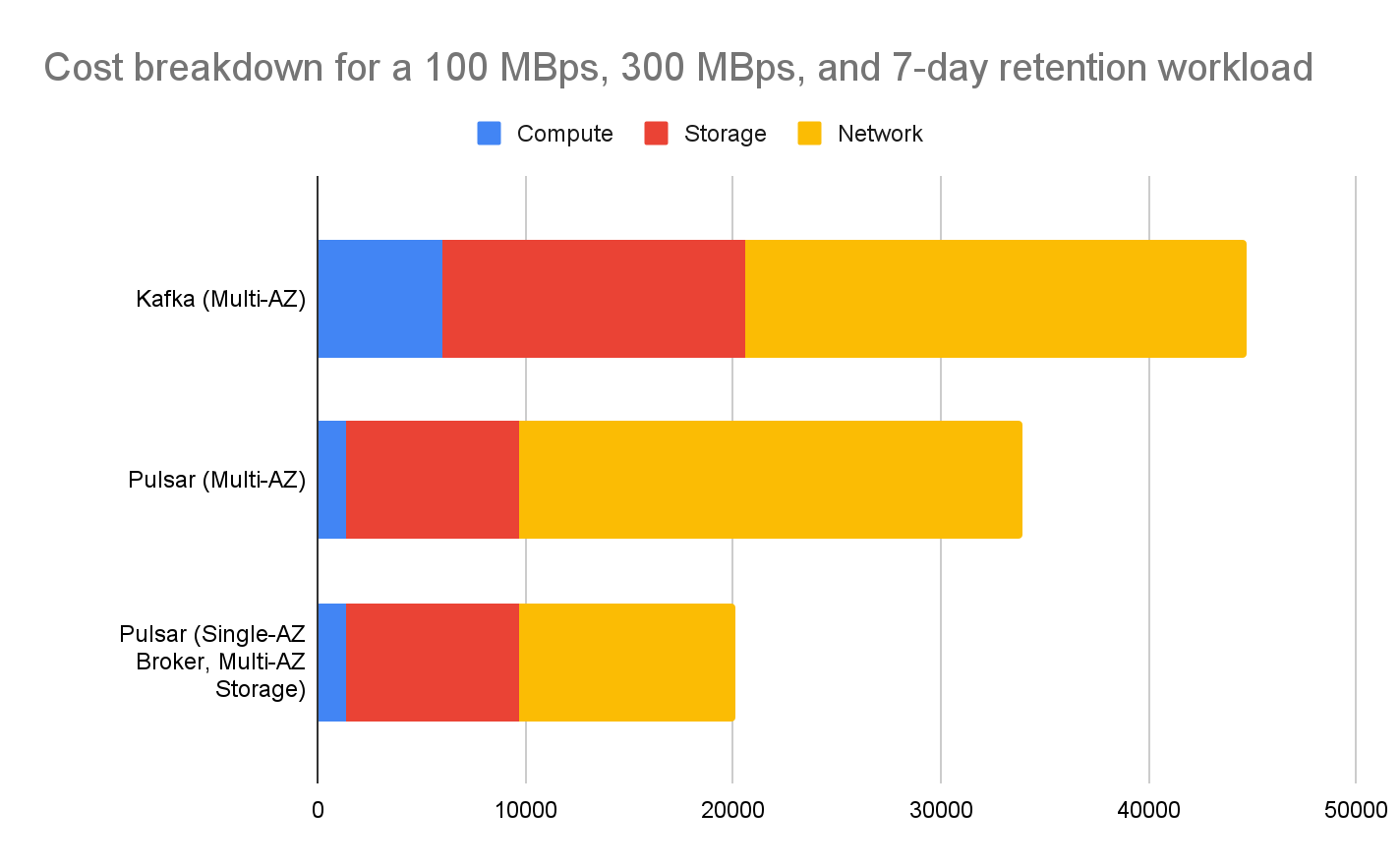
So, how can you save money?
Up to this point, we've dissected the cost structure of your data streaming infrastructure, hopefully providing you with a clearer understanding of how a data streaming platform can impact your finances. This guide outlines a methodical approach for Kafka users to tackle each cost component. A logical first step could be enabling follower fetching to mitigate cross-AZ charges. Lowering the replication factor for non-essential topics can further optimize networking expenses tied to partition replication. It's also beneficial to evaluate different instance types to find the most cost-effective fit for your requirements. Finally, adjusting your cluster's scale based on workload fluctuations ensures you're not overspending on underutilized infrastructure.
In our experience assisting numerous Kafka users in evaluating the costs of self-hosted open-source Kafka against open-source Pulsar and our fully managed Kafka API-compatible cloud service, StreamNative Cloud, we've consistently found that transitioning to a fully managed Kafka API-compatible cloud service and utilizing the architectural benefits of Apache Pulsar is the most cost-effective strategy. Apache Pulsar's distinctive, cloud-native architecture not only facilitates cost reductions but also introduces at-scale efficiencies. StreamNative Cloud, developed atop Apache Pulsar, offers full Kafka compatibility, enabling you to migrate without needing to overhaul your Kafka applications and capitalize on the cost advantages of Pulsar’s cloud-native design.
Don't miss our next installment in this series, which will delve into another crucial cost factor for data streaming platforms: development and operations personnel. If you're interested in calculating your Kafka expenses or discovering potential savings with StreamNative, we encourage you to talk to our data streaming experts today and conduct a TCO analysis.
If you want to learn more about our development around Kafka API-compatible data streaming platforms, don’t miss the upcoming Pulsar Summit on May 14th next week. Our team will present our next-generation data streaming engine, purposely designed to reduce costs in this cost-conscious era. Register for the event today!




